Когда речь заходит про взаимодействие микросервисов, все сразу вспоминают о сложных архитектурных паттернах, вроде Event Bus и CQRS. В этой статье я расскажу, как выполнить простенькую задачку для двух микросервисов без навороченной архитектуры. В моем случае это создание сервиса, который агрегирует события компании в единую ленту событий.
Задача
Дано два сервиса:
- регистратор сотрудников,
- лента событий компании.
Цель: сделать так, чтобы в ленте создавалось событие при регистрации нового сотрудника.
С подобной задачей я столкнулся при разработке корпоративного портала Selectel. Мне нужно было организовать отображение в ленте целого ряда новых событий — в их числе изменение должности или структуры команд, переименование отдела, реакция на событие (лайк или огонек).
В моем случае я сразу пришел к одному из озвученных в тексте решений. Но, поскольку мы инсценируем эту задачу на Хабре, рассмотрим возможные реализации с описание плюсов и минусов.
30 марта мы проведем митап «Типичный Python». Обсудим типизацию, новинки в SQLAlchemy и релиз Mypy 1.0. Расскажем, как разрабатываем свои продукты и ответим на вопросы.
Регистрируйтесь на живую встречу или онлайн-трансляцию.
Решение 1. Синхронное взаимодействие
Чтобы решить задачу, будем действовать постепенно. Для начала рассмотрим самый простой для нас вариант, в котором регистратор посылает POST-запрос на создание события в ленте.

Подойдет ли нам этот подход? Зависит от того, что происходит в регистраторе. Тут нужно иметь в виду, что каждое новое действие, добавленное в метод регистрации, замедляет его выполнение. Не хочется заставлять сотрудников ждать на старте их карьеры в компании. К тому же, метод будет замедляться при добавлении новых действий. Например, регистрации в разных социальных аккаунтах.
Такое взаимодействие называется синхронным. Его лучше избегать, и сделать это довольно просто. Нужно внедрить асинхронный подход!

Решение 2. Асинхронный подход
Если попытаться нагуглить «асинхронные фоновые задачи в Python», скорее всего, наткнешься на такие решения, как Dramatiq или Celery. Они довольно популярны, и не просто так. С их помощью можно быстро накодить асинхронное взаимодействие для наших сервисов, нужен только брокер сообщений.
Брокер сообщений — это отдельный сервис, который передает сообщения в один или несколько пунктов назначения. В нашем случае он нужен для того, чтобы передать команду «Отправь задачу на создание события с параметрами a и b» в Worker. Обычно брокером выступает Redis, RabbitMQ или Kafka. Хотя бывают и случаи, когда после долгих и упорных исследований используют YMQ.
Worker — это отдельная программка, которая выполняет полученные из брокера задачи. В нашем случае именно Worker будет отправлять запрос на создание события.
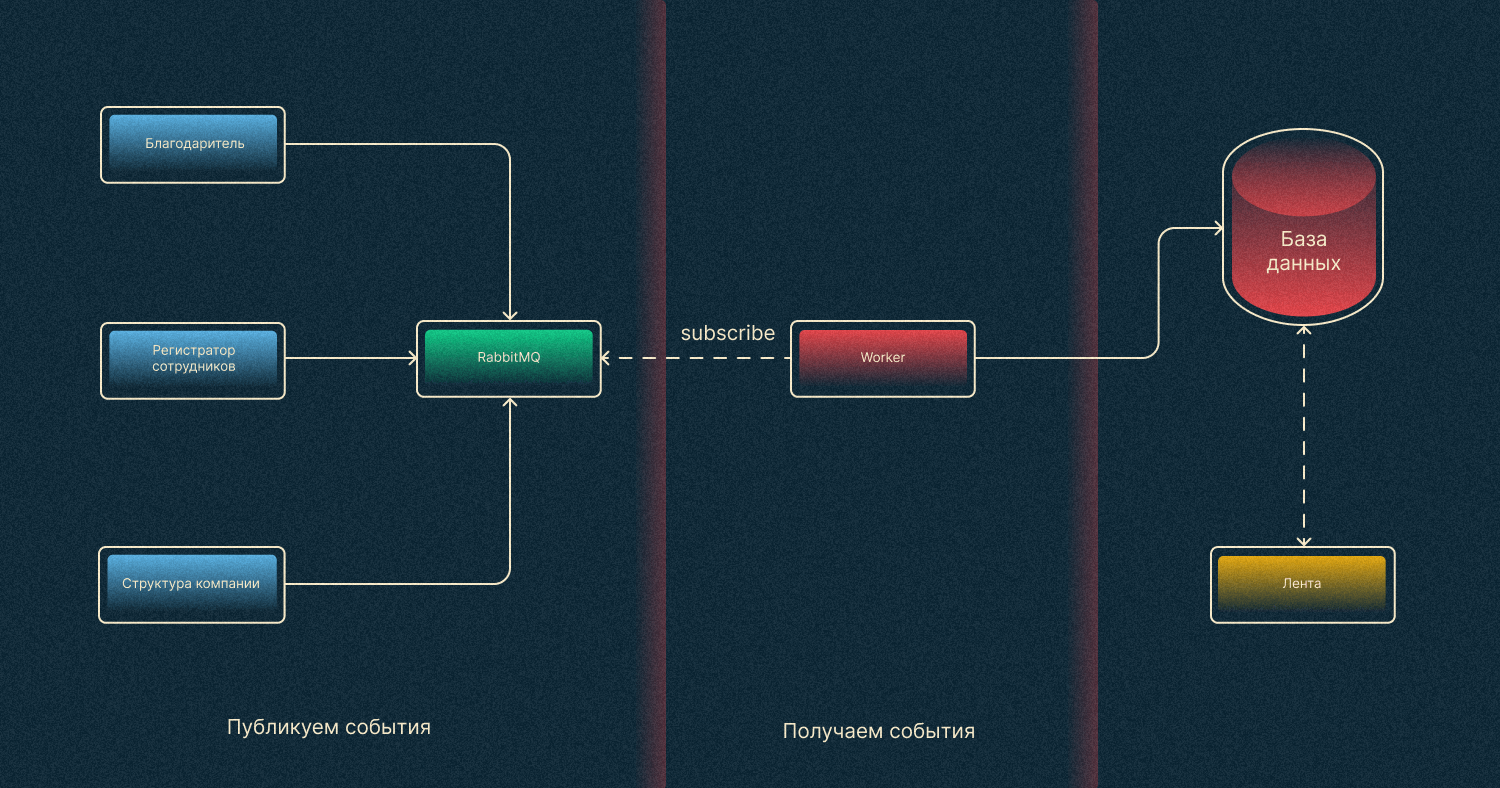
После внедрения изменений наша архитектура станет похожей на диаграмму ниже.

Регистратор посылает задачу на публикацию события в брокер RabbitMQ. В то же время на этот брокер подписан Worker, который ожидает задач от брокера. После получения задачи на публикацию события Worker посылает HTTP-запрос в сервис ленты.
Такое взаимодействие выглядит и работает намного лучше, чем первое, потому что регистратор не зависит от количества действий при регистрации, а сотрудник не ожидает их выполнения.
Можно остановиться и на этой реализации. Но в реальности, где нежданно-негаданно меняются требования, наше решение по-прежнему не доведено до ума.
А что если сервисов станет больше? Отправление событий по HTTP
Представим, что мы выкатили решение в прод. События при регистрации появляются в ленте, все довольны, всем все понравилось. Настолько понравилось, что сотрудники подумали и попросили: «Слушайте, а давайте добавим еще событий в ленту? Например, будем отправлять сотрудникам благодарности или информацию об изменениях в структуре компании».
Что случится с нашей архитектурой, если отправлять сообщения в ленту будет не только регистратор, но и еще несколько сервисов?

В этом случае каждый сервис будет посылать в ленту события по HTTP, а это будет необоснованно нагружать сервис. К тому же, держим в голове, что, помимо получения событий, сервису ленты нужно их еще и показывать по запросу на главной странице портала.
В принципе можно оставить все как было. Но такой подход будет хорошо работать до тех пор, пока:
- мало событий,
- мало сервисов, которые шлют события,
- мало сотрудников.
Решение 3. Очередь RabbitMQ
Появляется вопрос: «Можно ли как-то избежать лишней загрузки сервиса?» Ответ: «Можно, если убрать HTTP из нашей схемы».
Действительно, зачем нам нужно отправлять запросы из Worker-ов по HTTP, когда мы можем сразу из сервисов отправлять задачи через брокер в Worker, который имеет доступ к БД ленты. А он будет эти события напрямую записывать.
После преобразований наша схема станет такой:
Как это реализовать? Создаем очередь (RabbitMQ) специально для нашего сервиса событий. Из каждого сервиса мы публикуем события в эту очередь. Отдельный Worker, в свою очередь, выполняет задачи из брокера. Если говорить терминами, то наши сервисы — это publisher-ы, а Worker ленты — это consumer.
На этом месте уже можно остановиться. Подход хороший, все работает классно, и теперь можно не беспокоиться за новые требования наших сотрудников. Осталось только понять, как все это реализовать на Python.
Реализация на Python
Раз сервисов много, будет логично сделать Worker ленты асинхронным, так как у него будет много простоев из-за ожидания ввода/вывода.
Для его реализации будем использовать библиотеку aio-pika.
async def main():
try:
connection = await aio_pika.connect_robust(settings.rabbitmq_dsn) # соединение с RabbitMQ
except exceptions.CONNECTION_EXCEPTIONS as e:
logger.error(e.args[0])
await asyncio.sleep(3)
return await main() # запускаем бесконечный цикл, пока не подключится
async with connection:
channel: aio_pika.abc.AbstractChannel = await connection.channel()
queue: aio_pika.abc.AbstractQueue = await channel.declare_queue(
settings.queue_name, durable=True
)
logger.info("Starting consuming")
while True:
try:
await consume(queue) # начинаем слушать очередь
except exceptions.CONNECTION_EXCEPTIONS as e:
logger.error(e.args[0])
return await main()
except Exception as e:
logger.error(e.args[0])
if __name__ == "__main__":
logger.info("Starting queue worker")
asyncio.run(main(), debug=settings.app_env == AppEnvEnum.local.value)
Функция consume тоже очень простая.
async def consume(queue):
message: aio_pika.IncomingMessage
async for message in queue:
async with message.process():
context = {
"service_name": message.app_id,
"task_id": message.message_id,
}
with logger.contextualize(**context):
logger.info("message is being processing")
data = json.loads(message.body.decode())
await create_new_events(data) # тут ваша бизнес логика
logger.info("message successfully processed!")
С consumer-ом разобрались, а что с publisher-ами? Сейчас в большинстве компаний существуют как синхронные, так и асинхронные сервисы, поэтому приведем пример и того, и другого.
Для синхронных сервисов будем использовать модуль pika.
def _get_message_properties(message_id: Optional[str] = None):
return pika.BasicProperties(
delivery_mode=DeliveryMode.Persistent.value,
content_type="application/json",
content_encoding="utf-8",
message_id=message_id or uuid4().hex,
app_id=project.config.application_name,
)
def _create_connection():
parsed = urlparse(_events_feed_config["queue"]["dsn"])
credentials = pika.PlainCredentials(
username=parsed.username, password=parsed.password
)
param = pika.ConnectionParameters(
host=parsed.hostname,
port=parsed.port,
virtual_host=parsed.path[1:],
credentials=credentials,
)
return pika.BlockingConnection(param)
def publish_to_events_feed(data, message_id):
with _create_connection() as connection:
channel = connection.channel()
properties = _get_message_properties(message_id)
logger.info("message is publishing")
channel.basic_publish(
exchange="",
routing_key=_events_feed_config["queue"]["name"],
body=json.dumps(data).encode(),
properties=properties,
)
logger.info("message successfully published")
А для асинхронных по-прежнему aio-pika.
def _create_message(data: bytes, message_id: Optional[str] = None):
return aio_pika.Message(
body=data,
content_type="application/json",
content_encoding="utf-8",
message_id=message_id or uuid4().hex,
delivery_mode=aio_pika.abc.DeliveryMode.PERSISTENT,
app_id=config.app_name,
)
async def _publish_events(data: EventListModel, message_id=None):
connection = await aio_pika.connect_robust(config.events_feed_queue_dsn)
async with connection:
routing_key = config.events_feed_queue_name
channel: aio_pika.abc.AbstractChannel = await connection.channel()
message = _create_message(data.json().encode(), message_id)
logger.info("message is publishing")
await channel.default_exchange.publish(
message,
routing_key=routing_key,
)
logger.info("message successfully published")
Заключение
Когда вы решаете задачу, исходите из требований. Зачастую не нужно строить сложную архитектуру — достаточно просто сделать POST-запрос. Когда же ваши сервисы начинают глючить, подвисать либо вы заранее знаете, что нагрузка будет высокой, имеет смысл выстроить хорошее решение для пользователей.
А если у вас есть решения 4 и 5 для задачи, приходите в комментарии — обсудим!
Возможно, эти тексты тоже вас заинтересуют:
→ Удар, еще удар: производство ОЗУ переживает не лучшие времена. Цены падают, производство сокращается
→ Полезные материалы по Data Science и машинному обучению, которые помогут пройти сквозь джунгли из терминов
→ КПК HP iPaq, Дюма 1870 года и PCMCIA факс-модем: новые находки на испанской барахолке
Комментарии (34)

9982th
00.00.0000 00:00+1return await main()
Если брокер однажды окажется недоступен, ваша реализация упадет с RecursionError чуть менее, чем через час. Причем этот час будет накапливаться по чуть-чуть и при меньших даунтаймах, вплоть до единичных ошибок.

Krivohizhin
00.00.0000 00:00В celery тоже можно одним воркером обойтись, и тоже им в базу писать.
А вот асинхронный таск... Хм..
Всё равно запись будет последовательной (на уровне базы блок, пишем же наверно в одну таблицу) и хронология может сбиться. При асинхронном воркере и асинхронной записи в базу, очередь конечно быстрее будет разбираться, но будут ли производители так быстро публиковать события, судя по бизнес-процессам - нет.
Думаю асинхронность здесь избыточна, хотя и самому нравится использовать asyncio. Ну что поделаешь, модно)

gardiys Автор
00.00.0000 00:00+2Если лента уже асинхронная, то и воркер хорошо бы сделать таким же, чтобы можно было шарить готовые функции между ними) А так наверно не критично конечно)

dph
00.00.0000 00:00+1А чем все-таки плох синхронный подход? Простой и, в данном сценарии, наиболее надежный, с минимальной latency, простотой контроля и развития.

Hedgehogues
00.00.0000 00:00Синхронный подход ничем не плох. Важно понимать, чего вы хотите им добиться. Может, например, стоит объединить два компонента в один?
dph
00.00.0000 00:00Автор пишет "Такое взаимодействие называется синхронным. Его лучше избегать". Хотелось бы понять, чем обусловлена такая рекомендация?
Hedgehogues
00.00.0000 00:00Скорее всего автор имел ввиду, что при синхронном взаимодействии происходит в среднем рост нагрузки на инфраструктуру
dph
00.00.0000 00:00Но это же не так.
Сделать http вызов с serviceA на serviceB очевидно дешевле, чем с ServiceA к брокеру и с брокера на ServiceB.
Я уж не говорю, что тот же кролик "из коробки" не дает никаких гарантий, а для доставки at-least-once нужно будет громоздить кластер, персистанс и специального человека на поддержку всего этого добра. Впрочем, чистый http call тоже не дает никаких гарантий, но хотя бы не является SPOFHedgehogues
00.00.0000 00:00Только от сервиса А к сервису Б у вас будет регулярный запрос, потому что в одном из них нет данных. Во втором случае такого не происходит, если данные заранее передаются. Хотя, конечно, можно спроектировать всякое
dph
00.00.0000 00:00Нет разницы, как запрашивать данные, синхронно или асинхронно, в обоих случаях результат можно сохранить, если он нужен.
Hedgehogues
00.00.0000 00:00Ровно это я и говорю, что данные не нужно запрашивать. Их нужно отправлять. Если вы запрашиваете, значит данными не владеете. А владеет соседний компонент. Значит нагрузка растёт, потому что в большинстве случаев вы это будете делать регулярно, чего нельзя сказать об отправке
gardiys Автор
00.00.0000 00:00+1На мой взгляд нужно стремиться к асинхронному подходу из-за этих причин:
1) Увеличиваете длительность работы эндпоинта, а от этого замедляется система в целом, клиент долго ждет ответ от сервера и так далее снежным комом
2) Если вдруг по каким-то причинам лента приляжет на короткий промежуток времени и будет невозможно отправить событие туда, то оно просто потеряется. Чтобы этого не допустить можно добавить ретраи в код, но это еще больше увеличит длительность работы эндпоинта, замедлит систему и опять снежный ком)
dph
00.00.0000 00:00Это неверно. Если нужен ответ от сервиса, то все равно вызывающий ждет response-сообщения от MQ, только при этом требуется гораздо больше времени. А если ответ не нужен - то зачем его ждать?
Клиенту нужен результат и если для его получения нужно вызвать 10 методов - они все будут вызваны, не важно, через MQ или синхронно. Но если вызывать через http/grpc, то результат будет быстрее и нагрузка на систему будет гораздо меньше.Если приляжет MQ, то нужно будет сделать точно то же, так что логика retry в коде все равно будет нужна. Впрочем, нормальный resilience для http есть во всех языках и странно его не использовать.
В общем, не видно, с чего бы вызовы через ненадежный и без гарантий рэббит был бы хоть по каким-то параметрам лучше, чем прямой http вызов. Ну а если в кролике включать гарантии доставки (или, лучше, ставить кафку), то latency вырастет еще выше. Да и проблему с отправкой сообщений все равно не решить (
gardiys Автор
00.00.0000 00:00В том то и дело, что клиенту результат о том, что "событие добавлено в ленту" не нужен, это происходит автоматически и клиент об этом может и не знать)
dph
00.00.0000 00:00(Прошу прощения, промахнулся по оценке, постарался компенсировать в других ваших комментариях).
В конкретных случаях - да, может быть, так как фактически речь идет о стриминге изменений между двумя bounded contexts. Правда, кролик тут неудачный выбор и нужно бы Transaction Outbox прикрутить. Впрочем, когда есть TO, то он может и синхронно отправлять события, зачем там асинхронный MQ.
Но, в любом случае, это не про "синхронные взаимодействия вообще плохи".gardiys Автор
00.00.0000 00:00Согласен с вами, наверно стоило бы сказать "по возможности стоит избегать" или "в зависимости от вашей ситуации". Потому что, конечно же, бывают случаи когда удобно отправить синхронный запрос, все зависит от контекста приложения и ваших потребностей)
dph
00.00.0000 00:00Да и "по возможности стоит избегать" - не совсем верно. Скорее уж асинхронное взаимодействие по возможности лучше избегать - как сложно контролируемое, увеличивающее latency и сложность кода.

hardtop
00.00.0000 00:00-1Действительно, http мешал им… а давайте post запросы делать.
Грустно всё это.


savostin
00.00.0000 00:00-1Вот только если что-то поменялось в Ленте, например в структуре БД, Вам (но т.к. у нас "настоящий" микросервис, то не Вам, а тому, кто его написал, а это не всегда тот же, кто пишет Ленту) теперь придется переписывать Worker. И доступ к БД Ленты из Worker - тоже не лучшее решение (Worker может быть далеко). Поэтому имхо самый "правильный" вариант - последний, но оставить доступ из Worker к Ленте по HTTP/API. Если боитесь, что Worker завалит Ленту, устанавливаете throttle (не больше N, а лучше M запросов в секунду).

Lioshik
00.00.0000 00:00Всё куда проще, надо сделать worker частью Ленты. Тогда Лента сама будет вычитывать данные из очереди и класть их в свою базу нужным образом.
savostin
00.00.0000 00:00Это конечно проще, но "Лент" может оказаться нужно запустить много больше, чем "Worker", например....
Lioshik
00.00.0000 00:00+1и каждый сервис будет включать в себя логику того, как именно ему надо распорядиться информацией о сообщении. Поставщик же просто уведомляет всех заинтересованных "появился новый человек". А подписчики уже реагируют по-своему.
savostin
00.00.0000 00:00-1Просто такими темпами Вы придете обратно в монолит ;)
Lioshik
00.00.0000 00:00+1Если под "монолитом" понимается то, что сервис делает более одной вещи (слушает очередь и предоставляет api) то да, деплоится сервис, который обслуживает часть домена и он единственный знает как с этой частью работать.
И то, что запущено 10 копий этого сервиса, но под чтение очереди используется 0.000001% мощности одной копии, а всё остальное выедает API на мой взгляд ничего страшного.
Можно конечно делить сервис на отдельные операции и деплоить 10 копий "Лента-GET-List", 5 копий "Лента-GET-Message" ,2 копии "Лента-POST-mesage", ... но все эти наносервисы будут зависимыми от единой доменной модели сервиса. В том числе и по деплою.
gardiys Автор
00.00.0000 00:00У нас нагрузки разные, лента запускается на трех подах, worker на двух, плюс еще у ленты соединение к БД на пулах, а у worker-а нет. Ваш подход не предлагает такой гибкости в настройке)
gardiys Автор
00.00.0000 00:00В целом, неплохое предложение по дальнейшему развитию, ну и выглядит как вариант 4) Мне показался достаточным 3-й вариант, когда воркер просто смотрит в БД, но, все мы знаем, что лучший код еще не написан)

Andrey_Solomatin
00.00.0000 00:00А что если сервисов станет больше?
Вот тогда и переделаете.
Если остановиться на втором варианте, можно попробовать очередь в базе хранить. https://docs.celeryq.dev/en/stable/getting-started/backends-and-brokers/index.html#sqlalchemy, не надо замарачиваться с поднятием отдельного брокера.
Моя любимая стратегия решить просто, посмотреть, что будет, переделать под новые требования.
Аргументы про нагрузку мне кажутся еще не достаточно сильными для перехода к третьему решению. Чем больше технических решений вы прячeте внутри и не показываете наружу, тем легче будет адаптироваться.
Хотя если процессы налажены, то второе и третье решения будут премерно одинаково затратно по врeмени. Я работал с очередями на AWS, там это несколько строк конфигов и не надо следить за инфраструктурой.
Hedgehogues
Побуду токсичным
В первом случае почти со 100% вероятностью у вас не микросервис. Почему я это предполагаю. Если сервис обращается за данными, то значит они ему зачем-то нужны и он хочет ими воспользоваться. Возникает вопрос, почему он их не хранит внутри себя. В силу наличия синхронной связи, он "сильно" связан с соседом. То есть он не может существовать без этих данных
Таким образом, основываясь на идее о том, что микросервисы -- это слабосвязанные объекты, можем заключить, что эти объекты не являются микросервисами, в том смысле, как это понимает, например Chris Richardson тут:
https://microservices.io/patterns/decomposition/decompose-by-business-capability.html
и
https://microservices.io/patterns/decomposition/decompose-by-subdomain.html
Относительно двух других примеров, в явном виде не следует, что это не микросервисы. Без примера бизнес-задачи сказать этого невозможно. Но рассуждениями можно прийти к выводу, что в широком спектре бизнесов такие компоненты не будут микросервисами
whoisking
Если микросервис не хранит в себе данные, то он просто stateless, а далее много разных профитов. Если микросервис не завязан ни на какие данные, то зачем он вообще нужен, что он вообще делает?) Все сервисы это так или иначе обработка данных. Взять для примера самый распространенный - сервис аутентификации. Как он может жить без данных пользователей? Он в любой системе будет зависеть от них, без данных он никому не нужен.
Hedgehogues
Я не говорил про системы, которые не хранят данные. Я сказал только про то, что это не сервис в понимании, которое имеет ввиду большинство людей и один из популярных авторов.
Я также подразумевал, что такая конфигурация будет выдавать меньший lead time, чем могло бы быть в иных случаях. При этом, вероятно, будет иметь другие параметры. Про конкретную задачу сложно сказать. Вероятно, она будет оптимизировать пару нагрузка-деньги.
PrinceKorwin
А также graphql сервис по вашему определению это не микросервис. И всех кого он "покрывает" нужно впихнуть в него? :)
gardiys Автор
В первом случае же никто не обращается за данными, скорее один сервис посылает их сам в Ленту, когда произошло какое-то событие. Ну и события тоже конечно хранятся)