Мы выбрали задачу от Альфа-Банка про прогнозирование оттока клиентов. Краткая суть:
Перед вами набор данных, состоящий из 3-х поколений (3 последовательных отчетных месяцев) активных клиентов, часть из которых спустя 2 месяца стали неактивными, т.е. ушли в отток (поле target = 1) Тестовый набор данных содержит следующее, 4-ое поколение активных клиентов.
Цель:
Для представленного набора данных построить бинарный классификатор вероятного оттока клиентов спустя 2 месяца.
Критерий качества оценки – AUC, по результатам проверки на контрольном наборе.
Работать предполагалось на сервисе Azure Machine Learning — вэб-платформе с вычислениями в облаке и всеми необходимыми интегрированными инструментами: Azure.
С платформой впервые мы познакомились накануне в пятницу, 27 ноября. 29 вечером отмечали победу. Это большой плюс сервиса, так как порог входа для новичка невысок, а вот знания в сфере машинного обучения для успешного применения встроенных моделей требуются.
Я сразу расскажу про модель, которая у нас получилась. Сделаю оговорку, что, в силу ограниченного времени, приходилось работать быстро и 99% возможных гипотез о данных не были проверены. По сути, мы подавали немного предобработанные данные и нажимали кнопку Run. Этакий фастфуд мира data mining. В обычной работе (а мы работаем в команде BI компании Align Technology), конечно, на первом месте идет кропотливый разбор данных, проверка статистических гипотез, выбор вариантов нормализации данных, подбор и сравнение моделей. Но можно отметить, что Azure также позволяет сделать это довольно комфортно.
Наш результат:
Стадия предобработки данных

Во-первых, мы решили убрать из набора данных все переменные типа string, потому что многие модели не хотели на них обучаться и выдавали ошибку — модуль Project Columns. После оцифровки стринговых данных и добавления их в модель мы не увидели улучшения качества обучения, поэтому окончательно от этих переменных отказались.
Во-вторых, мы заменили missing data на одну из мер центральной тенденции, и анализ значимости полученных переменных показал, что бывшие миссинги статистически значимо влияют на Target.
В-третьих, из обучающего набора был исключен столбец с ID.
Данные были разделены на обучающий и тестовый наборы с помощью модуля Split Data в пропорции 70/30.
Первый слой обучения: «слабые» классификаторы

На нижнем уровне мы выбрали 3 классификатора, исходя из нашего опыта и после нескольких проб всех доступных моделей two-class classifier с использованием модуля Sweep Parameters. Пример быстрого доступа к интересующим нас моделям:

Реально удобно, но мы сошлись на мнении, что, в целом, сервис не для статистиков. То есть, все по максимуму стандартизовано, шаблонно, и с защитой от дурака.
Выбор пал на boosted decision trees, neural network, logistic regression. Для каждой из моделей мы выбрали по 3 набора параметров (из Sweep Parameters), которые можно характеризовать как а) наиболее слабая модель, б) средней сложности модель, в) модель повышенной сложности. Это и количество деревьев и эпохи обучения и learning rate.
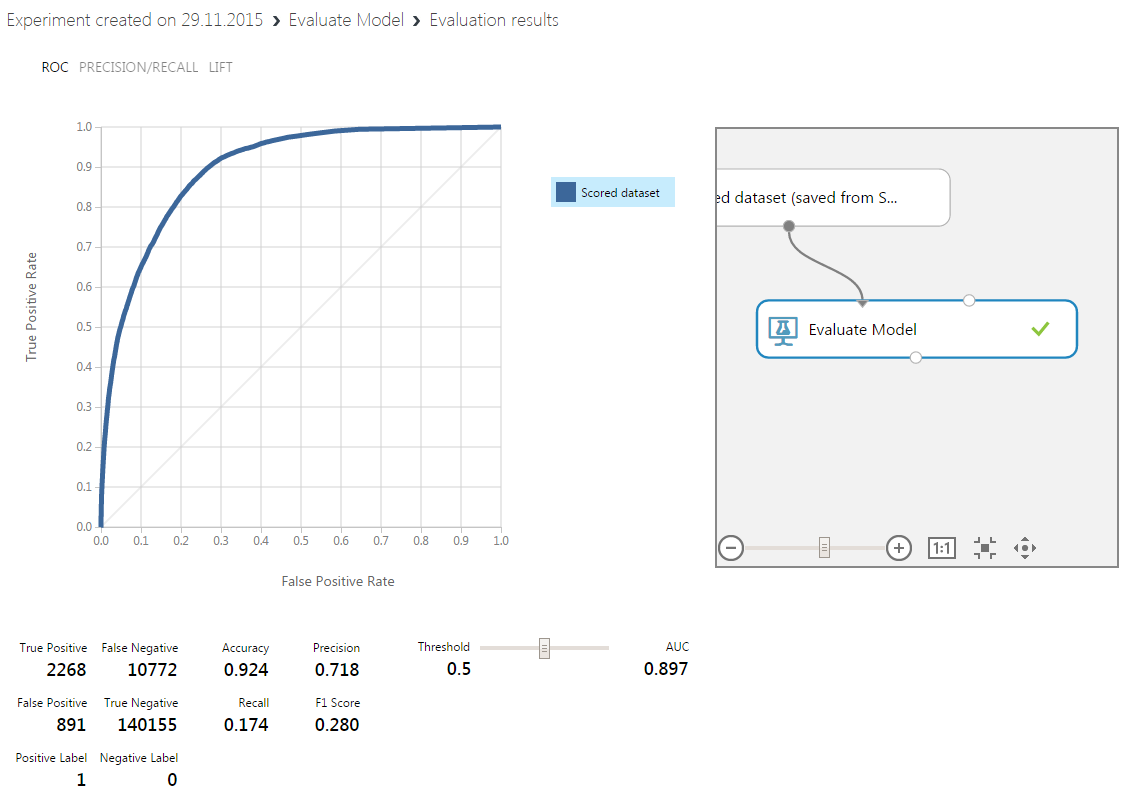
Получили 9 вариантов предсказаний, из которых ускоренный лес деревьев дал наилучший результат, примерно соответствующий уровню попавших в тройку лучших моделей на этой задаче:

В реальности метрика была немного лучше (я уже переобучил модель с другими параметрами).
Логистическая регрессия и слабая нейронная сеть дали результаты похуже.
Второй слой обучения:
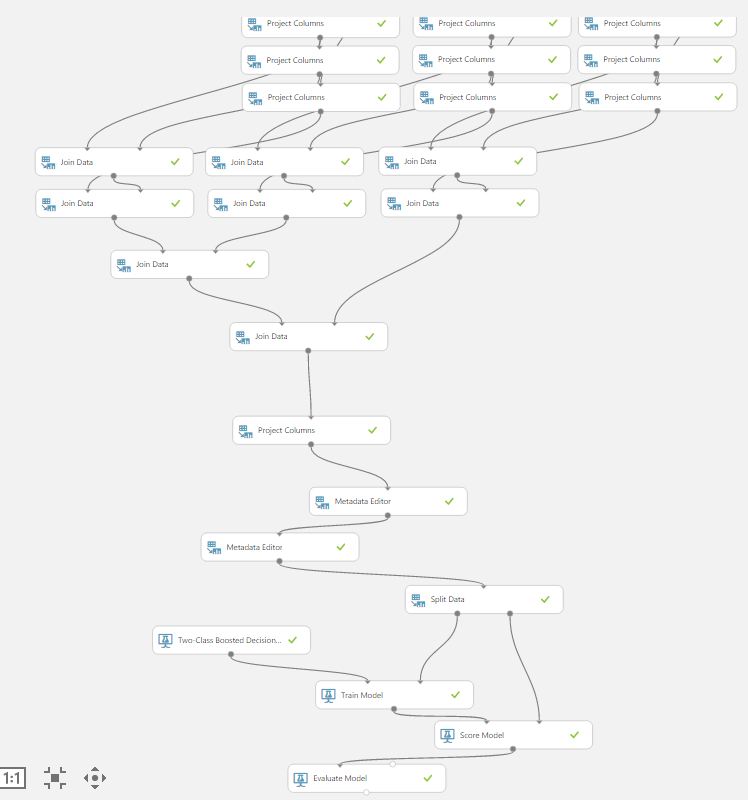
Мы приняли решение подать предсказания всех 9-ти моделей первого слоя в качестве обучающего набора на модель второго слоя, в качестве которой был выбран также ускоренный лес деревьев решений. Таким образом мы реализовали концепцию Stacking (мета-обучение), которая при некоторых допущениях даст результат не хуже, чем лучший из «слабых» моделей. У нас это и получилось в результате.
Заметим, что на второй слой шли результаты, полученные на тестовом наборе (30%) выборки.
Для того, чтобы второй корректно отработал на входах-выходах первого слоя нужно колдовство с MetaData Editor:

Все. Плюс к сказанному — мы делали одновременно разные части работы и копировали друг у друга получившиеся эксперименты для доработок. В результате к 15:00 подошли с двумя одинаковыми архитектурами, но с разными параметрами обучаемых моделей. Выбрана была лучшая согласно наших представлениям.
Отметим, что обучение на наборе из 400+ К строк и 100+ столбцов в облаке Azure происходило быстрее, чем мы думали — около 10 минут. Мы даже успели пообедать до того, как в 15:55 расшарили workspace с экспертами MS.
Также советуем вам обратить внимание на правила оформления workspace и experiments. Мы чуть не попали в просак, назвав наше рабочее пространство произвольным именем, и пришлось досабмитить модель уже перед самым объявлением победителей.
Сорри, МикроЯндекс, мы вас оставили на почетном втором месте. Респект СПб за почетное третье место.
Из минусов сервиса, которые можно, кстати, списать на наше нубство, мы не смогли найти как вывести список переменных с типами. И капитан команды Роман юзал ночью SQL и R, чтобы создать такую банальную таблицу вывода. А я руками просеивал столбцы и наполнял Project Columns.
Отметим также, что, возможно, стринговые переменные могут еще улучшить качество прогноза, если их хорошо приготовить и тщательно переварить.
Спасибо за внимание.
Роман, Алексей.
PS: Спасибо Татьяне за отличную организацию.
Комментарии (10)

Temp1ar
30.11.2015 22:19+1А вам предоставлялось описание параметров? Интересно было бы узнать, какие всё-таки параметры сильнее всего влияют на отток клиентов. Можете ли сформулировать результат для бизнеса в двух словах?

Alexey_mosc
01.12.2015 20:25Я могу дать приблизительный ответ. Мы не анализировали каждый параметр, потому что время на анализ превзошло бы экономию времени на обучение более легкой модели )
Из самых значимых:
остатки клиента по продуктам банка за некоторый период
оборот на счетах клиента за некоторый период
срок жизни клиента в банке
Я бы с позиции своего опыта сказал так — рулит RMF (Recency, Frequency, Money), то есть, сколько потратил, с какой частотой тратит, как давно последний раз тратил деньги на ваши продукты. Это универсальное правило.

pro100olga
01.12.2015 17:57+2Спасибо за материал и с победой! А каким ПО вы пользуетесь в обычной работе?
Вообще, из нескольких описаний хакатонов и других конкурсов по data mining, которые мне попадались, складывается впечатление, что подход «мы подавали немного предобработанные данные и нажимали кнопку Run» — это правило таких мероприятий. И мне кажется, это очень грустно, потому что формирует представление о DM как о чем-то, где надо не столько думать, сколько уметь засовывать данные в процедуру random forest )Alexey_mosc
01.12.2015 19:56+1Спасибо! Для нас победа стала неожиданностью. На контрольной выборке модель показала более высокую метрику Area Under Curve, чем на маленьком валидационном наборе, которым мы пользовались перед сабмитом.
В работе мы используем R (но никто не ограничивает работать на Яве или Питоне), данные получаем через SQL-запросы, в основном. Я как аналитик со стажем 8+ лет люблю и использую MS Excel для некоторых задач и запускаю vlookup и другие функции с закрытыми глазами.
Я фанат статистики, люблю получать наиболее прозрачные результаты, трактуемые, достоверные. Для меня самого работы Random Forest и других моделей с большим количеством скрытых элементов представляется, в первую очередь, неплохо работающей эвристикой. Сложнее сделать метрику, которая бы явно сообщала о том, что данный набор входных переменных именно на столько-то процентов детерминирует выход и указать статистическую значимость данного результата. Но я и это умею делать, хотя времени требуется гораздо больше.
Что касается конкурсов по предиктивной аналитики, это мой первый опыт (не считая Kaggle) и я вообще называю борьбу за первые места гонкой за шумами. Если приглядеться к Kaggle leaderboard-ам, нетрудно заметить, что перетасовка победителей на контрольной выборке случается часто, и заранее бывает сложно сказать, есть ли смысл подогнать модель еще на 0,5% на доступных данных или подождать.
Я за то, чтобы данные анализировались медленно и качественно. Понятно, что конкурсы преследуют и свои собственные маркетинговые цели.pro100olga
01.12.2015 20:16+1Ваш комментарий просто бальзам на душу )
Я тоже люблю эксель, трактуемые результаты и качественный медленный анализ )

MRoizner
02.12.2015 18:58А можете на me@druxa.ru расшарить пожалуйста эксперимент, в котором получается 0.897? Очень хочется подробности посмотреть. Это вас из команды МикроЯндекс беспокоят :) У меня нет на хабре аккаунта, пишу из под чужого.
codezombie
Пару вопросов:
1) лучшее/худшее значение AUC обученных на нулевом уровне (если считать, что метамодель — это level 1) моделей?
2) как подбирались параметры алгоритма обучения метамодели?
Alexey_mosc
Худшая AUC — 0.709, лучшая — 0.85
Метамодель сначала обучали с помощью Sweep Parameters. Затемы выбрали лучшие параметры, вручную задали такую модель и пропустили ее на кросс-валидации, увидели, что метрика плавает с разбросом примерно 0,01. После этого убрали кросс-валидацию и обучили на 95% (уже тестовой) выборки.
PS: мы почему-то не смогли задеплоить тестовую модель с включенными модулями Sweep Parameters. Поэтому размножили модели сами.
codezombie
Вот это интересные подробности! Еще раз поздравляю с победой.