Так как тема парсинга часто привлекает внимание и вызывает эмоции (в массе негативные), подготовил статью, где ответил на основные вопросы (их получилось 43) с которыми сталкивались в процессе работы и, надеюсь, развеял некоторые мифы.
1. Можно ли зарабатывать на парсинге? Да. Мы стали активно заниматься этим бизнесом в 2018 году и с тех пор к счастью растем. Привожу открытые налоговые данные. В 2022 году надеемся, что результат будет чуть лучше.

2. В чем заключается бизнес на базе парсинга? Бизнес, условно говоря, можно разделить на две части: сбор данных и аналитика. Мы не занимаемся аналитикой (попробовали и поняли, что не потянем) и сконцентрировались только на сборе “сырых” данных. Другими словами — мы ежедневно предоставляем нашим заказчикам итоги парсинга в формате CSV/XML.
3. Что такое аналитика? Мало собрать данные, с ними надо уметь работать. Например, сервисы, которые занимаются аналитикой маркетплейсов. Эти команды парсят данные и сразу их обрабатывают в удобном для использования виде. Как упоминал ранее, мы попробовали и не справились. Почему? Нужно очень хорошо знать предметную область, чтобы сделать качественную аналитику. Мы же парсим все, что “шевелится”: ) и далее наши клиенты сами работают с этими данными.
4. Что клиенты делают с данными? Анализируют, но как — мы не знаем. Наша задача обеспечить поставку на ежедневной основе полных данных. Знаю, что часть клиентов загружают данные в 1С для удобства работы менеджеров, кто-то работает с PowerBI/Google BigQuery, а кто-то просто предпочитает Excel и открывать файлы по протоколу WebDav (у вас файлы будут доступны в проводнике Windows, как будто они находятся локально).
5. Что вы парсите? Все то, что в открытом доступе и доступно к сбору руками человека. Например: цены на товары, наличие по магазинам и т. п. Мы не занимаемся парсингом сайтов, где требуется указать логин- пароль (или эти данные должен предоставить сам клиент, понимая, что риски на блокировку полностью на его стороне, но стараемся отговаривать от таких решений).
6. Какой средний чек в этом бизнесе? С некоторой погрешностью можно назвать сумму 15 000 руб. в месяц. Но учитывая, что это бизнес больше проектный, чем продуктовый, разброс цен может быть большой. У нас есть клиенты, которые платят 400 000 р. в месяц за большой набор данных, а есть совсем “малыши” с чеком 5 000 р. в месяц.
7. В чем плюсы и минусы этого бизнеса? 80% клиентов ожидают регулярные данные (ежедневно, еженедельно), что позволяет применять подписную модель (иными словами — регулярные платежи). Минус в большой конкуренции и низкой стоимости входа.
8. Этот бизнес масштабируем? Да, но не так просто, как хотелось бы. Любой новый клиент (если он крупный), требует усиление команды разработчиков.
9. Сколько у вас сейчас персонала? 5 разработчиков full time в штате и команда поддержки (сотрудники, которые занимаются ежедневным тестированием результатов суточного парсинга). У нас очень молодая команда, ребята учатся (магистратура, бакалавриат) и им очень интересно заниматься парсингом, особенно если этому противодействуют.
10. Почему вы занялись этим бизнесом? Совершенно случайно. Нас попросили собрать цены с Леруа Мерлен. Попробовали, получилось ну и закрутилось: ).
11. Много поддержки? Очень. Поддержка фактически прямо пропорциональна количеству сайтов, которые парсим. Любое изменение разметки сайта может привести к тому, что парсинг сломается. Мы всегда предупреждаем клиентов, что такие риски существуют, но от этого объем работы не уменьшается).
12. Как клиенты получают данные? После многих экспериментов, мы остановились на частном облаке на базе NextCloud и я могу смело его рекомендовать. Удивительно устойчивое и бесплатное решение, регулярно обновляется, есть документированное API. Мы ежедневно выгружаем огромный объем данных на это облако в виде файлов, а клиенты забирают информацию удобным способом: API, WebDav, браузер. Звучит не так уж сложно, но как показал опыт — работает.

13. Сколько у вас серверов задействовано? Недавно заказали 6-й. Ранее мы парсили с VPS/VDS, но оказалось, что экономически целесообразнее парсить с помощью bare metal серверов (иными словами “железные” выделенные сервера), которые мы арендуем в нескольких ДЦ. В месяц сервера нам обходятся в ~70 000 руб. и сейчас, к сожалению, сильно подорожала аренда. Перед арендой мы рассказываем хостеру (ДЦ) в чем суть нашего бизнеса, как мы работаем и т. п. Очень редко (может быть раз в год) поступают жалобы на работу наших парсеров хостеру, но всегда вопросы урегулируем.
14. Насколько этот бизнес устойчив к санкциям? Мы, откровенно говоря, ничего не заметили. 100% наших клиентов в СНГ (80% Россия, 20% Казахстан, Беларусь и т. п.). Разве что пришлось открыть еще один расчетный счет помимо Альфа-Банка (клиенты из Казахстана не могли оплачивать).
15. Какие типы сайтов вы парсите? Любые, где есть открытые данные. Подчеркну — парсинг фактически означает автоматизацию того, что может сделать руками человек. Чаще всего (90%) просят парсить Интернет-магазины, которые относятся к категории ТОП 100.
16. Были судебные угрозы? Пару раз мы получали предупреждающие письма от компаний, которые находили у нас примеры парсинга их сайтов. Последний раз я получил письмо от CEO Aviasales, который угрожал судом и жесткой расправой, хотя по факту мы их не парсили на момент обращения. Претензия была оформлена некой нанятой юридической компанией с непонятными трактовками, т. к. видимо юристы не совсем поняли о чем идет речь вообще. Я думаю, что когда Aviasales столкнулся с массовым парсингом, они сделали рассылку претензии по всем компаниям, которые публично заявляют, что занимаются этим бизнесом на тот случай, что кто-то отреагирует. Было еще обращение от компании, которая отслеживает упоминание товарных знаков (простите, могу ошибаться, кажется это были brandmonitor), чтобы мы убрали упоминание Эльдорадо. Нам тоже грозили небесными карами, но чуть успокоились и перешли в более конструктивное русло, когда мы запросили официальные документы на подтверждение представления интересов компании Эльдорадо в этом вопросе. Чтобы сгладить вопрос, мы теперь выкладываем примеры парсинга вот с таким названием (см. ниже). Полная чепуха, понимаю, но юридически безопаснее (нет времени и желания заниматься юридической бюрократией).
17. Можно ли получить льготы от государства, как ИТ- компании? Пытаемся, т. к. фактически мы работаем с базами данных (в законе есть соответствующие формулировки). В Сколково точно не возьмут: )
18. Парсить этично? Сложный вопрос, полагаю что да. Вообще мне кажется, что бизнес должны работать в правовом поле, а не рассматривать свое существование как этичное или нет. Вопрос философский, но обсуждаемый, т. к. парсинг зачастую вызывает негативные эмоции. Никто не любит, если их парсят. Но я сотрудникам всегда говорю — при общении с новым клиентом, если мы вдруг парсим его сайт, обязательно расскажите про это.
19. Парсить законно? Да, если вы соблюдаете некоторые моменты. Я не буду приводить развернутую юридическую оценку нашего бизнеса, но если говорить коротко — то любая общедоступная информация может собираться, если это не наносит вред источнику и не нарушает прав. Канцелярским языком это звучит следующим образом:
Организация вправе осуществлять автоматизированный сбор информации (парсинг сайтов), размещенной в открытом доступе на сайтах в сети интернет если соблюдаются следующие условия:
Информация находится в открытом доступе и не защищается законодательством об авторских и смежных правах.
Автоматизированный сбор осуществляется законными способами.
Автоматизированный сбор информации не приводит к нарушению в работе сайтов в сети интернет.
Автоматизированный сбор информации не приводит к ограничению конкуренции.
Вот, например, обычный запрос от клиента:
“Здравствуйте. Мне нужен парсер, который будет ежедневно собирать остатки с сайта поставщика и отдавать их в виде excel файла или xml фида.”
20. А что относительно авторского права? Не нужно просто парсить (или использовать) информацию, которая может быть объектом авторского права. Например описания товаров. К счастью, 99% клиентов просят нас собирать фактические данные, которые не попадают под эту категорию: цена, бренд, категория и т. п. Тут уместно упомянуть Яндекс/Google, которые парсят ваш сайт, собирая контент с страниц в свой индекс. Владельцам сайтов это нравится, т. к. это увеличивает посещаемость, а парсинг не нравится, т. к. потенциально усиливает конкурента. Но эти роботы действуют одинаково.
21. Я написал в оферте на моем сайте, что запрещаю парсинг! Простите, но это никого не интересует и вашу оферту никто читать не будет.
22. Усложняю вам парсинг — цену выведу картинкой! Хоть звучит смешно, но встречали и такое на ряде сайтов. Пожалуйста, не тратьте свое время — библиотеки распознавания изображений работают великолепно. Вы же не будете цены на ваши товары выводить следующим образом:

23. Я тогда ограничу количество запросов, а потом попрошу решить капчу (captcha) и это усложнит вам работу сильно! Есть очень дешевые сервисы ручного решения капчи. Упрощенно говоря, когда наши роботы встречают капчу, по API мы подключаем этот сервис, которые перекидывает задачу оператору для ручного решения. В месяц мы тратим порядка 4 000 р. на оплачу этих сервисов.
24. Вы сильно нагружаете сайты, которые парсите? Нет. Никто не хочет сделать так, чтобы владельцы сайта, раздраженные мощной, паразитной нагрузкой от парсеров, стали внедрять механизмы защиты, которые просто усложняют нам «жизнь”. Если говорить про абсолютные цифры, то нормальным считаем парсинг данных с карточки одного товара в 3-4 секунды. К сожалению, не все придерживаются такой парадигмы и ко мне лично обращались владельцы сайтов, которые уточняли не мы ли их парсим, т. к. нагрузка была запредельной. Чаще всего причина в »кривых руках” разработчиков.
25. Чем парсинг отличается от DDOS? Тем, что наша задача — автоматизированный сбор данных, на регулярной основе, в течении длительного времени. DDOS преследует совершенно иную цель —” сломать” сайт.
26. Вы взламываете сайты? Нет и не планируем. Бывает, что нас просят «как-то решить” с получением данных, которые защищены паролем. Но это не наш бизнес и вообще это не бизнес, а некая »тема” относящаяся уже к darknet.
27. Можно ли защититься от парсинга? Нет, но можно усложнить парсинг до такой степени, что мы начнем отказывать клиентам, т. к. для клиента это будет экономически невыгодно оплачивать нашу исследовательскую работу по обходу защиты. Все что доступно без пароля в сети Интернет так или иначе может быть собрано автоматизированным способом.
28. Все же, какой самый лучший способ защиты? Выложить данные в формате XML и дать ссылку. Вас гарантированно перестанут парсить и будут забирать данные в удобном виде. Звучит, конечно, как некая утопия и я понимаю, что мало кто последует данному совету, но это единственный способ избежать парсинга.
29. У кого самая сложная защита? АВИТО. У них достаточно ресурсов, чтобы заниматься этим вопросом на очень высоком уровне. Причем, как я думаю, в основном компании защищаются не от самого парсинга, а от DDOS — атак, а парсинг, образно говоря, попадает “под раздачу” защитными фильтрами.
30. Нужно ли мне внедрять на своем сайте защиту? В случае промышленного парсинга, лично мое мнение, — защита не очень поможет, но может усложнить задачу. Но совершенно точно любая защита может отсеять «студентов”, которые вчера прочитали книжку "Парсинг с помощью Python для чайников”. Бизнес устроен так, что чем сложнее парсить сайт, тем дороже будет цена для конечного клиента и тем больше усилий будет приложено командой для решения задачи.
31. Много у вас конкурентов? Очень. Много фрилансеров-самозанятых, которые предлагают услуги парсинга значительно дешевле наших. Насколько мне известно, к ним обращаются за разовым услугами, т. к. если заниматься парсингом регулярно, должна уже быть команда специалистов в штате на поддержку.
32. Как вы обходите защиту? Прокси. Разные. Много. Смена fingerprint (цифровой отпечаток браузера). Плюс — опыт команды, который накопился за несколько лет. Чем сложнее защита, тем медленнее парсинг, т.к. нам приходится, например, решать капчу - а это время. Сайты на 5-6 запрос просят решить капчу, парсер ждет решения человеком, далее продолжает работу (меняя fingerprint), до следующего запроса на решение.
33. Что думаете про cloudflare? Научились обходить. Но отмечу, что этот сервис в основном ставят для CDN/DDOS, а не для защиты от парсинга. С введением санкций количество сайтов с ним упало. Qrator отличное решение для защиты от DDOS - атак тоже добавляем нам сложностей :)
34. Как вы ищите клиентов? Тут мы не оригинальны и все клиенты приходят через сайт с помощью органического трафика (Яндекс и Google 50-50%). Мы пытались давать контекстную рекламу, но отдачу не увидели. Самое результативное, что догадались сделать — публиковать примеры (статичные) парсинга известных компаний на своем сайте с возможностью их скачать и изучить. Дальше люди просят данные уже в динамике и мы заключаем договор. Пример ниже, цифры по скачиванию честные. Сам сайт сделан на WordPress, ничего сложного.

35. На что конкретно заключается договор? Автоматизированный сбор неструктурированных данных с открытых источников в сети Интернет с преобразованием в структурированные данные. Собственно так и есть.
36. Какой запрос на парсинг самый частый? “Соберите мне, пожалуйста, контакты маркетологов фитнес-центров г. Казань”. Это не шутка, именно подобные запросы мы получаем чаще всего. Задача не имеет роботизированного решения, т. к. мы не работаем с персональными данными людей, которые еще и не хотят их делать публичными. Мы можем сделать, например, базу Интернет-магазинов косметики, с помощью анализа title/description сайтов в зоне. RU/. РФ и собрать публичные адреса электронной почты и телефоны. Но не решить задачу по сбору личных контактов ЛПР.
Какие еще интересные запросы вы получаете? Вот, пожалуйста. Задача тоже не имеет никакого решения.
“Здравствуйте, хотим получить базу стоматологических клиник. При возможности параметры: в городах больше 500,000. Более 4 кабинетов в клинике. Средний чек больше 7000. + Имейл и телефон ЛПР (рабочие, не пустые)”
37. Как делают базы компаний? Создание баз компаний с открытыми данными — производная парсинга. Настраивают роботов, которые обходят все сайты в Рунете (где-то 6.5 млн.) и собирают общедоступные данные. Таким образом можно создать, например, Базу всех ресторанов и кафе, Базу оптовых компаний и т. п. В любом случае, обрабатываются только общедоступные, публичные корпоративные данные.
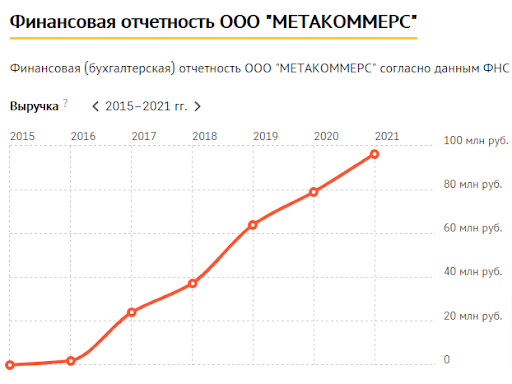
38. А вы делаете матчинг товаров? Нет. Может быть зря, но наша задача — поставлять данные регулярно, в запрашиваемом клиентом объеме. Признаю, что если сделать “шаг вперед” и заняться матчингом товаров между разными продавцами и продавать аналитическую отчетность, мы могли бы добиться больших результатов. Могу ошибаться, но именно этим занимаются наши конкуренты (или смежники, так лучше назвать) и финансовые результаты по выручке у них явно лучше (см. ниже, я завидую :). Что удерживает? Ресурсоемкость. Матчить (сопоставлять) между собой товары по названию между разными игроками на постоянно основе очень сложно. Мы пытались внедрять различные алгоритмы, которые частично автоматизируют этот процесс, но результаты были неудовлетворительные (попробуйте, например, сопоставить аптечные препараты с фасовкой-граммовкой-литражом).
39. Почему крупные компании заказывают парсинг на стороне, а не делают сами? Причины разные. Очень крупные, публичные компании, сталкиваются с рекомендациями своих юристов/СБ, чтобы никоем образом не быть самим вовлеченными в автоматизированном сборе данных (это не домыслы, а опыт общения). Другие компании не хотят заниматься наймом дополнительных разработчиков, управлять ими, тестировать результаты и т. п.
40. Компании вообще знают, что вы (или кто-то другой) их парсит? Часто новые клиенты спрашивают (в шутку или нет), а не парсим ли мы их случайно!? Наша позиция — мы честно отвечаем как есть. Только один раз, крупный клиент рассердился и сказал, что если мы хотим с ним работать, прекратить парсить его. В итоге мы с ним не работаем.
41. Вы храните данные исторические? Нет. Нам не "по карману" хранить историю ежедневного среза цен по всем магазинам. Звучит очень интересно, но нашими силами это не потянуть. Мы регулярно удаляем данные старше 7 дней.
42. Можете выйти на глобальные рынки? Боюсь что нет. Это больше проектная деятельность, чем продуктовая. Нужен менеджер по работе с клиентами с отличным английским, поддержка на этом языке и т.п. Но совершенно точно - можно работать на локальных рынках и зарабатывать, т.к. услуга востребованная. Чем больше информации, чем активнее идет цифровая трансформация (простите за этот изъезженный термин), тем больше востребованность превращения неструктурированных данных в структурированные!
43. Где можно почитать больше информации? Я регулярно пишу в канале Телеграмм наш опыт. Мне можно писать напрямую в Телеграм @maximkulgin
Спасибо за внимание, старался быть краток и по делу — не стесняйтесь задавать свои вопросы в комментариях.
p. s. Не ругайтесь: ) я понимаю, что парсинг сразу настраивает на негатив. Но это обычный бизнес, которым, уверяю вас, занимаются 80% торговых компаний (в том или ином виде) .
Комментарии (60)

lolipoka
07.09.2022 14:40+2попробуйте, например, сопоставить аптечные препараты с фасовкой-граммовкой-литражом
С аптечным ассортиментом как раз всё достаточно просто, т.к. он не такой большой по сравнению с каким-нибудь китайским ширпотребом на маркетплейсах. По сути, единственная проблема - фасовка, масса и т.д. у всех продавцов в разном порядке идёт.

ti_zh_vrach
07.09.2022 16:56+6Я тут кончено мимокрокодил, но есть, что сказать по поводу аптечной номенклатуры.
Интересно становится, когда в наименовании лекарственного препарата есть МНН. Производителей может быть десятка два. Название производителя могут прибавлять, а могут не прибавлять к названию препарата. Одни укажут суффиксы типа «акос» и «гексал», другие нет. А ещё одну и ту же дозировку могут указать и в мг, и в мкг, и в г. Физраствор может быть и в мл, и в л. Это всё может быть и без сокращений. Или вообще размерность не укажут. Количество таблеток бывает «таб. №30», а бывает «упаковка контурная ячейковая (10) №3». Или ещё как-нибудь. И это без изделий медназначения с дичайшим бардаком в сокращениях внутри наименований.
По поводу величины ассортимента предлагаю сходить в этот реестр, прибавить сюда БАДы с ИМН. Если мне не изменяет память, только номенклатура списка ЖНВЛС представляет собой физически 2-3 пачки бумаги А4 с 9-м кеглем на обеих сторонах. По-моему до сих пор лежат в торговом зале почти каждой аптеки, на столике.
Не знаю, как всю эту красоту переносят из аптечных баз на сайты, но там вряд ли что-то сильно сложнее копипасты.

alex_ak1
07.09.2022 15:31+1Если не секрет, то примерно сколько данных в гб набегает за неделю парсинга и со скольки сайтов?

makasin4ik Автор
07.09.2022 15:32+1500 сайтов, где-то 20 Гб в неделю. Но мы чистим не храним

Upsarin01
07.09.2022 18:27+820 Гб в неделю? Что-то совсем мало а точнее не о чём.
Может быть 20 ТБ?

waxtah
08.09.2022 10:45Это же не видео и не картинки, а текст насколько я понимаю.

FreeNickname
08.09.2022 12:51+3Просто с 20 Гб в неделю непонятно, почему хранить их – проблема. Это примерно 1 Тб в год. Даже с RAID и бэкапом 3-2-1 хранить 1 Тб в год – это для бизнеса копейки.
Конечно, чужие деньги считать – так себе занятие, да и нет смысла платить за что-то, что не приносит прибыли, но, мне кажется, интерес к историческим данным вполне мог бы быть, а хранить данные хотя бы за последний год при 20 Гб / неделю обойдётся очень дёшево.
makasin4ik Автор
08.09.2022 18:57Надо уметь делать аналитику . А мы ещё слабы в этом
FreeNickname
08.09.2022 19:01+3Если что, я вас не критикую, просто удивляюсь :) Мне просто кажется, что хранить пару терабайт вместо 20 Гб проблемой быть не должно, а если / когда вы вдруг решите заняться аналитикой – они у вас уже будут. А то ведь с данными такая подстава, что чтобы проанализировать данные за год, нужно вначале собирать их год :)
Плюс, возможно, вы могли бы предложить сторонним компаниям исторические данные для их аналитики на продажу. Возможно, покупатель бы нашёлся. Даже если найдётся один клиент, мне кажется, это окупит стоимость всего решения :)
makasin4ik Автор
08.09.2022 19:04+2Понимаю. Но честный ответ - так сложилось . Надо что то менять, но руки не доходят. Рутина

JayDi
08.09.2022 13:11Если это инкрементный парсинг только новых данных, то нормальные цифры. Там на трафик будет больше уходить на порядки (например, на 1 гб данных потребуется скачать 10 тб текстового трафика).

solomax2013
08.09.2022 20:04Текстовые данные (CSV), сжатые в ZIP архивы. Не знаю точно, сколько в распакованном виде бы весило, но всё же текст сжимается достаточно хорошо

FlashHaos
07.09.2022 21:16+2Для одного из топ5 продавцов смартфонов велосипедил лет пять назад парсинг айфонов с сайтов основных конкурентов и телеграмм бота с данными. Было очень интересно, хотя и был удивлён, что это так и осталось инициативой одного аналитика (который попросил меня помочь), а после ухода его из компании - сошло на нет.
Скажите, почему железные северы оказались выгоднее виртуальных? Не очень ясно, как это может быть. А если бы не легаси, наверное лямбда и аналоги для этой задачи идеально подходят?
Insurgent2018
08.09.2022 12:11+3при постоянной прогнозируемой нагрузке и стабильном коде - железо будет в этому конкретном случае(про статью) - дешевле.

12rbah
08.09.2022 12:13Скажите, почему железные северы оказались выгоднее виртуальных?
Те кто предоставляют виртуальные сервера не всегда разрешают парсинг и в один момент вся система может перестать работать "из-за большого числа подозрительных запросов мы решили на время ограничить... обратитесь в тех. поддержку"

AVL93
08.09.2022 12:35+3Сайт ЦИК с результатами выборов пробовали парсить? А то, помню, там очень «оригинальная» защита от парсинга в виде кастомного шрифта, встречалось ли такое где-то еще?

F0iL
08.09.2022 12:44Автор упомянул парсинг посредством распознавания текста из изображения, так что в принципе парсинг подобных извращений от ЦИКа им сделать будет совсем нетрудно (на Хабре в комментах это вообще решили десятистрочником на Javascript использующим Canvas + Tesseract)

weirded
08.09.2022 14:30+1Не пробовали с некоторыми часто парсимыми сайтами со своей стороны договариваться о предоставлении структурированных данных (условно - платное API, например)? Им нагрузка меньше, вам быстрее это всё получится обработать, может со своей стороны сэкономленное время как-то им компенсировать.

tearexs
08.09.2022 14:50Скорее всего, после того, как владельцы таких сайтов узнают о факте парсинга, они постараются сделать данные менее читаемыми :)

Vsevo10d
08.09.2022 14:32Я правильно понимаю, что если парсить и хоть чуть-чуть все-таки анализировать или там раскладывать по категориям а-ля "принадлежащих Императору, набальзамированных, прирученных", то можно зарабатывать еще больше?
makasin4ik Автор
08.09.2022 18:58Да. Вы правы. Но здесь надо очень серьезно вникать в аналитику данных

d2d8
08.09.2022 16:09+1Добавил бы, что частенько у топов есть свои приложения для телефонов и они, как правило, тянут всё через api, перехватить пару запросов от такого приложения достаточно чтобы понять как распарсить всё. При этом на запросы к api от мобильных часто нет никаких ограничений по RPS, а то и есть возможность качнуть всю базу целиком.

uvlad7
08.09.2022 18:55+2Приложения зачастую защищают от перехвата трафика, не только чтобы парсерам жизнь усложнить, но и для безопасности, если например платежи встроены. Запросы могут подписываться. В общем больше нюансов, чем на сайтах. Это всё обходится, конечно, и в каком-то конкретном случае приложение может быть защищено слабее, чем сайт, но в среднем собирать данные из приложения сложнее. Ну и плюс данные в приложении и на сайте могут отличаться.
d2d8
08.09.2022 19:56В теории да. Иногда приходится ковыряться и в самом приложении. Но профит от парсинга api в итоге компенсирует затраченное время. Кстати, иногда сайты тупят и падают, иногда в процессе парсинга, что создаёт проблемы качества данных. Api делают это гораздо реже. Скорость, полнота и простота парсинга куда лучше. Во всяком случае в своих проектах я предпочитаю найти/расковырять api, нежели регулярками парсить килотонны html.
Опять же добавлю, что если уж парсить html то как правило проще это делать с мобильными версиями сайтов, если таковые имеются.
uvlad7
08.09.2022 22:18Я бы не противопоставлял скачку веб-версии скачке через апи, это разные категории. Тут смотря как качать, конечно, можно через браузер страницы открывать (puppeteer, selenium и т. д.) и разбирать DOM, не работая с api сайта напрямую.
Но при больших объёмах это плохо масштабируется. А если качать без браузера, просто делать http запросы и разбирать респонсы, то и веб версии обычно через апишку качаются. А если нет json api на сайте, то часто и мобильное приложение получает html и отображает через webview. Правда ещё чаще это какой-нибудь мелкий сайт без приложения вообще.
А парсить html регулярками в любом случае не стоит, xpath обычно.

tommyangelo27
08.09.2022 16:47+1Спасибо за интересную статью. По поводу легальности — у меня есть одно замечание:
Но эти роботы действуют одинаково.
Да, но суть не в роботах, а в том, что дальше происходит с данными. В большинстве случаев можно совершенно легально собирать данные из открытых источников для личного использования, для научной работы или для обучения.
Но как только вы эти данные начинаете собирать с целью передачи третьим лицам (в данном случае вашим заказчикам), то тут уже _могут_ возникнуть нюансы. Пример с Гуглом был бы корректен, если бы Гугл данные с вашего сайта передавал кому-то дальше.
Я абсолютно не в теме законодательства вашей страны, но полагаю, что опытный юрист может зацепиться именно за факт последующей передачи данных, а не их сбора как такового.makasin4ik Автор
08.09.2022 18:56Но человек может собрать и передать. Мы же просто автоматизируем . В общем пока работаем :)

khgvghv
08.09.2022 17:26+1Вообще мне кажется, что бизнес должны работать в правовом поле, а не рассматривать свое существование как этичное или нет.
По скользкой дороге ходите..
inferrna
08.09.2022 18:07Я парсю, в основном, финансовые данные. Есть 4 варианта:
Когда есть нормальный API, запросы которого можно отловить через отладчик браузера. Готовые данные, бери и юзай. Только не забыть подставить заголовки, типа, тоже браузер.
Данные отдаются в виде HTML. Вариант похуже, зажмуриваемся и парсим.
Используется хитрый API с защитой по токену, с использованием кук и прочих барьеров. Такой, например, используется на spbexchange. Тогда приходится запускать полновесный браузер с селениумом.
Данные в виде картинок, например, графики котировок. Признаём своё поражение, ищем жертву посъедобнее.
namaz_kamazov
08.09.2022 18:56С помощью selenium/pupputeer такое реализуемо?
makasin4ik Автор
08.09.2022 18:56Да

alekseyefremov
08.09.2022 22:57+1Можете посоветовать какой либо дефолтный набор ключей для chromedriver?
В сети много «советчиков», данные от которых или безнадежно устарели, или не имеют отношения к боевому использованию.

StrikeBack
08.09.2022 18:56Подскажите пожалуйста как решили проблему с приемом платежей из Казахстана?

hbn3
09.09.2022 00:35Интересно встречаются дублирующие запросы — т.е. несколько клиентов просят один и тот-же Леруа?

cry_san
09.09.2022 05:40Обязательно. Настроили парсинг 1 раз, а продажа одной и той же базы идет нескольким клиентам.
hbn3
09.09.2022 16:52Мне кажется что в период затишья (когда не все заняты заказами), имеет смысл настраивать парсинг каких-нибудь популярных сайтов (типа хабра) и выкладывать в общий доступ бесплатно. Если ещё в добавок к общему ещё и дельты выкладывать, вообще супер.
Думаю что как маркетинговый ход, себя должно многократно окупить.

BackDoorMan
09.09.2022 18:14+1У авито одна из самых топорных защит, попробуйте обойти например DataDom. Хотя, я думаю, вы пытались)

AcidLynx
09.09.2022 21:07+1Круто! Спасибо!
На заре своего фриланса занимался парсингом тоже. Очень интересная и динамичная работа.
Удачи в таком труде. Судя по вашему тексту, у вас принципиальная позиция делать все в открытую и на законных основаниях. Достойно!
logout
Чем парсите? Можете в двух словах об архитектуре?
makasin4ik Автор
.net/chromium
logout
Не раскрыта тема как вы парсите веб апликации, когда дата не ХТМЛ?
Vinni37
Судя из слова "chromium", через DOM
maxcat
можно же через их API. Они же обычно через понятный json всё передают - даже собо муторно парсить не надо - просто десериализуй и всё!
solomax2013
Если у сайта есть API (используемый, к примеру, JS на сайте для динамического обновления страницы), ничего не мешает дёргать его, получать XML/JSON и уже дальше работать с ним
wavebvg
CEFlib (chromiumembedded) или какое-либо другое решение?
solomax2013
Для работы с хромом используется Selenium. А дальше уже получаем HTML код страницы и возвращаемся к случаю без хрома (AngleSharp для работы с DOM)
available
судя по упоминанию фингепринтов, могу предположить что сишарп+зенно
cry_san
А если ли решение смены фингепринтов для селениума на Java?