
Всем привет, Хабр. Меня зовут Сергей, в Selectel я работаю в департаменте IaaS-продуктов и отвечаю за выделенные серверы, которые мы сдаем в аренду. Число клиентов растет каждый год — вместе с ними растет потребность в новых серверах и комплектующих. Чем больше становится оборудования, тем сложнее контролировать его наличие на складе и вовремя планировать новые поставки. Но это часть моей работы.
Чтобы облегчить эту задачу, я, не программист, написал скрипт, который стал дополнительным инструментом управления постоянно меняющимися цифрами наличия комплектующих. Об этом скрипте и о том, как мы анализируем число оборудования на складе, пишу под катом.
Для начала поясню, как я дошел до написания скриптов. До Selectel я более 6 лет работал в международной торговой компании. В числе моих задач была аналитика показателей филиала и рынка региона в целом. Инструментом анализа данных о складе и продажах были OLAP-кубы и Excel.
В какой-то момент возможностей этой системы уже не хватало, и я познакомился с библиотекой Pandas, открыв для себя возможности Python для анализа данных. Думаю, дата-аналитики подтвердят, что на сегодняшний день это универсальный и эффективный инструмент.
Полученные знания я решил применить и в Selectel.
Немного контекста
Мы в Selectel сами собираем серверы. То есть не получаем собранные вендорами машины в коробочке, а закупаем так называемую «рассыпуху» — комплектующие серверов от процессоров до карт памяти, дисков и так далее. Это более выгодное и гибкое решение: мы не ограничены в возможных конфигурациях и можем предоставлять как фиксированные, так и кастомные сборки.
Чтобы поддерживать рост компании, необходимо регулярно закупать новое железо для выделенных серверов, но и не забывать о том, что уже куплено, но не сдано клиентам. Для анализа таких данных мы используем несколько BI- и ERP-систем. С их помощью получаем информацию о расходе комплектующих, остатках на складе, свободных серверах фиксированных конфигураций и арендованных серверах.
Однако возможностей систем аналитики не всегда достаточно. В таких случаях приходится лезть в БД и обрабатывать «сырые» данные. В случае, если такие данные необходимы регулярно, аналитика автоматизируется.
Почему понадобился скрипт
2021 год был ознаменован кризисом полупроводников, и это отразилось на регулярности поставок оборудования. Чаще стали возникать ситуации, когда отдельные детали задерживаются и собрать конкретную конфигурацию сервера невозможно. При этом остальное железо лежит на складе и снижает показатели оборачиваемости.
Подвидов комплектующих и вариаций их использования очень много. По очень грубым подсчетам в конфигураторе серверов можно собрать несколько тысяч серверов в разных вариациях (при наличии всех комплектующих на складе).
На сегодняшний день в арсенале выделенных серверов более пяти линеек актуальных процессоров: Intel® Xeon® Scalable 3rd, AMD EPYC™ 7003, Intel® Xeon® W, Intel® Xeon® E, десктопный сегмент. Менее «свежее» железо также доступно к заказу — начиная от предыдущих поколений масштабируемых процессоров Intel® Xeon® Scalable и AMD EPYC™ и заканчивая Intel® Xeon® E3. Под разные модели процессоров применяются совместимые материнские платы, может отличаться тип оперативной памяти. Также, например, на запасы на складе влияет возможность использования масштабируемых процессоров в материнских платах с разным количеством сокетов и их распределения относительно друг друга. Все это усложняет управление заказами и остатками комплектующих на складе.
При очередном планировании возник вопрос, какое максимальное число готовых серверов мы можем собрать прямо сейчас из имеющихся на складе комплектующих всех поколений? Какое железо остается и что является блокером для его использования?
Готового отчета с ответами не было, но ручную выгрузку никто не отменял. С помощью Excel и данных по остаткам на складах я определил соответствие процессоров и материнских плат, просуммировав по семействам, и рассчитал, сколько серверов и с каким объемом памяти мы можем собрать. На расчеты потратил несколько часов и решил, что подход интересный — стоит пользоваться им чаще.
Для автоматизации отчетов с данными в Selectel можно обратиться к сотрудникам департамента аналитики. Они могут делать сложносочиненные дашборды, которые подтягивают данные десятков источников. Для этого нужно сформулировать задачу, цель дашборда, обсудить нюансы с коллегами и запустить в работу.
На этапе формулирования задачи BI-специалистам мне стало понятно, что требования к отчету не очевидны и мне нужно протестировать детали на уровне заказчика. Python для этого подходит лучше, чем Excel, так как позволяет загрузить входящие данные и обработать их скриптом, быстро внести необходимые правки и изменения. Я решил создать прототип отчета с помощью библиотеки Pandas и проверить, как и с какими данными он будет работать. И уже после этого поставить задачу департаменту аналитики.
Верхнеуровнево в создаваемом отчете было достаточно расчетов по количеству процессоров, совместимых материнских плат и оперативной памяти. Я решил начать с этих компонентов, но впоследствии прибавил к ним корпусы и дополнительные сетевые карты.
Создание скрипта
Дисклеймер 1. Все данные, продемонстрированные далее, получены с помощью функции random на входе и не отражают реальные запасы компании, так как такие данные относятся к коммерческой тайне.
Дисклеймер 2. Также напомню, что я не программист, а категорийный менеджер. Скрипт я написал, чтобы проверить гипотезу о том, насколько полезен был бы такой отчет. Это MVP, главная задача которого — просто работать. А значит, код может быть неидеальным. Но если вы знаете, как его улучшить, поделитесь в комментариях, будет интересно.
Входящие данные
На входе в отчет используется файл Excel со следующими данными:
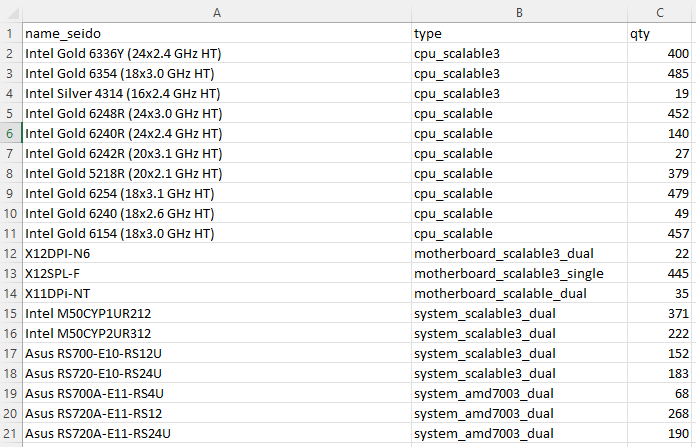
Наименование (name_seido) и количество комплектующих (qty) выгружаются из учетной системы, столбец type прописывается вручную и содержит в себе тип, семейство комплектующей и количество сокетов для материнских плат. Также доступна выгрузка в Google Sheets, откуда впоследствии можно загрузить датасет в Jupyter Notebook.
После загрузки данных файла в датасет на основе столбца type создаются соответствующие столбцы:

data['device'] = data['type'].str.split('_', 1).str[0]
data['family'] = data['type'].str.split('_', 2).str[1]
data['socket'] = data['type'].str.split('_', 3).str[2]Функции для расчета
Проще всего рассчитать количество доступных для сборки серверов для односокетных материнских плат и совместимых процессоров. Алгоритм функции прост: необходимо определить, чего из двух типов комплектующих меньше, и по этому числу вывести количество серверов. Так же рассчитывается тип и количество «лишних» комплектующих.
def cpu_mb(cpu, mb):
print('CPU :',cpu)
print('1 сокетных MB:',mb)
if cpu >= mb:
qty = mb
print('Можем собрать серверов:',qty)
print('Оверсток CPU:',cpu - qty)
else:
qty = cpu
print('Можем собрать серверов:',qty)
print('Оверсток материнских плат:',mb - qty)
return(qty)Для ряда комплектующих масштабируемые процессоры могут устанавливаться как в односокетные материнские платы, так и в двухсокетные. В таком случае задается пропорция. В примере ниже на 60% двухсокетных материнских плат рассчитывается 40% односокетных. Функция усложняется: на первом шаге рассчитываются показатели для односокетных материнских плат, а на следующем — для двухсокетных за вычетом процессоров, использованных на первом шаге.
def cpu2_mb2and1(cpu, onesocket, twosocket):
print('CPU :', cpu)
print('односокетные MB :', onesocket)
print('двухсокетные MB :', int(twosocket / 2))
if cpu >= (onesocket + twosocket):
qty = onesocket + twosocket / 2
print('Можем собрать односокетных серверов:', onesocket)
print('Можем собрать двухсокетных серверов:', int(twosocket / 2))
print('Оверсток CPU:', int(cpu - onesocket - twosocket))
elif onesocket <= cpu * 0.25:
qty = int(onesocket + (cpu-onesocket) / 2)
print('Можем собрать односокетных серверов:', int(onesocket))
print('Можем собрать двухсокетных серверов:', int((cpu-onesocket) // 2))
print('Оверсток CPU:', cpu - onesocket - (cpu - onesocket) // 2 * 2)
print('Оверсток двухсокетных MB:', int(twosocket / 2 - int(cpu - onesocket) // 2))
elif twosocket <= cpu * 0.375:
qty = int(twosocket / 2 + cpu-twosocket)
print('Можем собрать односокетных серверов:', int(cpu - twosocket))
print('Можем собрать двухсокетных серверов:', int(twosocket / 2))
print('Оверсток односокетных MB:', onesocket - int(cpu - twosocket))
else:
qty = int(cpu * 0.375)+(cpu - int(cpu * 0.375) * 2)
print('Можем собрать односокетных серверов:', cpu - int(cpu * 0.375) * 2)
print('Можем собрать двухсокетных серверов:', int(cpu * 0.375))
print('Оверсток односокетных MB:', onesocket - (cpu - int(cpu * 0.375) * 2))
print('Оверсток двухсокетных MB:', int(twosocket / 2-int(cpu * 0.375)))
return(qty)Но и это еще не все.
В рамках одного поколения могут существовать масштабируемые процессоры, процессоры, работающие только в одном сокете, и соответствующие материнские платы. Функция для расчета в таком случае предполагает сначала распределение single-процессоров в односокетные системы, затем распределение масштабируемых процессоров в одно- и двухсокетные материнские платы и платформы:
def cpu2and1_mb2and1(cpu, cpu1, onesocket, twosocket):
print('масштабируемые CPU :', cpu)
print('single (P) CPU :', cpu1)
print('1 сокетные MB :', onesocket)
print('2 сокетные MB :', int(twosocket / 2))
if cpu1 >= onesocket:
qty_P = onesocket
print('Можем собрать односокетных серверов c single (P) CPU:', int(onesocket))
print('Оверсток single (P) CPU для одного сокета:', cpu1 - onesocket)
onesocket = 0
elif cpu1 <= onesocket:
qty_P = cpu1
print('Можем собрать односокетных серверов c P cpu:', int(cpu1))
onesocket = onesocket - cpu1
if cpu >= (onesocket + twosocket):
qty = onesocket + twosocket / 2
print('Можем собрать односокетных серверов:', onesocket)
print('Можем собрать двухсокетных серверов:', int(twosocket / 2))
print('Оверсток масштабируемых CPU:', int(cpu-onesocket - twosocket))
elif onesocket <= cpu * 0.25:
qty = int(onesocket + (cpu-onesocket) / 2)
print('Можем собрать односокетных серверов:', int(onesocket))
print('Можем собрать двухсокетных серверов:', int((cpu-onesocket) // 2))
print('Оверсток масштабируемых CPU:', cpu-onesocket-(cpu-onesocket) // 2 * 2)
print('Оверсток двухсокетных MB:', int(twosocket / 2 - int(cpu-onesocket) // 2))
elif twosocket <= cpu * 0.375:
qty = int(twosocket / 2 + cpu - twosocket)
print('Можем собрать односокетных серверов:', int(cpu - twosocket))
print('Можем собрать двухсокетных серверов:', int(twosocket / 2))
print('Оверсток односокетных MB:', onesocket - int(cpu - twosocket))
else:
qty = int(cpu * 0.375) + (cpu - int(cpu * 0.375) * 2)
print('Можем собрать односокетных серверов:', cpu - int(cpu * 0.375) * 2)
print('Можем собрать двухсокетных серверов:', int(cpu * 0.375))
print('Оверсток односокетных MB:', onesocket - (cpu - int(cpu * 0.375) * 2))
print('Оверсток двухсокетных MB:', int(twosocket / 2 - int(cpu * 0.375)))
return(qty + qty_P)Ничего не понятно, но жутко интересно.
Как это работает на практике
Intel® Xeon® E-23xx
Первый пример — для нового поколения процессоров Intel® Xeon® E-23xx.
Минимальная номенклатура комплектующих, только односокетные материнские платы и платформы.
data_xeone23 = data.query('family=="xeone23"').copy() #фильтрую только совместимые комплектующие по модели и поколению
cpu_xeone23 = data_xeone23.query('device=="cpu"')['qty'].sum() #считаю число процессоров
mb_xeone23 = data_xeone23.query('device=="motherboard" or device=="system"')['qty'].sum() #считаю число матплат и платформ
print(color.BOLD + 'Intel Xeon E-23xx' + color.END)
display(data_xeone23[['name_seido','device','family','qty']])
print()
qty_xeone23 = cpu_mb(cpu_xeone23,mb_xeone23)
#функция считает кол-во серверов и выводит на экран деталиРезультат выполнения кода на экране, пора закупать процессоры:

Intel® Xeon® Scalable 3-го поколения
Усложним задачу и рассмотрим новейшее поколение Intel® Xeon® Scalable.
Это масштабируемые процессоры, которые можно установить как в односокетные, так и в двухсокетные материнские платы или платформы.
data_3scalable = data.query('family=="scalable3"').copy()
cpu_3scalable = data_3scalable.query('device=="cpu"')['qty'].sum()
socket1_3scalable = data_3scalable.query('socket=="single"')['qty'].sum()
socket2_3scalable = data_3scalable.query('socket=="dual"')['qty'].sum() * 2
print(color.BOLD + 'Intel 3rd Scalable' + color.END)
display(data_3scalable[['name_seido','device','family','socket','qty']])
qty_3scalable = cpu2_mb2and1(cpu_3scalable,socket1_3scalable,socket2_3scalable)Что видим после выполнения кода:

Ситуация с процессорами повторяется: их снова недостаточно. При этом один процессор — лишний, так как число процессоров четное, а односокетных материнских плат — нечетное. В целом видно, что их значительно меньше, чем двухсокетных. Возможно, также стоит докупить односокетные платформы или материнские платы.
Напомню, что в тестовом датасете число CPU рандомное, но в реальной жизни процессоры могут задерживаться или частично не приехать вообще. Тогда и возникает оверсток по материнским платам. Об этом, как правило, известно и так, однако скрипт позволяет посчитать показатели быстрее.
AMD EPYC™ 7003
И наконец, вишенка на торте — AMD EPYC™ 7003. То самое поколение, в котором есть single-процессоры, масштабируемые процессоры и материнские платы с разным количеством сокетов:
data_amd7003 = data.query('family=="amd7003" or family=="amd7003p"').copy()
cpu_amd7003 = data_amd7003.query('device=="cpu" and family=="amd7003"')['qty'].sum()
cpu_amd7003p = data_amd7003.query('device=="cpu" and family=="amd7003p"')['qty'].sum()
socket1_amd7003 = data_amd7003.query('socket=="single"')['qty'].sum()
socket2_amd7003 = data_amd7003.query('socket=="dual"')['qty'].sum() * 2
print(color.BOLD + 'AMD EPYC 7003' + color.END)
display(data_amd7003[['name_seido','device','family','socket','qty']])
print()
qty_amd7003 = cpu2and1_mb2and1(cpu_amd7003,cpu_amd7003p,socket1_amd7003,socket2_amd7003)
Какие делаем выводы: не хватает односокетных материнских плат и масштабируемых процессоров.
Общий итог
Общий итог по всем серверам рассчитывается просто:
total_servers = ddr4_reg_servers + ddr4_ecc_servers + ddr3_reg_servers + ddr3_ecc_servers
#переменная объявлена ранее в блоке расчета оперативной памяти
print(color.BOLD + 'Всего можем собрать серверов:'+ color.END, int(total_servers))
print('Intel 3rd Scalable: ',int(qty_3scalable))
print('Intel Scalable: ',int(qty_scalable))
print('AMD EPYC 7003: ',int(qty_amd7003))
print('AMD EPYC: ',int(qty_amdepyc))
print('Intel Xeon W: ',int(qty_xeonw))
print('Intel Xeon E-23xx: ',int(qty_xeone23))
print('Intel Xeon E-22xx: ',int(qty_xeone22))
print('Intel Xeon E5: ',int(qty_xeone5))
print('Intel Xeon E5 ddr3: ',int(qty_xeone5ddr3))
print('Intel Xeon E3: ',int(qty_xeone3))
print('Intel Xeon E3 ddr3: ',int(qty_xeone3ddr3))
Получаем желаемый результат в виде общего числа потенциальных серверов и разбивку по поколениям.
Расчеты для оперативной памяти, корпусов и сетевых карт.
На примере регистровой памяти DDR4:
data_ddr4_reg = data.query('type=="ram_ddr4_reg"').copy()
data_ddr4_reg['size'] = data_ddr4_reg['name_seido'].str.split(' ', 1).str[0].astype(int)
data_ddr4_reg['total'] = data_ddr4_reg['size'] * data_ddr4_reg['qty']
display(data_ddr4_reg[['name_seido','size','qty','total']])
total_ddr4_reg = int(data_ddr4_reg['total'].sum())
В коде определяется размер памяти по наименованию и рассчитывается общий объем памяти этого типа на складе. Далее происходит пересчет на один сервер исходя из общего количества серверов с данным типом памяти:
ddr4_reg_servers = qty_3scalable + qty_xeonw + qty_scalable + qty_amd7003 + qty_amdepyc + qty_xeone5
print(color.BOLD + 'DDR4 ECC REG'+ color.END)
print('Общий объем DDR4 ECC REG:', data_ddr4_reg['total'].sum() / 1000,'TB')
print('Рассчитано серверов:', int(ddr4_reg_servers),'шт')
print('На один сервер:', int(total_ddr4_reg / ddr4_reg_servers),'GB')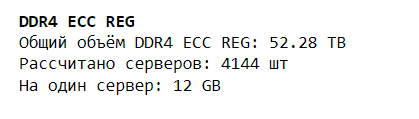
Аналитика поверхностная и не учитывает соотношение планок по размерам, зато она отлично работает как красный флаг для закупки. В нашем примере DDR4 ECC REG на складе недостаточно. Для потенциальной сборки всех серверов не хватит.
Четыре строки кода о корпусах и сетевых картах:
print('Всего материнских плат на складе:', data.query('device == "motherboard"')['qty'].sum())
print('Всего корпусов:', data.query('device == "chassis"')['qty'].sum())
print('Расчетное желаемое количество карт 10GE:',int(total_servers*0.4))
print('На складе карт 10GE:',int(data.query('type=="card10ge"')['qty'].sum()))
Если после исключения платформ (а они здесь исключены) материнских плат меньше, чем корпусов, необходимо действовать — докупать разницу. В более подробной аналитике, безусловно, также необходимо проверить совместимость и расход разных типов комплектующих. По сетевым картам решение очевидно — пора оформлять заказ.
Что в итоге
Во-первых, на написание скрипта я потратил несколько часов. И он работает, без привлечения существенных ресурсов компании. Теперь для формирования отчета по остаткам на складе мне не нужно столько же времени «залипать» в Excel.
Во-вторых, при проверке на реальных данных я подсчитал количество доступных к сборке серверов по семействам и поколениям. С удивлением обнаружил дисбаланс комплектующих — например, материнских плат в одном случае и планок памяти в другом. Что примечательно, в обоих случаях для устаревших платформ, например, один из типов DDR3 на складе в избытке. Будем искать ему применение. К работе подключится отдел сборки, так как один из вариантов борьбы с таким оверстоком — создание новой фиксированной конфигурации.
Также ничего не мешает нам добавить к актуальным остаткам информацию о количестве комплектующих, которые находятся в пути и гарантированно приедут в ближайшее время. Результат расчетов меняется, иногда кардинально. Если выявляется недостаток актуального железа, которое мы закупаем, логично отправить заявку в отдел закупок на поставку недостающих комплектующих.
Минус скрипта — в том, что он не интегрирован в общую систему отчетов. Для его запуска необходимо вручную, пусть и в два клика, добавить актуальные остатки и запустить Jupyter Notebook.
Возможно, в дальнейшем мы все-таки сформулируем требование и интегрируем его в BI-систему Selectel. Но сейчас стоимость разработки скрипта в соотношении к выдаваемому результату оптимальна, а тестирование, учет остальных блокеров и поиск новых показателей продолжается.

Комментарии (6)

belch84
21.04.2022 22:17+1Работаю в компании, которая занимается сборкой компьютеров с 1995 года. Уже тогда написал достаточно универсальную программу, которая с некоторыми изменениями используется и сейчас. Она подходит как для десктопных компьютеров, так и для серверов. Для ее работы нужно иметь предварительно подготовленный набор описаний стандартных конфигураций, он должен быть достаточно представительным, чтобы, отталкиваясь от стандартной конфигурации, с помощью добавления, изменения и удаления деталей можно было создать вообще все, что угодно (и при этом чтобы было трудно создавать конфигурации, не являющиеся работоспособными). Для любой (стандартной или нестандартной) конфигурации можно получить ответ на вопросы: сколько таких компьютеров можно собрать, а также: сколько и каких деталей нужно докупить, чтобы собрать заданное кол-во компьютеров заданной конфигурации. Результатом логической сборки конфигурации является список конкретных деталей с количествами, составляющих эту конфигурацию. Некоторые из этих деталей могут быть виртуальными, т.е. для того, чтобы физически собрать компьютер, эти детали нужно приобрести.
Что только не сделаешь, лишь бы не внедрять в компании нормальное ПО для складского учёта. :)
За очень долгое время существования системы было несколько попыток её переписать или заменить на так называемое нормальное ПО для складского учета. Пока все они закончились примерно одним и тем же —обосраниемнеудачей разработчиков или внедренцев той или иной степени с различными объяснениями её причин
ghostinushanka
22.04.2022 15:54За очень долгое время существования системы…
Желания сделать из этого свой продукт, или выгрузить в открытый доступ под лицензия по выбору не возникало?
А если возникало, то что помешало?belch84
22.04.2022 16:25Каждый программист хочет, чтобы его программа использовалась как можно большим количеством пользователей, но…
На очень раннем этапе существования системы стало понятно, что сделать её тиражируемой не получится, и универсальность вступает в прямое противоречие с требованиями к системе. Сборка компьютеров — это очень специфическая и достаточно узкая область. Многие серьезные производители предлагают какую-то свободу в выборе конфигураций, но собирать вообще все, что может понадобиться заказчику, решается редко кто (чаще производители стараются убедить заказчика, что ему это не нужно, и среди стандартных конфигураций всегда найдется именно та, в которой заказчик нуждается). Именно поэтому «нормальное ПО для складского учёта» может продаваться большим тиражом, но не может обеспечить такого рода даже не мелкосерийную, а индивидуальную сборкуПример форм для логической сборки компьютеров



Thomas_Hanniball
Что только не сделаешь, лишь бы не внедрять в компании нормальное ПО для складского учёта. :)
Свои велосипеды — это всегда весело и увлекательно, но, как правило, такими велосипедами пользуются только их создатели и ещё несколько обученных ими людей. Другие люди со стороны ими пользоваться не будут, а после ухода из компании автора скрипта, все остальные вернутся к привычному миру Excel.