Сегодня обсудим узкоспециализированные возможности и кейсы использования RabbitMQ. Эти вещи полезны не всем, но в некоторых случаях помогают сэкономить уйму времени.
Что конкретно разберём:
расчёт количества консьюмеров по формуле Эрланга;
шардирование — различные способы балансировки;
дедупликацию сообщений в очереди;
многоуровневую очередь повторных попыток;
приоритеты сообщений.
Статья подготовлена на основе конспекта Алексея Барабанова, IT-директора «Хлебницы».
Другие конспекты:
RabbitMQ: терминология и базовые сущности
Как запускать RabbitMQ в Docker
Типовое использование RabbitMQ
Разбираемся с High Aviability и HighLoad
Расчёт количества консьюмеров
Немного истории

Агнер Краруп Эрланг — сотрудник датской телефонной компании.
Он проводил анализ работы местной телефонной станции одной деревни, жители которой совершали вызовы абонентам других населённых пунктов. На основании этих работ он и стал основоположником теории массового обслуживания.
Поработав в телекоме длительное время, начинаешь понимать что массовое обслуживание — это не только call-центры, но и любые другие потоки обработки данных. Необязательно с применением живых операторов. В системах call-центров так же, как и в высоконагруженных IT-системах, используются очереди и распределённые нагрузки. Кстати, для серьёзных call-центров очереди RabbitMQ не подходят, потому что они слишком статичны.
Обращаю ваше внимание на то, что RabbitMQ написан на Erlang — языке, созданном в первую очередь для разработки телекоммуникационных приложений. Есть две версии этимологии названия этого языка: или в честь Агнера Эрланга, или просто как сокращение «Erisson language». Теперь уже никто и не вспомнит.
Формула
В 1917 году Эрланг изобрел формулу, которая до сих пор активно используется в телекоме.
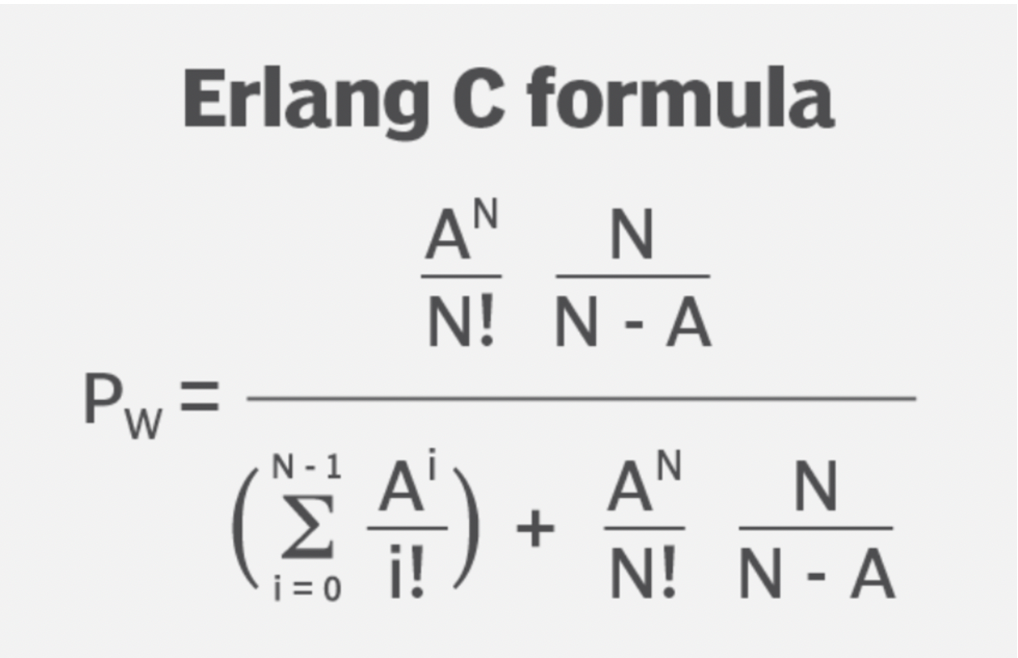
На изображении выше представлена формула Erlang-C для расчёта количества операторов для обеспечения требуемого уровня SLA.
Эта формула отлично подходит для определения количества консьюмеров, необходимых для обработки определённого количества сообщений в момент времени. Формула может пригодиться, когда обработка ваших сообщений занимает больше секунды и нужно спланировать мощности под размещение консьюмеров. Также её можно адаптировать для расчёта более быстрых консьюмеров. Но все текущие реализации имеют шаг в одну секунду.
Понятное дело, что в таком виде использовать формулу сложно. Есть масса онлайн калькуляторов Erlang-C — стоит только загуглить. Однако эти калькуляторы заточены преимущественно под call-центры, поэтому не во всех можно указать время обработки меньше 5 секунд.
Реализация
На PHP и Apache 2 я сделал простейшую реализацию библиотеки Erlang-C. Почему не на Golang? Я делал лет 10 назад, и переписывать просто лень. Реализацию выложил в этот репозиторий в папку /erlang-c. Внутри есть необходимые для сборки и запуска файлы, веб-морда выглядит предельно аскетично.

Вверху вводим количество обрабатываемых сообщений за интервал, затем длину этого интервала.
Максимальная длина очереди говорит, сколько сообщений допустимо держать в очереди до их взятия в обработку.
Время обработки — среднее время обработки одного сообщения.
В конце идут два параметра SLA — это время ожидания каждого сообщения до начала обработки и процент, сколько сообщений уложатся в это время.
Нажимаем Calculate и получаем необходимое количество консьюмеров.

«RabbitMQ для админов и разработчиков»
Шардирование
Шардирование — это балансировка одного потока сообщений по очередям или инстансам RabbitMQ с применением (или без) ключа шардирования.
Использование ключа шардирования необходимо, если вы хотите, чтобы все сообщения с одним ключом попадали в одну очередь.
Плагины:
consistent-hash — позволяет шардировать по консистентному кругу шардирования;
modulus-hash — с более простым и быстрым шардированием по целочисленному делению;
random — без использования ключа шардирования, просто рандомное распределение.
Также можно настроить шардирование (но без ключа, просто рандомно) при помощи Shovel. Теперь давайте поподробнее о каждой методике.
consistent-hash
Шардирование по консистентному хэшу — не думаю, что в рамках этой статьи есть смысл объяснять его принципы. Можете просто загуглить consistent hashing — вылезет много картинок с кругами. Если вкратце, этот механизм шардирования обеспечивает максимально высокий процент попадания одних и тех же ключей в свои шарды при изменении количества узлов шардирования. Это бывает полезно, когда вам нужно, чтобы сообщения с одним и тем же признаком шардирования (например, город или магазин) всегда обрабатывались в рамках одной очереди. И в случае изменения количества шард распределение менялось не так значительно, как в других методологиях шардирования.
Для запуска механизма необходимо включить в RabbitMQ встроенный плагин rabbitmq_consistent_hash_exchange.
Кстати, плагины можно включать на лету без перезагрузки RabbitMQ командой rabbitmq-plugins. Просто наберите внутри контейнера команду rabbitmq-plugins enable **name_of_plugin**. RabbitMQ при этом должен иметь права на запись в файл enabled_plugins.
После включения плагина при создании exchange появится новый тип exchange — x-consistent-hash. Логика работы этого exchange отличается от привычного exchange.

Такой exchange шардирует все сообщения по ключу шардирования, которым по умолчанию выступает RoutingKey. Делает он это равномерно по всем биндингам, но логика RoutingKey здесь кардинально другая: это вес биндинга при шардировании. Например, на скриншоте половина роутингкеев будет распределена в очередь q4, а вторая половина будет разделена на 3 части и распределена между q1, q2 и q3.

Понятное дело, что если у вас поток сообщений будет с одним routing key, все сообщения попадут в одну и туже очередь. Для проверки нужно отправлять сообщения в exchange с разными routing key.
Также важное преимущество consistent hash шардирования — при добавлении новой шарды распределение routing key по шардам будет изменено незначительно. Но это и минус — за такой подход приходится платить снижением производительности шардирования.
Шардирование по консистентному хэшу может работать не по routing-key, а по заголовку. Для этого при создании exchange нужно указать, какой именно header использовать как ключ шардирования:

modulus-hash
Теперь переходим к более простому механизму шардирования — целочисленное деление хэша на количество шард. Главные его преимущества: скорость и минимальное потребление ресурсов. Из минусов могу отметить полное нарушение консистентности шардирования при изменении количества шард. Также этот механизм не умеет в веса шард. Ну, и шардирует он только по RoutingKey. Называется плагин rabbitmq_sharding.
После добавления у нас появится новый тип exchange — x-modulus-hash:
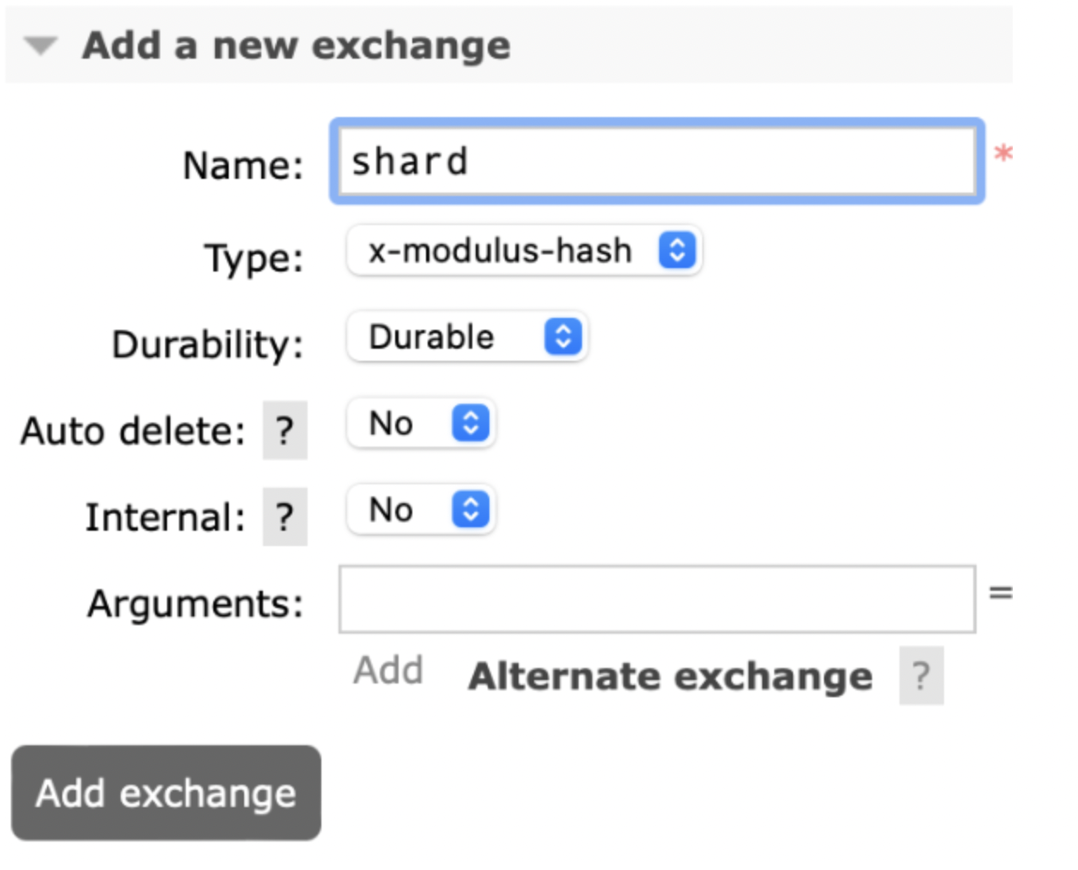
При биндинге очередей к exchange RoutingKey игнорируется, поэтому проще всего оставить его пустым. По сути сообщения по routingkey расшардируются на 4 очереди, всё довольно просто.

При проверке не забываем, что шардируется именно по RoutingKey. Меняем его, чтобы достичь распределения.
random
Теперь переходим к ещё более простому механизму шардирования — случайному. Плагин называется rabbitmq_random_exchange, добавляет x-random тип exchange:
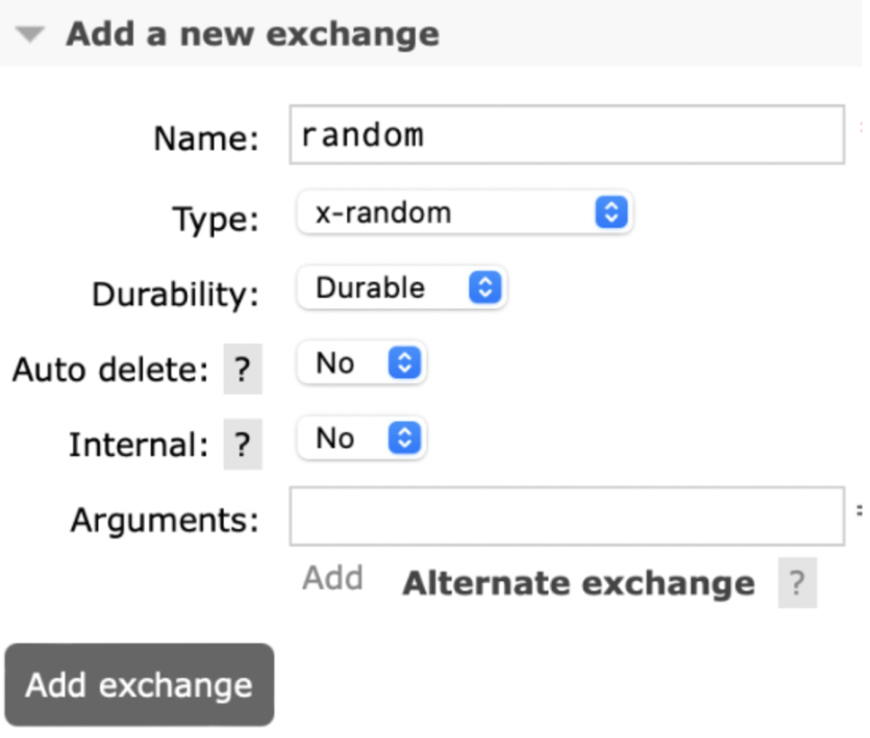
Шардер просто случайным образом выбирает из списка биндингов любой и отправляет сообщение туда. Все поля сообщения игнорируются, можно отправлять их с одним routingkey чтобы увидеть результат. Работает быстро, когда допустимо подобное распределение — вполне себе удобно.
shovel
Также аналог случайного распределения можно реализовать на shovel’ах. Создаём обычную очередь и перенаправляем сообщения из неё в 4 очереди. Распределение будет полностью аналогичным распределению x-random, единственным отличием будет возможность шардировать не только внутри одного rabbitmq, но и распределять шарды по удалённым инстансам RabbitMQ.

В данном случае очередь in разгребается на 4 очереди: s1, s2, s3, s4.
Самописный
Также можно написать свой самописный шардер. В некоторых случаях когда, например, необходимо шардирование по ключу из тела сообщения (поле json возможно) не остаётся ничего другого, как реализовывать свою логику шардирования. Вы можете или вынимать это поле и отправлять дальше это сообщение в x-consistent-hash exchange с таким RoutingKey, или же полностью реализовать всю логику у себя.
Дедупликация
К сожалению, у RabbitMQ нет штатного механизма дедупликации сообщений, уже находящихся в очереди. Хотя кейс очень востребованный. Реализуется он довольно простой архитектурой с использованием, например, Redis.
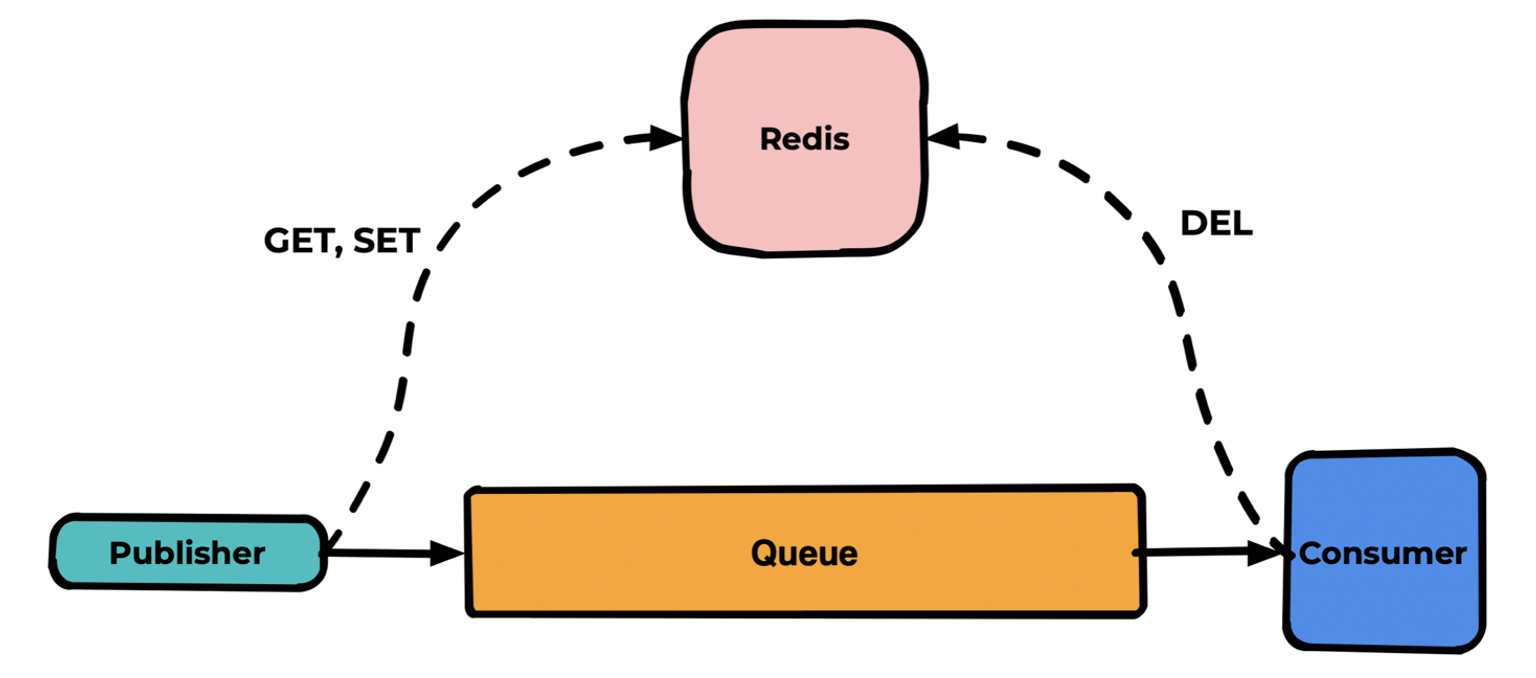
Паблишер перед паблишем в очередь проверяет в redis наличие уникального ключа для этого сообщения, если ключа нет — отправляет сообщение в очередь и создаёт ключ. Если ключ есть — отбрасывает сообщение.
Консьюмер, в свою очередь, после обработки сообщения удаляет этот ключ из redis. В результате в очереди одинаковых сообщений быть не может.
В самом деле есть сторонние плагины дедупликации, но они работают просто по TTL. Это подходит далеко не всегда. И даже когда подходит я бы рекомендовал redis для этой задачи.
Многоуровневая очередь повторных попыток
Очередь повторных попыток — довольно удобный инструмент для обеспечения повторных попыток обработки. Но он имеет один большой минус — сообщения будут крутится там бесконечно, если мы не обеспечим какой-то TTL для них встроенными механизмами консьюмера, что не всегда возможно и удобно.
Обычная очередь повторных попыток
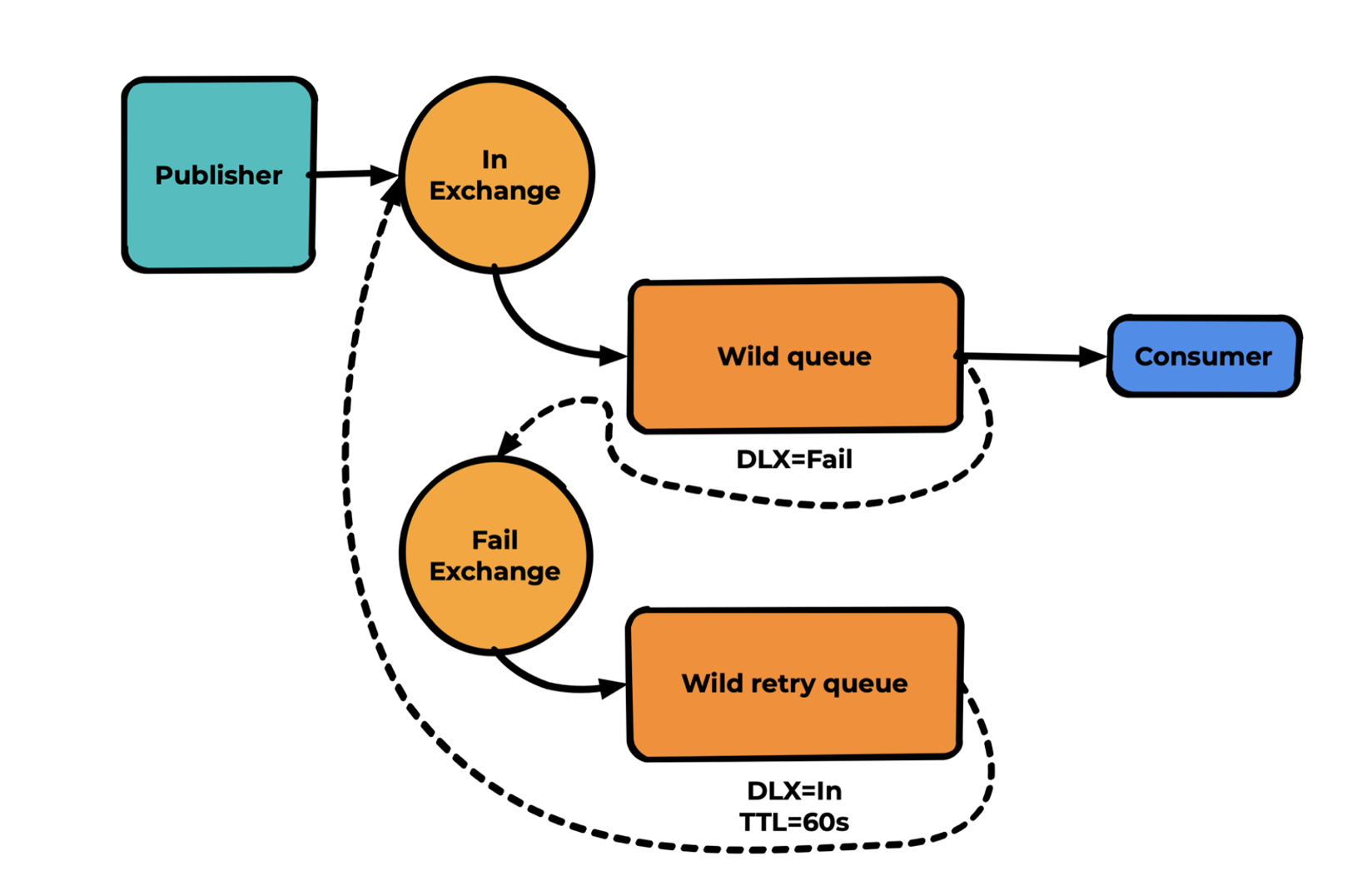
Значительно более удобная схема — это многоуровневая очередь повторных попыток.
Мы отделяем несколько попыток с разным временем отложенного повтора и в финале создаём отстойник, откуда сообщения уже не будут повторно обрабатываться — нужен только для отладки и диагностики. Н,у или в случае исправления ошибок в коде консьюмера можно вручную shovel’ом отправить эти сообщения снова в основную очередь для повторной обработки.

Многоуровневая очередь повторных попыток
Если кратко про принцип работы: мы используем возможность DLX — Dead Letter Routing Key, переопределяя его в каждой очереди кроме основной.
Подробнее:
Для основной очереди — DLX - Fail, Для очередей повторных попыток — DLX - In. Дополнительно в каждой очереди повторных попыток мы переопределяем RoutingKey, чтобы exchange Fail в следующий раз смаршрутизировал сообщение в следующую очередь.
Из exchange In мы создаём три биндинга в очередь — retry1, retry2, fail очередей повторов может быть и больше. Думаю, суть их настройки понятна.
Паблишер отправляет сообщения в exchange in с RoutingKey retry1. В случае reject от consumer сообщение уйдет по DLX в exchange fail, где смаршрутизируется по биндингу retry1 в очередь retry1. Там пролежит 10 секунд и по DLX изменит свой RoutingKey на retry2 и снова уйдет через DLX exchange in в очередь Queue. Но окажется он тут уже с другим RoutingKey — retry2. Поэтому при reject от consumer сообщение уже через exchange Fail будет смаршрутизировано в очередь Retry2.
Третий проход не требует пояснений — в результате сообщение уже попадет в очередь Fail. Его, конечно, также стоит лимитить или по длине, или по TTL — это уже зависит от ваших планов на сообщения. Возможно, вы вообще не хотите держать такой отстойник — можно вместо него добавить финальную очередь, которая тоже будет совершать повторные попытки. Для этого нужно просто перестать переопределять RoutingKey или устанавливать его равным RoutingKey биндинга в эту же очередь.
Выглядит сложно, но по факту настраивается довольно легко. Рекомендую сначала хотя бы на бумажке нарисовать все биндинги и DLX и только потом садиться настраивать.
Приоритеты сообщений
При декларировании очереди мы можем задать такой параметр — x-max-priority. Он говорит, сколько уровней приоритета будет у указанной очереди. Если заглянуть под капот этого функционала — это создание N отдельных очередей. Единственное отличие — консьюмер у этих сообщений может быть один. В первую очередь в консьюмер будут проталкиваться сообщения с более высоким TTL, и только в случае, если более приоритетных сообщений нет, будут проталкиваться менее приоритетные.

Для установки приоритета необходимо при отправке сообщения указывать параметр priority.

Еще раз хочу обратить ваше внимание: установка параметра x-max-priority в слишком большие значения не рекомендуется, так как это вызывает создание соответствующего количества очередей, из-за чего RabbitMQ будет нести накладные расходы.
Вообще лично я на практике не находил кейсов, где есть потребность в приоритете сообщений.