
Современные бизнес приложения имеют сложную структуру, состоят из множества независимых компонентов, часто распределенных по разным узлам, контейнерам или виртуальным машинам. В связи с этим, поиск неисправностей в таких серьезных приложениях становится тоже непростой задачей, зачастую превращающейся в нетривиальный квест. При этом не стоит забывать, каждая минута простоя приложения в продакшене стоит денег, поэтому выявлять причины сбоев необходимо как можно быстрее. В этой и последующих статьях мы поговорим о том, как производить мониторинг работы приложений, осуществлять сбор событий и трейсинг для решения конкретных проблем в работе приложения. Эти статьи ориентированы на специалистов, занимающихся администрированием Linux, хотя о Windows мы тоже будем иногда упоминать.
Эта статья будет посвящена мониторингу. Мы поговорим о том, зачем вообще нужно мониторить активность приложений, как это лучше делать и какие средства лучше использовать.
Что мониторить
Какие проблемы могут возникнуть в работе приложения или веб сайта? Прежде всего, сайт может начать тормозить. Те, кто застал времена диалапа наверняка помнят, как бесила медленная загрузка какого-нибудь сайта. Так что, если ваш веб сайт медленно открывается, то вряд ли пользователи будут это долго терпеть и скорее всего, воспользуются другими, аналогичными ресурсами, которые не тормозят. Другая, не менее неприятная проблема, это когда сайт не тормозит, но работает неправильно. Не сохраняет данные, введенные пользователями, неправильно выводит результаты поиска и т.д. В такой ситуации пользователи тоже не будут долго терпеть и пойдут к конкурентам. Про случай, когда сайт просто лежит или приложение не открывается я думаю говорить не стоит, все понятно и так.
Между тем, у приведенных выше проблем в работе могут быть различные причины. Сайт может тормозить из-за медленного канала связи, низкой производительности веб-сервера, отказа одного из компонентов приложения и т.д. Для того, чтобы быстро выявлять причины сбоев нам необходимо получать обратную связь от инфраструктурных компонентов ОС, железо, СХД, сеть. Также необходимо следить за работой и состоянием поддерживающих сервисов. То есть, если приложение использует например Nginx, MySQL, то работу этих компонентов тоже необходимо мониторить. Ну и естественно, нужно мониторить работу самого приложения. Что, где и как работает.
Если необходимость мониторинга представленных выше элементов обычно не вызывает вопросов, то о мониторинге деплоя частот забывают, а зря. Как мы уже говорили, каждая минута простоя стоит денег, и это относится не только к простою самого приложения, но и к простоям программистов, разрабатывающим его. Если у нас проблемы например с Jenkins, то разработчики не могут выкладывать код и процесс разработки останавливается. Поэтому важно осуществлять мониторинг компонентов процесса деплоя, для того чтобы этот процесс был непрерывными.
Еще один вид мониторинга, неочевидный для технарей это мониторинг бизнес метрик и поведения пользователей. Бизнес тоже интересуют многие параметры работы приложения, связанные с деньгами. Например, если взять веб сайт интернет магазина, то бизнес интересует, сколько денег мы зарабатываем по будням, выходным, в определенные временные интервалы и т.д. Как не странно, эти бизнес метрики тоже могут помочь технарям. Например, в ситуации, когда в “высокий период” у нас вдруг перестали обновляться данные о заработанных деньгах. То есть по факту продажи идут, но в системе это никак не фиксируется. Это явный признак того, что в нашей системе не работает компонент учета платежей.
Надеюсь, все вышесказанное убедило читателя в том, мониторинг необходим. И подводя итог, предлагаю такое определение мониторинга: Мониторинг это совокупность инструментов и практик, позволяющая осуществлять контроль над работой IT систем и давать оценку качества работы этих систем.
Виды мониторинга
Собирать метрики с целевых систем можно по-разному. В случае, если наша система представляет собой “черный ящик”, то есть у нас нет доступа к исходному коду, и мы не можем вести мониторинг отдельных компонентов. В таком случае, мы можем вести мониторинг наличия процесса, доступности портов, собирать метрики по загруженности памяти, посчитывать коннекты и т.д. То есть, по сути, мы можем мониторить только службы ОС и инфраструктурные компоненты.
Недостатки такого подхода очевидны: мы не можем сказать, какой именно из внутренних компонентов нашей системы работает неправильно. То есть, мы можем сказать, что наше приложение расходует, к примеру более 90% памяти, но сказать какой именно компонент кушает слишком много мы не можем. То есть, мониторинг методом “черного ящика” позволяет получить общую информацию о состоянии узла, но для детального мониторинга он не пригоден.
Мониторинг методом “белого ящика” дополняет blackbox и собирает информацию о внутренней работе системы. Этот метод мы можем использовать тогда, когда нам доступны метрики с компонентов системы, такие как время запроса к БД, расход памяти при выполнении отдельных операций, количество пользователей в приложении и т.д.
Архитектура системы мониторинга
Мы разобрались с тем, что и как мониторить, теперь давайте определимся с архитектурой системы мониторинга. Основными компонентами типовой системы мониторинга являются следующие:
Средства сбора и отправки данных: агенты, API libs
Хранилище данных
Инструмент обработки и аналитики данных
Инструмент визуализации
Система оповещения
Сбор данных для системы мониторинга может осуществляться с помощью агентов, или безагентским способом. В случае использования агентов на целевые системы устанавливаются небольшие утилиты, которые собирают метрики с нужных компонентов системы, обрабатывают их должным образом и отправляют в ядро системы мониторинга. Если используется безагентский метод, то основной модуль системы мониторинга сам обращается к целевым узлам и забирает с них нужные метрики. Далее собранные метрики передаются в модуль обработки и аналитики данных, и сохраняются в хранилище.
Для того, чтобы красиво отображать метрики нам необходимы инструменты визуализации, обычно работающие через веб интерфейс. Также, для автоматизации уведомления администраторов о превышении пороговых значений или аномальных активностях желательно развернуть подсистему алертинга, которая будет автоматически отправлять оповещения.

Собирать мы будем метрики с инфраструктуры и ОС, а также метрики приложений и бизнес логики.
Системы мониторинга
Существует большое количество различных систем мониторинга, но пожалуй наиболее распространенными являются Zabbix, Nagios и Prometheus. Вот последнюю мы и будем использовать в качестве системы мониторинга, а в качестве модуля визуализации мы развернем еще одно распространенное решение – Grafana.
На схеме ниже представлено взаимодействие целевых узлов, Prometheus и Grafana.
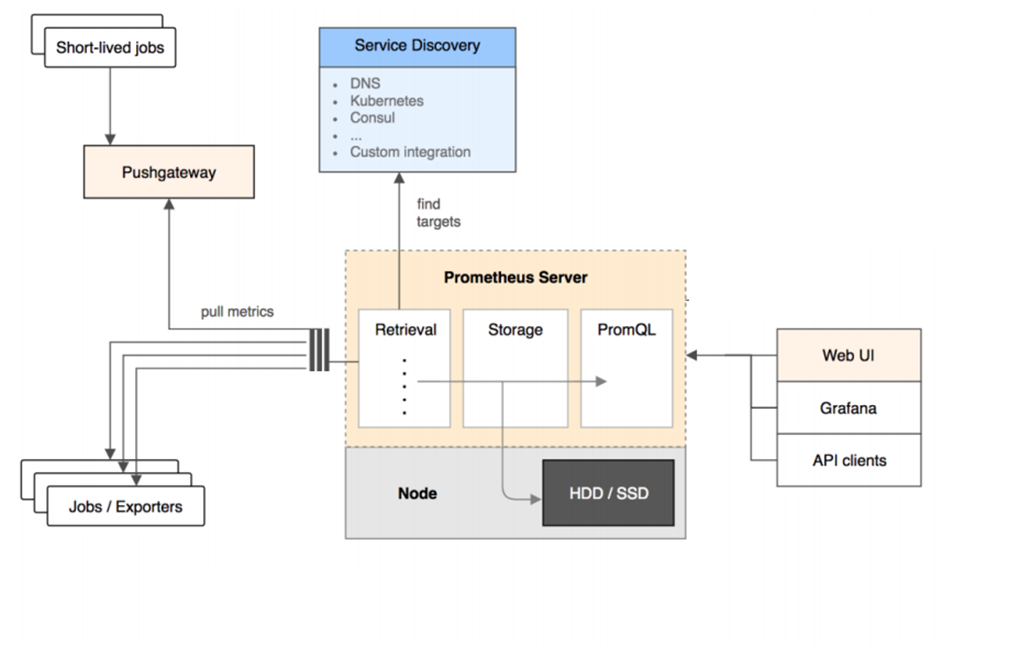
Как уже упоминалось ранее, возможны два способа сбора метрик: Pull, когда сбор инициируется системой мониторинга и Push когда метрики передают целевые системы. Prometheus использует механизм Pull, однако в случае, если нам системы могут работать только через Push, мы можем развернуть Pushgateway, с которого уже Prometheus будет сам забирать метрики.
Установка
Процесс установки Prometheus достаточно прост. В качестве примера я использую ОС Ubuntu Linux 22.04. Загрузим архив из репозитория:
wget https://github.com/prometheus/prometheus/releases/download/v2.42.0/prometheus-2.42.0.linux-amd64.tar.gz
Подготовим каталог:
mkdir /etc/prometheus
cd prometheus-*.linux-amd64
Распределяем файлы по каталогам:
cp prometheus promtool /usr/local/bin/
cp -r console_libraries consoles prometheus.yml /etc/prometheus
chown -R prometheus:prometheus /etc/prometheus /var/lib/prometheus
Задаем владельца для скопированных файлов:
chown prometheus:prometheus /usr/local/bin/{prometheus,promtool}
Для запуска Prometheus воспользуемся командой:
/usr/local/bin/prometheus --config.file /etc/prometheus/prometheus.yml --storage.tsdb.path /var/lib/prometheus/ --web.console.templates=/etc/prometheus/consoles --web.console.libraries=/etc/prometheus/console_libraries
Для того, чтобы убедиться в работоспособности решения отроем в браузере IP_адрес_сервера порт 9090. Открыться должно примерно следующее:
По умолчанию Prometheus мониторит только собственный сервер. Для того, чтобы убедиться в его работоспособности можно выбрать метрики из списка и построить их графическое представление с помощью вкладки Graph.
Но для визуализации представления лучше все-таки воспользоваться Grafana. Установка здесь тоже достаточно простая.
snap install grafana
systemctl enable grafana-server
systemctl start grafana-server
Grafana слушает порт 3000. При первом подключении необходимо будет сменить пароль пользователя.
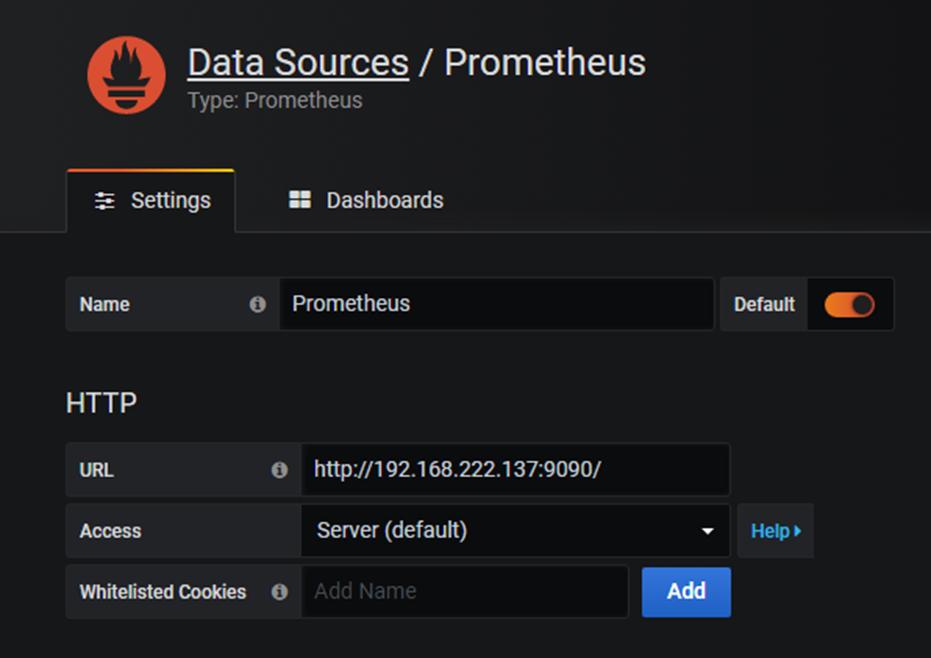
Для начала нам необходимо настроить взаимодействие с Prometheus. Для этого выбираем Configuration -> Data Sources.

Указываем адрес и порт нашего сервера.
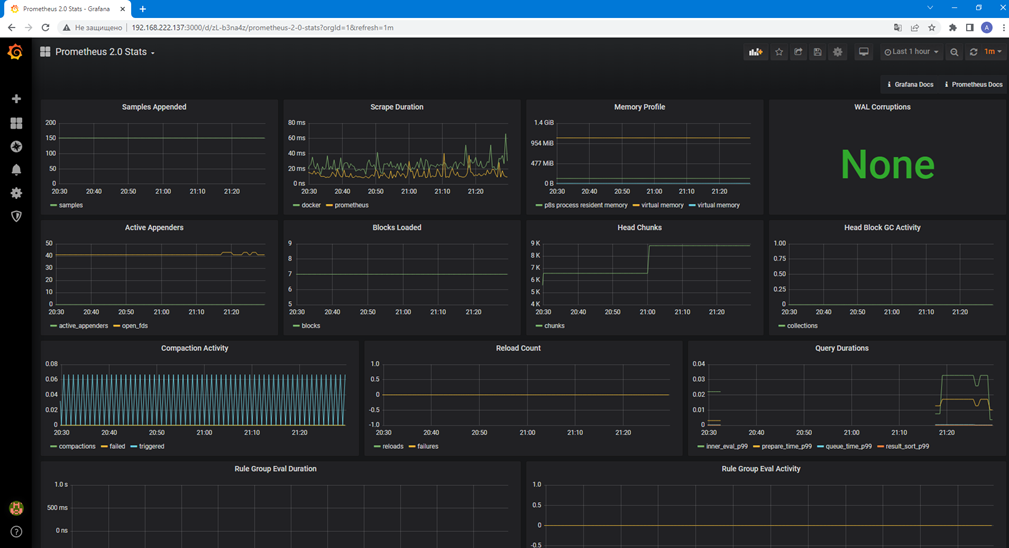
Далее для того, чтобы получить собственно красивые графики, нам необходимо создать Dashboard – набор панелей расположенных на одной странице. В Grafana есть несколько способов для создания или добавления готовых дашбордов. Но для начала мы в настройках Prometheus можем просто выбрать вкладку Dashboards и в ней импортировать Prometheus 2.0 Stats. В результате получим набор графических панелей показывающих загруженность памяти, частоту запросов и другие метрики.
При желании, дашборды можно модифицировать или дополнить, но в рамках этой статьи мы не будем это рассматривать. Вместо этого выберем свойства дашборда и далее JSON Model.
Здесь наш дашборд представлен в виде JSON-файла, который можно редактировать при необходимости.
Заключение
В этой статье мы поговорили о том, как правильно строить систему мониторинга, как лучше собирать метрики и настроили связку Prometheus + Grafana. В следующей статье мы продолжим рассматривать работу этих приложений и подключим еще несколько источников.
Также приглашаю всех желающих на бесплатный вебинар, где мы разберемся, как можно изучить Linux с нуля и какие актуальные ресурсы лучше всего использовать новичку.
Tzimie
Решает ли prometius проблемы, которую я описал тут https://habr.com/ru/post/720390/ в пункте 9? (Про то что метрика это не только число а микрорассказ)?
В Zabbix все с этим плохо
Gasparonik
Мы сделали с помощью графаны алерты, ориентируясь на несколько графиков, в зависимости от их состояния можно написать и микрорассказ.
Например: два графика: скорость ответа API и количество заказов за период. Если скорость стала меньше относительно предыдущего периода и количество заказов стало меньше относительно предыдущего периода, то сработает уведомление "падение количества заказов из-за уменьшения производительности"
Алерты работают в основном по "среднему" значению, поэтому проблемы с тем, что что-то случилось, а через 5с перестало у нас нет, но жертвуем временем реакции системы.
ildarz
Вы там не написали, что конкретно вы хотели бы видеть, поэтому сложно сказать, есть ли проблема вообще, не то что ее решение описать. :) В том же Заббиксе никто не заставляет пользоваться дефолтными счетчиками производительности, агент может брать данные из выполняемого на хосте скрипта, который вам хоть рассказ, хоть роман напишет - главное формализуйте хотелки, чтобы их можно было к какому-то алгоритму работы свести.
Tzimie
В Zabbix может быть текст (правда потоком, без форматирования). Но проблема вот в чем. Допустим мы говорим о блокировках.
Возникает лок (spid 99 waits spid 77 on DB XXX table YYY)
Через какое то время все больше локов приходит:
(spids 99,555,556,557,558 wait spid 77 on DB XXX table YYY)
В Zabbix есть два режима триггера: SINGLE и MULTIPLE. В Single изменение текста состояния не вызывают новых алертов.
В MULTIPLE другой текст вызывает появление НОВОГо алерта, а не изменения состояния старого. То есть по одной теме алерты начинают дуплицироваться
Смотрю что тут наворотили до меня... Куча костылей с какими то номерными слотами для решения подобных проблем.
ildarz
Я как раз о том, что дефолтные алерты вообще могут задачу не решать, но это само по себе не повод для печали. Основной вопрос всея мониторинга - "а на что нам вообще надо реагировать"? Вы сможете формализовать свои требования к триггеру, на который нужна ваша реакция (для начала вообще забыв о том, какая там система мониторинга)? Если да - дальше уже дело техники. Можно не кидать в Заббикс алерты на каждый лок, а накидать на хосте скрипт, который будет анализировать статистику по блокировкам именно тем способом, который нужен именно вам. А придумать способ, как по результату отработки скрипта алерт сгенерить, не такая большая проблема. Хотя бы тем скриптом кастомное событие в эвент лог отправлять, а Заббиксом на него реагировать.