SQL – концептуально странный язык. Вы пишете ваше приложение на одном языке, скажем, на JavaScript, а затем направляете базе данных команды, написанные на совершенно другом языке – SQL. После этого база данных компилирует и оптимизирует эту команду на SQL, выполняет её и возвращает вам данные. Такой метод кажется ужасно неэффективным, но, всё-таки, ваше приложение может проделывать сотни таких операций в секунду. Просто безумие!
Но на самом деле всё ещё страннее.
Язык SQL исходно был спроектирован для пользователей-нетехнарей как средство взаимодействия с базой данных. Сегодня же им пользуются почти одни лишь программисты, и современные приложения просто нашпигованы SQL-запросами.
Почему так случилось, что этот язык, сделанный «для представителей бизнеса», стал стандартным инструментом в индустрии разработки приложений?
Одно из основных достоинств SQL заключается в его декларативности. Это значит: вы сообщаете базе данных, что хотите сделать, но не сообщаете, как это сделать. Ваша база данных знает ГОРАЗДО больше вашего о той информации, с которой приходится работать, поэтому должна быть в состоянии значительно грамотнее решать, как лучше выбирать и обновлять эти данные. В таком случае у вас появляется возможность улучшить ваш слой данных, добавляя индексы и даже реструктурируя таблицы — и вся эта работа минимально отражается в коде вашего приложения.
Среди встраиваемых баз данных SQLite уникальна не только благодаря своему транзакционному уровню хранения данных, построенному по принципу Б-дерева, но и благодаря собственному надёжному движку выполнения SQL. В этой статье мы подробно разберём, как SQLite синтаксически анализирует, оптимизирует и выполняет ваши SQL-запросы.
Машина-сэндвичеделка
Если ранее вам доводилось читать в блогах статьи о характерном для SQLite формате файлов, где все метафоры построены вокруг изготовления сэндвичей — например, в журнале откатов и в WAL, то, вероятно, у вас уже пробуждается аппетит. Кроме того, вы, должно быть, знаете, какая эта нудная работа — складывать сэндвичи вручную. Поэтому давайте и в нашем посте продолжим сэндвичевую аналогию и поговорим о машине-сэндвичеделке.
Эта машина будет выполнять несколько задач:
Принимать заказ на изготовление сэндвичей.
Определять наиболее эффективный способ их изготовления.
Готовить сэндвичи и передавать их вам.
Процесс построения и выполнения SQL-запросов подобен такому собиранию сэндвичей, правда, здесь всё не так вкусно. Давайте в нём разберёмся.
Учим машину считать
Сначала нужно выдать машине заказ. Передаём ей бланк, на котором записано:
Make 3 BLT sandwiches hold the mayo, 1 grilled cheese
Сделай 3 сэндвича с беконом, латуком и томатом, без майонеза. Ещё сделай 1 сэндвич с жареным сыром
Для нашего компьютера этот заказ — просто последовательность отдельных символов: M, a, k, e, т.д… Чтобы помочь компьютеру его понять, мы должны сгруппировать эти символы в слова или, точнее, «токены». Этот процесс называется «токенизацией» или «лексическим анализом».
После токенизации видим следующий список токенов:
"MAKE", "3", "BLT", "SANDWICHES", "HOLD", "THE", "MAYO", ",", "1", "GRILLED", "CHEESE"
Далее начинается этап синтаксического разбора (парсинга). Парсер берёт поток токенов и пытается каким-то образом их структурировать, так, чтобы эта информация стала понятна компьютеру. В результате получается так называемое «абстрактное синтаксическое дерево» или AST.
Такое AST для нашей команды по изготовлению сэндвичей может иметь вид:
{
"command": "MAKE",
"sandwiches": [
{
"type":"BLT",
"count": 3,
"remove": ["MAYO"]
},
{
"type": "GRILLED CHEESE",
"count": 1
}
]
}Отсюда начинает просматриваться, как можно взять это определение и приступить к готовке сэндвичей на его основе. У нас был совершенно беспорядочный массив текста, а мы обогатили его структурой.
Лексический анализ и синтаксический разбор SQL
SQLite действует таким же образом, когда читает SQL-запросы. Сначала она группирует символы в токены, например, SELECT или FROM. Затем парсер строит структуру для представления такого запроса.
В документации по SQLite предоставляются полезные синтаксические (т.н. «железнодорожные») диаграммы. Они представляют пути, следуя по которым, парсер может потреблять потоки токенов. Определение SELECT показывает, как можно начать с ключевого слова WITH (для обобщенных табличных выражений), а затем перейти к условиям SELECT, FROM и WHERE.
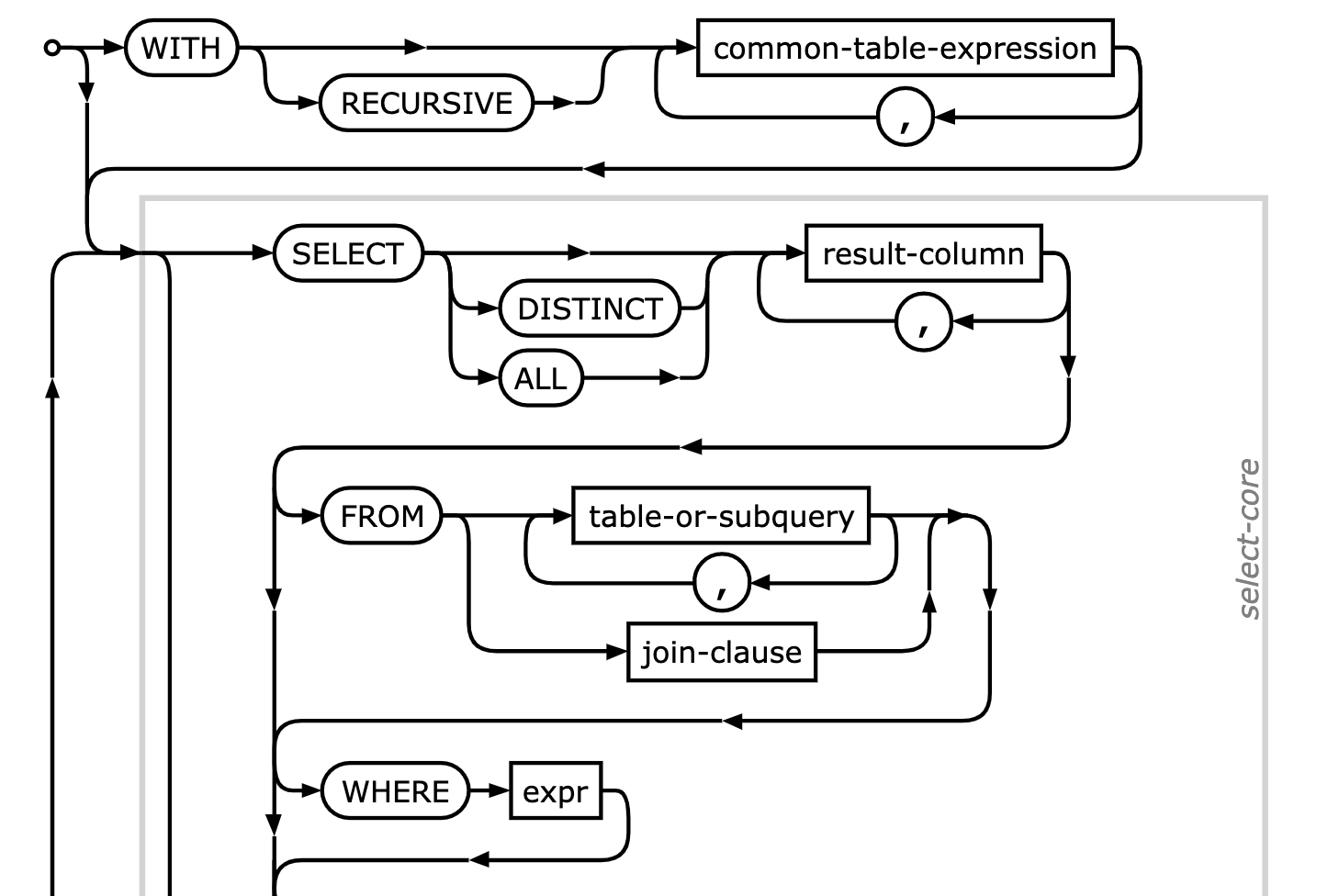
Когда парсер закончит работу, он выведет структуру с очень точным названием Select struct. Если бы у вас был примерно такой SQL-запрос:
SELECT name, age FROM persons WHERE favorite_color = 'lime green'
То на его основе получилось бы абстрактное синтаксическое дерево вида:
{
"ExprList": ["name", "age"],
"Src": "persons",
"Where": {
"Left": "favorite_color",
"Right: "lime_green",
"Op": "eq"
}
}Выясняем, как лучше всего поступить
Итак, теперь у нас есть абстрактное синтаксическое дерево, на основе которого заказывается состав сэндвичей, и мы планируем переходить к приготовлению нашего первого сэндвича, верно? Не совсем.
Абстрактное синтаксическое дерево представляет то, что вы хотите – то есть, пару сэндвичей. Оно не сообщает, как их сделать. Прежде, чем перейти к плану, мы должны определиться, какой путь изготовления сэндвичей оптимален.
При помощи нашей сэндвичеделки можно собрать целое множество разных сэндвичей, так что мы запасёмся всевозможными ингредиентами. Если мы хотим сделать сэндвичище, который сдобрим всеми имеющимися у нас топпингами, то машине стоило бы, ориентируясь на абстрактное синтаксическое дерево, посетить местоположение каждого ингредиента и решить, пойдёт он в ход или нет.
Но для сэндвича BLT нам требуются только бекон, латук и томаты. Работа пошла бы быстрее, если бы мы задали машине посетить только три этих местоположения (по индексу) и переходить только между ними.
SQLite приходится принимать подобные решения, когда она планирует, как выполнить запрос. Для этого она опирается на статистические данные о содержимом своих таблиц.
Ускоряем запросы, руководствуясь статистикой
Когда SQLite рассматривает абстрактное синтаксическое дерево, могут найтись сотни способов доступа к данным, позволяющие выполнить запрос. Самый тривиальный подход – просто считать всю таблицу, проверяя каждую строку, годится ли она нам. Именно такой подход называют «полное сканирование таблицы» — он страшно медленный, если вам нужно выбрать из большой таблицы всего несколько строк.
Другой подход — пользуясь индексом, быстро переходить к интересующим вас строкам. Индекс — это список идентификаторов строк, которые отсортированы в один или несколько столбцов. В данном случае у нас получится вот такой индекс:
CREATE INDEX favorite_color_idx ON persons (favorite_color);
В таком случае идентификаторы для строк со всеми людьми, которым нравится «мальвовый» цвет, окажутся у нас в индексе сгруппированными вместе. Используя индекс при запросе, мы должны сначала считывать позицию в индексе, а затем перейти к строке в таблице. В результате стоимость каждой такой операции (на строку) возрастает, поскольку приходится проводить две операции поиска – но «мальвовый» не нравится почти никому, поэтому и строк в нашей результирующей выборке будет мало.
А что произойдёт, если искать популярный цвет, например, «голубой»? Если сначала выполнить поиск по индексу, а потом переходить в таблице к такому множеству строк, то операция окажется даже медленнее, чем простой полнотабличный поиск.
Поэтому SQLite проделывает с нашими данными некоторый статистический анализ, чтобы выработать (пожалуй) оптимальный рецепт для каждого запроса.
Статистка SQLite хранится в нескольких таблицах "sqlite_stat". Эти таблицы развивались годами, и теперь в них ведётся статистика сразу четырёх видов. Но в новейших версиях SQLite остались в ходу лишь две из них: sqlite_stat1 и sqlite_stat4.
Формат таблицы sqlite_stat1 прост. В ней хранится приблизительное число строк для каждого индекса, а также количество дублирующихся значений для столбцов индекса. Эта грубая статистика эквивалентна отслеживанию простейших средних значений для датасета: они не слишком точны, но их быстро вычислять и обновлять.
Таблица sqlite_stat4 несколько более продвинутая. В ней хранится несколько десятков значений, выборочно взятых со всего индекса. Поскольку SQLite может делать такую значительно более тонкую выборку, очевидно, что эта база данных в принципе понимает, насколько уникальны различные значения в масштабах всего пространства ключей.
Выполняем наш план
Как только у нас будет оптимизированный план сборки сэндвича, прикажем машине его записать. Таким образом, если когда-нибудь в будущем нам поступит такой же заказ, мы сможем повторно использовать имеющийся рецепт, а не разбирать и не оптимизировать заказ каждый раз.
Как же будет выглядеть такой план сборки сэндвича?
План будет составлен как список команд, выполнив которые, машина в будущем снова сможет собрать сэндвич с беконом, латуком и томатами. Мы не хотим писать команды на каждый тип сэндвича, поскольку таких типов может быть очень много. Лучше иметь набор общих инструкций, которые можно было бы многократно использовать, чтобы «спланировать» любой сэндвич.
Например, у нас могут быть следующие команды:
FIND_INGREDIENT_BIN(ingredient_name)– ищет, где находится банка с нужным ингредиентом.FETCH_INGREDIENT(bin)– берёт ингредиент роборукой из банки с нужным ингредиентом (банка находится по номеру).APPLY_INGREDIENT– роборука выкладывает ингредиент в нужный сэндвич.GRILL– собранный сэндвич поджаривается
У нас есть ещё одно требование, на первый взгляд неочевидное. У нас ограничено место на хранение готовых сэндвичей, поэтому мы должны делать всего один сэндвич за раз и проследить, чтобы клиент забрал его прежде, чем мы приступим к готовке следующего сэндвича. Таким образом, мы сможем обработать любое количество сэндвичей, сколько бы их ни содержалось в заказе.
Такой процесс передачи называется сдачей, и для этой цели у нас есть команда YIELD, после которой мы дожидаемся, пока клиент заберёт у нас сэндвич.
Также нам нужен определённый поток управляющих команд, при помощи которых мы можем сделать множество экземпляров определённого сэндвича, поэтому также добавим команду FOREACH.
Итак, в обобщённом виде наш план может иметь следующий вид:
// Делаем сэндвичи с беконом, латуком и томатом
FOREACH 1...3
bin = FETCH_INGREDIENT_BIN("bacon")
FETCH_INGREDIENT(bin)
APPLY_INGREDIENT
bin = FETCH_INGREDIENT_BIN("lettuce")
FETCH_INGREDIENT(bin)
APPLY_INGREDIENT
bin = FETCH_INGREDIENT_BIN("tomato")
FETCH_INGREDIENT(bin)
APPLY_INGREDIENT
YIELD
END
// Делаем сэндвич с жареным сыром
bin = FETCH_INGREDIENT_BIN("cheese")
FETCH_INGREDIENT(bin)
APPLY_INGREDIENT
GRILL
YIELDТакой набор предметно-ориентированных команд и движок, предназначенный для их выполнения, называется виртуальной машиной. Она обеспечивает нам уровень абстрагирования, адекватный для решения поставленной перед нами задачи (напр., готовка сэндвичей) и позволяет реконфигурировать команды — по-разному для разных сэндвичей.
Проверяем виртуальную машину SQLite
Виртуальная машина SQLite устроена схожим образом. В ней есть набор команд для работы с базой данных, позволяющих выполнять шаги, необходимые для выборки результатов запроса.
Например, начнём с таблицы людей, в которую добавлено несколько строк:
CREATE TABLE persons (
id INTEGER PRIMARY KEY AUTOINCREMENT,
name TEXT,
favorite_color TEXT
);
INSERT INTO persons
(name, favorite_color)
VALUES
('Vicki', 'black'),
('Luther', 'mauve'),
('Loren', 'blue');Её можно проверить при помощи двух разных команд SQLite. Первая называется EXPLAIN QUERY PLAN, позволяет просмотреть устройство запроса в самом общем виде. Если выполнить её с простым SELECT и условным оператором, то увидим, что машина полностью сканирует таблицу persons:
sqlite> EXPLAIN QUERY PLAN SELECT * FROM persons WHERE favorite_color = 'blue';
QUERY PLAN
`--SCAN personsЭта команда станет информативнее, когда вы начнёте выполнять более сложные запросы. Пока же давайте рассмотрим другую команду, чтобы далее проверить план.
Эта команда несколько нелогично называется EXPLAIN. Просто отбросьте часть "QUERY PLAN" от первой команды — и машина выведет гораздо более подробный план:
sqlite> EXPLAIN SELECT * FROM persons WHERE favorite_color = 'blue';
addr opcode p1 p2 p3 p4 p5 comment
---- ------------- ---- ---- ---- ------------- -- -------------
0 Init 0 11 0 0 Start at 11
1 OpenRead 0 2 0 3 0 root=2 iDb=0; persons
2 Rewind 0 10 0 0
3 Column 0 2 1 0 r[1]=persons.favorite_color
4 Ne 2 9 1 BINARY-8 82 if r[1]!=r[2] goto 9
5 Rowid 0 3 0 0 r[3]=rowid
6 Column 0 1 4 0 r[4]=persons.name
7 Column 0 2 5 0 r[5]=persons.favorite_color
8 ResultRow 3 3 0 0 output=r[3..5]
9 Next 0 3 0 1
10 Halt 0 0 0 0
11 Transaction 0 0 1 0 1 usesStmtJournal=0
12 String8 0 2 0 blue 0 r[2]='blue'
13 Goto 0 1 0 0 Это «человеко-читаемое» представление байт-кода, в который компилируется ваш запрос. Код может показаться запутанным, поэтому давайте пошагово разберём его.
Набор команд для виртуальной машины SQLite
Подобно тому, как компьютер выполняет низкоуровневые операции с ЦП, например, MOV и JMP, SQLite оперирует схожим набором команд, но на немного более высоком уровне. На момент написания этой статьи существует 186 команд или опкодов, понятных виртуальной машине SQLite. Полная спецификация этих команд приводится на сайте SQLite, но здесь мы разберём лишь пару из этих команд.
Первый опкод — это Init, инициализирующий выполнение, а затем переходящий к другой инструкции в нашей программе. Параметры опкодов перечисляются в порядке от p1 до p5, а их определение специфично для каждой из команд. Что касается опкода Init, он переходит к инструкции, указанной p2, а это 11.
По адресу 11 находим опкод Transaction, с которого начинается наша транзакция. При работе с большинством опкодов виртуальная машина после выполнения инструкции переходит к следующему адресу, в нашем случае это будет адрес 12. Данный опкод String8 сохраняет строковое значение "blue" в регистр r[2]. Функционально регистры — это набор адресов в памяти, которые используются для хранения значений в процессе выполнения. Этим значением воспользуемся позже для проверки равенства.
Далее переходим к адресу 13 и находим там инструкцию Goto, согласно которой мы далее должны перейти к инструкции, указанной у неё в параметре p2, а это адрес 1.
Далее переходим к обработке строк. Инструкция OpenRead открывает курсор в таблице persons. Курсор — это объект для перебора данных в таблице или для движения по ней. Следующая инструкция, Rewind, переводит курсор к той первой записи в базе данных, с которой мы начнём сканирование таблицы.
Инструкция Column считывает столбец favorite_color в регистр r[1], а инструкция Ne сравнивает его со значением "blue" в регистре r[2]. Если эти значения не совпадут, то мы перейдём к инструкции Next по адресу 9. Если же они совпадут, то мы заполним регистры r[3] , r[4] и r[5] данными столбцов id, name, и favorite_color соответственно.
Наконец, мы переходим туда, где можем сдать результат вызывающей стороне, для этого используется инструкция ResultRow. В результате вызывающее приложение скопирует значения из регистров r[3…5]. Когда это приложение вызывает sqlite3_step(), программа возобновит работу с того места, на котором остановилась при вызове Next и повторит обработку строки, которой занимались на инструкции 3.
Когда Next перестанет производить новые строки, он перейдёт к инструкции Halt – и программа будет завершена.
К чему мы пришли
Выполнение запросов в SQLite построено по такому простому принципу «разбор-оптимизация-выполнение» каждого запроса, поступающего в базу данных. Эти знания помогут нам повысить производительность приложения. Пользуясь связывающими параметрами в командах SQL (речь о таких ? подстановочных символах), можно один раз подготовить команду, а затем многократно её использовать, пропуская при этом фазы разбора и оптимизации.
SQLite подходит к выполнению запросов как виртуальная машина, но существуют и иные подходы. Например, в Postgres применяется поузловой план выполнения, структурированный во многом иначе.
Теперь, когда вы в общих чертах представляете, как устроен план выполнения, попробуйте применить команду EXPLAIN к какому-нибудь более сложному из имеющихся у вас запросов и посмотрите, понимаете ли вы, как запрос пошагово превращается в результирующее множество данных для вашего приложения.
Комментарии (14)

kmatveev
14.09.2022 17:05Прикольно. Байт-код, похоже, фиксированного размера, чтобы проще было для переходов находить инструкцию по индексу. Виртуальная машина регистровая, и приходится указывать регистр-получатель результата. Я так понял, что идентификатор курсора - это r[0], используется, когда нужно значения колонки прочитать. Столбцы идентифицируются индексами, значит компилятор зачитывает схему таблицы для кодогенерации. Оптимизация так себе: столбец "favorite_color" зачитывается из курсора дважды, второй раз только для того, чтобы ResultsRow мог сформировать результат из последовательного набора регистров. Интересно, почему не скопировать регистр-регистр в этом случае.

QtRoS
15.09.2022 00:27Но мы из статьи не узнали, какие есть оптимизации на уровне выполнения этого байткода. Возможно машина умеет схлопывать такие инструкции. Плюс надо понимать, что это лишь способ описать SQL-запрос более формально. Сколько настоящих копирований между регистрами происходит тут не представляется возможным посчитать.
amarao
Интересно, насколько быстрее станет работа с базой данных, если ORM при компиляции программы будет компилировать запросы в БД уже в готовом байт-коде?
SGordon123
А разве код не зависит от статистики?
sbars
От статистики зависит в связи с бедностью SQL - невозможно объяснить СУБД, как лучше выполнить запрос исходя из знания, какие данные хранятся в таблицах.
kai3341
Выигрыш будет сильно меньше, чем хотелось бы:
Основное время БД находится в ожидании IO
Даже замена всех SQL запросов захардкоженными параметрами на параметризуемые даёт крайне низкий профит по производительности (другое дело, что эта срань отравляет кэш запросов, но о нём далее)
Наконец, БД кэширует как разобранные запросы, так и позволяет работать с prepared statements -- теми самыми скомпилированными запросами
Что реально даёт профит:
Внимательный разбор плана каждого мало-мальски сложного запроса
В случае ORM внимательный анализ запросов, которые она генерит
Наконец, ORM не позволяет забить на изучение SQL и RDBMs
А ещё декларативность SQL -- миф. В случае подзапросов БД выполнит их императивно -- начиная с самого глубоко вложенного и наверх
kai3341
Кстати об оптимизаторе запросов. Воображение рисует, каким будет реально работающий оптимизатор запросов. Это должен быть робот, который находит программистов, пишущих плохой код, и нещадно их
3.1415926amarao
Если вы можете написать робота (алгоритм), который может отличить хороший код от плохого в автоматическом режиме, то это будет большое достижение, вне зависимости от гопнических замашек.
hint: вы не можете предсказать что делает программа имея на руках программу и её данные. Halting problem, всё такое.
kai3341
Я не вижу задачу невыполнимой ни в каком виде
amarao
Я не понимаю почему вы не видите задачу невыполнимой ни в каком виде.
Akina
Не аксиома. Запрос с подзапросом запросто может быть развёрнут анализатором в обычный JOIN (т.е. будет построен план исполнения, полностью совпадающий с планом выполнения логического аналога этого запроса, использующего JOIN).
И вообще, почему Вы отметаете вариант, что в подобных случаях наиболее эффективный способ выполнения поставленной задачи (план) просто тупо совпадает с текстом задания (запрос)?
kai3341
Именно. Сложный запрос можно составить десятками разных способов, из которых два-три могут конкурировать по производительности, а все остальные являются или саботажем, или бездарностью. В своё время я насмотрелся на бездарность
Редко, но оптимизаторы меня действительно удивляют. Иногда приятно, чаще нет. Как по мне, чем предсказуемее оптимизатор, тем ниже вероятность сюрприза на проде. Одно приятное удивление было в примере бездарного кода:
Так вот, вместо честного
TABLE FULL ACCESSоптимизатор смог использоватьINDEX RANGE SCAN, разве что выгреб годовой интервал вместо сутокedo1h
не думаю, что выигрыш будет существенен.
постгресовский
explain analyze, например, пишет время работы планировщика и время исполнения запроса, разница обычно на порядки.плюс для сложных запросов постгре включает генетический алгоритм, который позволяет найти «достаточно хороший» план за разумное время.
а ms sql агрессивно кэширует планы исполнения запросов (одно время периодический запуск
dbcc freeproccacheбыл описан чуть ли не в каждом втором руководстве по тюнингу связки 1c/ms sql).PeterFukuyama
Как с [prepared](https://www.sqlite.org/c3ref/stmt.html)?