Казалось бы, прогресс сейчас быстр как никогда и любой пользователь смартфона расскажет вам о всё более и более быстрых процессорах, которые появляются в новых моделях. Но на крайнем севере уже потянуло холодком от стены, защищавшей нас от регресса. Там, где максимальная производительность микроэлектроники действительно нужна — в области суперкомпьютеров на самых передовых границах — прогресс остановился.
Как видно из графика, уже три года производительность топового суперкомпьютера (выраженная в операциях с плавающей точкой в секунду — FLOPS) не растёт. Более того, если заглянуть в анонсированные планы, то можно с уверенностью сказать, что ситуация не изменится как минимум в ближайший год. А значит стагнация производительности топового суперкомпьютера распространится и на 2016 год:
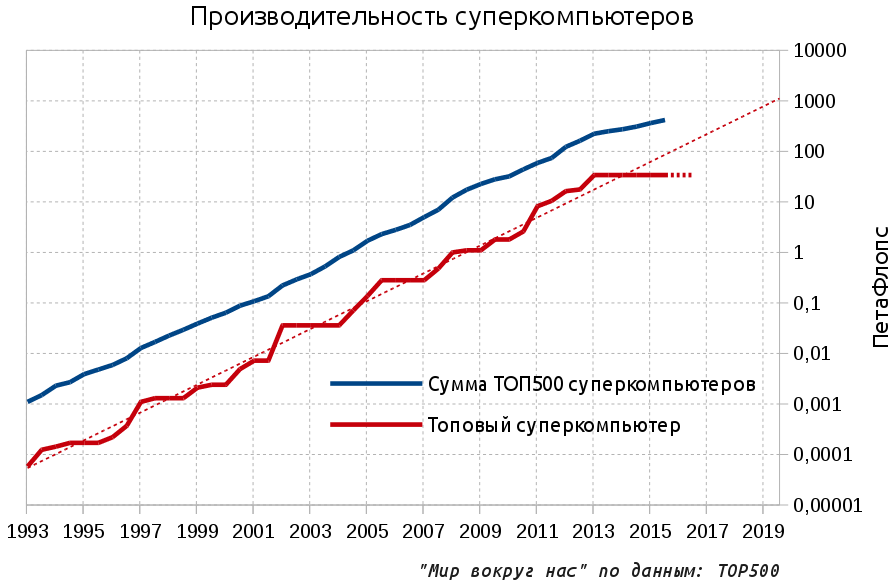
Пунктирами обозначены экспоненциальный тренд развития и прогноз для топового суперкомпьютера на 2016 год (стагнация). Коротко о матчасти: в статье используются приставки Пета и Экса. ПетаФлопс — 10^15 операций в секунду, а необходимое и обсуждаемое тысячекратное будущее — ЭксаФлопс, 10^18.
Для продолжения экпоненциального тренда суперкомпьютеры должны выйти на масштаб ЭксаФлопса в 2019 году, а сейчас в планах лишь около 100 ПетаФлопс для 2018 года — Aurora. Но в чём собственно проблема?
По моему опыту даже многие профессиональные разработчики софта и железа не смогут вам сказать в чём важность суперкомпьютеров. В современном мире, в веке всепроникающего интернета, огромные залы, набитые стойками железа и посвящённые обработке одной сложной вычислительной задачи кажутся уделом романтического прошлого начала компьютерной эпохи 1960х-70х. Ведь сегодня ресурсов даже одного личного компьютера хватает для решения многих сложных задач, а коммерчески доступные сервера позволяют обслуживать нужды огромных компаний. А ведь есть и популярные облачные вычислительные сервисы, обещающие вам бесконечные вычислительные ресурсы за скромное вознаграждение.
Но на самом деле суперкомпьютеры это то единственное, что даёт сегодняшнему семимиллиарному человечеству возможность продолжать развиваться и жить, не опасаясь мальтузианского проклятья.
Все передовые задачи можно решить только с помощью очень больших вычислительных мощностей и суперкомпьютер, где максимально оптимизируются все компоненты вычислительной техники, это самое подходящее средство для решения этих задач. Более того, прямое компьютерное моделирование можно интерпретировать как третий научный метод познания в довесок к теоретическим и экспериментальным изысканиям. Чтобы не быть голословным приведём несколько примеров.
О нефти матушке, которую уже давно почти невозможно найти без мощных компьютеров, мы уже писали и вывод был категоричен: утром суперкомпьютер — вечером нефть, вечером суперкомпьютер — утром нефть. Посмотрим и другие темы.
Авиация
В проектировании новых самолётов компьютерная симуляция позволила снизить количество физических тестов в аэродинамической трубе с 77 штук в 1979 до 11 в 1995 году и с тех пор значение остаётся на том же уровне. В чём-то из-за этого наши самолёты и остались примерно там же, где были. Переход на принципиально более точную физическую симуляцию на основе прямого применения уравнений Навье-Стокса требует вычислительных возможностей порядка 50 эксафлопс, то есть в 1000 раз больше чем у современного лидера — китайского Тянхэ-2 на 33 ПетаФлопс. При этом расчёт внешней аэродинамики ещё относительно прост — но, например, типичный двигатель состоит из тысяч движущихся частей и моделирование внутренних потоков потребует ещё более высокой вычислительной мощности.

Вычислительная гидродинамика применительно к лопаткам турбины (слева) и летательному аппарату X-43 при числе маха = 7
Термоядерная энергетика
В области термоядерной физики, о которой увлекательно пишет коллега tnenergy, проектирование следующего поколения токамаков невозможно без прогресса в моделировании высокотемпературной плазмы в условиях магнитной ловушки. Уже сейчас в моделях участвуют несколько миллиардов частиц в пространстве с разрешением 131 млн точек. Для таких масштабов используются самые мощные системы порядка ПетаФлопса и получены неплохие результаты, но ясно, что достаточной точности полной симуляции на базовых принципах понадобится увеличить масштаб в скромные 13 миллионов раз.

Моделирование поведения плазмы в токамаке
Климат и погода
Моделирование климата и точное предсказания погоды позволяют оптимально планировать наши действия — точность прогнозов растёт вместе с ростом производительности суперкомпьютеров. В перспективе можно будет предсказывать ливневые осадки и соответственно, наводнения и сели. Засухи и неурожаи.

Сегодня метеопрогноз на 4 дня столь же точен, как в 1980 году на один день
Всё более точные предсказания требуют более детальной модели планетарного масштаба и необходимо постоянное уменьшение ячейки симуляции. На данный момент ячейки моделей для краткосрочных региональных прогнозов имеют размеры 10х10 км, а долгосрочные климатические модели используют сетку с ячейками в сотни км, в то время как необходим масштаб 1х1 км по поверхности (в 10000 раз крупнее чем сейчас) и 100 метров по вертикали. Да с периодизацией в 1 секунду, что для двух месяцев означает 5 млн. секунд.
Пример современной модели с ячейкой 300х300 км.

Медицина и биология.
Не является исключением и медицина. На сегодня топовые суперкомпьютеры способны моделировать лишь отдельные сверхмалые части клеток:

На рисунке результат моделирования работы ионных каналов в мембране клетки на топовых суперкомпьютерах — а задействовано всего-то около 100 тысяч молекул. При этом всего молекул в клетке человека миллиарды, а самих клеток — почти квадриллион (10^14). Процесс получения новых лекарств и вывод их на рынок занимает 5-15 лет и уже сейчас идут разговоры о новых концепциях в драг-дизайне. Только представьте, насколько можно ускорить процесс и повысить эффективность лекарств, если моделировать ситуацию комплексно — начиная от ДНК возбудителя, в которой, по сути, заключена вся информация о нём и заканчивая моделью человеческого тела с учётом индивидуальных генетических особенностей.
Реальный список гораздо, гораздо больше: поиск принципиально новых материалов с заданными свойствами, астрофизика, атомная энергетика и многое многое другое.
Бухгалтерия экспоненты
Встаёт вопрос: если выгоды так велики, то почему мы не вкладываем действительно крупные деньги в мощные суперкомпьютеры? Дело в том, что до сих пор на нашей стороне была экспонента, а именно экспонента Мура — каждые 18-24 месяца плотность транзисторов удваивается и до самого недавнего времени это означало, что и производительность удваивается тоже.
Поэтому студентов геймеров мучил постоянный вопрос: “Нужно ли покупать комп сегодня за $2000 баксов или брать что-то попроще за $1000?” Ведь на оставшуюся $1000 через 3-4 года можно будет купить комп в пару раз мощнее. Это не удивительно, ведь линейная функция всегда проигрывает экспоненциальной и умножение стоимости давало в лучшем случае такое же линейное умножение производительности вместо степенной зависимости в случае экспоненты. Как правило, бюджет у студентов был не резиновый и выбор падал на второй вариант, но иногда хотелось попонтоваться, брали разпальцованый вариант и уже через пару лет зло смотрели на эту старую рухлядь.
Аналогичный процесс, но в гораздо более серьёзной обстановке, происходил и во время обсуждений новых суперкомпьютеров. В большинстве случаев выбирали более умеренный, но продуктивный путь. Показательно, что за последние 20 лет только три компьютера стоили больше 300 миллионов долларов и все три были построены за пределами США: два в Японии и один сегодняшний лидер в Китае, в странах с претензией на мировое лидерство. Ведь кроме реальной выгоды, иметь свой суперкомпьютер на первой строчки рейтинга стало предметом национальной гордости в доказательство факта существования национальной передовой науки.
Конец экспоненты
Из года в год раздаются возгласы, что закон Мура близок к концу и пока вроде бы это всё страшилки. Но при желании уже можно разглядеть отдельных всадников апокалипсиса:

Выше пять трендов для различных характеристик микропроцессоров. Закон Мура вроде как бы продолжается: оранжевым отмечено количество транзисторов на единицу площади с удвоением каждые 18-24 месяца. С 2005 года параметр вырос в 100 раз, но радости от этого уже не так много — синим отмечана производительность одного ядра и рост за тот же срок уже менее чем в 10 раз. Остальные транзисторы пошли на увеличение количества ядер, позволяющих обрабатывать задачи параллельно (чёрным).
В 2005 году можно было приобрести процессор с тактовой частотой 3,8 ГГЦ, а вот сейчас процессоров Интел с тактовой частотой выше 4 ГГц не купить. К графику это относится прямо: частота процессора, ответственная до этого за половину роста производительности, практически не менялась с 2004 года (зелёным), так же как и потребление энергии (красным), которое уперлось в возможности отвода тепла.
Эти тренды абсолютно симметрично проявляются и в архитектуре суперкомпьютеров. Если взять сегодняшнего китайского рекордсмена, то там мы видим и один из самых высоких показателей по энергопотреблению (18 МВт), и огромное количество вычислительных ядер и даже регресс по цене за ПетаФлопс. Всё это позволило построить суперкомпьютер всего лишь в два раза производительнее чем предыдущий конкурент.
Отвергнем буржуазную экспоненту ради коммунистической линейки !

Военнослужащие кибернетических войск Китая удаляют закладки из процессоров Intel Xeon.
Если компьютеры так важны, почему бы просто не продолжить китайский путь и сделать суперкомпьютер побольше, а потом и ещё побольше? Нужно понимать, что любое увеличение производительности за счёт линейного увеличения масштаба это не только увеличение долларовой цены, но и такое же линейное увеличение в потреблении энергии. Если взять китайского монстра с тремя миллионами ядер и попытаться масштабировать его с уровня 33 ПетаФлопс до уровня 30 ЭксаФлопс, то потребуется выделить в эксклюзивное пользование два десятка новеньких атомных реакторов, а это соответствует всем реакторам которые сейчас строятся в Китае. Если это ещё можно как-то затянув пояс потянуть, то уровень 30 ЗеттаФлопс с его 20’000 реакторами для нас закрыт навсегда.
Есть ли выход
Можно ли всё-таки продолжить экспоненту? На ближайшие годы — да, всё ещё можно. Через 2-3 года выйдут суперкомпьютеры примерно в три раза мощнее топового китайского и с лучшими параметрами потребления энергии и стоимости ПетаФлопс. А что будет дальше?
Лично я точно не знаю, но эксперты не очень оптимистичны. Например, директор Майкрософта посетил в конце октября официальный форум, посвящённый разработке будущей ЭксаФлопс-системы в США. На форуме были все ведущие производители железа, а также представители различных гос.агентств, разрабатывающие и использующие суперкомпьютеры.
Процитируем:
Всем участникам форума очевидно:
Современная микроэлектроника на базе технологии CMOS подходит к концу своих возможностей.
Нет альтернативной технологии, которая будет доступна в течение ближайших десяти лет.
Проще говоря, в ближайшие 10 лет существующая парадигма закончится, а другой парадигмы у нас для вас нет.
Комментарии (61)

darkfrei
26.11.2015 23:28+2Можно практические выводы?
Как я понял, топовый компьютер, купленный сегодня, за ближайшие лет десять морально не устареет?
Sychuan
26.11.2015 23:43+2Не совсем, скорее «топовый суперкомпьютер», купленный через 3-4 года, не устареет в течение 10 лет. Я так думаю.

150Rus
27.11.2015 00:00+4В самом топовом всё-таки включена наценка «за фанатcтво») Но серьёзный компьютер купленный сегодня будет актуален гораздо дольше, чем в начале 1990-х.

foxnet
03.12.2015 09:13+3Сегодня вполне можно работать на компьютере 2005 года. В принципе до недавнего времени я более-менее комфортно использовал комп 2001 года, а многие и продолжают его использовать. В то время как в 2005 году использование компа 1995 года было, мягко говоря, не комфортным. А это, стоит сказать, что-то вроде Pentium 166
Rumlin
04.12.2015 09:46Pentium — это было слишком дорого и потому и редко, хоть и быстро в сравнении с более дешевым K5 или VIA. Из-за современных браузеров и сайтов сейчас сложно пользоваться машинами с XP и 512Мб RAM.
foxnet
04.12.2015 09:49Ну как сложно, вполне работоспособно. Вконтактик, музычка, скайп, все работает. И людей, до сих пор работающих на northwood процессорах чрезмерно много. А они и не хотят ничего нового покупать, работает же.

rPman
26.11.2015 23:59+1У меня пока только одно слово — FPGA.
Я не просто удивлен, я негодую, почему эти технологии, в купе с продвинутыми компиляторами, не внедряются и наверное не сильно то и развиваются последние 5-10 лет.
Почему такая крутая технология, позволяющая на порядок повысить производительность при обычных вычислениях и на несколько порядков — распараллеливаемых при том же энергопотреблении, до сих пор находится исключительно как прерогатива железячников?
Где рост количества программируемых вентилей? Где мульти-чиповые решения? Где грамотная сетевая интеграция с модулями памяти и друг с другом? Где стандартизация этих решений и внедрение в персональное оборудование типа ПК, планшетники, мобильники,..?
p.s. у меня складывается впечатление, что современные суперкомпьютеры это сговор нескольких чиновников (принимающих решения в этой области) и производителей чипов (intel/amd/nvidia), сливающих основные объемы своих поставок на создание суперкомпьютеров?VioletGiraffe
27.11.2015 00:21+1А где компилятор С (а лучше — С++) в RTL?
Слишком дорого выбросить все программные наработки и выдумывать велосипед заново.rPman
27.11.2015 00:33Извините но с текущими наработками и парадигмой мы уже встреваем:
в ближайшие 10 лет существующая парадигма закончится, а другой парадигмы у нас для вас нет.
p.s. OpenCl компилятор для FPGA например может облегчить переход, хотя бы на первое время.
evocatus
27.11.2015 01:06Вы не поверите…
http://www.xilinx.com/products/design-tools/vivado/integration/esl-design.html

shebeko
27.11.2015 00:55+4Мы когда-то пытались брутефорсить блочный шифр на FPGA.
Казалось, что FPGA для этого идеально подходит.
Я довольно быстро накатал прогу на Verilog. Так вот она у меня не смогла скопмилится. Даже один раунд.
Проблема в том, что ячейки в FPGA не соединяются каждая с каждой, а имеют ограниченное количество связей.
А в шифре есть таблица битовых перестановок. Получается такое себе битовое выражение, которое компилер пытался упростить,
чтобы вложится в доступное к-во связей. :)
Самое смешное, что трудоёмко, но вполне реально, сделать раунд блочного шифра на макетке, используя обычные логические микрухи и соединив их обычными проводками.
Так что не всё так просто с FPGA.
Я уж молчу про операции с плавающей точкой.bigfatbrowncat
27.11.2015 17:44Думаю, что это всё лечится вложением средств в технологию.
В итоге, скорее всего, появится некий гибридный «монстр» из FPGA, образованный кучей микроядер-вычислителей.

vmarunin
27.11.2015 01:13+2Вроде бы Флопс это floating-point operations per second и там давно уже ASIC, сопроцессор по нашему.
Да, он встроен в процессор, но тем не менее.
В любом случае FPGA это возможность сделать много маленьких ядер, с более низкой частотой по сравнению с ASIC (обычный процессор по нашему). Да, этих ядер будет много, конвеер длинный, работать оно может в итоге даже быстрее, но всё это не помогает росту частоты. А нет роста частоты, нет и бесплатных плюшек. Или у FPGA продолжается экспоненциальный рост частоты?
Учимся думать, господа!
Ну и количество ядер у нас не забирают. Учимся использовать много ядер с огромными расстояниями между ними.
PS Размер атома и скорость света меня категорически не устраивает! Атомы должны быть меньше, а свет — быстрее. Хрен с ним с Kinect. Радары жалко, но хрен и с ними. :)rPman
27.11.2015 02:40shebeko, vmarunin это ньюансы реализации конкретных чипов, к тому же совершенно логично, что какие то ограничения и лимиты всегда будут.
Что за глупость! реализовывать на FPGA прцессоры общего назначения чтобы на них опять таки по шагам исполнялся требуемый алгоритм? когда на FPGA можно реализовать алгоритм и максимально оптимально напрямую, на сколько он вообще может быть реализован в железе.
p.s. Мало того, в теории наработки, накопленные по мере разработки различных приложений и библиотек, в будущем могут быть без особых затрат переведены в реальное железо и добавлены к компьютерам как сопроцессоры. Полагаю это однозначно добавит скорости работы.
0serg
27.11.2015 13:14+1FPGA очень сильно отличается от «максимально прямой реализации» и тем более — от оптимальной.
Работать оно работает, но не сказать что принципиально лучше обычного мощного CPU. Основной плюс FPGA сегодня в том что оно гораздо компактнее и его куда проще впихнуть в небольшую железку, а вот как от «ускорителя» к компьютеру от него мало толку.rPman
27.11.2015 15:21Вы сами ответили на свое же возражение.
FPGA эффективнее на ту же единицу электроэнергии и компактнее, а значит их можно разместить больше…
p.s. и стоимость производства на том же уровне (если не дешевле) что и обычные процессоры, правда стоимость разработки под них значительно выше,… пока.0serg
27.11.2015 17:38+1Стоимость FPGA сегодня намного выше чем стоимость GPU.
Performance/watt — это да, в некоторых задачах получше, но это все равно очень нишевое получается решениеbigfatbrowncat
27.11.2015 17:49+1Надо не стоимость сравнивать, а себестоимость. Потому что стоимость определяется прежде всего спросом, а он на FPGA очень низок пока, увы.
А вообще, к.м.к, GPU — это уже некий шаг в сторону использования FPGA. Когда вместо создания «универсального решателя всего на свете» маятник качнулся к «разделению обязанностей». Итог очевиден. На всех хорошопараллелизуемых задачах выигрыш колоссален. Универсальность CPU нафиг не нужна для графики ил моделирования сплошных сред, например.
А FPGA — шаг в сторону умения более гибко подразделять специализации чипов. В идеале — платы, на которых можно будет переключать вентили «в runtime». Вот такие решения здорово выиграют по производительности.
Хотя мне, как разработчику, становится прохладно межд лопаток от того, как сложно будет под них кодить.
Dendroid
27.11.2015 07:33Прямо как специально для вас: Intel hybrid CPU
А насчёт статьи статьи: «не верю». Односторонний подбор фактов + отличное умение задорно их подать )150Rus
27.11.2015 11:54Спасибо за комплимент)
Статья не истина в последней инстанции, но это достаточно распространённая точка зрения среди людей, которые занимаются суперкомпьютерами (хотя и не единственная, конечно). В статье есть цитата от человека, которому в отличие от автора положено быть специалистом в этой области. Во-вторых, по мне так сам факт того, что развитие суперкомпьютера эксафлопс-класса стало стратегической инициативой президента США, говорит о многом.

ncix
27.11.2015 01:23А что насчет сетей суперкомпьютеров? Или суперсетей рядовых серваков. Есть же интернет, почему нельзя объединить всю это дикую распределенную мощь умным софтом? Был же SETI@home, другие аналогичные проекты.
DanmerZ
27.11.2015 02:04+1Ну так есть проекты наподобие NorduGrid, обьединяющие университетские кластеры и предоставляющие пользователям свободные расчетные мощности.
a5b
27.11.2015 04:30+3Один из признаков суперкомпьютера — быстрая сеть (с низкими задержками и высокой пропускной способностью — т.е. локальная сеть — требуемые задержки могут составлять единицы микросекунд). Её наличие необходимо для некоторых классов задач (позволяет намного более эффективно их решать). В то же время есть другие классы задач, почти не требующие обменов данными, они как раз запускаются в BOINC и различных *@home.

vanxant
27.11.2015 07:25+4Большинство вычислительных алгоритмов в мат. моделировании сводятся к тому, что мы делим пространство на мелкие элементы (трёхмерные пиксели, воксели) и дальше пошагово считаем систему дифур на этих элементах. Причём состояние элемента на следующем шаге зависит только от состояния самого элемента и его соседей на предыдущем шаге.
Казалось бы, алгоритм прекрасно параллелится, воткни побольше процессоров и считай.
Но нет.
Допустим, каждый сервер кластера у нас обсчитывает куб пространства 1000х1000х1000 элементов (1 млрд. всего). Чтобы сшить сетку, сервер должен обмениваться с 6 своими соседями значениями параметров граничных элементов. Таких элементов 6 млн штук. Допустим, каждый элемент описывается 10 параметрами типа double. Это значит, на каждом шаге сервер должен отправить 480 мб данных и столько же принять. На 10-гигабит эзернете скорость симуляции составит 1 шаг по времени за секунду. Это очень медленно. А вы говорите — интернет.
Уменьшение количества элементов, обсчитываемых одним сервером, делает только хуже. Потому что общее количество снижается как куб стороны, а объём передаваемых данных — всего лишь как квадрат. В итоге всё упирается в рост производительности отдельных процессоров, которая последнее время практически стоит.ncix
27.11.2015 10:42Спасибо, доходчиво объяснили. но есть наверное задачи которые не требуют большого обмена данными, как упомянули выше?
150Rus
27.11.2015 11:46Но есть наверное задачи которые не требуют большого обмена данными, как упомянули выше?
Да, уже сейчас есть проекты которые считают на домашних компьютерах, объединённых в распределённую сеть. Самый крупный из них BOINC насчитывает 14 миллионов машин и имеет производительность в 140 петафлопс — в 4 раза больше чем китайский суперкомпьютер.
vanxant
27.11.2015 11:49+2Я не знаю, как биологию считают, но все остальные перечисленные в статье задачи работают именно так.
Есть большой класс задач на перебор, типа взлома шифров, поиска лекарства от рака и прочих там зелёных человечков — вот они да, не генерируют большого трафика.
Задачи, которые можно положить на map-reduce, а это всякий data-mining, тоже относительно мало грузят сеть, если правильно организована архитектура кластера (в частности, СХД).
red_andr
03.12.2015 04:42+1Расчёт погоды требует очень интенсивного обмена между процессорами. Точнее динамическая часть. Физическая и химическая, да, может считаться независимо на каждом процессоре.
rPman
27.11.2015 15:28Полагаю проблема скорости связи решается изменениями в архитектуре всего суперкомпьютера, когда узлы соединятся не в общую сеть а (дополнительно например) в сетевую структуру, где каждый узел связан только со своими соседями — т.е. очень короткие расстояния но зато очень высокие скорости…
И да, в конечном счете при любых технологиях, мы упремся в передачу данных,… это не проблема технологии или постановки задачи,… просто скорость передачи данных растет примерно с той же скоростью с какой растут скорости вычислений.
p.s. суперкомпьютер обычно делают универсальным,… и именно это накладывает на него ограничения по скорости… грубо говоря если сделать весь суперкомпьютер заточенным под одну задачу (класс задач) то его скорость в решении именно этих задач будет на порядок выше 'за те же деньги'.vanxant
27.11.2015 18:18+1Поздравляю, вы придумали архитектуру «тор» или «гипертор» (когда каждый узел обменивается данными по каналу точка-точка с 4 или 6 ближайшими соседями, а всё вместе выглядит как бублик в 3- или 4-мерном пространстве.
vanxant
27.11.2015 18:20+1И да, «вычислительные» суперкомпьютеры затачиваются под конкретную задачу — решение феерически огромных СЛАУ (к которым сводятся дифуры на сетке). И даже все эти ваши рейтинги строятся тестом LINPACK
bigfatbrowncat
27.11.2015 17:53Тут есть, правда, одна хитрость. Можно пренебречь синхронизацией длиной в один шаг на ячейку и передавать данные параллельно с обсчетом ячейки, а не попеременно. То есть каждая ячейка будет знать предыдущее (а не последнее) состояние соседних. При этом виртуальное время на передачу данных придет ко времени копирования этих данных в память конвеера передачи.
vanxant
27.11.2015 18:23Есть такая массивно-параллельная архитектура, вылетело из головы название. Ей неважна производительность отдельных процессоров, хоть Z80 ставь, главное их количество. Но и там всё упирается в латентность (задержку) межпроцессорных соединений.
bigfatbrowncat
27.11.2015 22:46Я просто имел в виду, что передачу данных можно распараллелить с расчетом, что снизит требования к скорости передачи данных. Мысль интересная…
a5b
28.11.2015 00:31Саму передачу сильно не распараллелить, сейчас сети всего лишь в разы медленнее чем память, и уже упираются в периферийные шины процессора (Infiniband EDR и Intel Omni-Scale — 100 Гбит/с на порт, каждый порт физически составлен из 4-х lane в каждую сторону по 25.7 Гбит/с каждая. Сетевые адаптеры требуют PCIe 3.0 шириной 16x).
Передача данных одновременно с вычислениями — это хорошая идея, и она используется уже более десяти лет…
www.osti.gov/scitech/servlets/purl/944757 (2008)
> Effective overlap of computation and communication is a well understood technique for latency hiding and
can yield significant performance gains for applications on high-end computers
techpubs.sgi.com/library/dynaweb_docs/0630/SGI_Developer/books/GS_Array/sgi_html/ch04.html#id78697 (image)
Есть и некоторое развитие, например, в MPI-3 или в новых интерфейсах к более умным сетям — blogs.cisco.com/performance/overlap-of-communication-and-computation-part-1

phprus
30.11.2015 10:15А смысл?
Задержка (latency) гораздо критичнее, чем пропускная способность, тем более, что пропускная способность сети уже близка к пропускной способности памяти, а задержка определяется скоростью света, которую не превысить.

potan
27.11.2015 09:49+1Подготовить задачу для суперкомпьютера не просто — порпобуйте воспользоваться какой-нибудь программой для химии ради интереса. Это ограничивает спрос. Правда, сейчас появилось «глубокое обучение», для которого достаточно иметь много данных, что может подстегнуть спрос.
Стоимоть микросхем быстро снижается с тиражем, и суперкомпьютеры приходится делать на чипах общего назначения. Если появятся коммерчески доступные технологии безмасковой литографии, то это ограничение будет снято.
В общем, шансы есть.

Teemon
27.11.2015 10:13А какая для интереса, мощность всех современных домашних компьютеров, ноутбуков? Думаю, ого-го.
ncix
27.11.2015 10:58Давайте прикинем очень примерно. Думаю ошибусь не более чем на порядок, если посчитаю что в мире около 1 млрд работающих домашних и офисных компов. Производительность возьем 10 ГФлопс — это на уровне простенького офисного компа.
10^9*10*10^9 = 10*10^18 или 10 экзафлопс. Что на самом деле не так уж много, всего в 300 раз больше лучшего суперкомпьютера.
Если к этому добавить все серваки во всех датацентрах, думаю можно увеличить еще на порядок — 100 экзафлопс.
Как-то так. Поправьте если сильно ошибся.

sergku1213
27.11.2015 10:26Вроде как и знал, смотрел недавно ТОП-500, и про частоты и неудовлетворительную скорость света, но тут так всё хорошо изложено, что опечалился. А тут ещё «Молчание Вселенной» — «парадокс Ферми», да и термояд застрял глубоко в… Ну, будем надеяться на «сильный антропный принцип», нейронные сети и мемристоры. Аминь.

Darth_Biomech
27.11.2015 11:36Necessity is the mother of invention ©. Цивилизация внезапно не рухнет из-за того что больше будет нельзя сделать более крутой процессор. Но дополнительного пинка под зад исследованиям для решения этой проблемы оно даст.

Gorthauer87
27.11.2015 12:01А как там дела с графеновыми транзисторами? Они же вроде позволяют делать частоту в сотни гигагерц. Недавно вот нашли способ делать графен в 100 раз дешевле. Может ещё пару таких итераций и он станет вполне массовым.
0serg
27.11.2015 13:19+2Отдельные кремниевые транзисторы тоже могут работать на частотах в сотни гигагерц, но у чипа с миллионами подобных транзисторов частота неизбежно получается ниже. Принципиального выигрыша графен емнип пока не дает.

Meklon
27.11.2015 21:32+3При частоте 100 ГГц, ваш сигнал успеет распространиться на 3 мм за такт. И этот для света в вакууме. В кристалле ещё меньшее расстояние. Какой у нас там общий размер кристалла? Тупо сигнал до другого конца чипа распространиться за такт не успеет.
0serg
01.12.2015 11:51Ну это только для latency всяких кэшей критично имхо. Размеры функциональных блоков в современных чипах поменьше будут 3 мм
a5b
01.12.2015 15:41+10serg, а каков размер комбинационной логики (длительность такта) в современных чипах в терминах FO4 (метрика для логики, которая позволяет оценить целевую частоту схемы на любом техпроцессе)? В en.wikipedia.org/wiki/FO4 есть некоторые примеры — 13 и 16 FO4 (10-25 FO4). С другой стороны для заданной технологии длительность одного FO4 примерно равна 5?.
Не могу точно сказать, сколько получится длительность FO4 для транзистора с f_t 100 GHz, однако в news.ycombinator.com/item?id=1104798 для RF КМОП транзисторов 90 нм назывались f_t 150 GHz. Для 65 нм LP CMOS оценивали FO4 в 28 psec. Для 28 нм — FO4 = 12 psec (целый инвертор с частотой порядка 80 ГГц).
В 2008 году техпроцесс 45 нм оценивали в f_t > 200 GHz, Fmax >500 GHz (опять RF, для логики несколько ниже); при сохранении FO4 это не позволило как-то значительно повысить частоты.
Уменьшать количество FO4 в такте в дизайнах особо некуда, т.к. при этом значительно увеличивается длина конвейера, простейшие операции приходится делать в несколько стадий. Увеличиться latency любых операций над широкими данными. Например, лучший 64-битный сумматор имеет длину в 7 FO4, еще немного, от 1 до 3 FO4 надо добавить на clock skew… Пробовали в Pentium 4 и Power6 (13 FO4, 5GHz, www-inst.eecs.berkeley.edu/~cs150/sp10/Collections/Papers/stolt-power6-jsscc200801.pdf), отказались.
Даже тактовые генераторы требуют определенной задержки, порядка 6-8 FO4. «Around 14-16 FO4 INV delays is limit for clock period»
Транзисторы с частотой переключения 100 ГГц и более уже есть (без графена, в массовом производстве), но процессоров более чем на 5-6 ГГц — единицы, и быстрее не ожидается.0serg
01.12.2015 17:38Это уже не ограничение по скорости распространения электромагнитного излучения и с размерами чипа FO4 насколько я понимаю слабо связано. А так материал очень интересный, не знал и соответственно подсказать что-либо не смогу.
a5b
01.12.2015 17:47Несколько FO4 может быть потрачено в процессе разводки схемы в пространстве… Плюс проблемы с целостностью сигналов на сверхвысоких частотах.
В целом, это подтверждение вашего комментария geektimes.ru/post/266506/#comment_8889736 "… у чипа с миллионами подобных транзисторов частота неизбежно получается ниже. Принципиального выигрыша графен емнип пока не дает."
И уточнение, что при повышении итоговых частот латентность повысится не только у кеша, но вообще у любых устройств и схем из-за необходимости их разбития на большее количество стадий.
Rumlin
27.11.2015 15:30+7Видел в своем универе действующую АВМ. Преподаватель сказал, что на ней рассчитывалась аэродинамика Су-27, в конце 80-х машину списали и передали весь комплекс в университет. И в универе в основном использовали для решения дифференциальных уравнений в задачах устойчивости зданий во время землетрясения. Данные (коэффициенты) вводились через древний ПК XT (некая самодельная ISA-карта c ЦАП/АЦП). Результат в реальном времени на ленту и циферблат вольтметра — нам продемонстрировали «землетрясение» в real-time. Стрелку вольтметра носило во все стороны, потом посмотрели график. Демонстрация решения «трехэтажных» уравнений впечатлила нас т.к. мы к тому времени делали работы по расчету простых диф/интегральных уравнений и при подобной точности одну итерацию наши программы считали десятки минут. А полный расчет за несколько часов. А эта штука выдавала результат сразу. Можно было подкрутить коэффициенты и сразу видеть их влияние на результат.
Imira_crai
27.11.2015 16:12Но на самом деле суперкомпьютеры это то единственное, что даёт сегодняшнему семимиллиарному человечеству возможность продолжать развиваться и жить, не опасаясь мальтузианского проклятья.
А в какой форме, по вашему мнению, будет выглядеть мальтузианское проклятье в современности и чем будет отличаться от того, которое было в доиндустриальную эпоху?ik62
27.11.2015 16:43масштабом?
Imira_crai
03.12.2015 10:01Мальтузианское проклятье же наступает в следствии дисбаланса демографического и продовольственного роста. Поэтому мне не совсем понятно, какого рода проклятье будет при исчерпании ресурсов суперкомпьютеров? Даже, если это опять будет кризис из-за дисбаланса демографии и продовольствия, то он явно будет иметь совершенно другую форму, нежели вековой давности.

evtomax
28.11.2015 00:46Мне кажется, что человечество ещё не до конца освоило уже существующие технологии. Вот у большинства людей вся бытовая автоматизация заканчивается на стиральной машинке и микроволновке, которые даже не подключены в домашнюю локальную сеть! Благодаря современным технологиям можно экономить кучу времени. Находясь в магазине, очень удобно видеть на экране мобильника содержимое холодильника. Если объединить автоматическое управление шторами на окне и искусственным освещением, можно решить проблемы со сном. И вот есть у меня на столе измеритель углекислого газа, и очень неудобно, что он самостоятельно не умеет управлять проветриванием. И таких примеров, где огромный потенциал для повышения эффективности с помощью уже существующих технологий, огромное количество.

ramntry
29.11.2015 17:41Никто же не говорит, что мы полностью исчерпали пути увеличения эффективности всех наших процессов, от производственных до бытовых, от исследовательских до социальных. Речь идет о том, что наша способность решать определенный класс фундаментально сложных задач, часть из которых в статье и описана, как будто бы перестала улучшаться, или по крайней мере сильно замедлила темп своего развития, к тому же, без легко видимых путей решения этой проблемы. Как говорил один из, если мне не изменяет память, советских актеров (или спортсменов?), «если я перестаю работать над собой, я замечаю это через три дня, мой тренер — через неделю, а зритель — только через месяц». Заметить стагнацию на передовом уровне науки и технологии сегодня — это способ рано заметить и спрогнозировать стагнацию во всем остальном в ближайшем будущем.
iBat
Спасибо за интересный анализ. А что со специализированными для конкретной задачи решениями? Для тех же биткоинов, требующих так же огромных вычислительных мощностей, сделали железки, которые на порядки «уделывают» не только универсальные CPU, но и менее универсальные, но более пригодные для определенных вычислений GPU. Кстати — а что на счет GPU в деле применения в суперкомпьютерах?
150Rus
GPU и специализированные акселераторы используются очень широко — все новые машины и верхние две строчки в рейтинге используют GPU. Специализованное железо, да, намного быстрее (несколько порядков), но его проблема в том, что нужно делать чип под каждую достаточно узкую задачу. Это очень и очень дорого и имеет смысл только при окончательном конце экспоненциального тренда.
Grox
Вот здесь и могут крыться корни новой эпохи — быстрое и относительно дешёвое автоматизированное производство специализированных чипов.
foxnet
Тем не менее, я так понимаю, что задачи, под которые строятся суперкомпьютеры все-таки достаточно ограничены, вы их и описали. По идее ведь можно оптимизировать процессоры только под определенные математические формулы, отойдя от использования процессоров для общего назначения. Собственно, а почему бы и нет? Хотя может быть, конечно, все значительно сложнее, чем кажется мне, обывателю)