Настало время поделиться нашим опытом организации процесса разработки в модной теме «Больших Данных». В телекоммуникационной отрасли с Big Data связаны немалые надежды на новые ниши, продукты, и, соответственно, доходы. Правда, многие телекоммуникационные компании предпочитают покупать готовые решения в области Больших Данных, а не заниматься развитием собственной экспертизы. Еще с 2013 года «МегаФон» пошел другим путем, сделав ставку на команду сильных специалистов по Big Data, способных эффективно решать весьма непростые задачи.
Прежде чем погружаться в Большие Данные, следует ознакомиться с законодательной базой, которая регламентирует их обработку. Федеральные законы «О связи» и «О персональных данных» детально прописывают процедуры обработки данных, которые накапливает сотовый оператор. Эта информация, в соответствии с законом, должна быть защищена, — следовательно, информацию о реальных клиентах и их транзакциях нельзя будет использовать для отладки и тестирования только что написанного кода.
Когда «внутренние клиенты» и исполнители работ сидят за соседними столами, это обеспечивает мгновенную и естественную обратную связь. Добавим сюда не всегда отчетливую постановку задач, желание заказчика вносить коррективы «на ходу», и увидим, что лучшим методом работы становится SCRUM. Он верой и правдой служил нам почти 12 месяцев до конца 2013 года. Разработка шла быстро, при этом у нас была возможность и экспериментировать, и выдавать эффективный продукт. Единая команда заказчиков и разработчиков в полном составе участвовала в обсуждении задач, в декомпозиции требований на технические составляющие. В результате заказчики видели, как их идеи реализовывались в коде, а разработчики решали интересные задачи, совмещая и выполняя функции аналитиков, архитекторов и проектировщиков.
Тем временем задачи от заказчика множились, требования становились жестче, накапливался бэклог, технический долг рос. Вдобавок ужесточались требования к надежности и производительности уже внедренных решений. Вот тут-то SCRUM и стал давать сбой: планирование спринта стало таким длительным и сложным, что нарушало ритм работы команды. Большие и сложные задачи никто не хотел брать в спринт, резать задачи тоже не хотелось. За большим количеством задач команда перестала видеть общую картину, сиюминутные задачи стали отвлекать людей и снижать производительность. Настало время метода «Канбан».
Мы перестроили рабочий процесс, снова привлекая к обсуждению самих «внутренних заказчиков», и наладили конструктивный диалог: оценка задач стала проводиться все время, а не только во время планирования спринта. В то же время стала ощущаться нехватка аналитика, который фильтровал бы поток требований заказчика, да и размер команды несколько не соответствовал объему поставленных задач. В итоге, мы пригласили тренеров, нам была нужна консультация людей, которые сделали обучение lean-технологиям своей профессией. После общения с ними мы пришли к той схеме процесса, которую используем сейчас.
Пожалуй, главной проблемой стало большое число задач (вне зависимости от объема работ для их решения), что растягивало сроки выполнения. Заказчик был недоволен, прозрачность процесса оставляла желать лучшего. Появилась и другая проблема: плохо работала обратная связь с заказчиком. Он не интересовался, как его задачи декомпозируются, в каком порядке берутся в работу, что и когда он получит на выходе. Отсюда и непонимание реальных сроков производства работ. Третьей проблемой стало то, что сами разработчики начали терять понимание того, как конкретная задача влияет на общие цели команды.
Сохраняя приверженность гибкому подходу (что обеспечивало скорость работы, гибкость и оперативную реакцию), мы так изменили наш процесс:
Мы договорились об общих правилах ведения и наполнения бэклога, когда все требования собираются, а аналитик расставляет акценты.
Заказчикам это даёт уверенность в том, что их задачи не потеряются, а разработчикам – возможность получать правильно описанные задачи с заранее проставленным приоритетом (в дальнейшем это поможет избежать лишних итераций по переделыванию функционала).
Мы начали активно применять User Story Mapping, этот инструмент стал хорошим подспорьем для вовлечения заказчиков в обсуждение задач и их декомпозиции. Для всех участников рабочего процесса стало понятнее, что делается для выполнения конкретной задачи и как это решение повлияет на конечный продукт.
После успешного применения Story Mapping мы подходим к инструменту Impact Mapping. Он позволит глобально оценить влияние каждой доработки на общие цели и расставить акценты.
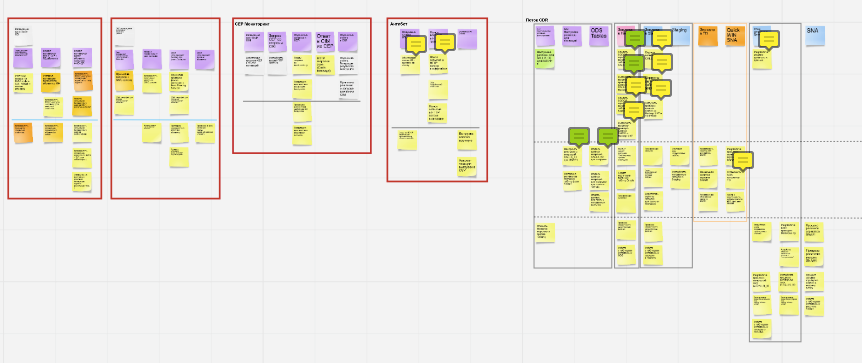
Мы выделили несколько направлений внутри процесса разработки и разделили на классы все сервисы, разрабатываемые разными командами. Это позволило изолировать команды разработчиков, благодаря чему программистов перестали отвлекать сиюминутными задачами других проектов, а заказчики и аналитики поняли возможности каждого направления разработки и строили свои цели эффективнее.
Для всех сотрудников (заказчиков и R&D) были проведены тренинги, на которых им рассказали про методологию, основные принципы работы и инструменты, позволяющие использовать «Канбан» с максимальной эффективностью.
Эта ключевая практика Канбана и позволила нам увеличить прозрачность процессов разработки для заказчиков. Мы посчитали среднее время выполнения задач и вычислили максимальное их количество по каждому направлению, которое необходимо для удовлетворения требований заказчиков. Поэтому, чтобы гарантировать качество и сроки работ, мы рассматриваем только задачи, с которыми точно справимся.
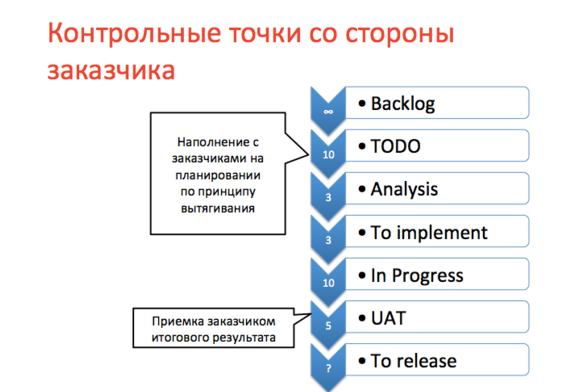
Мы не смогли польностью отказаться от еженедельного планирования, поэтому оставили еженедельные встречи с заказчиками, на которых обсуждаются статусы этапов разработки, определяется, какие задачи переводятся из бэклога в ToDo, принимаются выполненные и протестированные работы.
Ключевые встречи:
• Планирование
Участники: Заказчики, Руководители
Цель встречи: наполнение TODO из Backlog
Еженедельно
• Приемка
Участники: Заказчики, Руководители, Команда
Цель встречи: Приемка результатов работы команды
Еженедельно
Мы стали устраивать еженедельные встречи для всей команды. Они устраивались и ранее, чтобы вся команда была в курсе общих процессов. Теперь делается упор на технические задачи, определяется, кто из разработчиков будет вести конкретные задачи, какие ранее выполненные работы закрываются, формируются планы по разработке. Это стало действительно эффективным инструментом.

Продолжение следует.
Есть закон
Прежде чем погружаться в Большие Данные, следует ознакомиться с законодательной базой, которая регламентирует их обработку. Федеральные законы «О связи» и «О персональных данных» детально прописывают процедуры обработки данных, которые накапливает сотовый оператор. Эта информация, в соответствии с законом, должна быть защищена, — следовательно, информацию о реальных клиентах и их транзакциях нельзя будет использовать для отладки и тестирования только что написанного кода.
От частностей – к общему
Когда «внутренние клиенты» и исполнители работ сидят за соседними столами, это обеспечивает мгновенную и естественную обратную связь. Добавим сюда не всегда отчетливую постановку задач, желание заказчика вносить коррективы «на ходу», и увидим, что лучшим методом работы становится SCRUM. Он верой и правдой служил нам почти 12 месяцев до конца 2013 года. Разработка шла быстро, при этом у нас была возможность и экспериментировать, и выдавать эффективный продукт. Единая команда заказчиков и разработчиков в полном составе участвовала в обсуждении задач, в декомпозиции требований на технические составляющие. В результате заказчики видели, как их идеи реализовывались в коде, а разработчики решали интересные задачи, совмещая и выполняя функции аналитиков, архитекторов и проектировщиков.
Тем временем задачи от заказчика множились, требования становились жестче, накапливался бэклог, технический долг рос. Вдобавок ужесточались требования к надежности и производительности уже внедренных решений. Вот тут-то SCRUM и стал давать сбой: планирование спринта стало таким длительным и сложным, что нарушало ритм работы команды. Большие и сложные задачи никто не хотел брать в спринт, резать задачи тоже не хотелось. За большим количеством задач команда перестала видеть общую картину, сиюминутные задачи стали отвлекать людей и снижать производительность. Настало время метода «Канбан».
Мы перестроили рабочий процесс, снова привлекая к обсуждению самих «внутренних заказчиков», и наладили конструктивный диалог: оценка задач стала проводиться все время, а не только во время планирования спринта. В то же время стала ощущаться нехватка аналитика, который фильтровал бы поток требований заказчика, да и размер команды несколько не соответствовал объему поставленных задач. В итоге, мы пригласили тренеров, нам была нужна консультация людей, которые сделали обучение lean-технологиям своей профессией. После общения с ними мы пришли к той схеме процесса, которую используем сейчас.
Работа над ошибками
Пожалуй, главной проблемой стало большое число задач (вне зависимости от объема работ для их решения), что растягивало сроки выполнения. Заказчик был недоволен, прозрачность процесса оставляла желать лучшего. Появилась и другая проблема: плохо работала обратная связь с заказчиком. Он не интересовался, как его задачи декомпозируются, в каком порядке берутся в работу, что и когда он получит на выходе. Отсюда и непонимание реальных сроков производства работ. Третьей проблемой стало то, что сами разработчики начали терять понимание того, как конкретная задача влияет на общие цели команды.
Сохраняя приверженность гибкому подходу (что обеспечивало скорость работы, гибкость и оперативную реакцию), мы так изменили наш процесс:
- 1. Формализация процесса сбора требований, ведение бэклога
Мы договорились об общих правилах ведения и наполнения бэклога, когда все требования собираются, а аналитик расставляет акценты.
Заказчикам это даёт уверенность в том, что их задачи не потеряются, а разработчикам – возможность получать правильно описанные задачи с заранее проставленным приоритетом (в дальнейшем это поможет избежать лишних итераций по переделыванию функционала).
- 2. Story Mapping
Мы начали активно применять User Story Mapping, этот инструмент стал хорошим подспорьем для вовлечения заказчиков в обсуждение задач и их декомпозиции. Для всех участников рабочего процесса стало понятнее, что делается для выполнения конкретной задачи и как это решение повлияет на конечный продукт.
После успешного применения Story Mapping мы подходим к инструменту Impact Mapping. Он позволит глобально оценить влияние каждой доработки на общие цели и расставить акценты.
- 3. Введение классов сервисов
Мы выделили несколько направлений внутри процесса разработки и разделили на классы все сервисы, разрабатываемые разными командами. Это позволило изолировать команды разработчиков, благодаря чему программистов перестали отвлекать сиюминутными задачами других проектов, а заказчики и аналитики поняли возможности каждого направления разработки и строили свои цели эффективнее.
- 4. Точный «Канбан»
Для всех сотрудников (заказчиков и R&D) были проведены тренинги, на которых им рассказали про методологию, основные принципы работы и инструменты, позволяющие использовать «Канбан» с максимальной эффективностью.
- 5. Ограничение числа задач, одновременно находящихся в работе, в том числе по классам сервисов
Эта ключевая практика Канбана и позволила нам увеличить прозрачность процессов разработки для заказчиков. Мы посчитали среднее время выполнения задач и вычислили максимальное их количество по каждому направлению, которое необходимо для удовлетворения требований заказчиков. Поэтому, чтобы гарантировать качество и сроки работ, мы рассматриваем только задачи, с которыми точно справимся.
- 6. Еженедельные встречи с заказчиками
Мы не смогли польностью отказаться от еженедельного планирования, поэтому оставили еженедельные встречи с заказчиками, на которых обсуждаются статусы этапов разработки, определяется, какие задачи переводятся из бэклога в ToDo, принимаются выполненные и протестированные работы.
Ключевые встречи:
• Планирование
Участники: Заказчики, Руководители
Цель встречи: наполнение TODO из Backlog
Еженедельно
• Приемка
Участники: Заказчики, Руководители, Команда
Цель встречи: Приемка результатов работы команды
Еженедельно
- 7. Ежедневные встречи (стендап-митинги) для команд разработчиков
Мы стали устраивать еженедельные встречи для всей команды. Они устраивались и ранее, чтобы вся команда была в курсе общих процессов. Теперь делается упор на технические задачи, определяется, кто из разработчиков будет вести конкретные задачи, какие ранее выполненные работы закрываются, формируются планы по разработке. Это стало действительно эффективным инструментом.
Продолжение следует.
Комментарии (3)

andrewnester
27.10.2015 10:29+2так а чем использование данных методологий для Big Data проектов отличается от их использования в не BigData?
Ivan22
27.10.2015 10:41-4У нас то же самое. То же пришли к канбану.
Только похоже дальше продвинулись.
Чего будет дальше:
1. Этап моделирования архитектором, после анализа. Нужно когда разработчиков много, проект большой, и реализацию нужно выполнить правильно, с точки зрения архитектуры системы.
2. Этап ревью. Ну тут понятно. У нас не только техническое ревью, но и даже ревью анализа есть.
3. Полноценный этап тестирования. Ни какой uat не проведет регрес тестирование и не проверит, что не поломалось старое, или соседнее или еще что-нить. Да и вообще полноценные тест кейсы надежнее чем Uat который зачастую идет «на глаз». Но UAT никто не отменяет!!!
ServPonomarev
Гибкие методологии не особо подходят под большие данные. Кодирования на день, расчётов на неделю. И так в каждой реальной задаче.