
Нода кластера: сервер отечественного производства Etegro (2 AMD Opteron 6320, 16 GB RAM, 4 HDD)
Системы хранения данных, используемые сейчас на практике в России, условно делятся на три категории:
- Очень дорогие high-end СХД;
- Мидрейнжевые массивы (тиринг, HDD, гибридные решения);
- И экономичные кластеры на базе SSD-массивов и HDD-массивов из «бытовых» дисков, часто собранные своими руками.
И не факт, что последние решения медленнее или менее надёжные, чем хайэнд. Просто используется совершенно другой подход, который не всегда подходит для того же банка, например. Но зато отлично подходит для почти всего среднего бизнеса или облачных решений. Общий смысл — берём много дешёвого чуть ли не «бытового» железа и соединяем в отказоустойчивую конфигурацию, компенсируя проблемы правильным софтом виртуализации. Пример — отечественный RAIDIX, творение петербуржских коллег.
И вот на этот рынок пришла EMC, известная своими чертовски дорогими и надёжными железками с софтом, который позволяет без проблем поднять и VMware-ферму, и виртуальную СХД, и всякий приклад на одних и тех же х86 серверах. И ещё началась история с серверов русского производства.
Русские серверы
Изначальная идея была взять наше отечественное железо и поднять на нём недостающие для импортозамещения куски инфраструктуры. Например, те же рассадники виртуальных машин, VDI-серверы, системы хранения данных для приклада и аппликейшн-серверы.
Российский сервер — это такая чудо-железка, которая на 100% собирается в России и является по всем нормам 100% отечественной. На практике — возят отдельные детали из Китая и других стран, закупают отечественные провода и делают сборку на территории РФ.
Получается не так чтобы очень плохо. Работать можно, хотя надежность ниже тех же HP. Но это компенсируется ценой железа. Дальше мы приходим к ситуации, в которой не самое стабильное железо должно компенсироваться хорошим управляющим софтом. На этом этапе мы начали экспериментировать с EMC ScaleIO.
Опыт получился хороший, в ходе экспериментов выяснилось, что железо не сильно важно. То есть — можно заменить на проверенное, от известных брендов. Получится несколько дороже, но меньше проблем с сервисом.
В итоге концепция поменялась: теперь мы говорим просто про выгоду ScaleIO на различном железе, в том числе (и в первую очередь) — из нижнего ценового сегмента.
Но к делу: результаты тестов
Вот принцип работы ScaleIO (http://habrahabr.ru/company/croc/blog/248891/) — берём серваки, набиваем их под завязку дисками (например, теми же SSD-штуками, которые предназначались для замены HDD в своё время) и соединяем всё это в кластер:

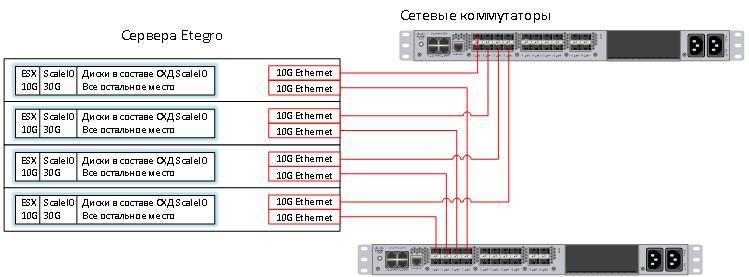
Конфигурация, проверенная нами в лаборатории в этот раз — это интеграция EMC ScaleIO и VMware. Коллеги из Etegro любезно одолжили нам 4 сервера с 2 процессорами AMD Opteron(tm) Processor 6320 и 16 GB оперативной памяти в каждом. В каждом стояло по 4 диска. Не самая ёмкая конфигурация, я бы предпочел серверы на 25 дисков 2.5 дюйма, но работать приходится с тем, что есть, а не с тем, чего хочется.
Вот серверы в стойке:

Весь объём дисков в сервере я поделил на 3 части:
- 10 Gb для ESX. Этого вполне достаточно.
- 30 GB для внутренних нужд ScaleIO, но об этом позже.
- Все остальное место будет отдано через ScaleIO.
Первое, что нужно сделать — установить VMware. ESX ставить будем по сети, так быстрее. Задача это не новая, а виртуальная машина с PXE сервером давно заняла заслуженное место в моем ноутбуке.

Как видите, в нашей лабе много тестового оборудования. Справа стоят еще 4 стойки и еще 12 на первом этаже. Мы можем собрать практически любой стенд по просьбе заказчика.
Технология работы Software Defined Storage такова, что каждая нода может запросить достаточно большое количество информации с других нод. Этот факт означает, что в таких решениях очень важны пропускная способность и время отклика BackEnd сети. 10G Ethernet хорошо подходит для решения этой задачи, а коммутаторы Nexus уже стоят в этой стойке.
Вот схема получившегося решения:
Установка ScaleIO на VMware очень проста. Фактически она состоит из 3 пунктов:
- Устанавливаем плагин для vSphere;
- Открываем плагин и запускаем инсталляцию, в этом же пункте нужно ответить на 15-20 вопросов визарда.
- Смотрим, как ScaleIO самостоятельно заползает на серверы.
Если визард закончился без ошибок, в vSphere появится специальный раздел для ScaleIO, в котором можно создать луны и отдать их ESX серверам.
Или можно использовать стандартную консоль ScaleIO, установив ее на локальный компьютер.
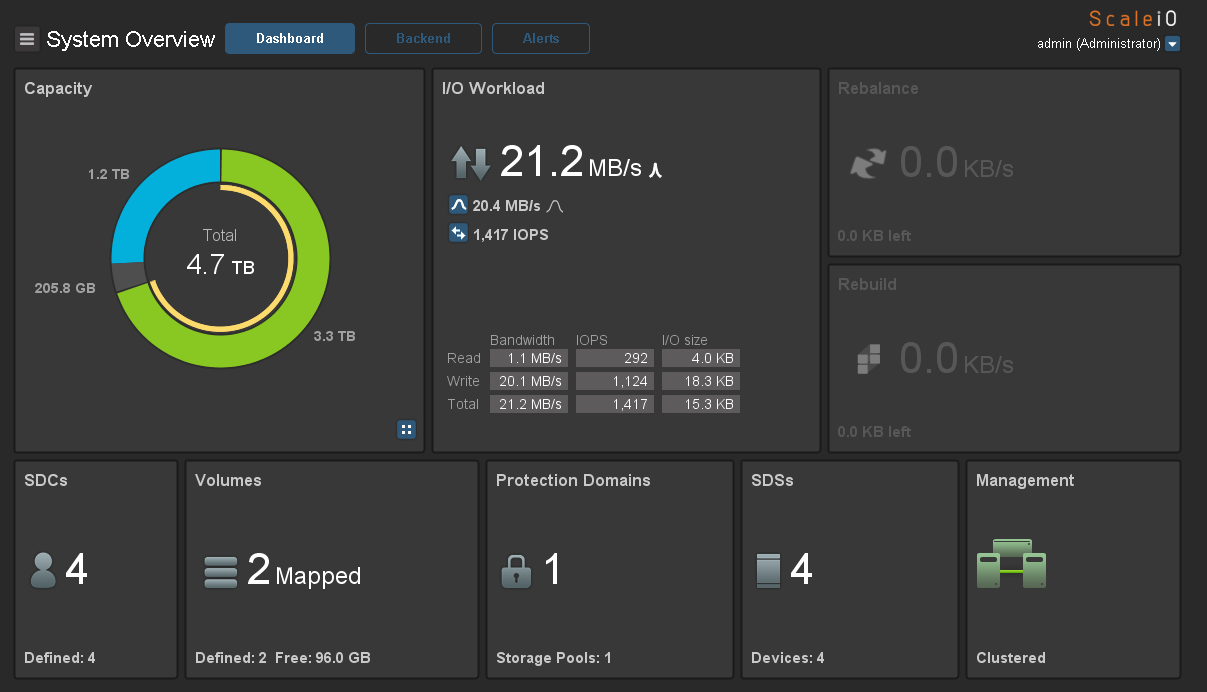
Теперь небольшой тест на производительность. Я создал на каждом хосте по виртуальной машине с 2 дисками по 50Gb и равномерно разделил их по датасторам. Нагрузку генерировал с помощью IOmeter. Вот максимальные результаты, которые мне удалось получить на нагрузке 100% random, 70% read, 2k.
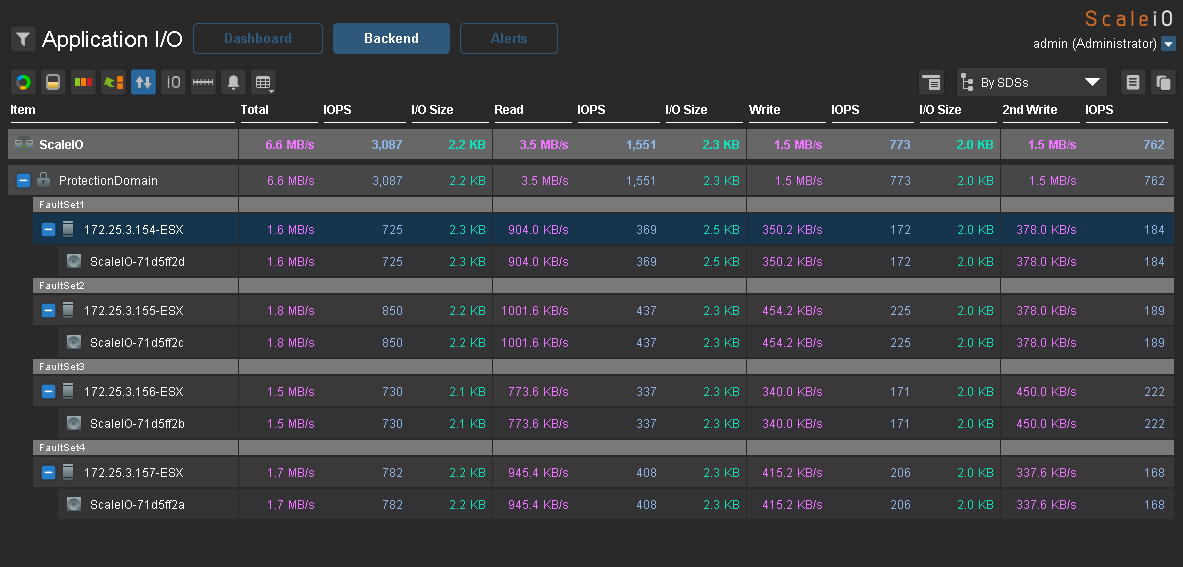
3000 application IO c 4-х серверов с SAS дисками — неплохой результат.
В качестве развлечения я попытался «завалить» систему, выдергивая ноды в разной последовательности и через разные промежутки времени. Если ноды выдергивать по одной и давать ScaleIO достаточно времени для ребилда, то виртуальные машины будут работать, даже если останется одна нода. Если отключить 3 ноды за минуту, например, доступ к общему пространству остановится до той поры, пока эти ноды не будут включены обратно. Данные становятся доступны, а массив выполняет проверку целостности данных и ребилд (если необходимо) в фоновом режиме. Таким образом, решение получается достаточно надежным для того, чтобы использовать его на боевых задачах.
Пожалуй, про виртуализацию все. Пора подвести итог.
Резюме
Плюсы:
- Цена решения (процессорные мощности + память + диски) конкурентоспособна и во многих случаях будет существенно ниже, чем серверы + СХД в аналогичных моновендорных предложениях.
- Можно использовать любое железо и получить замену «большой красивой» СХД для таких же задач. Если нужно, серверы можно заменить на более мощные без закупки каких-либо дополнительных лицензий для ScaleIO. Он лицензируется потерабайтно без привязки к железу.
- Решение конвергентное. Виртуальные машины и СХД на одном и том же сервере. Это очень удобно практически для любого среднего бизнеса. Флеш-СХД — уже не фантастика на этом уровне.
- Плюс требуется меньше места в стойках, меньше энергопотребление.
- Хорошая балансировка — равномерное распределение IO по всем дисковым ресурсам.
- Решение можно разнести на 2 разные площадки, настроив зеркалирование между ними на уровне одного кластера ScaleIO.
- Для синхронной и асинхронной репликации между кластерами можно использовать виртуальный RecoverPoint.
Минусы:
- Во-первых, придётся применить мозг. Дорогие решения, как правило, хороши тем, что внедряются очень быстро и не требуют почти никакого специального обучения. Учитывая, что ScaleIO — это, фактически, самосборное СХД, придётся разобраться в архитектуре, покурить пару форумов для оптимальной конфигурации, поставить эксперимент на своих данных для выбора оптимальной конфигурации.
- Во-вторых, за избыточность и отказоустойчивость вы платите местом на дисках. Коэффициент преобразования raw space в user space меняется в зависимости от конфигурации, и, возможно, вам потребуется больше дисков, чем вы думали изначально.
Напоминаю, вот здесь можно прочитать про софтверную часть подробно, а я же с удовольствием отвечу на вопросы в комментариях или почте RPokruchin@croc.ru. А ещё через месяц, 26 ноября, мы с коллегами будем делать открытый тест-драйв с Scale IO пылесосом Керхер, кувалдой и другими штуками, пока мужики не скажут: «Аааа, заррраза». Регистрация тут.
Комментарии (36)

gotch
22.10.2015 10:23+7Извините, но что в этом сервере отечественного, кроме этикетки?

FractalizeR
22.10.2015 11:13+1Российский сервер — это такая чудо-железка, которая на 100% собирается в России и является по всем нормам 100% отечественной. На практике — возят отдельные детали из Китая и других стран, закупают отечественные провода и делают сборку на территории РФ.
Сборка. Только сборка.gotch
22.10.2015 11:24+1То-то и оно. Ни оригинального дизайна — ходя бы форм-фактора материнской платы, ни корпуса, ни салазок, ни ru-iLO.
Сервер отечественного производства. Да его и отверткой-то китайской, наверняка, собирали.

RPOkruchin
22.10.2015 11:57Сборка, цена и дизайн плат. Компоненты и готовые платы производителю (сборщику) везти через таможню куда дешевле, чем целый сервер. Смысл же в том, что можно использовать любое железо, включая такое, и получать надежные решения.

navion
22.10.2015 23:13+1Под дизайном плат — имеете ввиду заказ у Кванты разъемов БП с другой стороны или фейла с подключением mezzanine-платы ко второму процессору?


celebrate
22.10.2015 11:03+3Простите, 3000 IOPS с 16 SSD дисков???
RPOkruchin
22.10.2015 11:26В массиве нет SSD-дисков.
celebrate
22.10.2015 12:03«Вот принцип работы ScaleIO (http://habrahabr.ru/company/croc/blog/248891/) — берём серваки, набиваем их под завязку дисками (например, теми же SSD-штуками, которые предназначались для замены HDD в своё время) и соединяем всё это в кластер:»
Поскольку ниже нет описания, какие же диски использовались, то создается полная иллюзия того, что все-таки SSD диски
ximik13
22.10.2015 16:30+1Если SAS диски стоят в серверах и I/O распределены равномерно по шпинделям, то даже расчетно получается (по консервативным прикидкам) 16*180 IOPS=2880 IOPS.
Только вот на скриншоте это скорее все же вackend IOPS, т.е. то что выдают диски. А не aplication (или frondend) I/O, т.е. то что генерят приложения на серверах. А это все таки немного разные вещи.RPOkruchin
23.10.2015 14:52Это вackend IOPS, состоящие из 1500 IO чтения (1500 на FE) и 2*750 IO записи (750 IO записи для клиента).
ximik13
23.10.2015 15:35В статье написано:
Вот максимальные результаты, которые мне удалось получить на нагрузке 100% random, 70% read, 2k.
Правильнее предположить что хосты генерят:
3000=x*0.7+x*0.3*2
x=3000/1.3= ~2300 IOPS, из которых чтение ~1610 IOPS (70%) и запись ~690 IOPS (30%).
gotch
22.10.2015 16:40+1А правда ли, что прайсовая цена ScaleIO примерно 1572 долларов за терабайт сырого места?

Chromex
23.10.2015 16:47Думаю, что правда, у IBM подобная система стоит заоблачных денег) очередная рекламная уловка
gotch
25.10.2015 19:30Немного шокирует. Да что уж, сильно шокирует.
Смотрю как «заигрывают» с рынком Nexenta и Nutanix (последние, к сожалению, благодаря блогу производят впечатление аггресивных хвастунов). У ScaleIO достижения скромнее, бери и используй для тестов без ограничений, по времени или объему, но без продуктовой нагрузки.
Жду широкого шага от VMware. Сейчас цена VSAN не сильно адекватна рынку. И в то же время VMware испытывает определенное давление со стороны Hyper-V, KVM и соответствующих инфраструктурных обвязок. Включение лицензии VSAN в стоимость гипервизора было бы глотком свежего воздуха для VMware.navion
26.10.2015 10:23Если очень хочется, то можно и для нормальной нагрузки её использовать.
А от VMware халявы ждать не стоит, они нацелены на рынок богатых ентерпрайзов и принципиально не дают ничего бесплатно. У них даже доступ к роликам с VMworld стоит 200 ойро в год, где показали занятную статистику использования DRS. По ней можно сделать вывод, что абсолютное большинство клиентов покупает vSphere в редакции Enterprise и выше, а не дешевую Standard.gotch
27.10.2015 12:39Да там все примерно то же написано
Q: Can I use it in production environments?
A: No, not really.navion
27.10.2015 12:41Вы зря не скопировали ответ полностью, там вполне разумное объяснение со следующим выводом «If you will NEVER CALL IN SUPPORT – whatevs.»
gotch
27.10.2015 12:49Думаю, мы понимаем о чем идет речь, об определенных разумных и добросовестных отношениях. «EMC isn’t going to police this.» Но если соблюдать все формальности, то все же нет.

phozzy
23.10.2015 10:27-1Зачем эта проприетарщина, когда есть Ceph?
RPOkruchin
23.10.2015 14:52+1Каждое ПО имеет свою область задач. С помощью Ceph невозможно решить задачу, описанную в топике. Нельзя установить его на хосты VMware и сделать SDS для виртуальных машин из локальных дисков.
phozzy
23.10.2015 15:56В топике написано
Как можно сделать отказоустойчивую систему хранения данных из отечественных серверов
По Вашему мнению Ceph не пригоден для создания программноопределяемого хранилища для хранения блочных устройств виртуальных машин?
А что же тогда у меня уже год работает? Мой опыт говорит, что из стандартного железа с помощью Ceph можно собрать SDS по характеристикам не уступающим, а местами и превосходящим high-end системы. Говорю не голословно, мы сравнивали с IBM XIV.navion
23.10.2015 16:55Поэтому ScaleIO не умеет права на жизнь? Как минимум он проще для гетерогенной среды — поставил драйверы на VMware/Windows/Linux, прокликал визард в гуе (в 2.0 обещают больше этого) и у тебя работает SDS.
Для совмещения ролей СХД и гипервизора не надо изобретатьНутаниксвелосипед с пробрасывнием в ВМ контроллеров с дисками.phozzy
26.10.2015 07:41Имеет. Меня возмущает общий, пространный характер содержания заголовка и преамбулы, и не соответствующее ему маркетинговое содержание коммерческого продукта.
navion
26.10.2015 10:59Не заметил там ничего про бесплатность или открытость.
Отечественные серверыестьбыли, условно-бесплатный ScaleIO тоже и даже прорекламировали RAIDIX (тоже местный, но сильно небесплатный и узкоспециализированный).
RPOkruchin
23.10.2015 17:08+1В статье речь идет о виртуализации от VMware. В ESX нет нативной поддержки RBD устройств. Можно отдать RBD устройства по NFS или iSCSI через прослойку (примапить их к серверу и отдать по другому протоколу). Будет ли такое решение превосходить high-end системы по отказоустойчивости, производительности, времени отклика и функционалу? Не будет.
Предлагаю не вести длинный диалог о том, насколько хорош или плох Ceph по сравнению с high-end системами, а посмотреть на рынок. Заказчики не спешат переносить данные с high-end систем на SDS. Таким образом mission critical данные по-прежнему хранятся на high-end системах. Потерять данные себе дороже.phozzy
26.10.2015 07:38В статье да, а в заголовке и преамбуле нет. Это вводит в заблуждение. Прочитав заголовок и преамбулу, я как минимум ожидал общее описание SDS или обзор решений, а в итоге получил маркетинговый треш.
gydex
26.10.2015 20:46Какое среднее время восстановления работоспособности системы при выходе из строя одного жесткого диска или SSD?
ximik13
26.10.2015 21:12Хороший вопрос, вот только посчитать довольно сложно. Блоки по 1Mb начнут копироваться по сети со всех дисков, где лежали дубликаты потерянных данных, на не меньшее количество дисков. Сеть в 1 Gbit/s, если не подрезать эти потоки встроенными средствами, ложится почти наглухо. На 10-ке наверно должно быть полегче. Хотя будет сильно зависеть от количества нод в кластере и от размера «погибшего» диска.
Но в целом интересно было бы увидеть, что было на практике на стенде из статьи.

AlexanderCam
27.10.2015 12:16Вот только вы не учитываете Storage Efficiency (компрессия, дедупликация) у тех самых «красивых и дорогих» СХД, и если посмотреть в этом разрезе, то не такие уж они и дорогие получаются, в особенности для VMWare. То что EMC для этого не подходит — тут я с вами согласен. У нас на уровне группы от америки до азии запрещено использовать в продуктиве на EMC как компрессию так и дедупликацию. Плюс я сам убедился в этом когда у нас 2 раза тестовый VNX прилег часов на 12 из-за использования дедупликации.
ximik13
27.10.2015 14:34Может вы просто не умеете ее готовить? :) Там достаточно много нюансов.
Да и на младших моделях семейства VNX2 дедупликация блочная возможна скорее только в ущерб производительности. По этому нужно понимать, что и зачем планируется дедуплицировать?
Компрессия так вообще требует при всех операциях I/O online сжатия/разжатия данных. Т.е. дополнительных ресурсов контроллера и времени. Что тоже не везде применимо.AlexanderCam
28.10.2015 14:18Так было бы из чего готовить. Не буду тут показывать пальцем на правильных вендоров, дабы не быть обвиненным в рекламе, где всё работает уже более 10 лет без нареканий (10 лет это только мой опыт, а так и того больше). Хочу так же отметить, что это не только мой опыт, а так же опыт всей группы в которой суммарно >500 СХД разного калибра… более того у нас так же стандартами «запрещено» использовать MirroView — если нужна репликация на EMC то SRDF или VPLEX. И для виртуализации никакого Fibre Chanel (SCSI) под датасторы — только NFS… все эти стандарты написаны
«кровью» убитыми данными. Я думаю это долгий разговор и не в рамках комментариев. :)
P.S. Приходите на EMC Forum 2015 30 октября :)ximik13
28.10.2015 16:55Не надо давить меня «групповым авторитетом», а то сломаюсь :).
У меня мнение простое. Не работает как написано в документации? Значит кто-то не прочитал документацию вдумчиво и до конца. А потом рождаютсястандартылегенды о пряморуких админах и неправильном оборудовании :).
Про репликацию я вас не понял. MirroView — это встроенный функционал средних хранилок (Clariion\VNX). SRDF — это уже hi-end массивы Symmetrix\VMAX. VPLEX — вообще самостоятельное, «массиво-независимое» решение, причем тоже скорее hi-end. Т.е. у вас в компании принято использовать только Hi-End решения? Ну значит этого требует бизнес, что тут можно сказать :).
А вот NFS меня окончательно запутал. Вы NFS с VMAX-а как раздаете (про VPLEX даже боюсь подумать)? Через файловые шлюзы от массивов среднего уровня? Ака Celerra\VNX file gateway? Мда…
P.s. На форум с удовольствием, если мне кто-нибудь билет на самолет до Москвы и обратно подкинет :).
blind_oracle
Спасибо за статью! Только вот ETegro уже… того. RIP.