
Ученые предупреждают, что мир движется к глобальному кризису хранения данных. Ожидается, что к 2025 году объем данных в мире увеличится на 300 процентов, и для всей этой информации уже начнет не хватать места. Несмотря на быстрое расширение AWS, GCP и Azure, облака не смогут разместить весь этот «умопомрачительный объем».
Такое предупреждение дают ученые из Астонского университета, которые изо всех сил пытаются разработать план, не предусматривающий паническое строительство дополнительных серверов, которые уже сейчас каждый год требуют около 1,5% мировой электроэнергии.
Чтобы как-то решить этот вопрос, команда пытается создать новую технологию для производства поверхностей с каналами шириной менее 5 нм. Это примерно в десять тысяч раз меньше ширины человеческого волоса. Что позволит создавать более энергоэффективные конструкции. Другой вариант — системы хранения данных на основе ДНК.
Профессор Мэтт Дерри, возглавляющий проект, пишет на сайте университета: «Простое строительство новых ЦОДов без улучшения технологий хранения информации не является жизнеспособным решением. Это может только немного отсрочить проблему».
«Мы все чаще сталкиваемся с риском так называемого кризиса хранения данных, и миру остро нужны улучшенные решения для хранения информации, которые занимали бы меньше места и требовали меньше энергоресурсов».
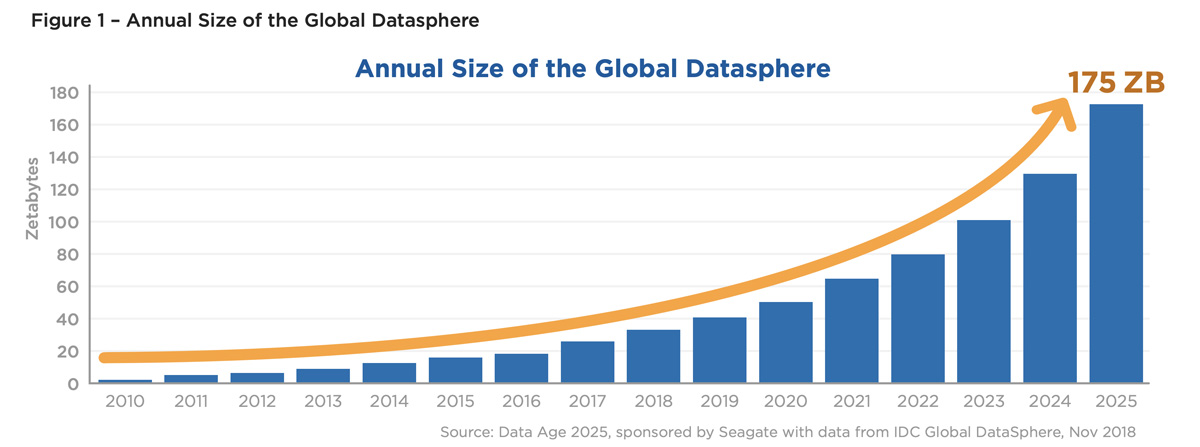
Согласно докладу Международной корпорации данных (IDC), «следствием растущей зависимости от данных будет бесконечное, неограниченное увеличение размера глобальной сферы данных, к которому нужно готовиться». Загрузить доклад можно здесь (осторожно, скачивается pdf!).
В этом докладе, в частности, говорится о том, что мировой объем хранимых данных в 2019 году составлял 45 зеттабайт, но к 2025 году он увеличится до 175 зеттабайт. Это увеличение более чем в три раза. Один зеттабайт равен триллиону гигабайт. Для его хранения требуется 240 млн 4-терабайтных жестких дисков. Это 152 тысячи тонн чистого веса металла, не говоря уже обо всем остальном.
«Если бы вы могли хранить все глобальные данные на DVD, у вас была бы стопка дисков Blu-ray, которая могла бы доставить вас до Луны 23 раза или облететь Землю 222 раза», — говорится в отчете IDC. И эта информация скоро утроится.
Резкий рост объема данных неизбежен, и Дерри и его команда, как и десятки тысяч других ученых, надеются найти решение до того, как время истечет.
Кумар Саркар, который недавно присоединился к команде Астонского университета, пишет там, что «мы будем использовать передовую химию полимеров в качестве способа концентрации данных. Увеличения их объема, располагаемого в кубическом сантиметре носителей. У нас сейчас остается только этот путь: повышение эффективности существующих технологий. Это позволит снизить потребность бизнеса и потребителей в очень дорогом и наносящем ущерб окружающей среде оборудовании. Позволит строить меньше новых мегацентров обработки данных».
Ученый добавляет, что «следующие 3 года для нас станут решающими». Если не найти способ хранить и обрабатывать данные эффективнее, цены на серверы будут неизбежно расти. В результате многие продукты, которые могли бы найти свою аудиторию и приносить пользу, станут неприбыльными и начнут банкротиться.
В 2010 году по всему миру было создано и реплицировано всего 2 ЗБ данных. Но это было всего через три года после того, как Apple выпустила свой первый iPhone, и всего через год после выхода смартфонов Samsung на рынок. А эти два устройства, вероятно, положили начало тем темпам роста объемов данных, которые мы наблюдаем сегодня. Неожиданно каждый мог снимать видео, где бы он ни находился. И люди могли просматривать это видео, где бы ни находились они. Один TikTok, с его 2,6 млрд установок, «потребляет» десятки петабайт данных ежегодно. А Ютуб обрабатывает и сохраняет около 500-700 петабайт в год.

Данные показывают особенно резкий скачок между 2019 и 2020 годами. С 41 ЗБ (зеттабайт) до 64,2 ЗБ. Произошло это в частности из-за того, что люди стали больше работать с личных устройств в условиях пандемии и ещё сильнее начали полагаться на интернет для своего развлечения.
IDC разбивает хранилища данных на три категории:
конечные точки;
периферийные устройства;
ядро.
В конечных точках находятся разные устройства вне сети, такие как смартфоны, ноутбуки, IoT и носимые устройства. К периферии относятся серверы в офисах, шлюзы и сотовые вышки. В ядре находятся ЦОДы предприятий и облачных провайдеров, где выполняется большая часть обработки и аналитики данных.
Во всей этой структуре, устроенной как слои лука, есть определенный порядок. Сначала необработанные данные передаются от конечных точек к периферии для анализа, а затем транспортируются в ядро для дальнейшего анализа и долгосрочного хранения.
IDC прогнозирует, что к 2025 году 80 % глобальных данных будут неструктурированными. Вместо того чтобы храниться в фиксированных, конкретных местах, где можно их контролировать и управлять ими, они будут буквально повсюду, перетекая из одного состояния в другое, из одного сервиса в следующий.
Международная корпорация данных также прогнозирует, что объем информации, собираемой на периферии, в том числе с помощью различных IoT и сенсорных устройств, будет увеличиваться на 33% в год. В итоге, как сообщает Seagate в своем отчете Rethink Data, к 2025 году почти 80% данных будут храниться в периферийных устройствах и в ядре.
Влияние конечных точек постепенно будет снижаться: многим пользователям теперь достаточно и хромбуков почти без собственной памяти, а коллекции музыки и видео всё чаще хранят не на своих жестких дисках, а в аккаунтах на онлайн-сервисах. Что помогает немного снизить потребность в новых хранилищах и переносит ещё больший вес сферы данных в ядро.
К 2025 году на периферию придется 22% от глобальной сферы данных. То есть у конечных пользователей будет храниться всего около пятой части от общего объема информации.
IDC прогнозирует, что 12,6 зеттабайта будут храниться в предприятиях — на жестких дисках, в флэш-памяти, лентах и компакт-дисках. А облачные провайдеры будут управлять 74% емкости. Для сравнения, сейчас в облаке хранится около 60% данных, а в 2015-м было только 30%.
Комментарии (30)

Zibx
16.01.2023 13:29+3Если бы я мог хранить данные на DVD, то у меня была бы стопка blue-ray. Интересные отчёты у IDC.
Скорость накопления данных сейчас снизится за счёт того что мы уже подошли к порогу за которым глаз перестаёт различать отдельные пиксели, а увеличение количества устройств больше не происходит с тем темпом как после выхода первых коммуникаторов.

vadimr
16.01.2023 13:48+3Эта песня про отдельные пиксели звучит при любом разрешении.
Будут хранить 3D-исходники для рендеринга в удобных зрителю ракурсах и масштабах.

novoselov
16.01.2023 21:51Для его хранения требуется 240 млн 4-терабайтных жестких дисков
Для начала стоит оценивать в более-менее современном железе, а не в допотопных HDD.
https://nimbusdata.com/products/exadrive/specifications/
ExaDrive DC 100 TB в формате 3.5"
https://www.supermicro.com/en/products/system/2u/2029/ssg-2029p-e1cr48l.cfm
Cloud-Density Storage вмещает 48 дисков в 2U
https://www.server-rack-online.com/42u-server-cabinet.html
Стандартная стойка на 42U
https://chayora.com/chayora-launches-new-10000-rack-data-centre-campus-serving-shanghai-china/
В датацентр спокойно помещается 10000 стоек
Итого: 100 PB в одной стойке, 1 ZB в одном датацентре (считал как маркетологи)
Судя по графику сейчас хранится 80 ZB, к 2025 прибавится еще 95ZB.
За предыдущий год прибавили почти 20 ZB, итого нужно расти такими же темпами и за 3 года чуток прибавить в объеме одного диска (тот же Nimbus разрабатывает диск на 200 TB).
Отбой паники, расходимся.

wazzard
17.01.2023 06:11Не учли резервирование для рейдов. Делать в датацентрах системы хранения без резервирования - моветон. Чем больше объем диска, тем больше потеряешь информации при его отказе

Alexey2005
17.01.2023 21:19Скорость накопления данных сейчас снизится за счёт того что мы уже подошли к порогу за которым глаз перестаёт различать отдельные пиксели
Скорость накопления данных в ближайшие годы резко вырастет из-за распространения генеративных нейросетей, которые генерируют контент с умопомрачительной скоростью.
Экспериментируя со Stable Diffusion, я ухитрялся забить доверху 500 Гб диск всего за ночь, а ведь это ещё только картинки. А теперь представьте, что такие нейронки будут идти в качестве компонента любого фото- и видеоредактора. Человек вводит "хочу видео с полосатыми котиками длительностью 30 минут", и сетка генерирует...
Тут рост не в разы и даже не на порядки намечается, а куда как больше.

Syzd
18.01.2023 12:05Так хранить не надо будет, нейросеть еще нагенерирует. То же самое или еще лучше.

screwer
16.01.2023 13:44+1Ожидается, что к 2025 году объем данных в мире увеличится на 300 процентов, и для всей этой информации уже начнет не хватать места
И это на фоне лютого снижения продаж ХДД ))


aaabramenko
16.01.2023 14:07+1Всё сожрут логи.

romxx
17.01.2023 08:55+4Ага. У меня в практике был такой случай. В конторе, где я занимался кой-какими стораджовыми делами, была одна база MS SQL, которая на тот момент занимала примерно терабайт диска. База была важная, и ее обычно старались не трогать по пустякам. Да и админ был, как бы это... не очень компетентный.
И вот в какой-то момент, когда размер базы подобрался к границе диска и встал вопрос о покупке большего размера диска на замену и миграции туда, кому-то все же пришло в голову посмотреть, чего же она так растет-то?
Оказалось, что примерно полтора года назад у базы сломался бэкап, и 99% объема диска под базу занимали логи, которые не трункатились с тех пор.
Вот примерно так, я полагаю, и растет в мире "объем хранения". :-}

Arhammon
16.01.2023 15:11+4Спрос-предложение, пока хранить мусор дёшево, его будут хранить. Станет дорого, отправят куда положено мусору.


Revertis
16.01.2023 15:55+3«Мы все чаще сталкиваемся с риском так называемого кризиса хранения данных, и миру остро нужны улучшенные решения для хранения информации, которые занимали бы меньше места и требовали меньше энергоресурсов».
Вы всё врёти! А как же Web 3.0, с могучим желанием всех пользователей хранить у себя петабайты данных???
Улучшенная система ранжирования нужности данных нам нужна. Например, сколько реально нужных видео из тех 500-700 петабайт видео на Ютубе? Сколько из них можно перевести обратно в текст?

cahbe
16.01.2023 16:02-2Вытереть из инета дубли, бекапы бекапов, посты ТПшек с километром фоток похода в туалет и инет скукожится до размеров одного среднестатистического датацентра.

dimka310
16.01.2023 18:16...и вход по паспорту!
Если серьёзно, то я издавна удивляюсь, откуда Google берёт резервы хранения для того же YouTube. Возможно мы, айтишники, застанем ещё обратную тенденцию ухода корпоративных данных из облака в локальные частные дата-центры.
Alexey2005
17.01.2023 12:30Youtube-то ещё ладно, там хотя бы модель монетизации понятна.
А вот есть такой сервис как Google Colab, и вот он по-настоящему вгоняет в шок невиданной щедростью. Просто прикиньте, сколько стоит аренда VPS сходного уровня даже без GPU, и уже начнёте тихо офигевать. А уж стоимость аренды VPS с GPU уровня Tesla и вовсе улетает в космос.
А Google раздаёт всё это на халяву, причём в промышленных масштабах. По ощущениям, уже у каждого студента-айтишника там есть по собственному инстансу.
Как захожу туда - каждый раз поражаюсь. У них там в Гугле что, уже коммунизм наступил, что вычислительные мощности раздаются каждому по потребностям без каких-либо попыток отбить затраты? За чей счёт банкет? Кто вообще за всё это платит?


usernotfound_yet
16.01.2023 20:28-1кризис хранения данных актуален уже давно, все дело в ценности этих самых данных.
тотальный переход с позорного х264 на куда более компактный х265 мало того что сократит емкость видеоконтента вполовину, так еще и избавит (впоследствии) ютуб и прочие "однокнопочные" от ущербных артефактов сжатия.
зачистка отсосальных сетей от никому ненужных "сторис с жопами и суши-роллами", а также стримов, стримов стримов и видеообращений ноунеймов к стенке с двумя просмотрами избавит датацентры от экзабайтов мусора.
- можно еще порнуху всю потереть
- ты в своем уме?
про то, с каким остервенением гугол все складирует "на всякий" аки барахольщица не упоминаю, это уже их личная проблема.
вобщем кризис обусловлен не только количеством данных, но и халатным отношением к полезности и востребованности этих данных. Сортировать некому и некогда, вот оно все и копится...

Vsevo10d
16.01.2023 21:03-1Просто нужно подчищать за собой, как и обычный мусор. Удалять за ненадобностью анбоксинги, стримы школьников, реакшн видео, камбоджийские фейки про строительство дворцов из глины руками и ловлю рыбы кока-колой, тупой однотипный прон, щитпостинг, видосики с домашними животными типа моя сюся пуся подрисила. Какой-нибудь механизм ввести с таймером удаления, если никто не нажимает просьбу оставить этот аккаунт.

ZekaVasch
17.01.2023 02:58+1"если никто не нажимает просьбу оставить этот аккаунт." тогда останутся только перечисленные выше, а знания уйдут в корзину
ahildar
16.01.2023 21:59Повторюсь.
Надо думать не о том, как бежать за увеличением объема информации, а про ее упорядочение и фильтрацию. Когда постоянно репостят накачанные губы, никаких накопителей не хватит)
Просто статистика:
каждую минуту через Uber заказывают 45 787 машин, Spotify добавляет 13 новых песен, пользователи Twitter постят 456 000 постов, в Instagram появляется 46 740 новых фотографий, поисковик Google реагирует на 3,6 миллиона запросов, на Wikipedia появляется 600 новых правок.
Каждую минуту рассылается 103 447 520 спам-сообщений.
Сейчас совокупный общемировой объем хранимой информации около 20 экзабайт (10 в 21-й степени), к 2025 году ожидается более 150 экзабайт. Из них только 60% будут промышленные данные, причем это в основном интернет вещей.
Проблема информационного мусора пока не слишком очевидна, но он скоро завалит нашу планету. Пора разрабатывать ИнфоВалли.
Хотя, чисто не там, где убирают, а там, где не мусорят...

Jetmanman
17.01.2023 17:50Требуется оптимизация хранимого контента.
1. Нужно исключить дубликаты данных выше определенного предела.
Не хранить временную информацию вечно
Определить насколько важна информация, всё лишнее удалить. Да тут кто-то должен будет принять решение, сервера не резиновые. Например зачем нужны бесконечные ролики про котов и собак? Люди генерируют подобный контент регулярно.
Нужно ввести различную цену на различный контент, это необязательно денежная цена, просто можно определить сколько и чего можно хранить в определенных объемах.
Хочешь не хочешь, а удалить менее важное придется, ведь иначе просто некуда будет сохранять важное. В принципе физическое ограничение хранилищь сделают это сами в некоторой степени.
aaabramenko
17.01.2023 21:47Бред, но часть проблем хранения может повесить вообще на клиента. Не спрашивайте, не знаю как технически и что конкретно, но вдруг.

CyaN
18.01.2023 11:20Рост будет даже быстрее экспоненциального. Ютьюбики и тиктоки легко потеряются на фоне одного полностью цифровизированного заводика, который станет хранить данные с датчиков IIoT и обрабатывать их. А когда захотят выявлять закономерности с большим периодом (например, несколько лет), придется хранить зеттабайты данных локально, так как существующие каналы связи с такими потоками просто не справятся. И если до мелких заводиков это дойдет не скоро, для объектов критической инфраструктуры это ближайшее будущее.
vadimr
С экспоненциальным ростом невозможно справиться простым масштабированием технологии.
kovserg
Любой экспоненциальный рост со временем «втыкается» в ограничения. Просто оценщики это не учитывают. Если будет дефицит просто поднимут цены. И тогда начнут задумываться какой мусор сохранять, а какой нет.