
Недавно я решил отправить свой проект, над которым работал в свободное время последние несколько лет, на конкурс в одну компанию. Я сел и стал думать, нет ли каких-то нюансов, которые я не учёл, и которые могут испортить впечатление и уменьшить шансы на успех. И первое, что мне пришло в голову — проект не работает под IE ниже 9 версии. То есть совсем, там стояла блокировка. После логина появлялось окошко с красивым предупреждением, что браузер не поддерживается, и пользователя опять перебрасывало на форму входа. Довольно изящно — но неприятно. Что, если у человека стоит Windows XP, а сторонних браузеров нет? Незадача.
И вот я решил потратить столько времени, сколько будет нужно, но при этом добиться стабильной безошибочной работы системы как минимум в IE 8. Я готов был убрать часть функций, если будет необходимо — но всё должно было выглядеть аккуратно и работать без сбоев. Предвкушая долгие и тяжёлые мучения (уже был несколько раз подобный опыт), я взялся за дело. Если вам интересно узнать, с какими сложностями я столкнулся, и какие изменения пришлось внести в разные компоненты — добро пожаловать под кат.
Я стал вспоминать, почему я так сделал — и вспомнил, что даже не стал пытаться исправить огрехи вёрстки после того, как увидел, что данные не приходят через XHR. Рассудив, что мессенджер без автообновления данных, где надо всё время жать F5 — это полный цирк, я и ввёл ту блокировку.
Однако после этого уже было 2-3 случая, когда я сталкивался с похожими симптомами, и успешно их устранял. А про этот проект — как-то забыл, что здесь проблема была та же. Это первое исправление и позволило устранить самую главную проблему, что, в свою очередь, открыло дорогу к дальнейшим улучшениям.
Ниже я приведу основные несовместимости, которые возможно придётся учесть, если вы решите обеспечить поддержку старых версий Internet Explorer. Итак, поехали!
IE не знает, что такое кодировка CP1251 (все версии)
Данная проблема — парадокс — присутствует до сих пор. Ей подвержены все версии IE, вплоть до 11-ой. Возможно, Microsoft не считает это багом, но при разработке это приходится учитывать — иначе браузер будет игнорировать все пришедшие через AJAX данные. Решений здесь два: либо добавить кодировку через .htaccess (если у вас Apache), либо добавлять её через
header() прямо в PHP коде. Второй вариант универсальнее (должен работать с любым веб-сервером), но более трудоёмкий, и явно засоряет код, поэтому я предпочитаю следующую строку в конфиге:AddDefaultCharset windows-1251
После этого заголовок ответа
Content-Type: text/html; charset=CP1251 изменится на Content-Type: text/html; charset=windows-1251, и всё заработает.Отсутствие поддержки некоторых псевдоклассов (IE8 и ниже)
Например, не работает селектор
nth-child(). Что создаёт большие проблемы, когда вёрстка и стили уже написаны. Адекватных решений, опять же, всего два — либо прописать нужным блокам (например, вторым в контейнере) особый класс во всех местах в HTML, либо написать одну JavaScript функцию, и в ней назначить нужные стили через style. Мне второй вариант показался более выигрышным, поскольку разметка не засоряется ненужными классами, меньше работы, проще удалить в случае чего — и главное, в этом случае можно этот код запускать только для IE нужных версий, обернув его в if(). Обратите внимание: в случае выбора первого варианта одними условными комментариями не обойтись, менять придётся саму разметку, добавляя лишний атрибут class там, где он в общем-то не нужен.Отсутствие поддержки background-size (IE8 и ниже)
Да, свойство
background-size является частью CSS3, поэтому его поддержки нет. Предсказуемо, но очень печально. Представим к примеру, что у нас есть маленькая иконка, которая почти нужного размера, но не совсем (например, она больше процентов на 20-50). При разработке мы могли сделать обычный div, назначить её фоном и задать background-size. В IE8 же мы получим её в полном, более крупном размере. Тут можно поменять вёрстку, сделав через img, и задав ему размеры. Но обычно дешевле сделать одну (или столько, сколько необходимо) копий картинки нужных размеров, и оставить разметку как есть.Отсутствие display: inline-block (IE7 и ниже)
Здесь следует заменить на
display: inline, он работает абсолютно так же (внешние отступы поддерживаются, и этого обычно достаточно). В особенно трудных случаях можно попробовать float: left (или float: right, если выравнивание нужно по правому краю, правда в этом случае порядок элементов изменится на противоположный, и вам придётся дописывать ещё и JS код).Баг со списками (IE7 и ниже)
Я часто использую список не по прямому назначению: например, для создания ряда горизонтальных ссылок, или пунктов выпадающего меню. Но на этот раз пришлось поменять разметку, ибо решения для данной проблемы я так и не нашёл. IE7 (и IE8 в режиме эмуляции) добавляет слева от всех пунктов отступ. При этом
padding у контейнера равен нулю, margin у элементов <li> — тоже, а фиксированное расстояние в 26 пикселей значится в инспекторе как offset (левее margin). При этом через CSS его убрать никак не получается (или я не нашёл как это сделать).UPD: andy128k подсказал решение проблемы: необходимо задать для элементов списка
list-style-position: outside, и отступ пропадёт.Сложности с подмешиванием собственных функций в прототип (IE8 и ниже)
В браузерах, вроде Chrome, Opera и Firefox можно добавлять нужные свойства в прототип элементов через объект HTMLElement. В IE 8 при попытке это сделать получим исключение, причём даже если просто написать if с этим именем — поэтому обязательно нужно использовать блок
try {}. Но аналогичную функцию там выполняет объект Element. А вот в IE7 нельзя сделать и этого. Можно конечно добавлять свойства в Object.prototype — но это не очень-то хорошая практика, на мой взгляд. Поэтому если обязательно нужна поддержка IE7, а подмешиваемых функций не очень много — проще отказаться от синтаксиса с точкой вовсе. И писать что-то вида addClass(obj, className) вместо obj.addClass(className).Отсутствие nextElementSibling и previousElementSibling (IE7 и ниже)
Да-да, этих свойств тоже нету. Совсем. Есть конечно коллекция children, по которой можно путешествовать, но вот в ряде мест, где надо получить следующий элемент, приходится использовать дурацкие циклы
while() в одну строку, перебирая nextSibling / previousSibling, пока не найдём элемент нужного класса, либо с nodeType равным единице. Тут следует заметить, что в IE соответствующих версий nextSibling и previousSibling как раз пропускают текстовые узлы. Только вот в других браузерах это не так, и кроссбраузерность сразу исчезнет (код перестанет работать везде кроме IE), если сделать простую замену.Отсутствие объекта JSON (IE7 и ниже)
Тут всё просто — пишем свой парсер/кодировщик (благо, это не так уж сложно). Можно использовать и
eval, особенно если источник данных — доверенный, например наш сервер. Но знающие люди не рекомендуют всё равно этого делать :)Неожиданные грабли с HTTPS (IE7 и ниже)
В моём проекте используется получение данных со стороннего ресурса через API по протоколу HTTPS. Можете представить моё удивление, когда на реальном IE7 на виртуальной машине я не получил тех данных через JSONP, которые прекрасно получал в IE8 в режиме эмуляции IE7. Уж не знаю, в чём там было дело, но похоже, что-то с набором поддерживаемых шифров — сервер просто не даёт установить соединение. Проверить это было легко — просто открыл в новой вкладке требуемый адрес и увидел ошибку SSL. И такая же ошибка была при открытии любой страницы того сайта. Что интересно — протоколы шифрования в настройках у IE7 и IE8 одни и те же: SSL 2.0 (не отмечен), SSL 3.0 и TLS 1.0. И длина ключа в окне «О программе» и там и там равна 128 бит. Но почему-то IE7 сервер отшивает. Если кто знает причину такого явления — пишите в комментарии.
Другое устройство selection
Если нам надо каким-то образом работать с выделением — не важно, выделение это просто на веб-странице, в
input или textarea — для IE нужен отдельный код. Не то, чтобы он был сильно сложнее в общем случае — однако в простых ситуациях (вроде «вставить текст в позицию курсора в текстовое поле») — подход и правда менее очевидный и требует более глубоких знаний.В интернете распространено куча вариантов кода для кроссбраузерного обрамления фрагмента текста тегом, или вставки текста в произвольную позицию (что по сути очень похоже). Мой вариант, который я в своё время откуда-то скопировал и толком не протестил (поскольку разработку я веду в Опере), не работал. Правильный вариант был найден на днях на одном известном форуме, авторство его коллективное. В общем я к нему отношения не имею, но приведу здесь его в сильно сокращённом и упрощённом виде (чтобы понятна была идея, и не было лишнего):
if (detectIE() < 9) {
window.sel = null
var f = function() { window.sel = document.selection.createRange().duplicate() }
document.getElementById('inputField').onselect = f
document.getElementById('inputField').onkeyup = f
document.getElementById('inputField').onclick = f
}
function tagSelectedText(obj, tag) {
if (document.selection) {
if (!window.sel) return
document.getElementById('inputField').focus()
var sel = window.sel
var len = sel.text.length
sel.text = '<' + tag + '>' + sel.text + '</' + tag + '>';
if (len == 0) sel.moveEnd('character', -(tag.length+3));
sel.select();
}
// ...код для других браузеров
}
Идея в том, что есть невидимый объект выделения (и часто не в единственном числе, это иногда кстати бывает видно в Опере, если что-то выделять мышью, перед этим в JS программно не сбросив как следует все Range). Но он пропадает, как только поле теряет фокус. Причём на onblur присваивать функцию его дублирования бесполезно: уже поздно. Поэтому onselect. onkeyup и onclick нужны для того, чтобы сохранять пустое выделение (нулевой длины) по мере набора текста или перемещения курсора по полю стрелками либо кликом мышки.
В момент нажатия на кнопку мы берём сохранённый объект, обновляем свойство
text реального объекта выделения, используя свойство сохранённого объекта. Если надо, двигаем курсор. Не забываем вызвать select() — это важно сделать, чтобы результат отобразился в браузере.Тормоза порой выявляют ошибки в логике
В одном месте в коде JavaScript (в месте, где создаётся интерфейс аудиоплеера) делался запрос на внешний сервер через JSONP. Функция-обработчик получала нужный плеер (тот, с которым работали в функции
createPlayer() в момент создания запроса) по его id, который вычислялся исходя из ответа на запрос, и прописывала ему атрибут с URL трека, вычисляемый из того же ответа. Везде, включая IE8, всё работало хорошо и так, как задумано. А в IE7 функция, вызываемая через JSONP, не могла получить объект-контейнер плеера по id.Оказалось, что проблема была в том, что в момент вызова
getElementByID() контейнер сообщения, в котором находился искомый контейнер плеера, ещё не был добавлен в нужное место методом appendChild(), который находился после вызова createMessage(), создающего сообщение. Но уже существовал, и id имел правильный. На самом деле элементы, созданные через createElement(), не становятся доступны мгновенно. Это нормально. И конечно же следует добавлять элемент в DOM, а потом уже к нему обращаться. Но обычно я сначала присваиваю все обработчики и наполняю элемент дочерними узлами, а только потом добавляю его. Поэтому здесь злую шутку сыграло то, что код функции-обработчика срабатывал в неизвестный момент времени, и в IE7 к этому моменту исполнение основного потока оказывалось ещё не завершено (либо DOM не актуализировался).Особенности работы с DOM тоже выявляют ошибки в логике
Здесь всё было в какой-то степени ещё интереснее. Библиотека xPlayer имеет возможность подключения и удаления «слушателей» (при её разработке в своё время специально было это сделано на случай если понадобится, вот оно и понадобилось). Эта возможность была использована, чтобы подключить плееры-контроллеры (те плееры, что отображаются в сообщениях) к мастер-плееру наверху страницы. Мастер-плеер позволяет скроллить переписку и даже переключаться между комнатами, при этом всё время имея доступ к управлению воспроизведением. При возвращении в комнату, где был запущен трек (или загрузке блока сообщений, где он был запущен) происходит «подхват» нужного контроллера при его инициализации. Код инициализации контроллера сравнивает специальный uid, формируемый из URL и названия трека, с uid у мастера, и по их совпадению и делает вывод, что этот контроллер «тот самый». При этом все контроллеры без исключения при создании имеют набор функций, обновляющих свой UI при разных событиях. И эти функции регистрируются как «слушатели» в мастере.
В IE8 вскрылась неожиданная ошибка — после перехода в другую комнату функция-слушатель продолжает выполняться, и падает при попытке определить
clientWidth элемента, который удалён из документа после очистки innerHTML зоны просмотра!С одной стороны — ссылка на элемент была передана в качестве контекста при регистрации функции, и сборщик мусора не должен уничтожать объект, даже несмотря на то, что он уже не является частью DOM. Но это в других браузерах — тут похоже объект как раз уничтожался, и свойство
clientWidth бралось уже от нулевого указателя. Другие браузеры не выдавали никаких ошибок в консоль (скорее всего там clientWidth равнялся 0, а объект существовал со всеми своими потомками вне DOM), и при возвращении в старую комнату всё работало отлично.Здесь же при возвращении шкала контроллера не «подхватывалась», а шкала мастер-плеера продолжала обновляться всё это время (функция обновления присваивается при старте воспроизведения через
setInterval(), из неё же запускаются все функции-слушатели из списка).Очевидно, что сама функция обновления работала, а вот функция-слушатель — нет. Ну и проблема вероятнее всего была в том, что новая функция-слушатель при возвращении в прежнюю комнату добавлялась в список (с привязкой к новому объекту), но до неё очередь не успевала дойти, поскольку при запуске старой, которая перед ней, код падал с ошибкой. А ошибка банальна донельзя — при смене комнаты список функций-слушателей очищать надо :)
К слову, это проблему и решило.
Безопасность превыше всего (IE8 и ниже)
Наверное, каждый, кто более-менее много работал с разработкой интерфейсов, знает простой приём, как стилизовать
input типа file. Достаточно сделать его скрытым, а на клик по произвольному элементу, который будет играть роль кнопки, повесить функцию-обработчик, внутри которой сделать вызовinput.click()
Но в IE8 и более младших версиях при попытке отправить форму с файлом, выбранным таким образом (например, через вызов
form.submit() повешенный на onchange инпута) мы получим ошибку:
Microsoft считает, что это небезопасная операция, поэтому даёт нам по рукам. Поэтому стилизовать файл-инпут привычным образом в Internet Explorer не получится. Кстати, даже если сделать его видимым через JS перед отправкой формы — ничего не изменится. Нужно, чтобы файл был выбран именно прямым кликом по инпуту. Поэтому единственный способ — сделать инпут прозрачным с помощью
filter: alpha(opacity=0), и подложить под него стилизованную кнопку. Тогда пользователь будет кликать по реальному (прозрачному) инпуту.А что насчёт IE6?
С IE6 всё плохо.

Я никогда толком не работал с этим браузером как разработчик — не довелось в силу возраста. Но читал где-то мельком, что там вообще другая блочная модель, и вообще нужна куча костылей. Пока в IE6 всё выглядит так же, как в IE7 при неуказанном DOCTYPE (т.н. quirks mode), или как в IE8 в режиме эмуляции «IE7: режим совместимости».
Но если у кого-то есть идеи, что надо дописать в стилях, чтобы ситуация хоть чуть-чуть исправилась — буду признателен.
Кроме того, не следует забывать, чтобы работа с событиями везде была организована кроссбраузерно (иначе код будет падать, и ничего хорошего не получится), чтобы скруглённые углы элементов там, где это жизненно необходимо, были выполнены картинками (или хотя бы имели картинки как альтернативный fallback). Кроме того, объекты, которые имеют эффект плавного появления и затухания через прозрачность, не будут иметь сглаживания шрифта (правда, этот баг можно обойти, присваивая фильтр до того, как
display установим в block, и убирая его вообще после завершения эффекта).Ну и даже после всего этого, серьёзное веб-приложение будет работать довольно медленно (подтормаживает даже обычная кастомная прокрутка, причём при не очень больших объёмах контента). Но по крайней мере при выполнении всех этих условий получившийся результат можно будет назвать graceful degradation. Наверное.
Комментарии (92)

Metaller
24.11.2015 13:47+1Жду картинку по троллейбус из буханки.
PS inline-block для IE 6-7 существует:
*display: inline; *zoom: 1;
popov654
24.11.2015 16:03-3Для IE7
zoom: 1вроде не нужен. А для IE6 — на скриншоте видно, что происходит. При том, что вёрстка самая обычная (центрированный контейнер с заданным max-width, внутри него разбивка на две колонки, и левой ещё на две секции — всё абсолютным позиционированием, у контейнераposition: relative).Metaller
24.11.2015 16:06+4Для IE7 zoom: 1 нужен, иначе это будет обычный display: inline. А у IE6 столько болезней, что дело может быть не только в этом.
IE6 не поддерживает max-width, в его случае нужны танцы с бубном и expressions.popov654
24.11.2015 18:09Позвольте не согласиться всё-таки. Обычный, да не совсем. Смотрим официальную спецификацию (кстати, Opera 11.64 ведёт себя согласно ей при задании
display: inline):
Особенности блочно-строчных элементов:
- им можно задавать размеры, рамки и отступы, как и блочным элементам;
- их ширина по умолчанию зависит от содержания, а не растягивается на всю ширину контейнера;
- они не порождают принудительных переносов строк, поэтому могут располагаться на одной строке, пока помещаются в родительский контейнер;
- элементы в одной строке выравниваются вертикально подобно строчным элементам.
Это с HTML Academy.
Теперь смотрите на скрины)
Показать
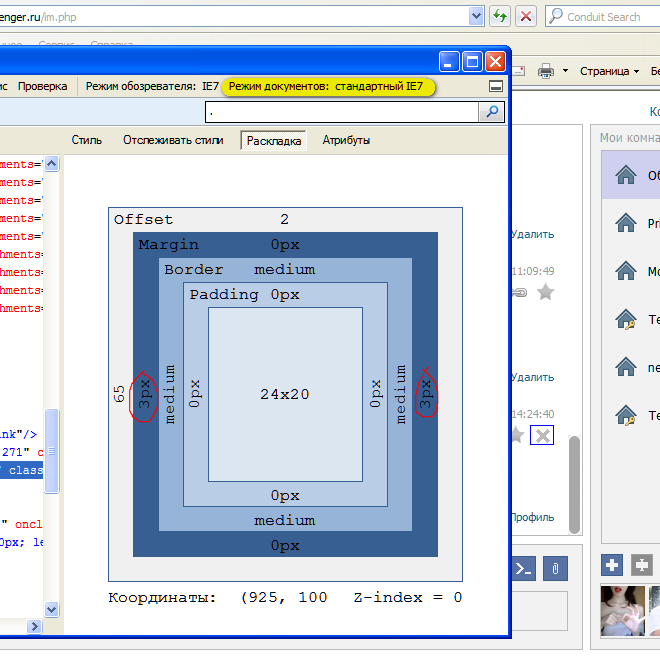
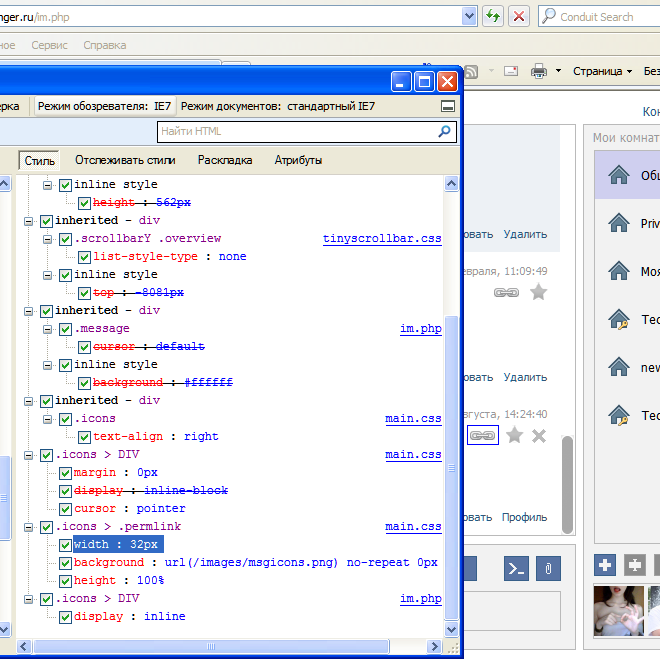


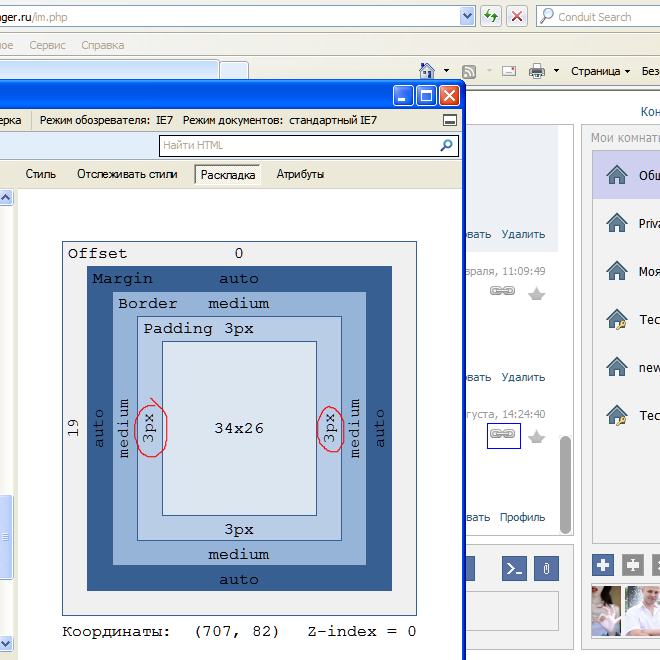
Metaller
24.11.2015 18:16+5Почитайте про hasLayout — он включается в том числе и при заданном width (как в вашем случае) и тогда zoom уже не нужен. Код выше (display: inline; zoom: 1;) это минимально необходимый код для inline-block на старых IE. Вы же утверждаете что обычный display: inline в IE ведет себя как dispaly: inline-block, а это не так.
popov654
24.11.2015 23:10Я так подумал по косвенным признакам) Спасибо за разъяснения. Но зачем zoom, если есть width? Я так понял, в моём случае всё-таки можно без него?

MTonly
24.11.2015 23:28hasLayout можно включить разными способами, и каждый работает чуть по-своему. По моему опыту, самый «пуленепробиваемый» —
height: 1px(или любая другая явно заданная ширина или высота в пикселах) (именноpx, т.?к.%в определённых ситуациях к желаемому результату не приводил) для IE6 иmin-height: 0для IE7.
Если hasLayout уже включён, например, с помощью ширины, тоzoomдля этой цели, разумеется, уже не нужен. Кстати, сzoomв контексте включения hasLayout были определённые проблемы, поэтому я его для этой цели не использовал.popov654
25.11.2015 19:34За IE6 не скажу, но в IE7 ширина в процентах работает (без указания высоты), при этом
inlineработает какinline-block. Пример (блоки с кнопками, по 2 штуки в двух контейнерах сdisplay: block)MTonly
25.11.2015 21:39На первый взгляд, процентные значения размеров элемента (я, кстати, говорил о фиктивных значениях, близких к нулю и используемых только для включения hasLayout) тоже включают hasLayout, но потом, по мере усложнения вёрстки, вид или поведение страницы могли (хотя и не обязательно) неожиданно стать неправильными.

Nadoedalo
24.11.2015 17:34+2Эм, после кодировки CP1251 перестал читать. Аффтар, ты в каком веке живёшь? UTF-8 жешь.
popov654
24.11.2015 18:12-6Если проект нацелен исключительно на Россию — зачем гонять для русского текста в два раза больше байтов? Траффик жешь :)
MTonly
24.11.2015 19:52+7Чтобы не иметь проблем со спецсимволами и их вставкой с помощью подстановок (entities)? ;-)
Про Gzip тоже забывать не стОит.popov654
24.11.2015 20:00-6Приведите пожалуйста пример спецсимволов, которые люди могут использовать в мессенджере общего назначения, и которых нет в однобайтовой кодировке)
Gzip и так работает, на самом деле. Просто не вижу смысла в юникоде, когда в сообщениях только русский и латиница. И кстати — ВК для российских пользователей использует CP1251, насколько я знаю.MTonly
24.11.2015 20:18+6Приведите пожалуйста пример спецсимволов, которые люди могут использовать в мессенджере общего назначения, и которых нет в однобайтовой кодировке)
Не уверен, что вы подразумеваете под мессенджером общего назначения, а на сайтах вполне могут использоваться, например, такие символы:
> < v ^ ? ? ? ? ?
Просто не вижу смысла в юникоде, когда в сообщениях только русский и латиница. И кстати — ВК для российских пользователей использует CP1251, насколько я знаю.
Подобные доводы, равно как и упоминание CP1251 вместо Windows-1251 пробуждает во мне впечатляющие воспоминания об одном человеке, который писал движок сайта на Delphi. :-)popov654
24.11.2015 23:06-4Не думаю, что в мессенджере кто-то будет часто использовать квадрат или куб)
Тем более эти стрелки, которые вообще непонятно для чего. Кстати, квадрат у меня прошёл… Странно. Кодировка передачи до PHP — windows-1251, кодировка соединения с БД — тоже. Не очень экзотические символы попались похоже =)
UPD: оказывается, перед отправкой символы преобразуются к виду &#nnn; (? для ? например). Видимо, заслуга браузера…MTonly
24.11.2015 23:20Да, современные браузеры при отправке форм вынужденно экранируют символы, отсутствующие в наборе символов используемой на странице кодировки. Эти коды — и есть подстановки (entities), с которыми в общем случае лучше не связываться без реальной необходимости. А реальная необходимость одна — экранирование служебных символов HTML (
<,>,&,") в текстовых узлах и значениях атрибутов.
И даже в «мессенджере» пользователь может вставить фрагмент текста, откуда-то его скопировав. ;-)popov654
24.11.2015 23:27Чем плохи подстановки? Тем, что символов 6 вместо одного?) А если это происходит раз в 100-200 сообщений? Вроде как, практические соображения перевешивают.
MTonly
24.11.2015 23:35+1Тем, что один реальный символ представлен более чем одним символом на уровне кода. Если есть универсальная кодировка, где все символы, кроме 4-х спецсимволов HTML, можно хранить непосредственно (UTF-8), нет смысла использовать другую кодировку. Экономия трафика путём использования ограниченной 8-битной кодировки вместо универсальной UTF-8 — это, пожалуй, экономия на спичках.
popov654
25.11.2015 01:13Согласен, в некоторых приложениях это может быть критично. К счастью, у меня задача намного проще, там нет особой работы с разбиением текста и обработкой фрагментов. Более того — сама идеология системы End-to-End шифрования подразумевает, что сервер ничего «не знает» и хранящихся текстах (даже в тех переписках, где они не зашифрованы). Ему должно быть пофиг, сколькими символами там закодировался редкий символ. Главное — чтобы обратное декодирование прошло без проблем и вернуло тот же результат.
Насчёт экранирования тех символов, что вы написали — ну можно хранить так, а замену делать на этапе вывода, например. Мне кажется, такой подход гибче, хотя и потребует лишнего процессорного времени. Более того, современные браузеры вообще прощают такие не экранированные символы в текстовых узлах (хотя это конечно не означает, что не нужно делать по правилам).MTonly
25.11.2015 01:31можно хранить так, а замену делать на этапе вывода, например. Мне кажется, такой подход гибче, хотя и потребует лишнего процессорного времени.
Можно, просто в общем случае нецелесообразно. Хотя, конечно, решение за разработчиком конкретного сайта или приложения.
современные браузеры вообще прощают такие не экранированные символы в текстовых узлах
Только когда очевидно, что спецсимвол использован как текстовый (например, если непосредственно за открывающей угловой скобкой следует пробел). Но код при этом не перестаёт быть синтаксически некорректным («невалидным»).popov654
25.11.2015 19:38Да, точно — валидацию разметка после такого не проходила, поправлял. Вы правы.
Про целесообразность — ну так экономия места в базе. Пока база маленькая, это не принципиально, но вот когда разрастётся… Впрочем, поскольку этих символов мало — можно не заморачиваться с этим. Но всё-таки этих символов больше, мне думается, чем тех, для которых придётся использовать entities. Так что мой подход тоже имеет право на жизнь

justaguest
25.11.2015 10:46Нет, ну конкретный символ из только что перечисленных может и нечасто нужен. Вот только это просто пример, а символов тысячи, и любым из них «российский пользователь» может попытаться воспользоваться.
Вы не представляете, как раздражает, когда на каком-нибудь кривом сайте во время общения по привычке вводишь специальный символ, а тот либо шлет какую-то кашу (в Quora есть такая проблема), либо выдает что-нибудь вроде «Ошибка записи в базу данных» (такая проблема на сайте МТИ).
justaguest
25.11.2015 10:57И да, к слову, даже если говорить только о перечисленных символах — стрелка «>» нередко бывает нужна, когда кому-нибудь по чату объясняешь последовательность действий, например в какие меню зайти в программе, и куда нажать.

faiwer
24.11.2015 21:36+7Просто не вижу смысла в юникоде, когда в сообщениях только русский и латиница.
Правильнее исходить из обратных побуждений. Нужно искать смысл НЕ использовать unicode. И в 21 веке такая причина должна быть веской.
И кстати — ВК для российских пользователей использует CP1251, насколько я знаю.
А хабрахабр до сих пор не умеет HTTPS. Впрочем, если мне не изменяет память, VK тоже далеко не сразу ему научился.popov654
24.11.2015 22:52-1Блин, а ведь и правда не умеет. А мне казалось, что умел(
Зачем тогда они HabraStorage на HTTPS перевели, да ещё так, что в старых Операх картинки не грузятся? Вот где загадка…
Впрочем, если мне не изменяет память, VK тоже далеко не сразу ему научился
Честно говоря, в HTTPS не вижу особого смысла. Если для ВК это ещё можно обосновать логинами через бесплатный Wi-Fi, то вот на Хабр заходят как правило из дома (ну по крайней мере статьи пишут точно оттуда). А уж шифровать картинки статей… Мда. Даже у Википедии больше причин работать по SSL, на мой взгляд.
Но главное — насчёт «не сразу» Вы не правы. ВК был создан в 2006 году, тогда UTF-8 очень даже был. И раньше был. Это их сознательный выбор, а не «не умеют». Я думаю, экономят траффик (даже с учётом сжатия будет меньше, тем более в ВК очень много текстов), плюс функции работы с обычными строками в PHP должны работать намного быстрее, чем те, что с префиксом mb_.
На самом деле, даже между разными серверами гонять меньше данных приходится — если соединение с SQL сервером в однобайтовой кодировке делать. Не знаю, как делает вк, но что у них сервера баз данных на отдельных кластерах, это без сомнений.MTonly
24.11.2015 23:49+1Кстати, VK вы, вероятно, переоцениваете. Например, они уже три месяца (после сообщения от автора этих строк) не могут «исправить» тривиальную ошибку типа «тёплое с мягким», из-за которой пользователя современного браузера перенаправляют на страницу «Вы используете устаревший браузер» лишь на основании отключённого JavaScript:
<noscript><meta http-equiv="refresh" content="0; URL=/badbrowser.php"></noscript>
Дополнительно впечатляет, что баг-трекер у них тоже есть, но там, судя по всему, почему-то доступен только поиск без возможности добавления новых баг-репортов, поэтому приходится действовать приватно через раздел «Помощь».popov654
25.11.2015 00:53Ну баг-трекер у них всегда был чем-то фиктивным, сколько я его помню, если мы с вами говорим об одном. А вот про JS вы зря. Это нормально, ВК без JS не работает, потому что не может работать — это не какой-то там мессенджер, а целая соцсеть. Так всегда было, насколько я помню — минимум года 4 или больше. То есть стоит отключить JS — и тебя кидает на эту страничку :)
MTonly
25.11.2015 01:08Проблема не в том, что без JS сайт не работает, а в ложном предположении, что отключённый JS говорит об устаревшем браузере (иначе говоря, божий дар с яичницей):
1. пользователь вводится в заблуждение не соответствующим действительности сообщением об устаревшем браузере, хотя браузер у него самый свежий;
2. вместо вывода уведомления непосредственно на запрошенной странице происходит принудительное перенаправление на другую страницу без возможности вернуться назад. Поэтому перейдя на страницу, например, с помощью браузерной закладки, не имеешь возможности, временно включив JS, просто обновить страницу — приходится снова искать страницу в закладках.
Т.?е. имеем не только ошибочную увязку не связанных вещей (отлючённый JS и устаревший браузер), но и технически безграмотное решение, снижающее удобство пользователя, а также нежелание со стороны их веб-разработчиков пошевелиться и элементарным образом решить этот тривиальнейший вопрос. Какой там UTF-8, что вы. ;-)popov654
25.11.2015 23:33Да, и правда фигово сделано.
Насчёт UTF-8 — так он был. Помните, статусы задом-наперёд с помощью специальных символов? От него намеренно отказались — и я думаю, на то были причины. Мне кажется, вы плохо знаете вк))
Кстати — как вам вот такое? Это всё на тему издержек.
А ещё тут писали про GZIP — так вот всё равно размер словаря будет больше. Я знаю, что там не просто дерево Хаффмана строится, а всё гораздо сложнее при ZIP сжатии, и используется несколько техник — но всё равно словарь вырастет. Примерно вдвое
faiwer
25.11.2015 07:59+2У вас всё так органично получается. Windows XP, no-HTTPS, no-Unicode + win1251, экономия на спичках (избегание mb_), Opera 12-. Пожалуй в этот ряд ещё отлично впишутся FTP и phpMyAdmin. Перечислил бы ещё пару пунктов, но адепты этих инструментов съедят с потрохами :D
Настоящая прогулка с динозаврами. Каноническая :)
Zenitchik
25.11.2015 16:01FTP и phpMyAdmin
С этими динозаврами порой приходится гулять не от хорошей жизни…
popov654
25.11.2015 19:46Ну в целом ваш посыл уловил, спорить не буду, всё так)
Вот только про XP зря вы — лёгкая и удобная ОС, без лишнего, и с чётким нормальным рендерингом шрифтов. Я кстати из-за бледного вывода шрифтов даже новым Chrome пользоваться нормально не могу.
no-HTTPS не потому, что я считаю, что так нужно (мессенджер этот как раз для безопасности общения сделан), а потому, что проект пока «не взлетел», прибыли не приносит, а сертификат хороший — стоит денег.
А про phpMyAdmin — вот тут я правда удивлён. Вы таки знаете более удобные аналоги?) Я думал, это стандарт де-факто. Причём, он не только с MySQL работает, а с многими СУБД. Ну и в любом случае, у меня к нему претензий нет особых.
Если интересно, почему Опера не новой версии — могу объяснить) Не 15+, потому что это уже не Опера в строгом смысле. И куча функций утеряно, и дизайн совсем не тот, со шрифтами те же грабли. А почему не 12.х — потому что тормозная и глючная до безобразия. Глюков тележку можно наперечислять в ней, если вспомнить =)
FSA
24.11.2015 21:50+3Это называется создать себе проблему, а потом её героически решать. До сих пор встречаюсь с проблемами кодировок… на Windows. В любой *nix системе уже давно забили на все альтернативные кодировки и повсеместно используют UTF-8. Я раньше такое даже на FreeBSD практиковал, хотя там в консоли, вроде, до сих пор проблемы (буду рад, что ошибаюсь, давно в консоли голой не был).
popov654
24.11.2015 22:57-2А не поделитесь, какие именно проблемы? У меня последние проблемы закончились ещё в середине нулевых, когда пересел на нормальный браузер (который делал автодетект без ошибок). Даже ещё раньше — уже IE7 почти не ошибался при определении. А при работе локально — так вообще никаких проблем, в Windows одна кодировка всего, там не может быть никаких вариантов. То есть есть ещё две двухбайтовых и UTF-8, но по дефолту всё в ANSI.
Единственное, когда плохо — это когда на Mac OS X пакуют файлы макета в архив (обычно дизайнеры), потом пересылают мне… А там все имена битые. Именно из-за того, что кодировка на Маке другая, похоже.FSA
24.11.2015 23:59Да бывает на работе обращаются с разными хитрыми файлами. Открываешь стандартными средствами, копируешь текст, а получаешь кракоряблики или просто знаки вопроса вместо русских букв. И ещё, такая же беда с файлами из 1C, вроде.
khim
25.11.2015 00:13+3А не поделитесь, какие именно проблемы?
Пресловутый Bush hid the facts в разнообразных вариациях. Ниже вы приводите разнообразные её вариации, приговаривая при этом «да всё ж работает… кроме этого, вот этого и ещё того».
Во всех системах, кроме Windows про эти проблемы все уже давно забыли: UTF-8 везде — и не нужно никаких автоопределений.popov654
25.11.2015 01:03because Notepad prepends a byte order mark as a non-standard UTF-8 flag
Ну вот, то есть для Windows маркером кодировки является BOM (который так все ругают постоянно), а если его нет — она пытается анализировать содержимое эвристически.
Протестил кстати примеры из статьи, работают =) У меня как раз WinXP SP3.
Но всё равно не понимаю, при чём тут веб. Если проект не планирует международного развития, хранит базу в любой кодировке, но движок интерпретирует её всегда как известную однобайтовую кодировку (и никуда не конвертирует) — такого казуса не произойдёт. У меня всё ещё лучше — данные сохраняются в UTF-8 (на уровне СУБД), то есть в базе может быть любой контент, на любом языке. И в тот момент, когда проекту понадобится перейти на UTF-8 — это будет сделано буквально в две строки в заголовочном файле. И никаких кракозябр, и ничего конвертировать не нужно.MTonly
25.11.2015 01:33+1данные сохраняются в UTF-8 (на уровне СУБД)
Это правильно. Хотя тогда тем более нет смысла заниматься перекодировкой туда-сюда, а лучше просто использовать UTF-8 везде. Унификация, единообразие, предсказуемость.popov654
25.11.2015 19:51Не соглашусь всё-таки. Понимаете, чтобы было везде — надо файлы тоже в UTF-8 хранить. Хотя бы шаблоны (а у меня местами в одном файле код и контент, то есть по сути все PHP скрипты надо перекодировать в UTF-8).
А теперь внимание — вы не знали, что ISP Manager имеет серьёзные баги при работе с файлами в UTF-8, содержащими русский текст? Сейчас не уверен, может уже и исправили, а вот как минимум весной-летом 2013-ого такой файл в панели было не открыть на редактирование (у меня другой проект в UTF-8 целиком). А редактировать каждый раз локально, а потом заливать кнопкой «Загрузить файл» (а правки я делаю по 3-4 раза в минуту) — увольте, я не мазохист.MTonly
25.11.2015 21:42вы не знали, что ISP Manager
Не просто не знал, но и никогда не пользовался ISP Manager. :-) С другой стороны, вполне могу понять вынужденное ограничение на уровне используемой платформы. Приходилось иметь дело с «движком», поддерживавшим только Windows-1251.popov654
25.11.2015 23:36А с cPanel работали?) Вот интересно, вы правда не разрабатывали никакой сайт для обычного хостинга? Даже в молодости?)
Мне казалось, почти каждый через это прошёл из здесь присутствующих. Естественно, в более крупных проектах уже правила игры другие. Но даже там часто покупают недешёвую лицензию — и таки да, ставят ISP Manager. Поскольку он и правда удобен и много чего может.MTonly
25.11.2015 23:41Насколько я понимаю, продукты типа ISP Manager и cPanel предназначены для хостинг-провайдеров и веб-разработчику не нужны. А для индивидуальных сайтов используется админ-интерфейс движка — либо универсального, либо созданного под нужды конкретного сайта.
FSA
25.11.2015 07:01Кстати, а у вас не было проблем c отображением отдельных букв кириллицы? Обычно вылезает проблема если пользователи сами могут сообщения оставлять на сайте.
Просто вспомнился один форум несколько лет назад где я был постоянным посетителем. Админ того форума никак не мог эту проблему исправить.
Кстати, тут нашёл свои слова возмущения от 1 февраля 2007 года. Неожиданно обнаружил, что свой личный сайт до сих пор в cp1251 :) Тут же переделал всё в UTF-8.popov654
25.11.2015 20:05Нет, никогда не было) По идее, такого вообще никогда не должно быть. Разве что, прогон через iconv() иногда даёт баги (но обычно не из UTF-8 а из более редких кодировок вроде UTF-16, сталкивался с подобным, когда парсил ID3-тэги в MP3 файлах самописной функцией).
Оффтопикiconv() вообще зло. в одном проекте было нужно парсить каналы на YouTube, и сначала это было реализовано не используя API (потом перешли на него, правда). Так вот iconv() плох тем, что когда он встречает в UTF-8 некоторые экзотические составные символы — он не выбрасывает их, а делает аварийный выход, и вся часть строки после проблемного символа — отбрасывается. Это доставляло массу проблем: например, «плохой» символ мог попасться в названии или описании канала — но из-за его присутствия мы не могли получить данные, расположенные дальше.
Точнее, могли, но для этого нужно было предварительно разбить весь HTML код на фрагменты. Задача реальная, но трудоёмкая, плюс это делало нас сильно зависимыми от разметки YouTube — в любой момент она могла поменяться, и разбиение стало бы работать неправильно.
matiouchkine
25.11.2015 10:13+6Вы, наве?рное, не пове?рите, но да?же кири?ллица иногда? не помеща?ется в оди?н байт.

aulandsdalen
25.11.2015 14:12+1> У меня как раз WinXP SP3.
Яснопонятно, откуда у вас такое отторжение юникода и прочего. Это ж слишком новое все, непроверенное и от лукавого!
А на сервере у вас, дайте угадаю, Server 2003, MSSQL и Apache 1.3?popov654
25.11.2015 20:09Это обычный недорогой хостинг, там Apache 2.x и CloudLinux. На домашнем сервере у меня Apache 2.0 стоял ещё в 2009-ом году, так что тут тоже не угадали (правда, и сейчас стоит он же, поскольку сервер этот мне особо не нужен, крутится там домашняя страничка, работает — и ладно). =)
И — стыд и срам — там стоит WinXP SP2 (SP3 уже не влазит на встроенный накопитель), причём изначально — она была Home Edition, то есть там даже управления политиками нет. Зато лицензионная =)
Серверной Windows у меня никогда не было, не качать же её для такой ерунды. Кроме того — нетбук её не факт, что потянет.

splatt
25.11.2015 06:28+5Я не знаю, какой у вас опыт в веб-разработке, и какой у вас сайт — тоже не знаю, но РАДИ ВСЕГО СВЯТОГО, используйте UTF. Причин вам накидали уже миллион, но самая главная — вы без серьезного на то повода ограничиваете как себя, так и ваших пользователей, ограничиваете преусловутыми 255 символами, половина из которых — английские и технические символы. Это все равно, что прыгать на одной ноге, вместо того, что бы бежать на двух, аргументируя «ну так одна нога меньше места занимает».
Не существует никакой необходимости не использовать юникод. Как вам уже написали, серьезной разницы по траффику нет — gzip сжатие поможет в любом случае). Вы считаете, что приложение русскоязычное, а что если завтра оно выстрелит и вам срочно нужно будет сделать мультиязычность?
А что, если ваши «исключительно русскоязычные» пользователи захотят написать/скопировать текст на эстонском, туркменском, китайском? Что если они скопируют спец-символы из блокнота? Что если они захотят написать иностранное имя, оригинальное название фильма, или название анимe на японском?
А что если вы захотите подключить внешний виджет, сграбить данные с API, подключить внешнюю базу которая в UTF? Парам-пам-пам — вам прийдется лепить костыли и подключать конвертацию. Или не вам, а разработчику, который за вас будет сайт доделывать/поддерживать (а теперь представьте, сколько проклятий в ваш адрес уйдет).
Я не знаю, сколько еще привести причин использовать UTF.
Тоже самое с HTTPS. Единственная причина не использовать его — это отсутствие денег на сертификат (и то, эта проблема уже решаема и скорее всего ее не будет в будущем).
HTTPs — это не только защита для «логинов через бесплатный Wi-Fi», как вы говорите. Это защита данных впринципе. Даже если на вашем сайте нету сессии (в чем я сомневаюсь), если через ваш сайт люди будут отправлять хоть какую-то информацию, ее имеет смысл шифровать.
Я понимаю, что домохозяйки этого понимать не могут, но уж вы-то как разработчик обязаны осознавать, что большинство людей не «фильтруют», что они пишут в интернете. Телефоны, номера кредитных карт… если ваше приложение — веб-мессенжер, то тут все еще хуже.
Не вижу смысла приводить миллион причин, т.к. в гугле есть миллион статей на эту тему. Просто почитайте.popov654
25.11.2015 20:25Да нет у меня неприятия UTF-8, как кто-то написал выше. Мне, очевидно, приписывают то, чего я нигде не писал. Просто в некоторых случаях он, на мой взгляд, избыточен (это моя личная позиция, и она может казаться вам неверной, это нормально).
Давайте по пунктам:
вы без серьезного на то повода ограничиваете как себя, так и ваших пользователей, ограничиваете преусловутыми 255 символами, половина из которых — английские и технические символы
Ну да, и что? В 90% случаев русскоговорящему пользователю достаточно русского и английского алфавита, цифр, знаков препинания и некоторых спецсимволов. То есть всех тех символов, которые есть на клавиатуре.
Вы считаете, что приложение русскоязычное, а что если завтра оно выстрелит и вам срочно нужно будет сделать мультиязычность
Будет надо — сделаем. Я или кто-то другой)
А что, если ваши «исключительно русскоязычные» пользователи захотят написать/скопировать текст на эстонском, туркменском, китайском? Что если они скопируют спец-символы из блокнота? Что если они захотят написать иностранное имя, оригинальное название фильма, или название анимe на японском?
Да, всё так, это как раз и есть те оставшиеся 10 процентов. Но в этом случае браузер закодирует всё это в entites, и побиться ничего не должно.
А что если вы захотите подключить внешний виджет, сграбить данные с API, подключить внешнюю базу которая в UTF? Парам-пам-пам — вам придется лепить костыли и подключать конвертацию.
Если этот виджет будет настолько важен (обычно виджеты — это что-то второстепенное), то перейдём конечно. Но я не считаю правильным из-за какого-то виджета, который выдаёт символы в UTF-8, менять кодировку целого сайта. Если там всего 1-3 таких символа, которые нельзя сконвертировать в текущую кодировку — проще написать костыль, который подменит их перед конвертацией.
HTTPs — это не только защита для «логинов через бесплатный Wi-Fi», как вы говорите. Это защита данных впринципе.
Защита при передаче по каналу связи, не более. Обычный проводной канал имеет меньше шансов быть прослушанным (да, про СОРМ я знаю, но это особый случай и особые полномочия). Главное же — HTTPS не поможет обезопасить данные от владельцев/админов сервера.
Я понимаю, что домохозяйки этого понимать не могут, но уж вы-то как разработчик обязаны осознавать, что большинство людей не «фильтруют», что они пишут в интернете. Телефоны, номера кредитных карт… если ваше приложение — веб-мессенжер, то тут все еще хуже.
И поэтому — тадам! — проект имеет свой алгоритм шифрования, который можно активировать при создании комнаты (работает независимо от того, есть ли HTTPS). Причём он шифрует данные насовсем, так что их не прочитает в том числе и администратор сервера. Общий чат не шифруется, конечно — смысла нет. Но если человек напишет в общий чат номер своей кредитки или полный список паролей — ну это, извините, диагноз, с этим ничего не поделать =)MTonly
25.11.2015 21:48в этом случае браузер закодирует всё это в entites, и побиться ничего не должно.
Зато, кстати, entities попадут в базу данных (и останутся там, скорее всего, навсегда), даже если сама она в UTF-8, если, конечно, перед записью в БД их не раскодировать (что в общем случае маловероятно).popov654
25.11.2015 23:42Ну да, а что поделать. Но ведь благодаря этому на выводе пользователь не увидит квадратики — я вот сильно сомневаюсь, что в обратную сторону браузер тоже заменит. Точнее, уверен, что нет, если данные приходят «сразу». Если через XHR — не знаю, надо смотреть.
При «переезде» на UTF-8 можно написать небольшую функцию, которая сделает замену. Это пишется в несколько строк — если, конечно, подготовить заранее базу этих самых кодов замены… Они кстати случайно не равны Unicode кодам?
popov654
25.11.2015 23:51Да, проверил. Вручную поправил в базе сообщение. Если бы не заменялось — был бы знак вопроса вместо символа. Что в принципе логично. Причём не важно, каким образом этот символ придёт, через XHR или нет — он приходит из СУБД уже в однобайтовой кодировке, и на этом этапе с ним ничего не сделать.
MTonly
24.11.2015 20:09+2либо прописать нужным блокам (например, вторым в контейнере) особый класс во всех местах в HTML, либо написать одну JavaScript функцию, и в ней назначить нужные стили через style.
Можно ещё добавлять классы средствами JS.
IE7 (и IE8 в режиме эмуляции) добавляет слева от всех пунктов отступ
Такого бага уже не припомню (давно IE9+, а задолго до этого — IE8+), но включение так называемого hasLayout с помощьюmin-height: 0для IE7 иheight: 1pxдля IE6 решало большинство абсурдных проблем, свойственных IE 6/7. У списков была другая проблема — увеличенный относительно номинальногоline-heightдаже приlist-style: noneдля списка, обходилась с помощьюvertical-align: topдляLI.
А что насчёт IE6?
IE6 (0,05%) уже давно нет. Как и IE7 (0,2%) и, в общем-то, IE8 (0,6%). Для них достаточно использовать подход с унифицированной упрощённой таблицей стилей, основанной на семантике.
SelenIT2
25.11.2015 09:45Справедливости ради, как раз списки (правда, нумерованные) — редкий пример, где hasLayoyt не только убирал проблемы, но и создавал (сбивал нумерацию:).
MTonly
25.11.2015 20:08Для тех списков, где нужна была нумерация, hasLayout, соответственно, намеренно оставлялся выключенным. ;-)

andy128k
24.11.2015 21:49IE7 (и IE8 в режиме эмуляции) добавляет слева от всех пунктов отступ.
это лечилось с помощью list-style-position: outside;
стилизовать input типа file
Его не нужно скрывать. Поместите его в div с position: relative и oveflow: hidden, сделайте position: absolute, растяните по размеру контейнера и сделайте прозрачным (filter: alpha(opacity=0)).
После этого стилизуйте div как вам надо.popov654
24.11.2015 23:25Про input выше уже ответили. Со списком — спасибо, работает. Обновлю текст публикации)

leMar
24.11.2015 22:46+2Ностальгии коммент :)
Здесь должно быть полно старичков, для которых подобные танцы были простой рутиной.
Очень многое решалось zoom:1; и position:relative; Ну и знать всякую «магию». Например IE6 при float:left; margin-left:10px; удваивал значение margin. То есть он считал margin-left:20px; Настоящая боль это скругленные уголки и прозрачность )leMar
24.11.2015 22:50Нужна помощь по этим динозварам (только JS я тогда не знал), пишите в личку. Не проподать же знаниям )
Nadoedalo
25.11.2015 00:45ну, скруглённые углы довольно успешно решаются тупо большим количеством разметки… Как вспомню этот код — брррр, ужас.
Потому во всех текущих проектах просто тупо забил на поддержку любых устаревших браузеров, а IE начинается с 9. Как только наберёт популярность Win 10 и EDGE — так сразу нафиг все устаревшие браузеры.
Пора переходить на современный JS… Как только пойму необходимость =)
PS смотрю код на «хардкорных» js-прогеров, удивляюсь обилию костылей и полифиллов. Это было необходимо 10 лет назад, сейчас — уже нет. Старый веб должен погибнуть вместе с поддержкой от программистов. Иначе так и будем из десятилетия в десятилетие таскать весь этот мусор.popov654
25.11.2015 01:06Как я вас понимаю) А с меня вот начальник спрашивает, почему я отключил доступ на сайт для IE8 и ниже (очень сильно ехала вёрстка). Мир был бы намного лучше, если бы IE9 выпустили под XP и на восьмёрку можно было забить.
MTonly
25.11.2015 01:27Начальнику полезно озвучить, какова текущая доля IE8 в России. :-)
leMar
25.11.2015 09:00+1Начальник может быть и не неправ. Если в конторе все работают на windows XP и везде IE8. А админ (если есть) занят чем-то более важным. Так часто бывает.
Rumlin
25.11.2015 11:00Это доля IE8 в интернет, а внутри сети предприятия скорее всего IE тотален. Админы не приветствуют сторонний софт на рабочих станциях, тем более не управляющийся групповыми политиками.
SelenIT2
25.11.2015 09:53+1Имхо, IE8 давно можно смело приравнять к Оперу-в-мини. И давать обоим минималистичный код без украшательств, по-максимуму зафоллбэченный через сервер. Всё равно наворотов, позволяющих ценой ацккого перенапряжения сил (и разработчика, и клиентской машины) воспроизвести на этих штуках все новомодные плавные переливания с объемными тенями, их несчастные пользователи скорее всего «не поймут, провинция-с »..:)
Zenitchik
25.11.2015 16:04Старый веб, к сожалению, может погибнуть только вместе с РЖД, Сбербанком и иже с ними. А до тех пор поддержка от программистов, неизбежна.

rw6hrm
25.11.2015 09:51-1Наконец-то хоть кто-то озаботился динозаврами. А то надоело вносить в блэклисты сайты, требующие «обновить браузер», имхо ибо всё должно быть совместимо. Катаетесь же на великах по ДОП, ибо вам удобно и мерс не нужен, почему юзеру тогда нужно браузер менять из-за прихотей программеров?
SelenIT2
25.11.2015 09:59+2Но никто нормальный ведь не требует для великов возможности разгоняться до 250 км/с, ксеноновых фар, подогрева сиденья и акустики с сабвуфером. Почему с браузерами должно быть иначе? Никто ж не против, если для динозавров будут доступны дороги (контент), но не надо требовать имитировать для них современные «навороты»…
Zenitchik
25.11.2015 16:08Это Вы велозадротов не видели. Светодиодные фары, настолько яркие, что гаишники принимают их за ксенонки — практически норма. Сабвуферов не видел, но мощная акустика встречается. 250 км/ч — это трудно, но учитывая малую массу велека (даже вместе со всем, что на него повесили) электромотор сотню выдаёт без перегрева.
SelenIT2
25.11.2015 23:54+1Поэтому и оговорка «никто нормальный» вместо строгого «никто». Если кто-то хочет и может в свободное время делать из своего велика «почти Мерс» (добиваться от своей странички почти «взрослой» работы в «динозаврах») — на здоровье, действительно, хобби бывают разные и это не худшее. Но если такой персонаж начнёт с горящими глазами вещать, что велики должны быть только такими, а у кого велик не светит ксеноном и не орёт сабвуфером, тот ламер и лузер — думаю, всем будет очевидно, что это… далеко не норма:).
Увы, в отношении страничек в старых браузерах почему-то здравый смысл отказывает чаще…
faiwer
25.11.2015 10:55+4почему юзеру тогда нужно браузер менять из-за прихотей программеров?
Интересная у вас логика. Инопланетная. Разработчик выполняет свою работу из альтруистических побуждений? Или ему всё таки платят зарплату? Зарплату платят исходя из кол-ва труда, которое обычно выражается в трудочасах. Соотвественно каждое действие в проекте, совершённое разработчиком стоит работодателю денег.
Теперь будем работодателей винить, что они игнорирует 0.02% пользователей, потому что стоимость разработки под них увеличит стоимость продукта на 20-30%? Почему юзер должен менять браузер из-за прихотей бизнесменов? Так? :-)
Если ваша лень в обновлении браузеров безмерна, то вы можете тратить свои собственные деньги на допилку тех проектов, которые у вас покривились. Это будет довольно честно, правда?rw6hrm
26.11.2015 20:58Моя логика основана на обязательности совместимости. Если программеры таковой не озабочены, то да, это не моя планета, согласен. Просто не забываем о частой необходимости использования систем искаропки, в которые тупо запрещено вносить изменения и использовать сторонние программы. А также понимаем, что все «новинки», вносимые в стандарт — обычные свистомигалки, без которых в большинстве случаев можно и обойтись.
khim
26.11.2015 21:28+1Моя логика основана на обязательности совместимости.
Кто обязал? Кого обязал? Кому обязал? Куда мне засунуть купленную лет так 12 назад VHS-кассету и как мне позвонить с купленного тогда же D-AMPS телефона? XP, так, для справки, тогда уже была в ходу.
Если программеры таковой не озабочены, то да, это не моя планета, согласен.
Значит вам нужно на другую планету. Ту, где всё ещё в ходу патефоны и диафильмы. А программисты — совместимостью озабочены, да. Но… в меру. Как только что-то отживает свой срок — оно перестаёт поддерживаться. Когда конкретно это происходит — вопрос сложный и в каждом случае решаемый индувидуально, но всё, что связано с техникой рано или поздно отживает свой срок. Да, иногда на то, чтобы полностью изжить какой-нибудь устаревший стандарт уходят годы — но это вовсе не значит что все вокруг должны всё это время их поддерживать.
Просто не забываем о частой необходимости использования систем искаропки, в которые тупо запрещено вносить изменения и использовать сторонние программы.
Ну вот тот, кто «тупо запретил» их менять — пусть с ними и разбирается. NASA покупает процессоры и дисководы на eBay — вам тоже никто не запрещает это делать. Но остальные-то разработчики тут причём?
А также понимаем, что все «новинки», вносимые в стандарт — обычные свистомигалки, без которых в большинстве случаев можно и обойтись.
А вот это уж предоставьте решать тем, кто их разрабатывает.rw6hrm
27.11.2015 08:25-1Да я не против всяких нововведений, как Вы не понимаете..., только не надо насильно заставлять ими пользоваться.
khim
27.11.2015 10:47То есть когда поддержка WiMAX или теж же эдиссононовких сетей на 200V постоянного тока прекращается — это нормально, а когда вас просят браузер обновить — то это катастрофа?! Где логика?
Как и чем вы будете ими пользоваться — это ваши проблемы. Но так же, как с какого-то момента оборудование с поддержкой цепей постоянного тока стало не так-то просто купить, так и здесь: хотите поддерживать старые браузеры — сами думайте как вы это сделать. Можете proxy какой-нибудь поставить, можете вообще глазками на исходный код смотреть. Но разработчики вам ничем не обязаны.
faiwer
26.11.2015 21:58+1Если программеры таковой не озабочены, то да, это не моя планета, согласен
Точно не ваша. Разработчики озабочены тем, за что им платят. А тем, за что им не платят, они не озабочены. Вы ожидали чего-то иного?
Просто не забываем о частой необходимости использования систем искаропки, в которые тупо запрещено вносить изменения и использовать сторонние программы
Полагаю, речь идёт об программном обеспечении для истребителей, да? Почему вы применяете эту логику к веб-сайтам? Какое они имеют отношения «имутабельным к системам из коробки»?
А также понимаем, что все «новинки», вносимые в стандарт — обычные свистомигалки, без которых в большинстве случаев можно и обойтись.
В этом, наверное, тоже разработчики «виноваты»?
В общем я не вижу в этих ваших комментариях никакой логики, кроме оголтелого ретроградства и брюзжания. Поверьте, всем плевать на проблемы 0.02% пользователей, в особенности тем, кто платит за разработку. В следующий раз когда вы что-нибудь у кого-нибудь закажете, и потребуете мелочную опцию, от которой не будет никакого толку, но из-за которой вам повысят стоимость услуги эдак раза в полтора, вы едва ли будете мыслить в том же духе.

navion
25.11.2015 20:23Что интересно — протоколы шифрования в настройках у IE7 и IE8 одни и те же: SSL 2.0 (не отмечен), SSL 3.0 и TLS 1.0. И длина ключа в окне «О программе» и там и там равна 128 бит. Но почему-то IE7 сервер отшивает. Если кто знает причину такого явления — пишите в комментарии.
Протоколы SSL и TLS ? наборы шифров.
IE для HTTPS использует системный SChannel, который в XP не умеет SNI, а почти все поддерживаемые шифры считаются слабыми. Если вы настраивали веб-сервер по рекомендациям Mozilla, то он скорее всего не будет работать с любой версией IE на XP, но будет работать на Vista и выше.popov654
25.11.2015 20:56Но с IE8 работает :)
На самом деле, мне были нужны такие данные (адрес и название MP3 трека по его ID), которые в защите не нуждаются вовсе. Поэтому я поставил небольшой прокси в виде простейшего скрипта, который эти данные загружает через file_get_contents() и передаёт основному модулю.
bolk
popov654
Которому элементу, инпуту? Так она не работает, только сегодня проверял. Правда, работает
visibility: hidden— но при нём не кликнешь. Касаемо же «сверху» — вообще сомневаюсь. Если положить сверху что-то с бОльшим z-index, то клик не проходит. В Опере точно такое было, пока я не узнал, что можноclick()делать просто.faiwer
Всё работает. Только как раз input поверх кнопки, а не кнопка поверх input-а. Этот «трюк» ранее использовался повсеместно.
popov654
Да, вы правы, прошу прощения. Моя версия IE8 битая, она не работает с прозрачностью никак (переустановка не помогает). Способ вполне рабочий
vanxant
… еще можно инпут файл положить внутрь лейбла. И тогда никакие трюки с прозрачностью не потребуются.
popov654
У меня не сработало это. Инпут остался видимым. Может, вы что-то не уточнили?
vanxant
Ну так инпут скрыть надо, а label стилизировать как вам нужно.
Трюк в том, что input внутри label перехватывает получает все клики на label без паники системы защиты (label for= тоже работает).
MTonly
В Firefox ниже 23-й версии был баг, из-за которого для file-полей это не работало.
vanxant
И?
В ИЕ5 тоже было много багов. Доля какая?
popov654
А смысл в label? То есть это позволит сделать
display: none, при этом не используя прозрачность? Но я так понял, label обязательно должна быть привязана к инпуту черезfor, или нет?vanxant
Да, это позволит не заморачиваться прозрачностью, абсолютным позиционированием и прочими хаками.
Плюс это семантичненько, позволяет, например, управлять голосом.
vanxant
И да, атрибут for обязателен, только если инпут не лежит внутри label.