Примечание переводчика: В нашем блоге мы много пишем о построении облачного сервиса 1cloud, но немало интересного можно почерпнуть и из опыта по работе с инфраструктурой других компаний. Мы уже рассказывали о дата-центре фотосервиса imgix, описывали детективную историю поиска проблем с SSD-дисками проекта Algolia, а сегодня представляем вашему вниманию адаптированный перевод заметки инженеров сервиса аренды жилья Airbnb о поиске аномалий в платежной системе проекта.

В процессе обслуживания клиентов со всего мира компания Airbnb стремится предоставить удобный способ оплаты, с помощью которого наши гости смогут заплатить за услуги сервиса в местной валюте привычным для них способом, а хозяева могут без труда получить деньги в предпочитаемой ими валюте. Например, в Бразилии основной валютой является бразильский реал, и большинство жителей знакомы с такой платежной системой, как Boleto. В США оплата производится совершенно другими способами, так что можете представить, что было бы, если бы эта проблема возникала еще в 190 странах, где Airbnb оказывает свои услуги.
Чтобы справиться с этой задачей, наша команда специалистов по платежам разработала первоклассную платежную систему, безопасную и удобную в использовании. В обязанности этой команды, помимо прочего, входит оказание поддержки при оплате услуг и передаче средств хозяевам, разработка новых форматов оплаты, например, выдача подарочных карт, и помощь в работе с финансовыми документами.
Так как Airbnb работает в 190 странах по всему миру, наша система поддерживает большое число валют и множество операторов. Как правило, она работает без сбоев, однако мы сталкиваемся с некоторыми трудностями, когда не обрабатывается определенный тип валюты или отсутствует доступ к определенному платежному шлюзу. Для того, чтобы максимально быстро устранить эти помехи, наша команда «ученых по данным» [англ. Data Science team] разработала систему обнаружения аномалий, которая позволяет выявлять проблемы в режиме реального времени по мере их появления. Эта система помогает команде по разработке продукта быстро определить проблемы и их возможные решения, тем самым давая команде «ученых по данным» больше времени на проведение A/B-тестирования (новые способы оплаты и запуска продукта), статистического анализа (влияние цены на бронирование, прогнозирование) и разработку моделей машинного обучения для персонализации пользовательского опыта.
В рамках обзора системы обнаружения аномалий, разработанной нами для определения выбросов в выборке платежей, в этой статье будут использованы вымышленные данные, позволяющие показать, как работает эта модель. Предположим, что в 2020 году я буду руководить организацией по оказанию услуг электронной коммерции. Эта организация занимается продажей трех предметов компьютерной техники: мониторов, клавиатур и компьютерных мышей. Кроме того, у меня есть два поставщика: Lima и Hackberry.
Основной задачей системы обнаружения аномалий является поиск выбросов в выборке временных рядов. Иногда обобщенного прогноза бывает достаточно, но чаще всего нам приходится разбивать данные, чтобы определить основной тренд. Далее, рассмотрим случай, где необходимо проследить за импортом мониторов.

Общее число мониторов выглядит вполне естественно. Теперь взглянем на показатели импорта мониторов двумя нашими поставщиками: Lima и Hackberry.

На графике видно, что Lima, наш основной поставщик мониторов, не поставлял ожидаемый от него объем продукции с 18 августа 2020 года примерно в течение трех дней. В этот период мы автоматически переключились на нашего второго поставщика, Hackberry. Если бы мы смотрели только на обобщенные данные, то не смогли бы выделить никаких проблем, но когда мы начинаем углубляться в детали, то сразу же получаем всю информацию, указывающую на наличие реальной проблемы.
Интуитивная модель заключается в проведении простой регрессии методом наименьших квадратов с введением фиктивных переменных, которые обозначают дни недели. Эта модель имеет следующий вид:

где y – объем отслеживаемых показателей, t – переменная времени, Idayi – переменная, которая обозначает i-й день недели, e – величина погрешности. Эта модель довольно простая, и, как правило, достаточно точно определяет текущий тренд. Однако у нее имеется ряд недостатков:
Даже несмотря на то, что мы можем увидеть некоторую закономерность в изменении отслеживаемых нами показателей и регулировать нашу модель вручную (то есть мы можем вводить дополнительные фиктивные переменные, когда наблюдаем за ярко выраженной ежемесячной или ежегодной сезонностью), этот процесс не масштабируем.
Автоматизированный способ определения сезонности помогает нам избегать систематических ошибок и позволяет применять этот способ не только на данных платежных систем.
Если требуется построить модель временных рядов, учитывая и тренд, и сезонность, то эта модель обычно принимает следующий вид:
где Y – искомый показатель, S – сезонность, T – тренд, e – величина погрешности. Например, в нашей модели простой регрессии S является суммой индикаторных функций, а T представляет собой выражение at+b.
В этом разделе мы рассмотрим новые методы оценки тренда и сезонности, применив знания, полученные из предыдущего раздела. Чтобы показать, как работает эта модель, мы воспользуемся показателями объема продаж двух вымышленных товаров: клавиатур и компьютерных мышей. Объем продаж каждого из двух этих товаров представлен на следующем рисунке:

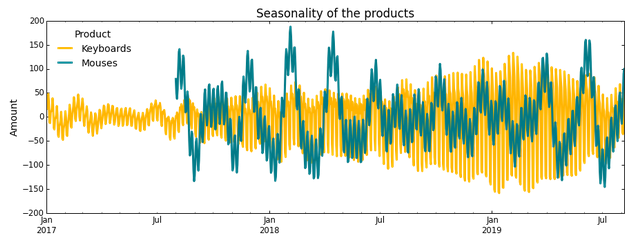
Как показано выше, основным товаром являются клавиатуры, продажи которых начались в сентябре 2016 года, а компьютерные мыши появились в продаже в августе 2017 года. Мы проведем моделирование сезонностей и трендов и попытаемся выявить аномалии, в результате которых величина погрешности оказывается гораздо выше среднего значения.
Чтобы определить сезонность, мы воспользуемся быстрым преобразованием Фурье (FFT). В модели простой линейной регрессии мы допустили наличие еженедельной сезонности. На графике выше можно заметить, что в случае с компьютерными мышами не имеется никаких регулярных еженедельных изменений, поэтому, если мы просто примем данное допущение, то наша модель не будет отражать реальной ситуации из-за слишком большого числа фиктивных переменных. В общем случае FFT отлично подходит для определения сезонности, когда у нас имеется большой объем исторических данных. Тогда мы без труда можем выявить сезонные паттерны. После применения FFT к обоим временным рядам мы получим следующие графики:
где
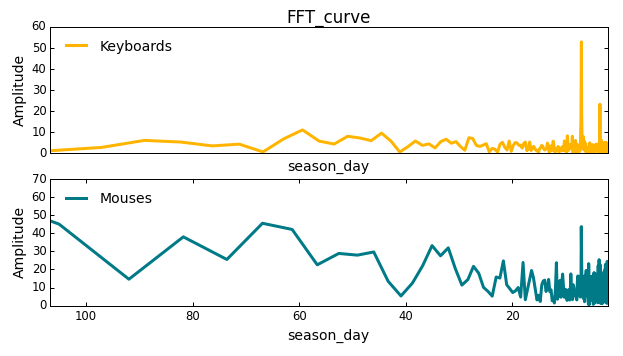
Как видно из графика, амплитуда сезонности продаж клавиатур со временем увеличивается, и прослеживается явная еженедельная сезонность, тогда как амплитуда изменения продаж компьютерных мышей демонстрирует явную сезонность не только в виде еженедельного тренда, но и на промежутке в 40 дней.
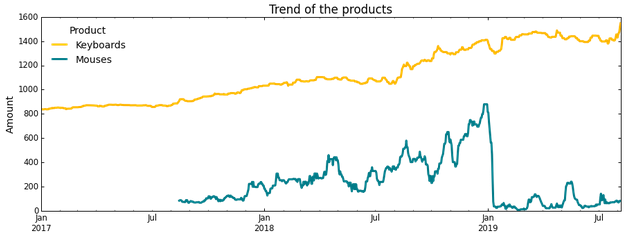
Для определения тренда временных рядов мы используем скользящую медиану. Будем считать, что рост на достаточно малом промежутке времени не очень сильный. Например, для выявления тренда в определенный день мы используем в расчетах скользящую медиану на промежутке в семь дней как среднее значение в этот день. Преимуществом использования медианы вместо математического ожидания является более высокая стабильность в случае возникновения выбросов. К примеру, если наше значение резко увеличивается в десять раз за один или два дня, то это никак не отразится на тренде, если смотреть на него с позиции медианы. Однако это окажет влияние на тренд в случае, если мы используем математическое ожидание. В нашем примере мы используем 14-дневную медиану в качестве тренда, показанного на графике ниже:
После определения сезонности и тренда нам необходимо оценить погрешность наших вычислений. Мы найдем величину погрешности и узнаем, нет ли в нашем массиве из временных рядов каких-либо аномалий. Если мы сложим вместе величины тренда и сезонности и затем вычтем полученное значение из исходных данных о продажах, то получим значение погрешности. Изменение величины погрешности мы изобразили на графиках ниже:
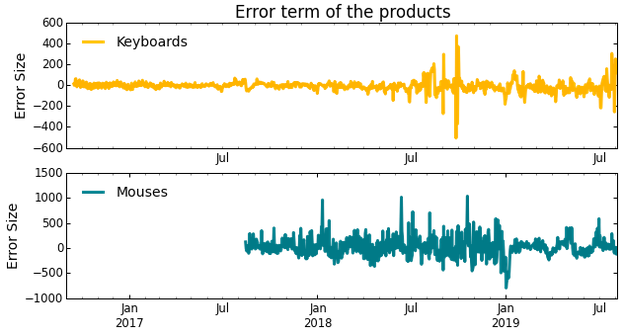
На них можно увидеть, что у нас имеется несколько скачков величины погрешности: это говорит о наличии аномалий в данных временных рядов. В зависимости от того, сколько ошибок нам разрешено допустить, мы можем выбрать, сколько стандартных отклонений разрешается отложить от нуля. В нашем случае мы разрешили отложить четыре стандартных отклонения, чтобы получить необходимое нам значение, или предупреждение.
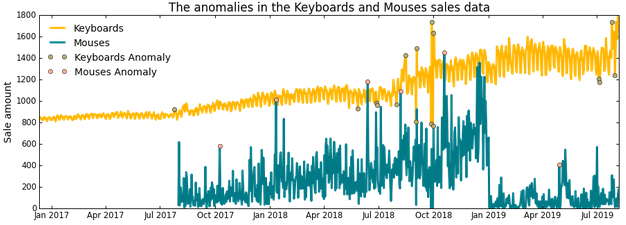
Как мы видим на графике выше, система предупреждений легко помогает определить большинство скачков величины погрешности, которым соответствуют аномалии в данных. Обратите внимание, что выявленные нами аномалии на первый взгляд таковыми не являются, однако на их наличие указывают сезонные паттерны.
Таким образом, в результате наших внутренних проверок выяснилось, что данная модель достаточно точно указывает на наличие аномалий и при этом вводит минимальное число допущений в данных.
Надеемся, что эта статья помогла вам разобраться в том, как можно построить модель для обнаружения аномалий. Такой анализ можно применять не только к данным о продажах – сам факт того, что в AirBnb придумали этот кейс в целях соблюдения конфиденциальности внутренней информации говорит о том, что данный подход может использоваться в самых разных ситуациях и будет полезен как крупным, так и небольшим бизнесам, отслеживающим те или иные статистические параметры. При этом самое главное в таком подходе – моделирование сезонности и тренда при наличии минимально возможного количества допущений (однако, как отмечают авторы статьи, в случае, если некоторые допущения значительно упрощают процесс моделирования, не стоит бояться их принимать).
В процессе обслуживания клиентов со всего мира компания Airbnb стремится предоставить удобный способ оплаты, с помощью которого наши гости смогут заплатить за услуги сервиса в местной валюте привычным для них способом, а хозяева могут без труда получить деньги в предпочитаемой ими валюте. Например, в Бразилии основной валютой является бразильский реал, и большинство жителей знакомы с такой платежной системой, как Boleto. В США оплата производится совершенно другими способами, так что можете представить, что было бы, если бы эта проблема возникала еще в 190 странах, где Airbnb оказывает свои услуги.
Чтобы справиться с этой задачей, наша команда специалистов по платежам разработала первоклассную платежную систему, безопасную и удобную в использовании. В обязанности этой команды, помимо прочего, входит оказание поддержки при оплате услуг и передаче средств хозяевам, разработка новых форматов оплаты, например, выдача подарочных карт, и помощь в работе с финансовыми документами.
Так как Airbnb работает в 190 странах по всему миру, наша система поддерживает большое число валют и множество операторов. Как правило, она работает без сбоев, однако мы сталкиваемся с некоторыми трудностями, когда не обрабатывается определенный тип валюты или отсутствует доступ к определенному платежному шлюзу. Для того, чтобы максимально быстро устранить эти помехи, наша команда «ученых по данным» [англ. Data Science team] разработала систему обнаружения аномалий, которая позволяет выявлять проблемы в режиме реального времени по мере их появления. Эта система помогает команде по разработке продукта быстро определить проблемы и их возможные решения, тем самым давая команде «ученых по данным» больше времени на проведение A/B-тестирования (новые способы оплаты и запуска продукта), статистического анализа (влияние цены на бронирование, прогнозирование) и разработку моделей машинного обучения для персонализации пользовательского опыта.
В рамках обзора системы обнаружения аномалий, разработанной нами для определения выбросов в выборке платежей, в этой статье будут использованы вымышленные данные, позволяющие показать, как работает эта модель. Предположим, что в 2020 году я буду руководить организацией по оказанию услуг электронной коммерции. Эта организация занимается продажей трех предметов компьютерной техники: мониторов, клавиатур и компьютерных мышей. Кроме того, у меня есть два поставщика: Lima и Hackberry.
Актуальность
Основной задачей системы обнаружения аномалий является поиск выбросов в выборке временных рядов. Иногда обобщенного прогноза бывает достаточно, но чаще всего нам приходится разбивать данные, чтобы определить основной тренд. Далее, рассмотрим случай, где необходимо проследить за импортом мониторов.
Общее число мониторов выглядит вполне естественно. Теперь взглянем на показатели импорта мониторов двумя нашими поставщиками: Lima и Hackberry.
На графике видно, что Lima, наш основной поставщик мониторов, не поставлял ожидаемый от него объем продукции с 18 августа 2020 года примерно в течение трех дней. В этот период мы автоматически переключились на нашего второго поставщика, Hackberry. Если бы мы смотрели только на обобщенные данные, то не смогли бы выделить никаких проблем, но когда мы начинаем углубляться в детали, то сразу же получаем всю информацию, указывающую на наличие реальной проблемы.
Модель
Модель простой регрессии
Интуитивная модель заключается в проведении простой регрессии методом наименьших квадратов с введением фиктивных переменных, которые обозначают дни недели. Эта модель имеет следующий вид:
где y – объем отслеживаемых показателей, t – переменная времени, Idayi – переменная, которая обозначает i-й день недели, e – величина погрешности. Эта модель довольно простая, и, как правило, достаточно точно определяет текущий тренд. Однако у нее имеется ряд недостатков:
- Прогнозирование роста осуществляется линейно. В случае, если рост происходит экспоненциально, смоделировать такой тренд будет весьма проблематично.
- В модели предполагается, что временные ряды настроены на еженедельную сезонность. Модель не будет работать с товарами, ориентированными на другие сезонные паттерны.
- Слишком большое количество фиктивных переменных требует большего объема выборки, чтобы коэффициенты достигли нужного уровня значимости.
Даже несмотря на то, что мы можем увидеть некоторую закономерность в изменении отслеживаемых нами показателей и регулировать нашу модель вручную (то есть мы можем вводить дополнительные фиктивные переменные, когда наблюдаем за ярко выраженной ежемесячной или ежегодной сезонностью), этот процесс не масштабируем.
Автоматизированный способ определения сезонности помогает нам избегать систематических ошибок и позволяет применять этот способ не только на данных платежных систем.
Модель быстрого преобразования Фурье
Если требуется построить модель временных рядов, учитывая и тренд, и сезонность, то эта модель обычно принимает следующий вид:
Y = S + T + eгде Y – искомый показатель, S – сезонность, T – тренд, e – величина погрешности. Например, в нашей модели простой регрессии S является суммой индикаторных функций, а T представляет собой выражение at+b.
В этом разделе мы рассмотрим новые методы оценки тренда и сезонности, применив знания, полученные из предыдущего раздела. Чтобы показать, как работает эта модель, мы воспользуемся показателями объема продаж двух вымышленных товаров: клавиатур и компьютерных мышей. Объем продаж каждого из двух этих товаров представлен на следующем рисунке:
Как показано выше, основным товаром являются клавиатуры, продажи которых начались в сентябре 2016 года, а компьютерные мыши появились в продаже в августе 2017 года. Мы проведем моделирование сезонностей и трендов и попытаемся выявить аномалии, в результате которых величина погрешности оказывается гораздо выше среднего значения.
Сезонность
Чтобы определить сезонность, мы воспользуемся быстрым преобразованием Фурье (FFT). В модели простой линейной регрессии мы допустили наличие еженедельной сезонности. На графике выше можно заметить, что в случае с компьютерными мышами не имеется никаких регулярных еженедельных изменений, поэтому, если мы просто примем данное допущение, то наша модель не будет отражать реальной ситуации из-за слишком большого числа фиктивных переменных. В общем случае FFT отлично подходит для определения сезонности, когда у нас имеется большой объем исторических данных. Тогда мы без труда можем выявить сезонные паттерны. После применения FFT к обоим временным рядам мы получим следующие графики:
где
season_day – это период, на котором амплитуда меняется по закону косинуса. В FFT мы обычно отбираем только те промежутки времени, на которых наблюдаются скачки амплитуды, указывающие на сезонность, а все остальные промежутки мы считаем помехами. В нашем случае на кривой продаж клавиатур мы видим два сильных скачка при значении переменной season_day, равном 7 и 3,5, и еще два небольших скачка при значениях 45 и 60. На кривой продаж компьютерных мышей мы видим резкий скачок на седьмой день и несколько небольших скачков при значениях 35, 60 и 80. Сезонности продаж клавиатур и компьютерных мышей, полученные после FFT, представлены на следующем графике:Как видно из графика, амплитуда сезонности продаж клавиатур со временем увеличивается, и прослеживается явная еженедельная сезонность, тогда как амплитуда изменения продаж компьютерных мышей демонстрирует явную сезонность не только в виде еженедельного тренда, но и на промежутке в 40 дней.
Тренд
Для определения тренда временных рядов мы используем скользящую медиану. Будем считать, что рост на достаточно малом промежутке времени не очень сильный. Например, для выявления тренда в определенный день мы используем в расчетах скользящую медиану на промежутке в семь дней как среднее значение в этот день. Преимуществом использования медианы вместо математического ожидания является более высокая стабильность в случае возникновения выбросов. К примеру, если наше значение резко увеличивается в десять раз за один или два дня, то это никак не отразится на тренде, если смотреть на него с позиции медианы. Однако это окажет влияние на тренд в случае, если мы используем математическое ожидание. В нашем примере мы используем 14-дневную медиану в качестве тренда, показанного на графике ниже:
Погрешность
После определения сезонности и тренда нам необходимо оценить погрешность наших вычислений. Мы найдем величину погрешности и узнаем, нет ли в нашем массиве из временных рядов каких-либо аномалий. Если мы сложим вместе величины тренда и сезонности и затем вычтем полученное значение из исходных данных о продажах, то получим значение погрешности. Изменение величины погрешности мы изобразили на графиках ниже:
На них можно увидеть, что у нас имеется несколько скачков величины погрешности: это говорит о наличии аномалий в данных временных рядов. В зависимости от того, сколько ошибок нам разрешено допустить, мы можем выбрать, сколько стандартных отклонений разрешается отложить от нуля. В нашем случае мы разрешили отложить четыре стандартных отклонения, чтобы получить необходимое нам значение, или предупреждение.
Как мы видим на графике выше, система предупреждений легко помогает определить большинство скачков величины погрешности, которым соответствуют аномалии в данных. Обратите внимание, что выявленные нами аномалии на первый взгляд таковыми не являются, однако на их наличие указывают сезонные паттерны.
Таким образом, в результате наших внутренних проверок выяснилось, что данная модель достаточно точно указывает на наличие аномалий и при этом вводит минимальное число допущений в данных.
Заключение
Надеемся, что эта статья помогла вам разобраться в том, как можно построить модель для обнаружения аномалий. Такой анализ можно применять не только к данным о продажах – сам факт того, что в AirBnb придумали этот кейс в целях соблюдения конфиденциальности внутренней информации говорит о том, что данный подход может использоваться в самых разных ситуациях и будет полезен как крупным, так и небольшим бизнесам, отслеживающим те или иные статистические параметры. При этом самое главное в таком подходе – моделирование сезонности и тренда при наличии минимально возможного количества допущений (однако, как отмечают авторы статьи, в случае, если некоторые допущения значительно упрощают процесс моделирования, не стоит бояться их принимать).