
В нашей прошлой статье про синтез речи мы дали много обещаний: убрать детские болячки, радикально ускорить синтез еще в 10 раз, добавить новые "фишечки", радикально улучшить качество.
Сейчас, вложив огромное количество работы, мы наконец готовы поделиться с сообществом своими успехами:
- Снизили размер модели в 2 раза;
- Научили наши модели делать паузы;
- Добавили один высококачественный голос (и бесконечное число случайных);
- Ускорили наши модели где-то примерно в 10 раз (!);
- Упаковали всех спикеров одного языка в одну модель;
- Наши модели теперь могут принимать на вход даже целые абзацы текста;
- Добавили функции контроля скорости и высоты речи через SSML;
- Наш синтез работает сразу в трех частотах дискретизации на выбор — 8, 24 и 48 килогерц;
- Решили детские проблемы наших моделей: нестабильность и пропуск слов, и добавили флаги для контроля ударения;
Это по-настоящему уникальное и прорывное достижение и мы не собираемся останавливаться. В ближайшее время мы добавим большое количество моделей на разных языках и напишем целый ряд публикаций на эту и смежные темы, а также продолжим делать наши модели лучше (например, еще в 2-5 раз быстрее).
Попробовать модель как обычно можно в нашем репозитории и в колабе.
Как попробовать
Для самых нетерпеливых — вот основные примеры звучания:
Update — баг с резким прерыванием речи на паузе уже пофиксили
Как обычно, все инструкции можно найти:
Вот самый минималистичный пример вызова модели:
import torch
device = torch.device('cpu')
torch.set_num_threads(4)
speaker = 'xenia' # 'aidar', 'baya', 'kseniya', 'xenia', 'random'
sample_rate = 48000 # 8000, 24000, 48000
model, example_text = torch.hub.load(repo_or_dir='snakers4/silero-models',
model='silero_tts',
language='ru',
speaker='ru_v3')
model.to(device)
audio = model.apply_tts(text=example_text,
speaker=speaker,
sample_rate=sample_rate)Спикеров и принимаемые символы для каждой модели можно посмотреть в свойствах модели model.speakers и model.symbols.
import os
import torch
device = torch.device('cpu')
torch.set_num_threads(4)
local_file = 'model.pt'
speaker = 'xenia' # 'aidar', 'baya', 'kseniya', 'xenia', 'random'
sample_rate = 48000 # 8000, 24000, 48000
if not os.path.isfile(local_file):
torch.hub.download_url_to_file('https://models.silero.ai/models/tts/ru/ru_v3.pt',
local_file)
model = torch.package.PackageImporter(local_file).load_pickle("tts_models", "model")
model.to(device)
audio = model.apply_tts(text=example_text,
speaker=speaker,
sample_rate=sample_rate)Как обычно, больше примеров вы можете найти по ссылкам в репозитории или в статье ниже. Все дальнешие примеры мы будем приводить без импортов для экономии места. С недавнего времени у моделей также появился своё pip-пакет, аналогичный по функционалу импорту через torch.hub.
Новые фишки и примеры аудио
Перечислим еще раз все нововведения вместе и более подробно пройдемся по каждому из них ниже с примерами:
- Снизили размер модели в 2 раза (ненарочно);
- Научили наши модели делать паузы;
- Добавили один высококачественный голос (и бесконечное число случайных);
- Ускорили наши модели где-то примерно в 10 раз (!);
- Упаковали всех спикеров одного языка в одну модель;
- Наши модели теперь могут принимать на вход даже целые абзацы текста;
- Добавили функции контроля скорости и высоты речи через SSML;
- Наш синтез работает сразу в трех частотах дискретизации на выбор — 8, 24 или 48 килогерц;
- Решили детские проблемы наших моделей: нестабильность и пропуск слов, и добавили флаги для контроля ударения;
Ускорение моделей в 10 раз
Тут особо нечего сказать, наши модели просто стали в 10 раз быстрее.
Скорость мы измеряем в секундах сгенерированного аудио в секунду, ограничивая число потоков в PyTorch (1 ядро = 2 потока) на процессоре Intel.
Так например, скорость V3 модели для 8 kHz в 50 секунд аудио в секунду означает, что аудио длиной в 5 секунд будет сгенерировано примерно за 100 ms.
| V1 модель | V1 модель | V3 модель | V3 модель | |
|---|---|---|---|---|
| 1 поток | 4 потока | 1 поток | 4 потока | |
| 8 kHz | 1.9 | 4.2 | 15 — 25 | 30 — 60 |
| 16 kHz | 1.4 | 3.1 | - | - |
| 24 kHz | - | - | 10 | 15 — 20 |
| 48 kHz | - | - | 5 | 10 |
Так как на CPU задержка и скорость напрямую зависят от длины генерируемого аудио, новые цифры указаны в виде интервалов. Скорость выходит на плато примерно на длительности аудио в 5 секунд. Задержка, понятно, линейно зависит от длины генерируемого аудио.
Тут интересно также посмотреть на задержку — её легко посчитать в уме, просто поделив нужную длину аудио на скорость. По ряду технических причин, наши модели теперь не принимают списки текстов и не работают с батчами.
В ближайшем будущем мы уже планируем (и самое главное — знаем как) ускорить модель еще в 2-5 раз. Также вышло снизить размер модели в 2 раза, но мы особо этим не занимались целенаправленно. Пока есть определенные проблемы с квантизацией и конвертацией в ONNX, но в теории минимальный возможный размер модели находится в районе 5-10 мегабайт. Вы всегда можете помочь нам профинансировать соответствующие исследования.
Пробуем разные высококачественные голоса
Тут также важно обратить внимание, что теперь все спикеры на одном языке будут жить внутри одной модели.
В этот раз мы готовы представить 4 высококачественных голоса, послушать можно по ссылке:
Для добавления нового голоса xenia нам потребовалось записать всего лишь 2 часа аудио, и это не предел.
...
speaker = 'xenia' # 'aidar', 'baya', 'kseniya', 'xenia', 'random'
...
audio = model.apply_tts(text=example_text,
speaker=speaker,
sample_rate=sample_rate)Синтезируем аудио разного качества
Мы можем синтезировать аудио с частотой дискретизации на выбор: 8, 24 или 48 килогерц. Предсказуемо, скорость работы моделей линейно меняется в зависимости от этого параметра.
...
sample_rate = 48000 # 8000, 24000, 48000
...
audio = model.apply_tts(text=example_text,
speaker=speaker,
sample_rate=sample_rate)Небольшая ремарка — качество модели для 8 килогерц сейчас не максимально возможное, мы это поправим при ускорении моделей.
Управляем речью и генерируем целые абзацы текста с помощью SSML
Раньше у моделей возникали проблемы при работе с текстами длиннее 140 символов — сейчас это ограничение снято. Также для удобства мы добавили поддержку самых важных SSML тегов:
| Тег | Пример тега | Возможные значения | Комментарий |
|---|---|---|---|
| Пауза | <break time="2000ms"/> |
5s, 500ms
|
Целое число секунд или миллисекунд |
| Скорость речи | <prosody rate="x-fast"> … </prosody> |
x-slow, slow, medium, fast, x-fast
|
rate и pitch можно комбинировать |
| Высота речи | <prosody pitch="x-high"> … </prosody> |
x-low, low, medium, high, x-high, robot
|
rate и pitch можно комбинировать |
| Предложение | <s> … </s> |
- | Эквивалентен точке |
| Абзац | <p> … </p> |
- | Эквивалентен длинной паузе |
Более подробную документацию по тегам можно найти тут.
Основные теги на примерах:
Update — баг с резким прерыванием речи на паузе уже пофиксили
ssml_sample = """
<speak>
<p>
Когда я просыпаюсь, <prosody rate="x-slow">я говорю довольно медленно</prosody>.
Потом я начинаю говорить своим обычным голосом,
<prosody pitch="x-high"> а могу говорить тоном выше </prosody>,
или <prosody pitch="x-low">наоборот, ниже</prosody>.
Потом, если повезет – <prosody rate="fast">я могу говорить и довольно быстро.</prosody>
А еще я умею делать паузы любой длины, например две секунды <break time="2000ms"/>.
<p>
Также я умею делать паузы между параграфами.
</p>
<p>
<s>И также я умею делать паузы между предложениями</s>
<s>Вот например как сейчас</s>
</p>
</p>
</speak>
"""
sample_rate = 48000
speaker = 'xenia'
audio = model.apply_tts(ssml_text=ssml_sample,
speaker=speaker,
sample_rate=sample_rate)Управляем ударением
Мы добавили возможность авторасстановки ударений ещё в прошлой версии, но в новом релизе стало доступно явно управлять флагами ударения и простановки буквы ё:
-
put_accent— флаг автоматической простановки ударения; -
put_yo— флаг автоматической простановки буквыё;
Вручную ударение, как и раньше, можно проставлять с помощью символа +.
Вот примеры — нет ударения вовсе, автоматическое ударение, автоматическое ударение + пара правок:
ssml_sample = """
<speak>
В недрах тундры выдры в гетрах тырят в ведрах ядра к+едров!
Выдрав с выдры в тундре гетры, вытру выдрой ядра к+едра.
Вытру гетрой выдре морду, +ядра - в в+ёдра, выдру в тундру.
</speak>
"""
sample_rate = 48000
speaker = 'aidar'
audio = model.apply_tts(ssml_text=ssml_sample,
speaker=speaker,
sample_rate=sample_rate,
put_accent=True,
put_yo=True)
display(Audio(audio, rate=sample_rate)) Единственная загвоздка состоит в том, что мы смогли добиться точности только в 80% в простановке ударения на омографах, и поэтому новая версия модели не вошла в этот релиз. Наша цель — точность на уровне 90-95%. Также в следующей версии мы увеличим словарь словоформ до 4 миллионов штук.
Дополнительные прикольные возможности
Среди дополнительных фишечек есть:
- Возможность говорить "как робот" (с помощью тега
prosodyсpitch="robot"); - Возможность генерации и сохранения бесконечного количества "случайных" спикеров;
- Возможность клонировать интонацию некой "модельной" фразы (в непубличной версии модели);
sample_rate = 48000
speaker = 'random'
audio = model.apply_tts(ssml_text=ssml_sample,
speaker=speaker,
sample_rate=sample_rate)
model.save_random_voice('test_voice.pt')
audio = model.apply_tts(ssml_text=ssml_sample,
speaker=speaker,
voice_path='test_voice.pt')Также можно послушать как работает перенос интонаций на известных и неизвестных спикерах:
Понятно, что можно сделать генеральную модель, которая бы хорошо работала на всем, но мы пока не ставили такой задачи.
Типичные проблемы публичных решений и индустрии
Часто после какой-то очередной пиар акции очередного инвестиционного стартапа, мне пишут люди, мол смотрите какие классные вещи люди делают.
На практике оказывается, что кто-то просто скопировал код самой модной статьи, прикрутил к нему CLI и теперь люди могут по-настоящему делать качественные, быстрые и демократичные модели!
В реальности такие решения долго тренируются, спроектированы на работу на карточках по типу RTX 3090 — A100 — V100 (то есть, имеющих более 16 GB VRAM) и уступают уже существующим решениям.
Вот недавно мы сравнивали новую модную модель VITS:
- В статье авторы пишут про инференс только на картах по типу V100;
- На практике на инфересе нужно более 16 GB VRAM для фраз нетривиальной длины (я не понимал зачем на инференсе такие карты до этого теста);
- Скорость уступает более простым решениям;
Самое печальное, что зачастую такие статьи написаны таким образом, чтобы нельзя было понять, какие элементы моделей на самом деле "тащат". Отчасти поэтому новые релизы занимают столько времени.
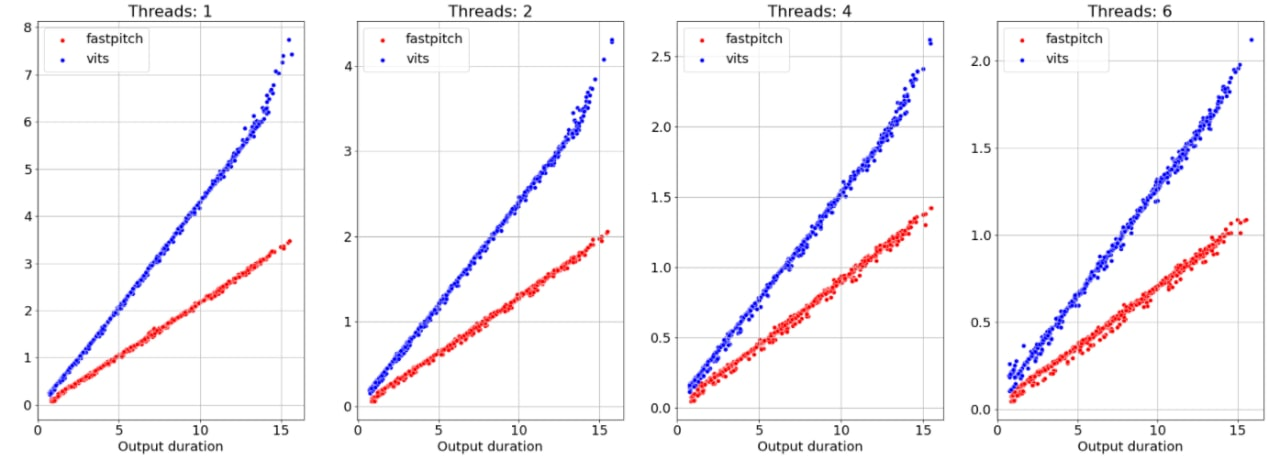
| Max VRAM, MB | |
|---|---|
| VITS | 16,301 |
| Fast Pitch | 3,215 |
Мы не преследуем идеологию перепродажи чужих наработок и воздуха инвесторам и поэтому мы делаем максимально простые, быстрые и максимально публичные компактные решения.
Дальнейшие планы
Мы не будем останавливаться на достигнутом, паниковать и следовать токсичным и самоуничижительным трендам.
Мы гордимся нашей командой и тем, что мы сделали по-настоящему уникальный продукт.
Мы верим, что только так мы все вместе можем бороться с игом корпораций, особенно иностранных.
Именно по синтезу, дальше мы планируем:
- Ускорить наш синтез еще в 2-5 раз;
- Прикрутить квантизацию и ONNX и тем самым возможно ускорить синтез еще в 2-4 раза;
- Добавить возможность использовать фонемы напрямую для синтеза для произношения сложных слов и аббревиатур;
- Довести до конца работу по автоматической простановке ударения в предложениях с омографами и достичь точности в 90-95% на омографах;
- Обновить модели для имеющихся у нас языков СНГ (если вы хотите записать какие-то новые — добро пожаловать), включая украинский;
- Обновить модели для английского и основных европейских языков (мы пока не решили каких именно);
- Сделать модель для индийских языков;
- И есть еще пара секретных фановых мини проектов, о которых я не буду вам рассказывать =);
- Нам и так потребовалась буквально пара часов для добавления нового высококачественного голоса и мы уже можем генерировать бесконечные случайные голоса. Возможно мы снизим штатное количество аудио для добавления нового высококачественного голоса до нескольких минут вместе с возможностью использования фонем;
Комментарии (75)

vagon333
12.04.2022 21:52+3Качественный TTS. Поздравляю.
Пробовал свой текст.
Числа не обрабатываются:
18 мая -> "мая"
2022 года -> "года"
snakers4 Автор
12.04.2022 21:55+2Да, а мы специально и не обрабатываем их.
Как мне кажется всякие подобные "middleware" не должны быть частью публичного движка для синтеза и должны настраиваться под конкретную задачу отдельно.
Понятно, что в целом решить задачу нормализации любого текста очень сложно, но в SSML есть рудиментарные теги, которые сильно проще сделать, но люди скорее всего не захотят заморачиваться, все в идеале должно работать "само".

sebres
13.04.2022 15:38+5А тут на самом деле не просто всё. Как в общем случае отличить количественные, порядковые, собирательные, те же рода и единственное/множественное и т.п.
Не говоря уж про всякие зависимости окончания от одушевлённости/неодушевлённости...Ну и без контекстного фильтра, и/или семантических и морфологических моделей сложностей хватает, к примеру - "
17 года" - это "семнадцатые года́" или "семнадцатого гóда"?Я как-то игрался с такими преобразованиями (и чисто алгоритмически и на ML) в контексте предложения, где-то лежит для русского в том числе, если найду выложу и кину ссылку.

janvarev
13.04.2022 16:19Если найдёте, киньте, пожалуйста.
snakers4 Автор
14.04.2022 08:29В общем случае все равно будут компромиссы. И количество усилий для решения этой задачи на 99% нетривиально. И с коммерческой точки зрения - пока не совсем ясно зачем это нужно, т.к. шаблоны можно в бизнесе любые заранее создать.
janvarev
12.04.2022 23:16+10Спасибо! Генерация стала еще качественней с прошлого релиза, особенно 48 000 вообще чума :)
Уже прикрутил к своему голосовому помощнику Ирине (плагин tts_silero_v3, залил минут 15 назад). Надо сказать, что v2 на моей машине генерировал результат с заметной задержкой, а вот v3 работает практически без задержки (правда, пришлось снизить частоту до 24 000).snakers4 Автор
13.04.2022 08:25+7Нативная частота в 48 kHz - это отчасти китч, отчасти просто публикация некоторых коммерческих фич, отчасти месседж (как вы поняли, это не просто ресемплинг для галочки).
В хороших наушниках разница между 24 и 48 конечно слышна, а так на самом деле конечно меньше.
Насчет задержки - модели реально стали в 10 раз быстрее, и это еще без квантизации и ONNX. И самое главное - мы знаем как сделать еще в 2-4 раза быстрее без потери качества.
Когда руки дойдут до ONNX, квантизации и дистилляции - будет еще 2-4 раза поверх. Но пока надо сделать релизы других языков и дистрибутивов.

napa3um
12.04.2022 23:45+3Очень, очень хорошо. И опасно реалистично :).
snakers4 Автор
13.04.2022 08:33+3Новый голос
xeniaпотребовал всего 2 часа записей. Понятно, что тут главное знать как записывать, но я допускаю, что в какой-то момент станет нужно буквально 5-15 минут для голоса такого же качества какxeniaА насчет опасности - я пытался подробно описать почему ее на самом деле нет в этой статье (ищем Существует ли массовая опасность со стороны "ИИ"). Основной аргумент - shit in - shit out. И на массе все-таки сильно проще применять социальный инжиниринг. Для таргетирования high net worth целей - уже даже наши технологии позволяют это делать, но геморрой.
В "zero shot" я не особо верю, ну или качество будет посредственное, или кост вычислений высокий.
napa3um
13.04.2022 19:28Дешёвое масштабирование перекрывает низкое качество, тупо один на тысячу повёлся - уже доход, который можно нелинейно умножать количеством серверов :).
Но ваши аргументы я тоже понимаю, да.
snakers4 Автор
14.04.2022 08:32Не уверен, что служба поддержки "Сбербанка" (которая явно переключилась на генерацию фейков по мотивам последних событий - звонки лично мне прекратились) и просто говенные СМС бабулькам типа "сынок помоги" не являются лучшей сетью.
А для богатых целей - можно и наверное проще применить специально обученных биороботов.

ximik666
12.04.2022 23:49+1Отличное качество. Насколько требователен к железу для работы в "реальном времени"? Хотим прикрутить автоответ на "голосовухи" в чате, а сам бот-автоответчик крутится в виртуалке.

Daddy_Cool
13.04.2022 00:53+2Автоответ это посылание далеко?
Боты автоответчики бесят.ximik666
13.04.2022 06:51+1В данном случае автоответ - сообщение о том, что голосовые сообщения запрещены, но уже не текстом, а приятным женским голосом).
janvarev
13.04.2022 08:30+3Возможно, тогда имеет смысл один раз записать WAV-файл, а затем его отправлять — не очень видно, зачем тут нужна генерация.

putnik
13.04.2022 18:27+1Если вы готовы так заморачиваться, то может лучше сделать распознавание голосовух ботом, а не генерацию сообщения о запрете?
snakers4 Автор
13.04.2022 08:38+2Насчет требовательности и скорости, сокращенно процитирую часть статьи.
На 1 или 4 потоках (2 ядра) современного процессора Intel c AVX2 инструкциями (95% процессоров выпускаемых последние лет 5-7) показатели скорости такие:
| | V3 модель | V3 модель | |-----------|-----------|-----------| | | 1 поток | 4 потока | | 8 kHz | 15 — 25 | 30 — 60 | | 16 kHz | - | - | | 24 kHz | 10 | 15 — 20 | | 48 kHz | 5 | 10 |На GPU (не помню, будет ли запускаться публичная модель на ней) - должно быть еще в ~10 раз быстрее.
На AMD будет хуже. На ARM или RISC V не тестировали. Наверное это решит ONNX, но пока ресурсов инвестировать в это нет.
Будет релиз еще с ускорением в 2-4 раза, потом еще релиз с ускорением в 2-4. Когда - как обычно КТТС / when it's done.
janvarev
13.04.2022 12:29+1У меня, кстати, странный опыт — публичная модель вполне запустилась на device('cuda'), но генерация стала даже немного медленнее. Возможно, дело в том, что старт дольше + у меня маленькие тексты, на которых не заметно разницы. Но тем не менее.
PS: Буду ждать релиза с ускорением :)snakers4 Автор
13.04.2022 12:32+1Иногда модели при первом запуске "тупят". Попробуйте несколько раз, на текстах разной длины.
Вообще если честно мы эту модель даже не тестировали на видеокартах, т.к. скорее основная цель была сделать быстрый и нетребовательный синтез.

vvzvlad
13.04.2022 00:52+8Вручную ударение, как и раньше, можно проставлять с помощью символа + перед ударной гласной.
Кошмар, кто в лес, кто по дрова.
Тинькофф: Для управления ударениями достаточно добавить 0 после ударной гласной: «соро0ка» и «сорока0».
speechpro: stress=«позиция ударения» (указание места ударения посредством сообщения номера ударной гласной от начала слова.)
Сбер: поставьте ударение в слове на ударный слог с буквой «е», используя апостроф — '. Обратите внимание, что апостроф ставится после ударной буквы.
aimyvoice: Указывает порядковый номер ударной гласной в слове. Чтобы обозначить ударение в слове, при передаче текста вы также можете использовать + после ударной гласной.
Google TTS умеет в юникодные знаки ударения: «они произносят иначе „кóторый“ и „котóрый“ „
Мне видится наиболее логичным использование тега для отдельной буквы (указывать номер тоже можно, но как-то криво). При использовании тега он не будет прорываться в обычный текст, и текст можно будет использовать в других местах. Либо юникодный символ, который специально для этого и сделан.snakers4 Автор
13.04.2022 09:07+7Позволю себе поиронизировать над тем, что сравнивается работающий на 1 потоке процессора бесплатный релиз синтеза, по качеству не уступающий или даже превосходящий решения корпораций и олигархов, с закрытыми продуктами, в которые вбухали на пару порядков больше бабла (причем как иногда в случае со Сбером и частично с ЦРТ - взятого из нашего с вами кармана без нашего согласия) и которые крутятся на корпоративных "суперкомпьютерах". Я думаю, что Яндекс только диктору заплатил больше, чем весь наш бюджет на разработку =)
Но если отложить демагогию в сторону, то давайте попробуем разложить это все по полочкам:
(0) Интерфейс простановки ударения
Указывать позицию ударения и чтение в виде очень verbose тега - кажется как минимум неуважением к пользователю. Нам очень не нравится XML и SSML, но скрепя сердце, мы не нашли лучшей альтернативы.
Но для указания ударения добавлять тег на каждое слово - ну такое (разве что так корпорациям будет проще майнить разметку из ваших данных xD ).
То же самое касается и юникод символов с ударением. С фонемами еще это имеет смысл (их много, они сложные и редкие, явно нужны для особых случаев), но юзеры проклянут такие символы, банально потому что на клавиатуре их нет. Решения с плюсами и апострофами кажутся гораздо более простыми и лаконичными. Почему мы взяли плюс - он не встречается ни в каком языке. Почему до буквы - честно говоря я даже не вспомню.
По этой же логике мы не стали впиливать вещи типа наивной интерпретации типа
say-asилиsub, потому что многие такие вещи проще сделать на стороне пользователя и мое личное мнение - они служат только целям сборки разметки.Все должно работать или само - или быть максимально минималистичным.
(1) Упоминание словарей и автоматической расстановки ударений
Нигде не нашел явного упоминания, какая точность расстановки ударений и точность учета контекста ни у кого. У ЦРТ написано что-то про словарь, но ни слова про его размер и как разрешаются омографы.
Готов предположить - все или плохо или просто никто не измеряет. Хотя если бы точность была 99%, никто бы не давал возможность править руками.
(2) Вычислительные мощности
Нигде нет никакой информации, как АПИ разрешающие омографы работают и какие там модели или инструменты используются. Если судить по публикации Яндекса на Хабре - там огромные языковые модели. Как по мне, это далековато от народа.
Ну и еще раз повторю свой посыл, что большая часть этих решений и близко не будут работать на 1 потоке процессора.

AigizK
13.04.2022 08:30+3Круто, поздравляю! Перенос интонации вообще тема, особенно с рандомными голосами.
А можно ли в перспективе рандомный голос генерить, который похож на указанный? Причем, чтоб указанный голос был носителем другого языка?
snakers4 Автор
13.04.2022 09:12А можно ли в перспективе рандомный голос генерить, который похож на указанный? Причем, чтоб указанный голос был носителем другого языка?
Да, это и есть voice transfer. Хотя мы на это скорее смотрим как на снижение количества аудио для качественного голоса. В zero shot трансфер я не верю.
Не думаю, что в скором времени это будет частью публичных релизов. В качестве экспериментов это все уже работает, но особой ценности или коммерческого смысла я пока не вижу, если конечно нужен качественный синтез.
Насчет большого числа языков в рамках одной модели - все это в принципе уже прекрасно работает, надо только финально решить вопрос фонем.AigizK
13.04.2022 09:54+3Я тут рассматриваю с точки зрения перевода мультиков. Как раз 2 проблемы там:
В переводе голос чтоб был похож на оригинал
Читать надо с интонацией
Второй пункт уже решен, достаточно самому прочитать с нужной интонацией и натравить синтезатор. Первый то же можно решить, нагенерив много голосов и подобрав похожий. Но можно ли сразу генерить, чтоб не перебирать варианты?

kryvichh
13.04.2022 09:10+1Мощно! Вашу команду купить уже не предлагали? Чтобы затем разработки закрыть и коммерциализировать.
snakers4 Автор
13.04.2022 09:18+9Купить естественно предлагали, но очень странные люди при странных обстоятельствах и со странными целями за странное количество денег xD Тут даже не булочка и трамвайчик, а скорее рваный носок, пакет от мусора и большая честь.
Не думаю, что наша идеология в принципе может сочетаться с "закрыть и коммерциализировать", если конечно нам не начнут ломать ноги.
А насчет коммерциализации - ну мы пока вроде сами справляемся с этим. Хотелось бы конечно, чтобы денег было больше, но полагаю, что это "налог на суверенитет".

DjPhoeniX
13.04.2022 09:16+1Звучит действительно хорошо, но синтез таки опознаётся - местами отдаёт характерным автотюном. Если попытаться этот эффект убрать - будет ещё более реалистично.
snakers4 Автор
13.04.2022 09:23Ну это неизбежно. А можете указать, на каком примере или тексте? Еще повторяется? Там в статье еще некоторые примеры были от предфинальных версий модели.

artemerschow
13.04.2022 09:51+1Не про автотюн, но когда проставляете паузы, то слишком резко обрубается голос. Паузы между предложениями затухают более естественно.
UPD. запустил на колабе — затухает уже нормально, не как в примерах.snakers4 Автор
13.04.2022 10:02+3А это кажется уже пофиксили. Мне просто было лень генерить все фразы заново. Я просто вчерашний билд использовал.
Проверьте на вашем примере, уже не должно быть.
Я проверил только что, эффект гораздо менее заметен. Я обновлю в статье.
artemerschow
13.04.2022 10:04+2Одновременно с вами свой коммент исправил :)
Да, сейчас вообще не заметно.snakers4 Автор
13.04.2022 10:07+3Да, спасибо за внимательность. Я думал народ не заметит и поленился при последней вычитке обновить, но народ заметил. Но я уже вставил "опровержение" в нужные места статьи, в плейлисте не нашел как аудио заменит.
Зато лишняя движуха под статьей, почему нет.

Mingun
13.04.2022 18:17+1У меня почему-то здесь просто тишина, хотя все остальные нормально проигрываются. И да, в некоторых таки заметно, что это синтез (характерный скрежет в речи) — в рандомных голосах, например.
snakers4 Автор
13.04.2022 18:26У меня почему-то при запуске аудио вкладка в браузере его выключает.
Mingun
13.04.2022 20:01+1Наверное, это глюк на серверах SoundCloud. Сейчас уже звук слышен. Браузер точно не отключал вкладку, потому что я для проверки запускал проблемный звук и он молчал, а до него и после — соседние семплы в статье, и они звучали


ColdPhoenix
13.04.2022 11:28+1Есть ли возможность использовать вне питона?
Иначе придётся генерировать какой-то сервис на питона, чтоб потом его использовать в другом проекте(конкретно интересует .Net Core)
snakers4 Автор
13.04.2022 11:51+2Бесплатные модели - скорее всего нет, банально у нас нет специалистов на шарпах. Мы подумали про ONNX, но наверное в него будем упаковывать только базовые модели без доп. функционала (просто предложения).
Если у вас
.Net, то скорее всего за этим стоит платежеспособный бизнес. А если так, то вы всегда можете купить у нас лицензию на наши коммерческие модели и обвязку вокруг них, чтобы дергать через АПИ. Ну или мы можем обсудить разработку или упаковку какого-то кастома.ColdPhoenix
13.04.2022 13:39За этим стоит физ лицо, с основным языком C# =D
Но спасибо за ответ, пока просто собираю информацию по тому что может быть полезно, о коммерции пока даже речи нет.
AigizK
13.04.2022 21:34можете написать маленький питон скрипт, который запускает модель, а потом начинает мониторить stdin.
А ваш c# код запускает этот скрипт как субпроцесс и отправляет в его stdin и ждет ответ от stdout
это самый простой рабочий способ запустить питон
DjPhoeniX
14.04.2022 00:33Чуть менее простой и чуть более рабочий - заимплементить обёртку вокруг необходимого кода и подключить CPython к основному проекту.
janvarev
13.04.2022 12:26-2(del)
snakers4 Автор
13.04.2022 12:30+3Все нужные шаги по пакетированию уже сделаны в наших коммерческих дистрибутивах. У всех наших публичных моделей некоммерческая лицензия.
Если нужно использовать для коммерческих целей - то нужно договариваться с авторами.
Я не против рекламы настоящих FOSS проектов, но вы уже как-то слишком активно пиаритесь под каждой второй веткой.

Islanna
13.04.2022 12:44+2Не совсем понимаю, зачем тащить за собой ещё миллион обёрток, если авторы уже всё завернули в пакет.


SnakeSolid
13.04.2022 13:50+2Возможно я что-то упустил, но похоже, что новая модель работает только с Русским языком. Возможен ли синтез речи для текстов содержащих одновременно русский и английский языки в одном предложении, например текст "java-разработчик"?
snakers4 Автор
13.04.2022 14:07+2Есть несколько способов решения этой задачи:
(0) Заменить текст на английском текстом на русском, т.е. сделать транскрипцию. Благо у нас довольно "фонетический" язык. Думаю это можно для простых случаев это самое оно.
(1) Сделать модель, которая бы опционально работала с фонемами. Это по сути просто прошлый пункт на максималках. Просто чуть более точно можно произносить слова.
(2) Сделать модель, которая бы озвучивала фонемы разным образом, в зависимости от метки языка, например.
Вот есть примеры (1 2) как это может звучать, на базовом и продвинутом уровне. Но тут опять же фонемы, и явная польза только будет, если вы хотите прямо "говорить" на другом языке.(2) скорее всего мы всегда будем держать для платящих клиентов, (1) возможно когда-то мигрирует в паблик, а (0) делается простыми методами от ситуации.
Какие-то middleware для транслитерации мы естественно у себя не держим по очевидным причинам.

Xambey97
13.04.2022 16:23+1Спасибо за статью! Ждем «Воскрешение» голоса Владимира Вольфовича
snakers4 Автор
13.04.2022 16:25Мы пробовали делать его голос еще год назад. В целом - качество публичного аудио не очень и очень много эмоций.
Но у нас есть другие идеи, какие поздравления сделать. Модели, скорее всего выкладывать не будем.

Lecron
14.04.2022 08:20Поищите возможность выделить установку ударений в отдельный модуль или какой-либо опцией сделать возможным вывод размеченного текста из существующей модели (без синтеза речи). Полезно для составления/генерации корректирующих пользовательских словарей. И даже для разметки текста с последующей озвучкой другим движком.
Существует немало синтетических имен собственных из различных книжек, обычно фантастики. Где-то уникальные, где-то повторяющиеся, особенно внутри цикла произведений. Сюда можно добавить устаревшие слова или слова некоей предметной области. У часто пользующихся синтезом уже сформирован свой словарь, у особо замороченных сформированы эпические словари ударений. Любой движок дает ошибки. Которые хотелось бы быстро найти и использовать небольшие корректирующие словари конкретно для вашей модели. Также полезно при обновлениях модели. В новой версии могут исправится одни ошибки и появится другие.
snakers4 Автор
14.04.2022 08:28Поищите возможность выделить установку ударений в отдельный модуль или какой-либо опцией сделать возможным вывод размеченного текста из существующей модели (без синтеза речи).
Таких планов у нас точно нет. Мы вложили очень много усилий конкретно в этот модуль (и в его максимально возможную обфускацию без ущерба функционалу), и у нас довольно мало желания делиться с корпорациями и олигархами нашими наработками бесплатно и без боя.
Мы думали в сторону полной обфускации модулей, но там беда в том, что бинари создаются на конкретную версию питона, и это бы вызвало шквал сложностей и обычных пользователей.
Существует немало синтетических имен собственных из различных книжек, обычно фантастики. Где-то уникальные, где-то повторяющиеся, особенно внутри цикла произведений. Сюда можно добавить устаревшие слова или слова некоей предметной области.
Во-первых, "длинные", русские, греческие и латинские слова модель и так часто нормально понимает, даже если их не было в словаре, основная проблема сейчас в омографах.
Во-вторых, не совсем понимаю, почему если у вас есть словарь вы просто не делаете по нему замены автоматически, модель это поддерживает. Качество от того, что вы разметите пару слов, которые модель уже знает, качество не изменится.
Lecron
14.04.2022 10:05почему если у вас есть словарь вы просто не делаете по нему замены автоматически, модель это поддерживает. Качество от того, что вы разметите пару слов, которые модель уже знает, качество не изменится.Возможно вы не верно поняли цель. Речь не о "разметить", и даже не о "что размечать", а что "не размечать". Опишу свой процесс. В Балаболке есть "поиск имен". Они прослушиваются, где есть ошибка вносятся в словарь, где нет, вносятся в список прослушанных слов, которые при следующем поиске удаляются из списка. За годы использования TTS прослушано ~100к имен и создан словарь на ~15к записей.
При переходе на ваш движок (спасибо, круто), придется все это дропнуть и начать прослушивание заново. И главное, это придется делать с нуля при каждом обновлении проекта. Если сегодня Александар, Наруто Узумаки или Кецалькоатль произносятся верно, не значит что это будет верно завтра.
Поэтому нужна возможность быстро узнать, где движок поставит ударение. Так же не понял, что может грозить вашему алгоритму. Нужен ведь не он, а результат. Причем не для общеизвестных слов и имен, которые нетрудно собрать из сети (зализняк, wiktionary и пр), а именно для редких и специфичных, ударения которых все равно нельзя использовать без предварительного контроля глазами. То есть никакой автоматизации сторонних проектов, а лишь работа с вашим.
snakers4 Автор
14.04.2022 10:19За годы использования TTS прослушано ~100к имен и создан словарь на ~15к записей.
При переходе на ваш движок (спасибо, круто), придется все это дропнуть и начать прослушивание заново. И главное, это придется делать с нуля при каждом обновлении проекта. Если сегодня Александар, Наруто Узумаки или Кецалькоатль произносятся верно, не значит что это будет верно завтра.
Не совсем вижу проблему. У вас есть ~15к "сложных" или "особенных" слов (вероятно в основном имена собственные), которые или совсем особенные или которые балаболка плохо принимала.
Вы можете просто применять их как словарь ДО отправки в нашу модель (там как есть флаги расстановки ударения, так и можно просто ставить ударение самому) и ставить ударение. Если вы слышите ошибку - точно так же дополняете словарь. Процесс не меняется вообще никак.
Если вы разметили "лишнее" слово - разницы никакой, модель его произнесет как вы указали. Если какие-то слова наши алгоритмы размечают не так - просто вносите в словарь. Омографы пока лучше все равно размечать самому. Возможно словари даже не разойдутся, потому что разметить "лишнее" слово - это не проблема.
И главное, это придется делать с нуля при каждом обновлении проекта.
Это тоже маловероятно, т.к. модели мы будем обновлять только при росте метрик. Возможно, что какие-то редкие слова не из вашего списка "сломаются" при обновлении, но это будет условно 1 слово на тысячу, и скорее всего никто не заметит, или оно будет внесено в словарь.
Я бы конечно вел два словаря - имена собственные и "обычные" слова, которые модель портит, но суть мало меняется от этого.
Lecron
14.04.2022 10:44Решения принимались лично, Балаболка только интерфейс.
Да, эти 15к можно использовать по прежнему, хотя конечно хотелось бы избежать лишней вычислительной сложности, если ваша расстановка ударений лучше. Вопрос в том, что делать с 100к имен, который прошлый движок произносил верно? Пример с Александар и Узумаки как раз из этого списка. Если и для них извлечь ударения и создать словарь на 115к, а потом туда добавить еще словари обычных слов специфичные для прошлого движка, еще 100к слов, то так и до собственного движка ударений можно дойти :)
Еще раз повторю, дело не в словарях, а в быстром определении слов "которые модель портит" при наличии эталонного значения ударения, то есть слов, для которых этот словарь нужен.
snakers4 Автор
14.04.2022 10:55еще 100к слов, то так и до собственного движка ударений можно дойти :)
Для полноценного собственного движка ударений нужно на два порядка больше слов + решение вопроса с омографами.
Вопрос в том, что делать с 100к имен, который прошлый движок произносил верно?
Еще раз повторю, дело не в словарях, а в быстром определении слов "которые модель портит" при наличии эталонного значения ударения, то есть слов, для которых этот словарь нужен.
Если у вас есть "эталонное" ударение для этих 100к слов, то опять же в чем вопрос? Просто добавьте их в свой словарь и все. Модель не обидится, если вы дадите ей лишнее ударение.
Публично выкладывать, даже неявно, свои словари даже опосредованным способом мы очевидно не очень заинтересованы.
Пример с Александар и Узумаки как раз из этого списка.
Звучит будто бы вы занимаетесь озвучкой аниме. Не готов гуглить, но раньше это было довольно прибыльным рекламным бизнесом (помню как моя компания на тот момент, Ponominalu, даже давала партизанскую рекламу в озвучках сериалов на 50-100к в месяц).
Возможно рынок поменялся, но вам явно нужна коммерческая поддержка моделей, т.к. даже судя по объемам словарей это не похоже на какую-то благотворительность.
Соответственно именно с аниме можно придумать миллион премиум фич не считая озвучки - например говорить голосом, похожим на персонажа конкретного аниме - это самое очевидное, что приходит в голову. Ну или говорить по-русски с японским акцентом голосами персонажей из аниме.
Lecron
14.04.2022 11:05Спасибо за общение. Нет, так нет. Но это не коммерция. Реально много слушаю, причем больше 10 лет без смены движка, вот и собралось.
snakers4 Автор
14.04.2022 12:03Если вы напишите к нам в личку, мы поможем решить вопрос с разметкой, если конечно он не решается вышеописанными методами.
В паблик точно выкладывать не будем наши словари.
Lecron
14.04.2022 12:33По поводу словарей. Это ваше решение, но предлагаю взглянуть на вопрос еще раз.
Существуют публичные словари Зализняка (плюс извеcтный в кругах любителей TTS основанный на нем orfoepic) и дамп Викисловаря. Это миллионы словоформ с большой избыточностью. Чтобы ее сократить, проводил исследование частотности использования слов.
Проверено ~10к книг разных жанров и времен, включая классику, русскую и переводы зарубежной.
Найдено ~1.9м словоформ требующих ударения, с ~400м вхождений.
Из них в публичных словарях найдено ~1м словоформ, с ~375м вхождений.
Покрытие словарями 95%Не знаю насколько более полон ваш словарь, пусть будет предельные 5%, но отсюда вопрос: я их недооцениваю или вы переоцениваете скрывая? Речь не об омографах, для которых нужен контекст и с которыми хорошо справляется проект Natasha (есть на Хабре). Только об обычных словах. Для которых API будет принимать только одиночные вхождения.
По поводу лички. Спасибо, но откажусь. Не люблю использовать привилегированный доступ в некритичных вопросах.
snakers4 Автор
14.04.2022 12:50Речь не об омографах, для которых нужен контекст и с которыми хорошо справляется проект Natasha (есть на Хабре)
Мы не можем засунуть Наташу к себе внутрь сетки (точнее в пакет можем, но это идеологически неверно, плюс у Наташи тоже точность будет в районе 85-90%), но омографы решить все-таки можем.
Если я верно понял вопрос, словоформ у нас уже в разы больше.Lecron
14.04.2022 13:33И не надо засовывать. Это отдельный проект, используется как мидлваре. Лишь намек, что и уникальность разрешения омографов не столь велика. Точность Наташи зависит от частотности. Все/всё и чем/чём больше 98%. А для нечасто употребляемых слов, может вообще заклинить в одном положении — в уже` или ду`шу. Еще сами с столкнетесь. Но тут частотность тоже позволяет утверждать хорошую достоверность. Одно у`же встречается на 500+ уже`.
По словоформам, это лишь реально встреченные в тексте. Оценка важности, а не количества. Количество же в исходных публичных словарях уже не помню, но мнооооого.
Есть ощущение что у вас замылился взгляд с позиции разработчика. Кажется что пользователи смогут вытащить из результата работы модели ваши наработки. В реальности, для них все ударения потенциально недостоверные. Без ручного контроля восстановить не выйдет. А ручной контроль можно сделать и на других предикторах. Поэтому, в первую очередь, это нужно для улучшения работы пользователей с вашей же моделью. "Вредоносное" использование даже представить не могу.
snakers4 Автор
14.04.2022 13:50Я все еще не понимаю, в чем претензия.
Хотите - ставьте все ударения самостоятельно и ставьте флаг False. Хотите - правьте только отдельные слова.
Наша задача сделать инструмент, который бы покрывал все основные кейсы работы юзеров, не имел внешних зависимостей и работал в 90 - 95 - 99% случаев без участия пользователя.
Я сильно сомневаюсь, что точность синтаксических парсеров приближается к 98%.
Lecron
14.04.2022 15:00Ни в коем случае не претензия. Омографы были затронуты вскользь и не являются предметом обсуждения. Только слова с постоянным ударением и попытка убедить, что отдача предсказанной позиции ударения вреда коммерции не принесет. Невозможно составить достоверный словарь ударений по прогнозам, только сравнить с уже существующим эталоном. Что облегчит генерацию корректирующих словарей конкретно под движок. Облегчит, а не даст возможность. Новые слова, как и прежде для SAPI движков, будут добавляться путем прослушивания.

delvin-fil
14.04.2022 15:19Звук сгенерированный RHVoice распознает процентов на 90. Голос "Елена", скорость 80.
А вот живой голос слабо. Пример:

snakers4 Автор
14.04.2022 15:30Еще бы понять, какое это имеет отношение к этой статье, но наше распознавание распознает получше, но жует слово знамя:
delvin-fil
14.04.2022 16:00Еще бы понять, какое это имеет отношение к этой статье
Я Вас понял. О статье. Но ведь не даром у вас на гите лежат скипты распознавания.
Генерю(пока) RHVoice, но планирую тщательно исследовать Ваш движок. На выходных.
За статьи - СПАСИБО!


nlinker
Потрясающе! Сэмплы ну прям сочно звучат!
snakers4 Автор
Спасибо! Там, где не указано иное, аудио в 48 kHz.