
Введение
Важный аспект эксплуатации вычислительной инфраструктуры – гарантировать, что используемые облачные ресурсы автоматически масштабируются по мере необходимости, как вверх, так и вниз. Серьезные флуктуации трафика могут наблюдаться ежедневно, и поэтому «площадь» облака должна динамически масштабироваться сообразно этим флуктуациям.
Например, в Airbnb такое масштабирование обеспечивается при помощи Kubernetes. Это опенсорсная система оркестрации контейнеров. Также в Airbnb используется OneTouch, интерфейс конфигурации сервисов, являющийся надстройкой над Kubernetes и более подробно описанный в этом посте.
Здесь же мы поговорим о том, как динамически подбирать размеры кластеров, пользуясь Kubernetes Cluster Autoscaler, а также подчеркнем функционал, привнесенный компанией Airbnb в сообщество sig-autoscaling. Эти улучшения способствуют настраиваемости и гибкости, а эти качества очень важны для выполнения уникальных бизнес-требований, предъявляемых в Airbnb.
Кластеры Kubernetes в Airbnb
В последние несколько лет Airbnb перенесла почти все онлайновые сервисы с координируемых вручную инстансов EC2 на Kubernetes. Сегодня компания эксплуатирует тысячи узлов, распределенных почти на сотню кластеров, чтобы справляться с имеющимися рабочими нагрузками. Однако, такие перемены не делаются в ночь на утро. В процессе такой миграции базовая конфигурация кластеров Kubernetes в компании развивалась, становилась все более затейливой по мере того, как в новый технологический стек перетекало все больше рабочих нагрузок и трафика. Эту эволюцию можно представить в виде трех этапов:
Этап 1: Однородные кластеры, масштабирование вручную.
Этап 2: Множество типов кластеров, независимое автомасштабирование.
Этап 3: Разнородные кластеры, автомасштабирование.
Этап 1: Однородные кластеры, масштабирование вручную
До перехода на Kubernetes каждый экземпляр сервиса использовался на собственной машине, и масштабировали его вручную – чтобы хватало мощностей для обработки возрастающего трафика. Управление мощностями варьировалось от команды к команде, а когда нагрузка падала, лишние мощности обычно не выводились из использования.
Первичная конфигурация кластера Kubernetes была относительно проста. Имелось несколько кластеров, каждый из них был образован узлами некого базового типа и обладал конкретной конфигурацией, рассчитанной только на эксплуатацию онлайновых сервисов без сохранения состояния. По мере того, как некоторые из этих сервисов стали переводиться на Kubernetes, компания перешла к использованию контейнеризованных сервисов в мультиарендной среде (много подов на узле). Такая агрегация позволила снизить расход ресурсов и консолидировать управление мощностями для этих сервисов в единой контрольной точке в управляющей плоскости Kuberentes. На данном этапе кластеры в компании масштабировались вручную, но ситуация все равно явственно улучшилась по сравнению с имевшейся ранее.

Рисунок 1: Сравнение узлов EC2 и узлов Kubernetes
Этап 2: Множество типов кластеров, независимое автомасштабирование
Второй этап конфигурирования кластеров начался, когда компания попыталась выполнять на Kubernetes более разнообразные типы рабочих нагрузок, предъявляя к каждому типу различные требования. Чтобы соответствовать этим требованиям, была создана абстракция «тип кластера». «Тип кластера» определяет конфигурацию того оборудования, на базе которого работает кластер; таким образом, все кластеры некоторого типа идентичны по всем показателям, от типа узла до различных настроек компонентов в этом кластере.
Чем больше было типов кластеров, тем больше становилось и самих кластеров, и исходная стратегия, предполагавшая ручное управление мощностями каждого кластера, быстро перестала работать. Чтобы это исправить, к каждому кластеру был добавлен инструмент Kubernetes Cluster Autoscaler. Этот компонент автоматически корректирует размер кластера в зависимости от запросов подов – если мощность кластера исчерпана, и ожидающий запрос со стороны пода можно обработать, добавив новый узел, то Cluster Autoscaler запускает такой узел. Аналогично, если в кластере есть узлы, которые в течение длительного периода могут быть недозагружены работой, то Cluster Autoscaler удалит их из кластера. В данную конфигурацию этот компонент вписался отлично, позволил сэкономить примерно 5% всего облака, а также избавиться от эксплуатационных издержек, возникающих при масштабировании кластеров вручную.

Рисунок 2: Типы кластеров в Kubernetes
Этап 3: Разнородные кластеры, автомасштабирование
Когда почти все онлайновые вычислительные мощности Airbnb были переведены на Kubernetes, количество типов кластеров достигло 30, а самих кластеров стало более 100. Из-за такого расширения управлять кластерами в Kubernetes стало затруднительно. Например, все обновления кластеров требовалось бы по отдельности тестировать для каждого из многочисленных типов кластеров.
На данном третьем этапе компания стремилась консолидировать свои типы кластеров, создав «разнородные» кластеры, которые были бы способны тянуть множество разных рабочих нагрузок в единой управляющей плоскости Kubernetes. Во-первых, при этом сильно снижаются издержки на управление кластерами, так как, если кластеров у вас сравнительно мало, и они универсальные, то уменьшается и количество конфигураций, которые требуется тестировать. Во-вторых, поскольку большая часть мощностей Airbnb теперь работала на кластерах Kubernetes, эффективность каждого кластера превратилась в серьезный рычаг, позволяющий сократить расходы. Консолидация типов кластеров позволяет работать в каждом кластере с варьирующимися типами нагрузок. Такая агрегация типов рабочих нагрузок – больших и малых – позволяет повысить качество упаковки в конвейеры и эффективность, а, следовательно, более полно задействовать кластер. При такой дополнительной гибкости, касающейся рабочих нагрузок, шире пространство для внедрения нетривиальных стратегий масштабирования, выходящих за пределы той логики расширения, что встроена в Cluster Autoscaler по умолчанию. В частности, ставилась цель реализовать такую логику масштабирования, которая перекликается с конкретной бизнес-логикой Airbnb.

Рисунок 3: Разнородный кластер Kubernetes
По мере масштабирования и консолидации кластеров, так, чтобы они становились разнородными (множество типов инстансов в каждом кластере), прямо в ходе расширения реализовывалась специфическая бизнес-логика, показавшая, что необходимо внести изменения в само поведение системы при автомасштабировании. В следующем разделе описаны некоторые из таких изменений, внесенные в Cluster Autoscaler для повышения его гибкости.
Улучшения Cluster Autoscaler
Собственный расширитель gRPC
Наиболее значительное улучшение, внесенное в Cluster Autoscaler, заключалось в добавлении нового метода, определяющего, какие группы узлов масштабировать. На внутрисистемном уровне Cluster Autoscaler ведет список групп узлов, содержащий разные кандидаты на масштабирование. При этом отсеиваются те группы узлов, что не соответствуют требованиям планировщика к данному поду: для актуального множества ожидающих подов (не подпадающих под планирование) имитируется прогон планировщика. При наличии таких ожидающих подов Cluster Autoscaler пытается масштабировать кластер, чтобы разместить эти поды. Любые группы узлов, удовлетворяющие всем требованиям подов, передаются компоненту, который называется Expander.
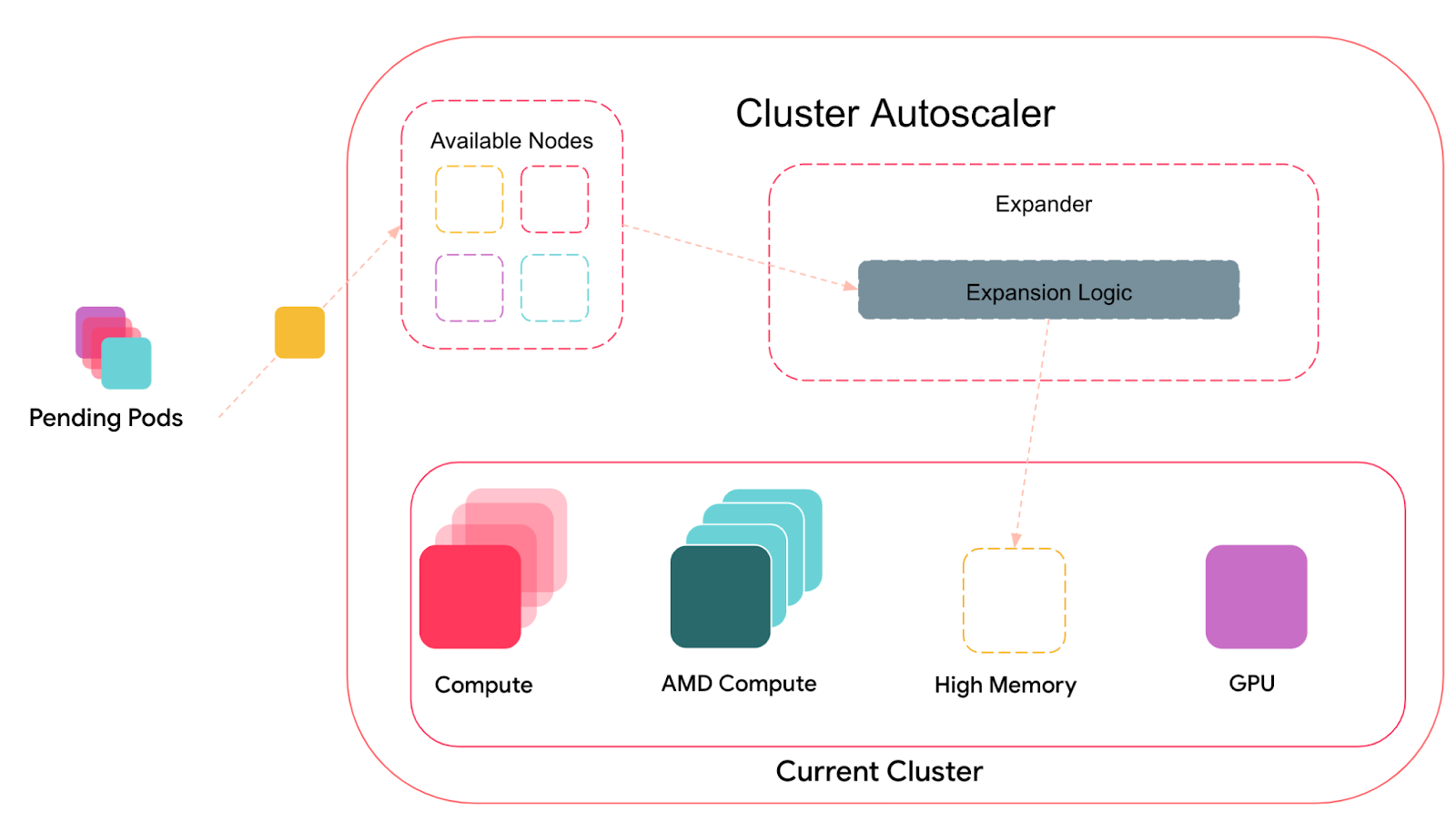
Рисунок 4: Cluster Autoscaler и Expander
Expander отвечает за дальнейшую фильтрацию групп узлов, в зависимости от требований эксплуатации. В Cluster Autoscaler есть ряд встроенных компонентов расширения, каждый из них предусматривает свою особую логику. Например, по умолчанию расширение реализуется случайным образом: вариант выбирается из всех доступных возможностей случайным однородным образом. Другой вариант – тот самый, которым исторически и пользовались в a Airbnb – это расширитель, работающий по приоритетам и выбирающий, какую именно группу узлов расширять – опираясь на составленный пользователем многоуровневый список приоритетов.
Перейдя к логике разнородных кластеров, компания обнаружила, что применяемые по умолчанию расширители недостаточно изощренные, и не удовлетворяют сравнительно сложным бизнес-требованиям, связанным с учетом расходов и выбором типа инстанса.
Немного надуманный пример: скажем, мы хотим реализовать расширитель, оперирующий взвешенными приоритетами. В настоящее время приоритетный расширитель позволяет пользователям указывать только разные уровни для групп узлов – то есть, всегда расширяет уровни детерминированно и в некотором порядке. Если на некотором уровне находится множество групп узлов, то связи будут рваться случайным образом. При стратегии взвешенного распределения приоритетов две группы узлов устанавливаются на одном и том же уровне, но одна из этих групп расширяется в течение 80% времени, а другая — в течение 20% времени, что недостижимо при настройках, действующих по умолчанию.
Кроме ограничений, присущих тем расширителям, что поддерживаются в настоящее время, приходится учитывать еще некоторые эксплуатационные соображения:
1. Конвейер доставки в Cluster Autoscaler устроен строго, и требуется время на ревью вносимых изменений, прежде, чем они будут добавлены в код и переданы наверх. Но бизнес-логика и желаемая стратегия масштабирования в Airbnb постоянно меняется. Расширитель, отвечающий потребностям компании сегодня, в будущем может им не соответствовать.
2. В Airbnb действует специфичная бизнес-логика, которая не обязательно подойдет другим пользователям. Любые изменения, внедряемые для соответствия этой логике, могут не пригодиться на более высоких уровнях системы.
На основе вышеизложенного был сформулирован следующий набор требований для нового типа расширителя в Cluster Autoscaler:
1. Необходимо решение, которое было бы как расширяемым, так и удобным для других пользователей. Другие пользователи, работая с новым вариантом, могут столкнуться с теми же ограничениями, что характерны стандартным расширителям при их крупномасштабном применении, поэтому хотелось бы предоставить универсальное решение, функционал которого можно было бы передать наверх.
2. Решение должно быть пригодно для внеполосного развертывания с применением Cluster Autoscaler, так, чтобы повысить скорость реагирования на меняющиеся бизнес-потребности.
3. Наше решение должно вписываться в экосистему Kubernetes Cluster Autoscaler, так, чтобы не пришлось неопределенно долго поддерживать форк Cluster Autoscaler.
С учетом этих требований было предложено решение, в котором ответственность ща расширение выводится за пределы базовой логики Cluster Autoscaler. Был спроектирован подключаемый “собственный Expander”, реализованный в виде gRPC-клиента (подобно собственному облачному провайдеру). Этот собственный расширитель подразделяется на два компонента.
Первый компонент – это gRPC-клиент, встроенный в Cluster Autoscaler. Этот расширитель соответствует тому же интерфейсу, что и другие расширители в Cluster Autoscaler. Именно этот компонент отвечает за преобразование информации о действующих в Cluster Autoscaler группах узлов в определенную схему protobuf (см. ниже) и получает вывод от gRPC-сервера, далее преобразуемый в окончательный список вариантов, в соответствии с которыми Cluster Autoscaler может масштабироваться вверх.
service Expander {
rpc BestOptions (BestOptionsRequest) returns (BestOptionsResponse)
}message BestOptionsRequest {
repeated Option options;
map<string, k8s.io.api.core.v1.Node> nodeInfoMap;
}message BestOptionsResponse {
repeated Option options;
}message Option {
// ID узла, нужен для уникальной идентификации nodeGroup
string nodeGroupId;
int32 nodeCount;
string debug;
repeated k8s.io.api.core.v1.Pod pod;
}Второй компонент – это gRPC-сервер, который придется написать пользователю. Этот сервер должен эксплуатироваться как отдельное приложение или сервис. Сервер должен быть приспособлен для выполнения сколь угодно сложной логики расширения и при этом выбирать, какую именно группу узлов наращивать – опираясь на информацию, полученную от клиента. В настоящее время сообщения protobuf, передаваемые по gRPC – это слегка преобразованные версии тех порций информации, что передаются расширителю в Cluster Autoscaler.
Продолжая вышеприведенный пример, отметим, что не составляет труда реализовать расширитель, работающий в соответствии со взвешенными случайными приоритетами. Для этого нужно, чтобы сервер считывал информацию из уровневого списка приоритетов, а конфигурацию взвешенных процентных соотношений брал из карты конфигураций – и соответствующим образом делал выбор.

Рисунок 5: Cluster Autoscaler и собственный gRPC-расширитель
В данной реализации предусмотрена опция отказобезопасности (failsafe). Рекомендуется использовать эту опцию при передаче в Cluster Autoscaler множества расширителей в качестве аргументов. В таком случае, если сервер откажет, Cluster Autoscaler сохранит способность расширяться на резервных мощностях.
Поскольку сервер работает как отдельное приложение, логика расширения может разрабатываться вне полосы в контексте Cluster Autoscaler. Кроме того, поскольку gRPC-сервер поддается кастомизации в зависимости от нужд пользователя, данное решение расширяемо и будет полезно широкому профессиональному сообществу.
В компании Airbnb данное новое решение используется с самого начала 2022 года и позволяет без проблем масштабировать все кластеры. Оно позволяет динамически выбирать, когда именно расширять определенные группы узлов с учетом текущих бизнес-потребностей. Следовательно, была достигнута изначальная цель написать собственный расширяемый механизм.
Наш собственный расширитель был принят и добавлен в основную версию Cluster Autoscaler ранее в этом году, а пользователям будет доступен в релизе со следующей версией (v1.24.0).
Другие усовершенствования
В ходе миграции на разнородные кластеры Kubernetes был выявлен ряд других багов и обрисованы улучшения, которые можно внести в Cluster Autoscaler. Они вкратце охарактеризованы ниже:
- Раннее отключение групп автомасштабирования AWS, не имеющих мощностей: быстрое закорачивание цикла Cluster Autoscaler, ожидающего отклика от тех узлов, которые он пытается поднять. Чтобы проверить, готовы ли они к работе, нужно вызвать конечную точку AWS EC2 и проверить, есть ли мощности в данной группе автомасштабирования. Когда такое изменение активировано, пользователь получает гораздо более быстрое и при этом правильное масштабирование. Ранее пользователи, имевшие дело с лестницей приоритетов, должны были бы ждать по 15 минут от одной попытки запустить группу автомасштабирования до следующей; только в через 15 минут можно было бы попробовать включить группу автомасштабирования с более низким приоритетом.
- Кэширование шаблонов запуска позволяет сократить количество вызовов AWS API: был введен кэш с шаблонами запуска для групп автомасштабирования AWS. Это изменение выявило большое количество таких групп, что сыграло важнейшую роль при выработке обобщенной стратегии работы с кластерами. Ранее в случае с пустыми группами автомасштабирования (когда в кластере отсутствуют узлы) Cluster Autoscaler раз за разом вызывал бы конечную точку AWS, чтобы получить шаблоны запуска. Поэтому со стороны AWS API наблюдалось.
Заключение
В последние четыре года компания Airbnb достигла больших успехов в настройке кластеров Kubernetes. Сосредоточив основную массу вычислений на одной платформе, Airbnb получила сильный управляемый механизм повышения эффективности, а далее сосредоточилась на генерализации кластерной конфигурации (как известно, серверы – это “скот, а не котики”). Разработав и поставив на службу более сложноорганизованный расширитель в Cluster Autoscaler (а также исправив ряд прочих мелких проблем в механизме автомасштабирования), удалось успешно разработать сложную стратегию масштабирования, отвечающую потребностям бизнеса, ограничив расходы и смешивая инстансы различных типов. Кроме того, некоторые достижения по результатам этой работы оказались полезны в широком профессиональном сообществе.
