
В данной статье делимся опытом внедрения решения на базе СУБД ClickHouse и сервисов Yandex Cloud. Мы не коснёмся тонких настроек ClickHouse или его масштабирования, но затронем достаточно интересные на наш взгляд темы:
как загружать данные из On-premise в облачный ClickHouse с использованием сервисов Yandex Cloud – Functions, Object Storage, Message Queue;
как обрабатывать/преобразовывать данные в облачном ClickHouse – очищать и строить витрины; какие «подводные камни» нам встретились на этом пути.
Исходная задача:
В On-premise в общую директорию с некоторой периодичностью поступают XML-файлы с массивами объектов. Каждый объект имеет ключ и содержит вложенные объекты/массивы объектов.
Объекты в файлах могут дублироваться: с одним и тем же ключом может поступить несколько как в одном, так и в нескольких разных XML-файлах. Имена файлов содержат timestamp их формирования в системе-источнике, но в общую директорию они могут поступать в любом порядке, не привязанному к этому timestamp.
Необходимо:
данные из XML-файлов сохранять в ClickHouse в исходной структуре (с вложенными массивами, объектами и т.д.) с минимальным отставанием по времени, т.е. данные в ClickHouse должны появляться/обновляться сразу после поступления файлов в общую директорию в On-premise;
данные «очищать» от дублей: среди объектов с одинаковым ключом нужно оставлять тот, у которого более ранний timestamp в имени файла;
строить/обновлять витрины, которые в данном случае представляют собой таблицы с определёнными агрегациями и преобразованиями исходных данных.
Теперь рассмотрим детальнее.
Данные из XML-файлов необходимо сохранять в ClickHouse в исходной структуре с минимальным отставанием по времени.
Пройдя интересный курс обучения «Построение корпоративной аналитической платформы» (кстати, рекомендуем тем, кто начинает изучать облачные технологии и ClickHouse) и увидев фишки вроде интеграции с Kafka, мы предположили, что для ClickHouse или его cli-клиента нет проблем распарсить XML-файл и разложить данные по столбцам. Но оказалось, что такое ClickHouse пока не умеет. Придётся самим парсить XML и делать вставку в ClickHouse.
Немного поспорили о том, что лучше использовать в данной ситуации. Выбирали между Airflow и сервисами Yandex Cloud, в итоге пришли ко второму, а именно — бóльшую часть логики решили сделать на Yandex Cloud Functions. Причиной тому послужили следующие факторы:
ClickHouse будет развернут в облаке Yandex Cloud как управляемый сервис, удобно иметь программную обработку данных в том же облаке рядом с БД;
Yandex Cloud Functions имеют нетарифицируемый объем (так называемый «free tier»), что удешевляет разработку, тестирование функционала и дальнейшую эксплуатацию. Не потребуется содержать в On-premise сервер с Airflow (а может и несколько серверов);
В Yandex Cloud много полезных сервисов, с которыми легко интегрируются Yandex Cloud Functions: Yandex Object Storage, Yandex Message Queue, Yandex DB и другие. Они также имеют свой «free tier»;
Легкость масштабирования Yandex Cloud Functions: мы становимся практически не ограничены в вычислительных ресурсах и параллельности;
Вся облачная инфраструктура описывается в Terraform (у Yandex Cloud есть provider) – так минимизируем затраты на развертывание, CICD/DevOps.
Эту часть задачи мы реализовали по следующей принципиальной схеме:
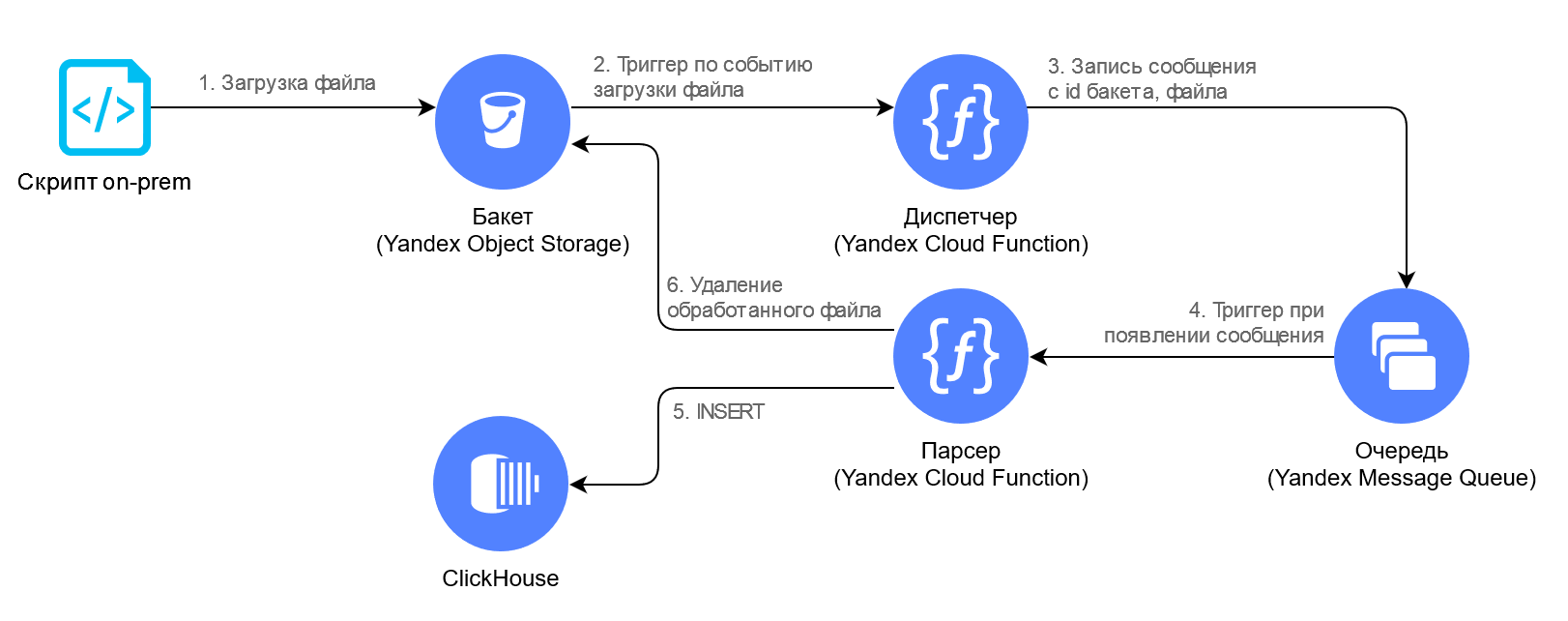
В On-premise запущен скрипт (его подробно не описываем, т.к. он очень простой), который непрерывно поллит общую директорию и каждый поступивший в неё XML-файл загружает (1) в Бакет Yandex Object Storage. Окончание загрузки файла в Бакет служит сигналом для запуска (2) функции «Диспетчер», которая кладёт (3) сообщение с информацией о файле в очередь, таким образом происходит троттлинг (сдерживание) нагрузки. Дальше функция «Парсер» читает (4) из очереди сообщения, скачивает файл из Бакета себе в оперативную память, парсит XML и вставляет (5) данные в хранилище. По окончанию обработки файл из Бакета удаляется (6), чтобы не занимать место и не тратить деньги впустую.
В ClickHouse все данные сохраняются в таблицу со структурой аналогичной схеме XML из файла. Всё благодаря богатому списку типов данных ClickHouse.
Пример реализации функции «Парсер» на Python в облаке:
# import зависимостей
import boto3
# подключение к облаку
boto_session = boto3.session.Session(
aws_access_key_id=os.getenv('ACCESS_KEY_ID'),
aws_secret_access_key=os.getenv('SECRET_ACCESS_KEY')
)
# подключение к объектному хранилищу
s3 = boto_session.client(
service_name='s3',
endpoint_url='https://storage.yandexcloud.net'
)
# подключение к ClickHouse
clickhouse = Client(host=os.getenv('CH_HOST'),
user=os.getenv('CH_USER'),
password=os.getenv('CH_PASSWORD'),
database=os.getenv('CH_DB'),
secure=True,
settings={'input_format_import_nested_json': 1})
# основной обработчик событий
# определяет, что вызов произошёл по сообщению из очереди,
# из тела сообщения берётся идентификатор файла,
# файл скачивается, парсится, данные вставляются в ClickHouse
def handler(event, context):
if 'messages' in event:
for message in event['messages']:
# получение текста сообщения:
task_json = json.loads(message['details']['message']['body'])
# получение объекта из S3:
get_object_response = s3.get_object(Bucket=task_json['bucket_id'],
Key=task_json['object_id'])
# парсинг файла:
parsed_data = parse(data=xmltodict.parse(get_object_response['Body'].read()),
filename=task_json['object_id'])
# сохранение данных:
store(data=parsed_data, file=task_json['object_id'])
# удаление обработанного файла:
s3.delete_object(Bucket=task_json['bucket_id'], Key=task_json['object_id'])
def parse(data, filename):
# ... реализация парсинга
def store(data, filename):
# ... реализация сохранения в ClickHouse
Декларация облачной инфраструктуры на Terraform:
# Подключение к Yandex cloud и хранение состояний в Yandex Object Storage
terraform {
required_providers {
yandex = {
source = "yandex-cloud/yandex"
}
}
backend "s3" {
endpoint = "storage.yandexcloud.net"
bucket = "neoflex-tf-state"
region = "ru-central1"
key = "terraform.tfstate"
access_key = "xxx"
secret_key = "xxx"
skip_region_validation = true
skip_credentials_validation = true
}
}
provider "yandex" {
service_account_key_file = "key.json"
}
locals {
folder_id = "xxx"
ch_secrets = jsondecode(file("clickhouse.json"))
cluster_name = "neoflex"
network_id = "xxx"
subnet_id = "xxx"
}
# Развертывание ClickHouse
resource "yandex_mdb_clickhouse_cluster" "neoflex" {
name = local.cluster_name
environment = "PRESTABLE"
network_id = local.network_id
folder_id = local.folder_id
service_account_id = yandex_iam_service_account.sa.id
sql_database_management = false
sql_user_management = false
clickhouse {
resources {
resource_preset_id = "s2.large"
disk_type_id = "network-ssd"
disk_size = 100
}
}
database {
name = local.ch_secrets["CH_DB"]
}
user {
name = local.ch_secrets["CH_USER"]
password = local.ch_secrets["CH_PASSWORD"]
permission {
database_name = local.ch_secrets["CH_DB"]
}
settings {
max_memory_usage_for_user = 17179869184
max_memory_usage = 17179869184
}
}
host {
type = "CLICKHOUSE"
zone = "ru-central1-a"
subnet_id = local.subnet_id
assign_public_ip = true
}
maintenance_window {
type = "WEEKLY"
hour = 3
day = "MON"
}
}
# Бакет для приёма файлов в облаке
resource "yandex_storage_bucket" "data-input" {
access_key = yandex_iam_service_account_static_access_key.sa-static-key.access_key
secret_key = yandex_iam_service_account_static_access_key.sa-static-key.secret_key
bucket = "neoflex-data-input"
}
# Очередь для троттлинга и dead letter queue
resource "yandex_message_queue" "dlq" {
name = "dlq"
access_key = yandex_iam_service_account_static_access_key.sa-static-key.access_key
secret_key = yandex_iam_service_account_static_access_key.sa-static-key.secret_key
}
resource "yandex_message_queue" "neoflex" {
name = "neoflex"
visibility_timeout_seconds = 600
receive_wait_time_seconds = 20
delay_seconds = 0
message_retention_seconds = 86400 # 1 day
redrive_policy = jsonencode({
deadLetterTargetArn = yandex_message_queue.dlq.arn
maxReceiveCount = 3
})
access_key = yandex_iam_service_account_static_access_key.sa-static-key.access_key
secret_key = yandex_iam_service_account_static_access_key.sa-static-key.secret_key
}
# Сервисная учётка для подключения к облачным ресурсам
resource "yandex_iam_service_account" "sa" {
folder_id = local.folder_id
name = "neoflex"
description = "Neoflex service account to access resource in the folder"
}
resource "yandex_resourcemanager_folder_iam_member" "sa-editor" {
folder_id = local.folder_id
role = "storage.admin"
member = "serviceAccount:${yandex_iam_service_account.sa.id}"
}
resource "yandex_iam_service_account_static_access_key" "sa-static-key" {
service_account_id = yandex_iam_service_account.sa.id
description = "Static access key for object storage"
}
# Функция Диспетчер и триггер её запуска при поступлении файла в Бакет
data "archive_file" "dispatcher" {
type = "zip"
output_path = "${path.module}/../packages/dispatcher.zip"
source {
content = file("${path.module}/../src/dispatcher.py")
filename = "dispatcher.py"
}
source {
content = file("${path.module}/../src/requirements.txt")
filename = "requirements.txt"
}
}
resource "yandex_function" "dispatcher" {
name = "dispatcher"
description = ""
user_hash = data.archive_file.dispatcher.output_base64sha256
runtime = "python39"
entrypoint = "dispatcher.handler"
memory = "128"
execution_timeout = "10"
service_account_id = yandex_iam_service_account.sa.id
folder_id = local.folder_id
environment = {
YMQ_QUEUE_URL = yandex_message_queue.neoflex.id
ACCESS_KEY_ID = yandex_iam_service_account_static_access_key.sa-static-key.access_key
SECRET_ACCESS_KEY = yandex_iam_service_account_static_access_key.sa-static-key.secret_key
}
content {
zip_filename = data.archive_file.dispatcher.output_path
}
}
resource "yandex_function_scaling_policy" "dispatcher" {
function_id = yandex_function.dispatcher.id
policy {
tag = "$latest"
zone_instances_limit = 4
zone_requests_limit = 150
}
}
resource "yandex_function_trigger" "data-dispatcher" {
name = "data-dispatcher"
description = "Triggered dispatcher when new file is available on S3"
folder_id = local.folder_id
object_storage {
bucket_id = yandex_storage_bucket.data-input.id
prefix = "some-input-file"
create = true
update = true
}
function {
id = yandex_function.dispatcher.id
service_account_id = yandex_iam_service_account.sa.id
}
dlq {
queue_id = yandex_message_queue.dlq.arn
service_account_id = yandex_iam_service_account.sa.id
}
}
# Функция Процессор и триггер её запуска по сообщению из очереди Yandex Message Queue
data "archive_file" "processor" {
type = "zip"
output_path = "${path.module}/../packages/processor.zip"
source {
content = file("${path.module}/../src/processor.py")
filename = "processor.py"
}
source {
content = file("${path.module}/../src/requirements.txt")
filename = "requirements.txt"
}
}
resource "yandex_function" "processor" {
name = "processor"
description = ""
user_hash = data.archive_file.processor.output_base64sha256
runtime = "python39"
entrypoint = "processor.handler"
memory = "512"
execution_timeout = "600"
service_account_id = yandex_iam_service_account.sa.id
folder_id = local.folder_id
environment = {
ACCESS_KEY_ID = yandex_iam_service_account_static_access_key.sa-static-key.access_key
SECRET_ACCESS_KEY = yandex_iam_service_account_static_access_key.sa-static-key.secret_key
CH_DB = yandex_mdb_clickhouse_cluster.neoflex.database.*.name[0]
CH_HOST = yandex_mdb_clickhouse_cluster.neoflex.host[0].fqdn
CH_PASSWORD = yandex_mdb_clickhouse_cluster.neoflex.user.*.password[0]
CH_RAW_TABLE = local.ch_secrets["CH_RAW_TABLE"]
CH_USER = yandex_mdb_clickhouse_cluster.neoflex.user.*.name[0]
DATA_BUCKET = yandex_storage_bucket.data-input.id
}
content {
zip_filename = data.archive_file.processor.output_path
}
}
resource "yandex_function_scaling_policy" "processor" {
function_id = yandex_function.processor.id
policy {
tag = "$latest"
zone_instances_limit = 4
zone_requests_limit = 150
}
}
resource "yandex_function_trigger" "processor" {
name = "processor"
description = ""
folder_id = local.folder_id
message_queue {
queue_id = yandex_message_queue.neoflex.arn
service_account_id = yandex_iam_service_account.sa.id
batch_size = "1"
batch_cutoff = "10"
}
function {
id = yandex_function.processor.id
service_account_id = yandex_iam_service_account.sa.id
}
dlq {
queue_id = yandex_message_queue.dlq.arn
service_account_id = yandex_iam_service_account.sa.id
}
}Осуществили загрузку данных в облачный ClickHouse сделали. Теперь данные необходимо «очищать» от дублей.
Какие варианты мы рассматривали при подборе решения этого пункта задачи:
Первый вариант: при парсинге XML-файла и перед вставкой данных в ClickHouse «на лету» проверять – не будет ли дублей и делать insert/upsert в зависимости от ситуации. Не подходит, так как ClickHouse – не OLTP, а OLAP и об этом явно сказано в документации. Обновление данных в таблице реализовано как мутация – достаточно тяжеловесная операция, которую не удастся выполнять часто/много/быстро. Зато ClickHouse очень эффективно работает при вставке (рекомендуем к прочтению статью-benchmark Faster ClickHouse Imports).
Второй вариант – специальный движок таблиц ReplacingMergeTree, который предназначен как раз для дедубликации данных по заданному ключу. Не подходит по двум причинам:
На «очищенных» (дедублицированных) данных нужно строить и обновлять витрины в режиме, близком к online, а движок ReplacingMergeTree осуществляет манипуляции с данными в фоновом режиме и в неопределенный момент времени. Поэтому есть риск собрать витрину на задублированных данных, а требования к витринам высокие, поэтому результаты должны быть точными;
ReplacingMergeTree предлагает дедубликацию по ключу сортировки (секция ORDER BY в DLL таблицы), которая в данном случае не применима, так как в рамках задачи нужно не просто удалять дубли по ключу, а выбирать из дублей подходящую строку (исходя из timestamp в имени файла);
Третий вариант, на котором мы и остановились, – загружать в буферную таблицу всё, что поступило в Бакет и дальше осуществлять merge буферной в «чистовую» таблицу. Этот вариант мы и опишем далее.
Буферная таблица, в которую вставляет «сырые» данные функция «Парсер», имеет поле со временем вставки, партиционирование по этому полю и срок жизни записей:
DROP TABLE IF EXISTS raw;
CREATE TABLE raw
(
...
insertTime DateTime('Europe/Moscow') DEFAULT now()
) ENGINE = MergeTree()
PARTITION BY toYYYYMMDD(insertTime)
ORDER BY (...)
TTL toStartOfDay(insertTime) + INTERVAL 1 DAY;Вообще, TTL в ClickHouse – отличная фича, которая одной строкой в DDL таблицы избавляет нас от самостоятельной организации очистки таблиц (от написания кастомных джобов, их контроля, запуска и мониторинга).
Используя Yandex Cloud Functions Trigger типа Timer, по расписанию запускается функция «Очиститель», которая сравнивает «сырые» и «чистовые» данные, определяет, что в сырых данных есть что-то новенькое и пора обновить чистовые данные. Схематично это выглядит так:
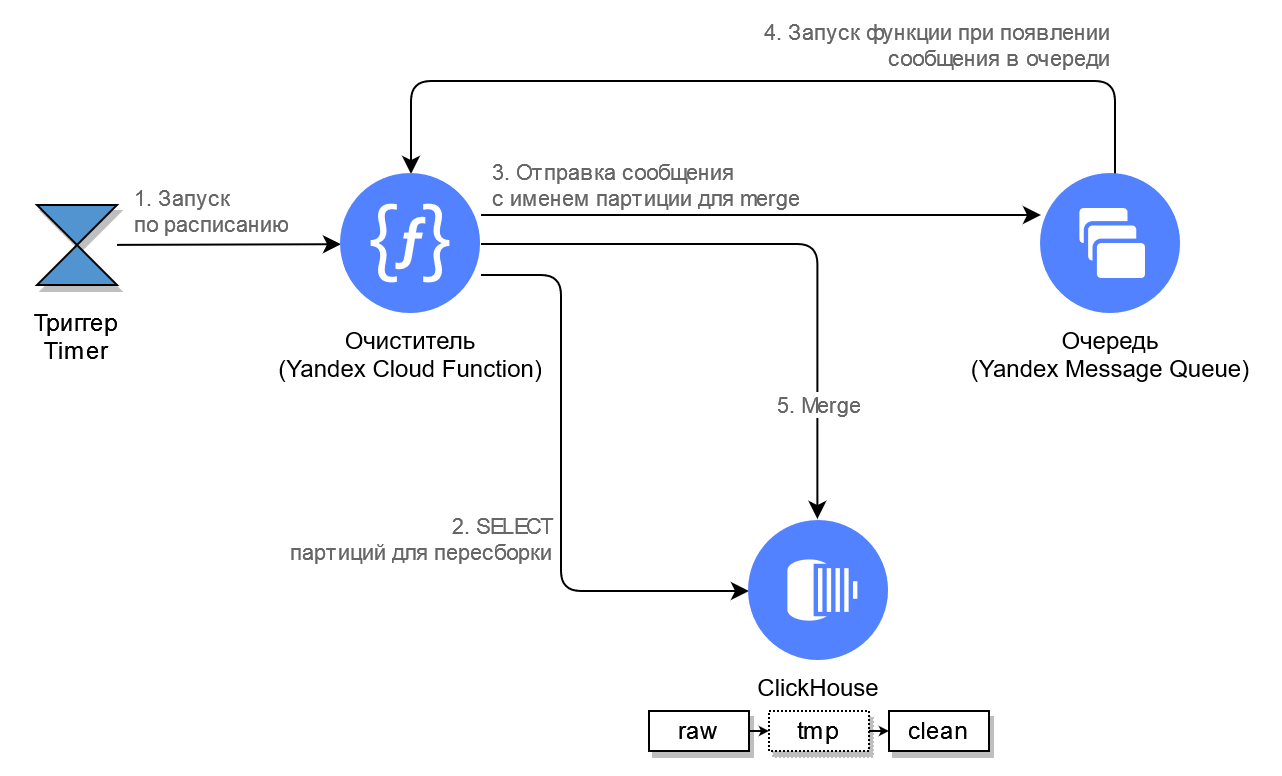
Примерно таким запросом выбираются партиции (2), которые требуют merge:
WITH rawParts AS (
SELECT partKey, MAX(insertTime) maxInsertTime
FROM raw
WHERE insertTime > toStartOfMinute(now()) - INTERVAL 1 HOUR
GROUP BY partKey),
cleanParts AS (
SELECT partKey, MAX(insertTime) maxInsertTime
FROM clean
WHERE partKey IN (SELECT origOperDay FROM rawParts)
GROUP BY partKey)
SELECT DISTINCT toYYYYMMDD(rawParts.partKey) AS partKey FROM rawParts LEFT JOIN parts USING partKey
WHERE rawParts.maxInsertTime > parts.maxInsertTime
ORDER BY partKey;Фактически этот запрос получает из буферной таблицы список пополненных данными партиций за последний час и по времени самой свежей вставки сравнивает с партициями «чистовой» таблицы. Если обнаружено расхождение (есть подозрение на «свежие» данные, которые отсутствуют в «чистовой» таблице), то такие партиции попадают в результат запроса. В реальном случае выборка может быть гораздо сложнее. Функция «Очиститель», выполнив запрос (2), складывает результат построчно в очередь для отдельного «попартиционного» merge (3).
Сам «попартиционный» merge (5) в простейшем случае можно сделать следующим рядом запросов:
-- Предварительная очистка промежуточной таблицы:
ALTER TABLE tmp DROP PARTITION {partKey};
-- Вставка в промежуточную таблицу накопленных, свежих и сразу очищенных данных:
INSERT INTO tmp
SELECT *
FROM (
SELECT * FROM raw r WHERE partkey = {partKey}
UNION ALL
SELECT * FROM clean WHERE partkey = {partKey}
)
ORDER BY field1, field2, field3, ...
LIMIT 1 BY field1, field2, field3, ...;
-- Удаление партиции в чистовой таблице:
ALTER TABLE clean DROP PARTITION {partKey};
-- Перемещение партиции из промежуточной в чистовую таблицу:
ALTER TABLE tmp MOVE PARTITION {partKey} TO TABLE clean;Данные сначала вставляются в промежуточную таблицу, а затем происходит подмена партиции в «чистовой» таблице, что делает весьма незаметным и быстрым её обновление.
Стоит отметить, что при вставке в промежуточную таблицу используется подзапрос, а с этим делом в ClickHouse не всё так уж просто: результат подзапроса должен помещаться в оперативную память одного сервера, ограниченную параметром max_memory_usage (или max_memory_usage_for_user). Если результат подзапроса не поместится в память, тогда весь запрос завершится с ошибкой:
DB::Exception: Memory limit (for query) exceeded
Поэтому для работоспособности такого решения потребовалось подобрать оптимальное сочетание объема одной партиции (читай – ключ партиционирования) и max_memory_usage (читай – объем оперативной памяти у хоста ClickHouse с учётом параллельности подобных запросов).
Упрощенный пример кода функции «Очиститель»:
# импорт используемых модулей
# import ...
# подключение к облаку
boto_session = boto3.session.Session(
aws_access_key_id=os.getenv('ACCESS_KEY_ID'),
aws_secret_access_key=os.getenv('SECRET_ACCESS_KEY')
)
# подключение к ClickHouse
clickhouse = Client(host=os.getenv('CH_HOST'),
user=os.getenv('CH_USER'),
password=os.getenv('CH_PASSWORD'),
database=os.getenv('CH_DB'),
secure=True)
# подключение к очереди Yandex Queue для отправки сообщений
ymq_queue = boto_session.resource(
service_name='sqs',
endpoint_url='https://message-queue.api.cloud.yandex.net',
region_name='ru-central1'
).Queue(os.getenv('YMQ_QUEUE_URL'))
# основной обработчик событий
def handler(event, context):
try:
if event is not None and type(event) == dict and 'messages' in event:
for message in event['messages']:
if 'event_metadata' in message and \
'event_type' in message['event_metadata'] and \
message['event_metadata'][
'event_type'] == 'yandex.cloud.events.serverless.triggers.TimerMessage':
# запуск по событию, инициированному триггером с типом Timer
# поиск партиций для merge и отправка заданий в очередь
queue_partitions()
else:
# запуск по сообщению из очереди
task_json = json.loads(message['details']['message']['body'])
partKey = str(task_json['partKey'])
# merge конкретной партиции
do_partition(partKey=partKey)
except Exception as ex:
logging.error(ex)
# поиск партиций
def queue_partitions():
# запрос поиска партиций для merge (см. выше пример)
query = '...'
rows_gen = clickhouse.execute_iter(query)
# отправка каждой партиции в очередь отдельным сообщением
for partKey in rows_gen:
ymq_queue.send_message(MessageBody=json.dumps({
'partKey': partKey[0]
}))
# merge конкретной партиции (см. последовательность запросов выше)
def do_partition(partKey):
# ...
Так это описывается на Terraform (декларация в добавок к той, что представлена ранее):
# Функция "Очиститель"
data "archive_file" "cleaner" {
type = "zip"
output_path = "${path.module}/../packages/cleaner.zip"
source {
content = file("${path.module}/../src/cleaner.py")
filename = "cleaner.py"
}
source {
content = file("${path.module}/../src/requirements.txt")
filename = "requirements.txt"
}
}
resource "yandex_function" "cleaner" {
name = "cleaner"
description = ""
user_hash = data.archive_file.cleaner.output_base64sha256
runtime = "python39"
entrypoint = "cleaner.handler"
memory = "256"
execution_timeout = "300"
service_account_id = yandex_iam_service_account.sa.id
folder_id = local.folder_id
environment = {
CH_DB = yandex_mdb_clickhouse_cluster.neoflex.database.*.name[0]
CH_HOST = yandex_mdb_clickhouse_cluster.neoflex.host[0].fqdn
CH_PASSWORD = yandex_mdb_clickhouse_cluster.neoflex.user.*.password[0]
CH_USER = yandex_mdb_clickhouse_cluster.neoflex.user.*.name[0]
ACCESS_KEY_ID = yandex_iam_service_account_static_access_key.sa-static-key.access_key
SECRET_ACCESS_KEY = yandex_iam_service_account_static_access_key.sa-static-key.secret_key
YMQ_QUEUE_URL = yandex_message_queue.cleaner.id
YANDEX_FOLDER_ID = local.folder_id
YDB_ENDPOINT = yandex_ydb_database_serverless.neoflex.document_api_endpoint
}
content {
zip_filename = data.archive_file.cleaner.output_path
}
}
resource "yandex_function_scaling_policy" "cleaner" {
function_id = yandex_function.cleaner.id
policy {
tag = "$latest"
zone_instances_limit = 4
zone_requests_limit = 150
}
}
# Триггер-таймер для запуска функции по расписанию
resource "yandex_function_trigger" "cleaner_cron" {
name = "cleaner-cron"
description = ""
folder_id = local.folder_id
timer {
cron_expression = "*/5 * * * ? *"
}
function {
id = yandex_function.cleaner.id
service_account_id = yandex_iam_service_account.sa.id
}
}
# Триггер для запуска функции по сообщению из очереди
resource "yandex_function_trigger" "cleaner_queue" {
name = "cleaner-queue"
description = ""
folder_id = local.folder_id
message_queue {
queue_id = yandex_message_queue.cleaner.arn
service_account_id = yandex_iam_service_account.sa.id
batch_size = "1"
batch_cutoff = "10"
}
function {
id = yandex_function.cleaner.id
service_account_id = yandex_iam_service_account.sa.id
}
}
# Очередь для сообщений с именами партиций, которые будут пересобираться
resource "yandex_message_queue" "cleaner" {
name = "partitions2merge"
visibility_timeout_seconds = 600
receive_wait_time_seconds = 20
delay_seconds = 0
message_retention_seconds = 86400 # 1 day
redrive_policy = jsonencode({
deadLetterTargetArn = yandex_message_queue.dlq.arn
maxReceiveCount = 3
})
access_key = yandex_iam_service_account_static_access_key.sa-static-key.access_key
secret_key = yandex_iam_service_account_static_access_key.sa-static-key.secret_key
}
Итак, данные в облако загрузили и очистили, теперь на основе очищенных данных необходимо строить ряд витрин с агрегациями.
Тут схема, процесс и реализация абсолютно идентичны предыдущей части – есть исходная таблица и нужно на её данных строить/обновлять витрину. Стоить отметить только один нюанс, с которым мы столкнулись, – это использование массивов и вложенных таблиц в ClickHouse.
Например, у нас есть исходная таблица со следующей структурой:
CREATE TABLE clean
(
id Int64,
positions Nested(
id UInt16,
value1 String,
value2 String
),
insertTime DateTime('Europe/Moscow') DEFAULT now()
) ENGINE = MergeTree()
PARTITION BY toYYYYMMDD(insertTime)
ORDER BY (id);
Мы хотим выбрать все данные в плоском виде и делаем такой запрос:
SELECT id, p.id, p.value1, p.value2
FROM clean ARRAY JOIN positions AS p
Это работает.
Дальше, например, у нас есть другая таблица с маппингами:
CREATE TABLE mappings
(
from String,
to String
) ENGINE = MergeTree()
ORDER BY (from);
И мы хотим применить маппинг к одному полю нашей таблицы с чистовыми данными:
SELECT p.value1, m.to value1_to
FROM clean ARRAY JOIN positions AS p
LEFT JOIN mappings AS m ON p.value1 = m.from;
Это тоже отлично работает.
Но если мы захотим сделать еще один маппинг по другому полю:
SELECT p.value1, m1.to value1_to, p.value2, m2.to value2_to
FROM clean ARRAY JOIN positions AS p
LEFT JOIN mappings AS m1 ON p.value1 = m1.from
LEFT JOIN mappings AS m2 ON p.value2 = m2.from
получим ошибку:
DB::Exception: Multiple JOIN does not support mix with ARRAY JOINs
Да, есть такое ограничение. И обойти его можно, используя подзапрос:
SELECT p.value1, value1_to, p.value2, m2.to value2_to FROM
(
SELECT p.value1, m1.to value1_to, p.value2
FROM clean ARRAY JOIN positions AS p
LEFT JOIN mappings AS m1 ON p.value1 = m1.from
) t
LEFT JOIN mappings AS m2 ON p.value2 = m2.from
Но, как отмечено ранее, подзапросы накладывают существенные ограничения прежде всего на объем обрабатываемых запросом данных. И, если в исходной таблице будут триллионы строк, то такой запрос вряд ли сможет быть выполнен. Придётся упрощать исходную таблицу (чтобы не делать два раза JOIN), либо упрощать целевую таблицу (отказаться от дополнительного маппинга), либо обрабатывать исходную таблицу частями (как, например, сделано при «очистке» сырых данных) и искать оптимальное сочетание вышеуказанных параметров решения.
Заключение
В ClickHouse достаточно много различных ограничений, в том числе синтаксических. До поддержки полноценного SQL он, к сожалению, пока не дотягивает. Тот же ARRAY JOIN в одном запросе/подзапросе можно использовать только один раз.
При проектировании решений с использованием ClickHouse мы рекомендуем сразу детально продумывать все структуры таблиц, необходимых сквозному процессу: от таблиц с сырыми данных до конечных витрин, с учётом различных ограничений ClickHouse.
Чтобы получать финишные данные за наименьшее количество итераций с наименьшим количеством промежуточных таблиц и подзапросов, иногда стоит отказаться от оригинальной структуры исходных данных в виде массивов или вложенных таблиц, Иногда будет быстрее, например, применить маппинг или сделать дополнительное вычисление еще на уровне обработки сырых данных перед вставкой в ClickHouse.
В общем, чем проще и полнее исходные данные (таблицы с данными), тем удобнее и дешевле в дальнейшем с ними работать и тем больше прелестей Full Scan открываются у ClickHouse.
Что касается плюсов применения ClickHouse, как нам видится, эта СУБД лучше всего пригодна в кейсах, когда в режиме online нужно сохранять колоссальные объёмы структурированных данных и иметь возможность из этих данных быстро получать несложные выборки (хотя бы без подзапросов и JOIN с крупными таблицами).
Вставка огромных объемов данных в ClickHouse – не проблема, как и простая выборка (с агрегацией) из большой таблицы, ведь изначально под такой тип задач ClickHouse и создавался в Yandex.Metrica. Кроме того, поддержка своеобразного SQL, хоть и весьма ограниченного, и классических способов подключения JDBC/ODBC является огромным плюсом.
Комментарии (6)

Volrath
16.09.2022 13:16А вот это точно правдиво?
ReplacingMergeTree предлагает дедубликацию по ключу сортировки (секция ORDER BY в DLL таблицы), которая в данном случае не применима, так как в рамках задачи нужно не просто удалять дубли по ключу, а выбирать из дублей подходящую строку (исходя из timestamp в имени файла)timestamp из названия файла нельзя парсером подтащить в виде значения в поле insertTime? или просто использовать MATERIALIZE колонку с таймстемпом вставки и её потом использовать как аргумент. Да и без аргумента replacing движок оставляет только смую последнюю вставленную строку. Пробблема движка в том только, что удаляет он не сразу и при выборке из таблицы дубли могут ещё оставаться и их надо чистить селектом.
Ну или я не так понял задачу))
И одна опечатка --- Перемещение партиции из промежуточной в чистовую таблицу:ALTER TABLE clean MOVE PARTITION {partKey} TO TABLE clean;Тут всё таки из tmp в clean, а не из clean в clean.
В остальном очень интересно, спасибо.

neoflex Автор
16.09.2022 13:21Благодарим за обратную связь!
> timestamp из названия файла нельзя парсером подтащить в виде значения в поле insertTime?
Нет, всё-таки insertTime отражает время фактической вставки в таблицу с "сырыми" данными. По этому полю потом таблица очищается по TTL. Может так выйти, что в обработку попадёт файл с timestamp в имени = неделя назад (а TTL = 3 суток) и данные из этого файла уйдут в молоко.
К слову, парсер вставляет timestamp из имени файла в отдельное поле (скажем, field3) и потом "Очиститель" делает вот так при сборке чистой партиции:
ORDER BY field1, field2, field3, ...
LIMIT 1 BY field1, field2, field3, ...;> Да и без аргумента replacing движок оставляет только самую последнюю вставленную строку.
Нам как раз нужно было оставлять не самую свежую строку, а ту, у которой timestamp в имени файла самый ранний. При этом файлы могут поступать в обработку в любом порядке, т.е. не привязанном к timestamp из имени ...
Опечатку поправили, спасибо за внимательность)
Volrath
16.09.2022 17:04Самую первую можно оставлять с "инвертированной" датой. Вычитать из какого-то таймстемпа в UInt64 в далёком будущем текущий и получится, что у каждой новой записи аргумент будет меньше, чем у самой первой. И она удалится.

JohnSelfiedarum
16.09.2022 15:16Почему, собственно, не ReplicatedMergeTree?
neoflex Автор
16.09.2022 17:16Подскажите, пожалуйста, в каком месте и для решения какого вопроса предлагаете использовать ReplicatedMergeTree?"
f1user
Спасибо, все по делу.