Apache DevLake – это интеграционный инструмент с функцией сбора информации DevOps, который презентует командам разработчиков другой этап данных через Grafana. Он также может помочь командам улучшить процесс разработки с помощью модели, основанной на данных.
Обзор архитектуры Apache DevLack
Слева на следующем скриншоте – интеграционный плагин данных DevOps (среди имеющихся плагинов находятся Github, GitLab, JIRA, Jenkins, Tapd, Feishu и наиболее продвинутый механизм анализа на платформе Simayi).
Основной фреймворк (в центре скриншота) завершает сбор, расширение и преобразование данных на доменном уровне путем выполнения подзадач в плагинах. Пользователь может запускать задачи с помощью config-UI или всех API.
RMDBS (Реляционная система управления базами данных) в настоящее время поддерживает Mysql и PostgresSQL, в будущем будет поддерживаться больше баз данных.
Grafana может генерировать различные типы необходимых данных с помощью SQL.

Затем перейдем к запуску DevLake.
Запуск системы
Перед запуском программы Golang автоматически вызовет метод init() в пакете. Нам нужно сосредоточиться на загрузке пакета сервисов. Нижеприведенный код снабжен подробными комментариями:
func init() {
var err error
// get initial config information
cfg = config.GetConfig()
// get Database
db, err = runner.NewGormDb(cfg, logger.Global.Nested("db"))
// configure time zone
location := cron.WithLocation(time.UTC)
// create scheduled task manager
cronManager = cron.New(location)
if err != nil {
panic(err)
}
// initialize the data migration
migration.Init(db)
// register the framework's data migration scripts
migrationscripts.RegisterAll()
// load plugin, loads all .so files in the folder cfg.GetString("PLUGIN_DIR"),in th LoadPlugins method(),specifically, LoadPlugins stores the pluginName:PluginMeta key-value pair into core.plugins by calling runner.
err = runner.LoadPlugins(
cfg.GetString("PLUGIN_DIR"),
cfg,
logger.Global.Nested("plugin"),
db,
)
if err != nil {
panic(err)
}
// run data migration scripts to complete the initializztion work of tables in the databse framework layer.
err = migration.Execute(context.Background())
if err != nil {
panic(err)
}
// call service init
pipelineServiceInit()
}Принцип выполнения DevLake
Процесс выполнения пайплайна Прежде чем мы перейдем к пайплайну, нам нужно сначала узнать, что такое Blueprint.
Blueprint – это задача, распределенная по времени, которая содержит все подзадачи и планы, которые должны быть выполнены. Каждая запись о выполнении Blueprint – это история запуска, она же пайплайн. Который представляет собой триггер для DevLack на выполнение одной или нескольких задач по преобразованию сбора данных с помощью одного или нескольких плагинов.
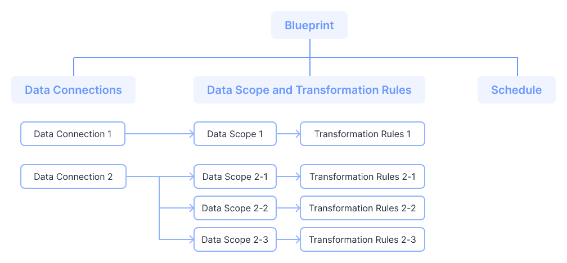
Ниже приведена блок-схема работы пайплайна.

Пайплайн содержит двумерный массив задач, в основном для того, чтобы обеспечить выполнение ряда операций в заданном порядке. Как показано на следующем скриншоте, если плагин этапа 3 должен использовать другой плагин для подготовки данных (например: работа refdiff должна опираться на gitextractor и Github, для получения дополнительной информации об источниках данных и плагинах, пожалуйста, обратитесь к документации), то когда этап 3 начинает выполняться, он должен убедиться, что его зависимости были соблюдены на этапах 1 и 2.

Процесс выполнения задачи
Задачи плагина на этапах 1, 2 и 3 выполняются параллельно:
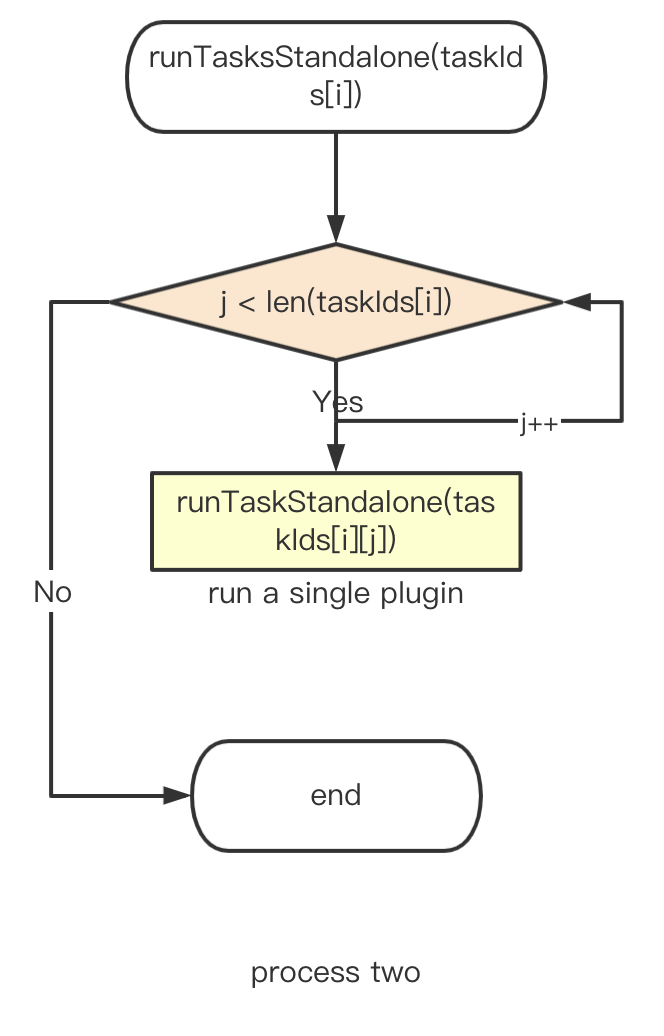
Следующий шаг – последовательное выполнение подзадач в плагине.

Перед RunTask необходимо подготовить параметры для вызова метода RunTask, такие как logger, db, context и т.д.
Основной принцип действия метода RunTask заключается в обновлении задач в базе данных, одновременно подготавливая к запуску опции задачи плагинов.
RunpluginTask получит соответствующую PluginMeta через core.Getplugin(pluginName), затем получит PluginTask через PluginMeta, а затем выполнит RunPluginSubTasks.
Процесс выполнения каждой подзадачи плагина (соответствующий интерфейс и функции будут описаны в следующем разделе)
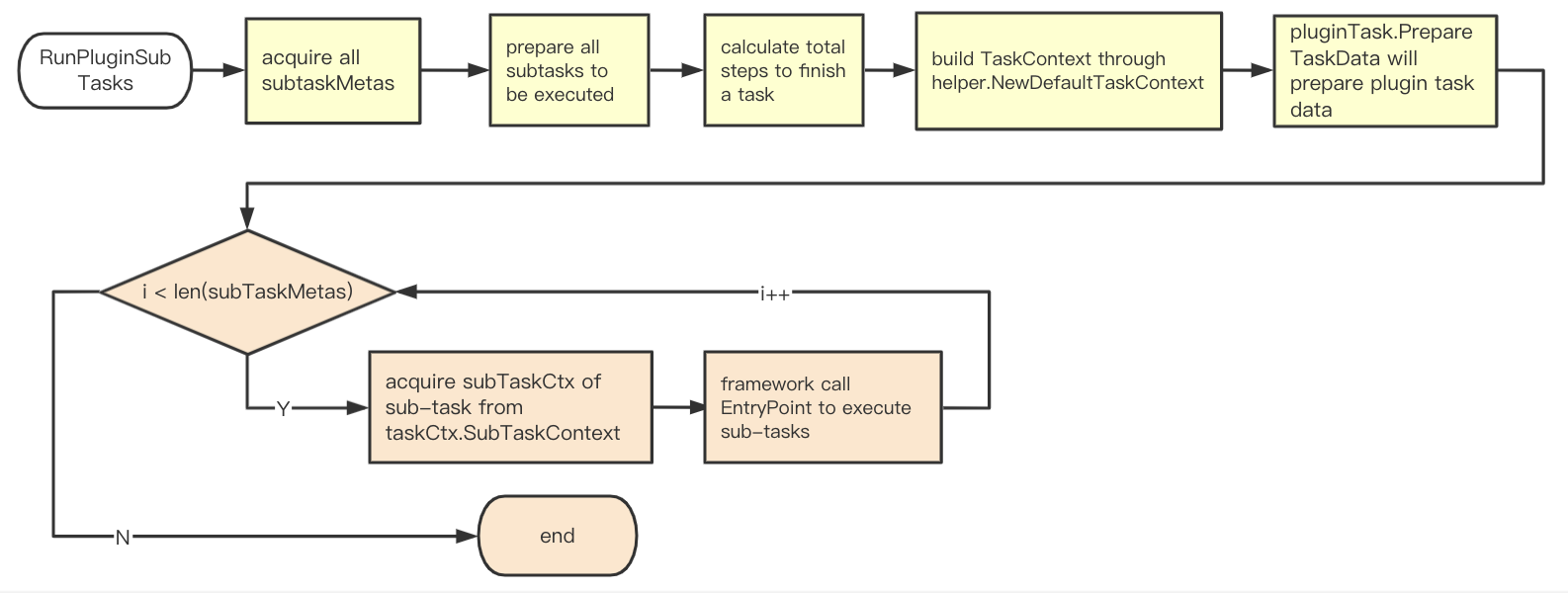
Получите все доступные подзадачи subtaskMeta всех плагинов, вызвав
SubTaskMetas().Используйте опции ['task'] и subtaskMeta для формирования набора подзадач при выполнении subtaskMetas.
Вычислите общее количество подзадач
Создайте taskCtx с помощью
helper.NewDefaultTaskContext.Создайте taskData с помощью вызова
pluginTask.PrepareTaskData.-
Выполните перебор всех подзадач в subtaskMetas.
Получите subtaskCtx подзадачи с помощью вызова
taskCtx.SubTaskContext(subtaskMeta.Name).Выполните
subtaskMeta.EntryPoint(subtaskCtx).
Важные интерфейсы в DevLake
PluginMeta: Содержит два основных метода плагинов, которые должны осуществлять имплементацию всех плагинов. Хранится в core.plugins при запуске системы. И получается через core.GetPlugin при выполнении задач плагинов.
type PluginMeta interface {
Description() string
//PkgPath information will be lost when compiled as plugin(.so), this func will return that info
RootPkgPath() string
}PluginTask: Он может быть получен с помощью PluginMeta, после того, как плагин реализовал этот метод, фреймворк может запускать подзадачу напрямую, вместо того, чтобы позволять самому плагину запускать ее. Самое большое преимущество этого в том, что подзадачи плагина легче реализовать. Мы можем этим запросто воспользоваться (например, добавление логов и т.д.) во время работы плагина.
type PluginTask interface {
// return all available subtasks, framework will run them for you in order
SubTaskMetas() []SubTaskMeta
// based on task context and user input options, return data that shared among all subtasks
PrepareTaskData(taskCtx TaskContext, options map[string]interface{}) (interface{}, error)
}Каждый плагин имеет taskData, содержащий параметры конфигурации, apiClient и другие свойства плагинов (как на github информация о репо).
SubTaskMeta:: мета-данные подзадачи, каждая подзадача определяет SubTaskMeta.
var CollectMeetingTopUserItemMeta = core.SubTaskMeta{
Name: "collectMeetingTopUserItem",
EntryPoint: CollectMeetingTopUserItem,
EnabledByDefault: true,
Description: "Collect top user meeting data from Feishu api",
}ExecContext: определяет все ресурсы, необходимые для выполнения (под) задач.
SubTaskContext: определяет все ресурсы, необходимые для выполнения подзадачи(включая ExecContext).
TaskContext: определяет все ресурсы, необходимые для выполнения задач (включая ExecContext). Разница с SubTaskContext заключается в том, что метод TaskContext() в SubTaskContext может вернуть TaskContext, а метод SubTaskContext (строка подзадачи) в TaskContext может вернуть SubTaskContext, что означает, что подзадача принадлежит подключаемой задаче, поэтому мы используем разные контексты, для того, чтобы различать это.
SubTaskEntryPoint: все подзадачи в плагине должны реализовать эту функцию, чтобы они могли быть скоординированы и упорядочены посредством фреймворка.
Дальнейший план
В этом блоге были представлены основы фреймворка DevLack и то, как он запускается и работает. Еще 3 контекста api_collector, api_extractor и data_convertor будут описаны в следующем блоге.
Завтра состоится открытое занятие «Clickhouse vs. Greenplum. Какую MPP-базу данных выбрать?». На этом уроке:
Узнаете, что такое MPP-БД на самом деле.
Познакомитесь с различными представителями таких систем.
Разберетесь, когда и в каких случаях стоит выбирать каждую из них.
На практике изучите наглядные примеры работы БД Clickhouse и Greenplum.
Записаться можно на странице онлайн-курса "Data Engineer".