
Идет очередной этап работы датасаентиста… обучена ML-модель, которая снизит издержки, повысит эффективность, сделает жизнь лучше, ничего не изменит, зато звучит модно. И вот настало время презентовать результаты ее работы. Если вы, как и я, работаете в промышленности, то на запланированную встречу наряду с менеджерами наверняка пригласят технологов с производства - именно они будут пользователями вашей системы, и успешность проекта может во многом зависеть от их заинтересованности и вовлеченности в совместную работу. Раз надо их заинтересовать, сделаем!
Привет, Хабр! Меня зовут Владимиров Дмитрий, я data scientist в группе анализа данных компании Норникель. Я хочу поделиться тем, как настроить интерактивную визуализацию работы ML-модели использую связку Python+Postgres+Grafana.
Стандартным подходом для первичной оценки качества модели является ее backtest («прогон») на исторических данных. Иными словами, обученная модель делает предикт на накопленных данных за прошлый период, рассчитываются метрики, и выносится предположение о том, что качество в будущем будет сопоставимым. Результатами презентации являются ряд графиков, цифры метрик и расчет потенциальной экономической эффективности. Полезные данные? Однозначно, вот только запомнят их ненадолго. Зато эффектно сделанная визуализация работы ML-модели внимания к себе точно привлечет. И тут нам на руку играет специфика работы в промышленности: если в банках и телекоме уже давно привыкли к красивым дашбордам, где следование принципам UX/UI является обыденностью, то на производствах распространены scada системы, визуальное оформление которых очень часто оставляет желать лучшего.

Scada - от англ. Supervisory Control And Data Acquisition — диспетчерское управление и сбор данных. Именно с помощью этих систем идет управление производственным процессом. Упор при их разработке делается не на «красивой картинке», а на предоставлении оператору информации, позволяющей сформировать понимание о текущих параметрах процесса и на возможности быстро внести корректирующие воздействия. UX часть таких систем продумывают очень тщательно, а вот UI остается в стороне. Получается, что у нас практически нет конкуренции по части визуализации - достаточно сделать красивее, чем в scada. И вот тут использование Grafana в презентации может помочь – привлечет внимание к вашей работе и, если визуализация сделана качественно, повысит заинтересованность технологов к разрабатываемому решению.
Настройка интерактивной визуализации
Наша система будет состоять из четырех основных частей:
.csv файл с архивными данными и прогнозом модели;
CУБД PostgreSQL, откуда Grafana будет забирать данные для визуализации;
Python скрипт, загружающий архивные данные в БД;
Grafana, на которой будет настроена визуализация.
Подготовка csv файла
Для примера я сгенерировал датасет, содержащий параметры работы абстрактной установки: ее температура, давление, подача питания и качество продукта, которое мы хотим контролировать. Причем последний параметр зависит от предыдущих. Его-то я и буду прогнозировать на 30 минут вперед.
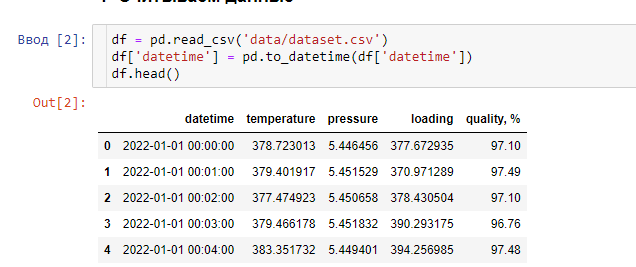
Для обучения модели проделываем стандартные шаги при работе с временными рядами: для начала сделаем целевую переменную. Нашим таргетом станет качество продукта, которое будет наблюдаться через 30 минут. Создадим новую колонку:
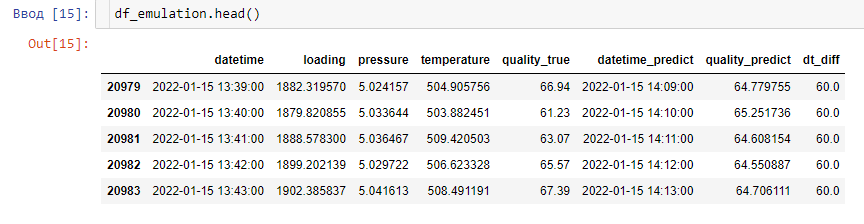
df['quality_target'] = df['quality, %'].shift(-30)Затем разделим датасет на тренировочную и тестовую части. На тренировочной части обучаем простую линейную модель с L2-регуляризаций (Ridge) и делаем прогноз на тестовую. В результате, если к тестовой части конкатенировать целевой вектор и прогноз модели, то получится следующий датафрейм:

Тут надо учесть, что quality_predict – это прогноз на 30 минут вперед (мы сдвигали таргет перед обучением модели), однако просто сделать обратный сдвиг недостаточно. Дело в том, что в случае сдвига при последовательной загрузке строк в БД метка времени самого последнего нашего прогноза будет соответствовать метке времени для наших фичей. Это не проблема, когда мы строим график для всей тестовой части, но при симуляции работы модели важно, чтобы график прогноза всегда обгонял график фактических значений, ведь так всё и будет выглядеть в реальной жизни. Модель сделала прогноз, а верный ли он мы узнаем только с задержкой в 30 минут.

Для этого вместо сдвига прогноза создадим еще одно колонку, которая будет соответствовать времени, на которое сделан прогноз. Она понадобится нам в дальнейшем.
df_emulation['datetime_predict'] = df_emulation['datetime'].shift(-30)Последний штрих: добавляем колонку, показывающую разницу во времени между соседними строками. Она требуется для того, чтобы после записи одной строки в БД «уйти в сон» на нужное количество времени.
df_emulation['dt_diff'] = df_emulation['datetime'].diff(-1)
df_emulation['dt_diff'] = df_emulation['dt_diff'].astype('timedelta64[s]') * -1Переименуем `quality, %` в `quality_true` и с подготовкой данных закончили! Вот что у нас получилось:
CУБД PostgreSQL
На этой части я останавливаться не буду, тем более что настраивать каким-то особенным образом нашу СУБД не требуется, все оставим по умолчанию. В интернете большое количество материала по установке и настройке Postgres. К примеру в видео «Docker and PostgreSQL in [10 Minutes]» показано, как установить Postgres с помощью Docker.
PS. Не верьте названию под видео. Это идет все 20 минут, но нам и вправду хватит первых 10)
Загрузка данных в БД
Данные готовы, Postgres настроен. Давайте научимся загружать данные в базу с помощью python-скрипта.
Что должен уметь наш код? Во-первых, он должен подключаться к СУБД, создавать в базе данных таблицу и уметь вносить в нее данные построчно. Во-вторых, нам не хочется, чтобы все данные были выгружены разом. Это должно происходить постепенно, имитируя технологический процесс, те после каждой записи надо делать паузу. Вот только если мы решим сделать симуляцию работы на данных за последний год, то демонстрация «немного» затянется. Чтобы этого избежать, скорость загрузки должна регулироваться. В-третьих, полезным будет добавить возможность предварительной загрузки определенного количества строк без задержки, чтобы не начинать демонстрацию каждый раз «с чистого листа».
С функционалом определились, можем начинать. Для начала опишем основные параметры для работы скрипта:
if __name__ == '__main__':
config = {'db_settings': {'dialect': 'postgresql',
'host': '127.0.0.1',
'port': '5432',
'db_name': 'postgres',
'username': 'postgres',
'password': 'qazwsx12345', # пароль от пользователя "Postgres"
'schema': 'public',
'table': 'fakedata', # произвольное название таблицы
},
'data_path': 'data/df_emulation.csv', # путь к подготовленным данным
'preload_rows': 3000, # количество строк для предварительной загрузки
'speedx': 60 # во сколько раз ускорить загрузку
}
main(config)Для Postgres все параметры из «db_settings» можно оставить без изменений, кроме пароля от пользователя “postgres”, который вы ввели при установке СУБД.
Теперь напишем класс, который будет работать с БД. Для работы с Postgres будем использовать sqlalchemy и ее встроенную ORM.
import time
import pandas as pd
import sqlalchemy as sa
from sqlalchemy import Table, Column, Numeric, DateTime
from sqlalchemy.dialects.postgresql import insert as pg_insert
class DB:
def __init__(self, config):
self.config = config['db_settings']
self.engine = self.create_engine()
self.table = self.define_table()
def create_engine(self):
conn_string = self.config['dialect'] + '://' + \
self.config['username'] + ':' + \
self.config['password'] + '@' + \
self.config['host'] + ':' + \
self.config['port'] + '/' + \
self.config['db_name']
return sa.create_engine(conn_string)
def define_table(self):
metadata_obj = sa.MetaData()
return Table(self.config['table'], metadata_obj,
Column('datetime', DateTime, nullable=False, primary_key=True),
Column('loading', Numeric),
Column('pressure', Numeric),
Column('temperature', Numeric),
Column('quality_true', Numeric),
Column('quality_predict', Numeric),
schema=self.config['schema']
)
def drop_table(self):
self.table.drop(self.engine, checkfirst=True)
def create_table(self):
self.table.create(self.engine, checkfirst=True)
def recreate_table(self):
self.drop_table()
self.create_table()
def insert_data(self, data: pd.Series):
# Update on conflict postgres insert
with self.engine.connect() as conn:
insert_stmt = pg_insert(self.table).values(data.to_dict())
do_update_stmt = insert_stmt.on_conflict_do_update(
index_elements=['datetime'],
set_=data.to_dict()
)
conn.execute(do_update_stmt)
При создании экземпляра класса DВ в него передается конфиг с параметрами, создается engine и при вызове метода `define_table` определяется структура таблицы в которую будут записываться данные. Первичным ключом в этой таблице выступает поле datetime. Методы `drop_table` и `create_table` просто удаляют и создают таблицу в БД. Метод `insert_data` записывает данные если такое значение 'datetime' отсутствует в таблице, в противном случае - обновляет данные в строке с этой меткой времени (к INSERT добавляется условие UPDATE ON CONFLICT, реализованное в Postgres). Для чего нужно это усложнение и почему не использовать обычный INSERT?
Дело в том, что в базу нам надо будет одновременно записывать 2 строки данных с разными datetime. Первая строка будет соответствовать "текущим" параметрам оборудования, которые мы наблюдаем в данный момент, а вторая строка - наш прогноз, datetime которого на 30 минут больше. На изображении ниже при следующей итерации записи мы обновим строку с datetime='2022-01-17 17:51:00', дополнив ее значениями параметров "loading", "pressure", "temperature" и "quality_true", и затем впишем прогноз модели с datetime '2022-01-17 18:21:00' (на 30 минут вперед).
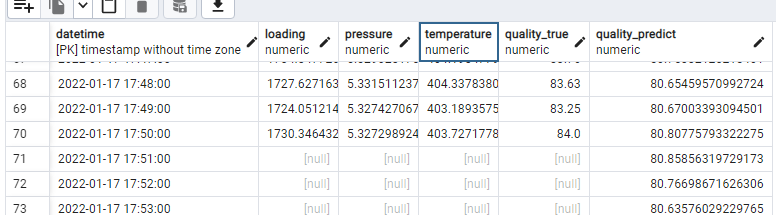
Таким образом "текущие" значения всегда дополняют строку с прогнозом, который был сделан ранее. UPDATE ON CONFLICT как раз позволяет как записывать в таблицу новый прогноз, так и дополнить прогноз текущими значениями параметров, datetime которого уже присутствует в таблице.
Добавим функцию, которая будет итерироваться по строкам в подготовленном ранее файле и записывать их в БД.
def main(config: dict):
db = DB(config)
# Обновляем таблицу в БД
db.recreate_table()
df = pd.read_csv(config['data_path'])
# Итерация по строкам датасета
for i, (_, row) in enumerate(df.iterrows()):
# Записываем "текущие" показания
# (все колонки кроме datetime_predict, quality_predict, dt_diff)
db.insert_data(row[:-3])
# Записываем в БД прогноз на 30 минут вперед
predict = row[['datetime_predict', 'quality_predict']]
predict.rename({'datetime_predict': 'datetime'}, axis=1, inplace=True)
db.insert_data(predict)
print(f'{i}: Data with timestamp {row["datetime"]} and predict '
f'to {predict["datetime"]} were sent')
# "Спим" только если записали больше строк, чем указано в
# параметре "preload_rows"
if i > config['preload_rows'] - 1:
time.sleep(row['dt_diff'] / config['speedx'])
Скрипт для загрузки данных в БД готов! Запустим его для того, чтобы заполнить таблицу с которой будем работать и переходим к следующему этапу...
Настройка дашборда Grafana
Для начала устанавливаем Grafana. Тут ничего сложного, идем на официальный сайт и скачиваем подходящую под вашу платформу версию.
После установки Grafana запустится локально на 3000 порте. Вбиваем в строке браузера localhost:3000 и попадаем на страницу авторизации. При первой авторизации дефолтная пара логин-пароль «admin»-«admin».

Теперь перед созданием дашборда нам надо настроить соединений с базой, в которую мы записываем данные. Идем в настройки -> data sources -> Add data source -> PostgreSQL. В открывшемся экране параметров вносим данные для подключения:
Если порт по умолчанию у postgres не меняли, в качестве хоста указываем localhost:5432
Database: postgres
User: postgres
Password: Пароль вводим для пользователя postgres, который задали при установке СУБД
Отключаем шифрование – TSL/SSL Mode "disable"
Все параметры введены, жмем Save&Test. Если все указано верно, то должен отобразиться статус Database Connection: OK
Теперь если перейти на вкладку Data sources, то отобразится добавленное нами подключение.
Для создания визуализации все подготовлено. В боковом меню нажимаем на вкладку Dashboards -> New dasboard. Перед нами откроется экран с предложением добавить "панель". В Grafana дашборды состоят из набора так называемых панелей. Каждая панель может содержать график, таблицу, текст, картинку и так далее. Размер панелей изменяемый, а Grafana поможет их выровнять между собой.
Создадим первую панель которая будет отображать график со значениями качества продукта и прогноза по качеству. Для этого нажимаем на кнопку "Add a new panel" и попадаем на экран конфигурации панели.

В окне конфигурации выбираем тип панели "Time Series" (блок 1), в Data Sorce выбираем подключение к Postgres, которое настроили ранее (блок 2), и в конфигураторе SQL запроса (блок 3) выбираем таблицу "fakedata", указываем колонку времени "datetime" и в блоке SELECT указываем две колонки для отрисовки "quality_true" и "quality_predict". В блоке WHERE по умолчанию стоит $_timeFilter - он автоматом добавляем условие "datetime" BETWEEN "начало_выбранного_диапазона_на_графике" AND "конец_диапазона". Условие лучше не убирать, ведь в противном случае при каждом обновлении дашборда из таблицы будут считываться все хранящиеся там записи, даже если мы выбрали на графике период в один час.
После конфигурации sql-запроса нажимаем ctrl+enter и, скорее всего вы увидите пустое окно графика. Для отображения наших параметров в блоке 4 выбираем данные за последний год и затем на самом графике можем выделить диапазон с загруженными нами данными. Блок 5 содержит разнообразные параметры для настройки графиков такие как подписи и масштаб осей, цвета графиков и другие. После завершения настройки графика жмем "Apply" и увидим наш одинокий график.

Добавим панели с расчетами метрик R2 и MAE за выбранный период. Для этого создаем новую панель и в ней указываем тип Gauge. Метрики будем считать в SQL запросе. Для этого конфигуратор Grafana нем уже не подойдет, поэтому в нижней части конфигуратора SQL-запросов нажимаем "Edit SQL" и в открывшемся окне вводим наш запрос.
SELECT
max(datetime) as "time",
(1.0 - sum((quality_predict - quality_true)^2) /
sum((quality_true - (SELECT AVG(quality_true)
FROM fakedata
WHERE quality_true IS NOT NULL AND $__timeFilter(datetime)
))^2)) as r2
FROM fakedata
WHERE
quality_true IS NOT NULL AND quality_true IS NOT NULL
AND $__timeFilter(datetime)
ORDER BY 1Снова жмем Apply и шкала с метрикой появилась на дашборде.

По аналогии добавим шкалу для отображения метрики MAE. SQL запрос для нее:
SELECT
MAX(datetime) AS "time",
AVG(ABS(quality_true - quality_predict)) as mae
FROM fakedata
WHERE
$__timeFilter(datetime)
ORDER BY 1График качества продукции есть, метрики на экран выводим. Но оператору могут быть интересны значения технологических параметров от которого зависит качество. Добавим графики температуры, загрузки и давления на экран. Тут все по аналогии с графиком качества продукции, только для того чтобы убрать "шум" на графиках, добавляю скользящее среднее. SQL запрос для всех трех параметров аналогичен, приведу пример для температуры:
SELECT
datetime AS "time",
AVG(temperature) OVER (ORDER BY datetime ROWS BETWEEN 30 PRECEDING AND CURRENT ROW)
FROM fakedata
WHERE
$__timeFilter(datetime)
AND temperature IS NOT NULL
ORDER BY 1Добавляем три графика и упорядочиваем панели на дашборде. Все готово для запуска визуализации!
Запускаем скрипт по загрузке данных в базу, включаем автообновление экрана grafana в правом верхнем углу меню и смотрим на результатат.

Заключение
В посте показана настройка симуляции с помощью связки Python+Postgres+Grafana, однако любую из этих частей можно заменить на то, с чем вам будет комфортнее работать. Тратить слишком много времени на проработку экрана на этом этапе не стоит, достаточно обозначить основной функционал будущей системы и сделать красивую визуализацию. Grafana как раз позволила собрать такой дашборд из базовых блоков за несколько часов.
Рад, если пост был для вас полезен! Интересно узнать про ваш опыт. Используете ли вы интерактивную визуализацию при презентации результатов моделирования в своих проектах?
Исходные данные, python код и json дашборда доступны в репозитории на github.