Ответом на это было новое поколение легковесных, высокопроизводительных баз данных, созданных для того, чтобы бросить вызов господству реляционных баз данных.
Большой причиной для движения NoSQL послужил тот факт, что различные реализации веб, корпоративных и облачных приложений имеют различные требования к их базам.
Пример: для таких объемных сайтов, как eBay, Amazon, Twitter, или Facebook, масштабируемость и высокая доступность являются основными требованиями, которые не могут быть скомпрометированы. Для этих приложений даже малейшее отключение может иметь значительные финансовые последствия и влияние на доверие клиентов.
Таким образом, готовое решение базы данных зачастую должно решать вопросы не только транзакционной целостности, но более того, более высокие объемы данных, увеличение скорости и производительности данных, и растущее разнообразие форматов. Появились новые технологии, которые специализируются на оптимизации по одному, или двум из вышеупомянутых аспектов, жертвуя другими. Postgres с JSON применяет более целостный подход к потребностям пользователей, успешнее решая большинство рабочих нагрузок NoSQL.
Сравнение документо-ориентированных/реляционных баз данных
Умный подход новой технологии опирается на тесную оценку ваших потребностей, с инструментами, доступными для достижения этих потребностей. В приведенной ниже таблице сравниваются характеристики нереляционной документо-ориентированная базы (такая как MongoDB) и характеристики Postgres'овской реляционной/документо-ориентированной базы данных, дабы помочь Вам найти правильное решение для ваших потребностей.
| Особенности | MongoDB | PostgreSQL |
| Начало Open Source разработки | 2009 | 1995 |
| Схемы | Динамическая | Статическая и динамическая |
| Поддержка иерархических данных | Да | Да (с 2012) |
| Поддержка «ключ-событие» данных | Да | Да (с 2006) |
| Поддержка реляционных данных / нормализованной формы хранения | Нет | Да |
| Ограничения данных | Нет | Да |
| Объединение данных и внешние ключи | Нет | Да |
| Мощный язык запросов | Нет | Да |
| Поддержка транзакций и Управление конкурентным доступом с помощью многоверсионности | Нет | Да |
| Атомарные транзакции | Внутри документа | По всей базе |
| Поддерживаемые языки веб-разработки | JavaScript, Python, Ruby, и другие… | JavaScript, Python, Ruby, и другие… |
| Поддержка общих форматов данных | JSON (Document), Key-Value, XML | JSON (Document), Key-Value, XML |
| Поддержка пространственных данных | Да | Да |
| Самый простой способ масштабирования | Горизонтальное масштабирование | Вертикальное масштабирвоание |
| Шардинг | Простой | Сложный |
| Программирование на стороне сервера | Нет | Множество процедурных языков, таких как Python, JavaScript, C,C++, Tcl, Perl и многие, многие другие |
| Простая интеграция с другими источниками данных | Нет | Внешние сборщики данных из Oracle, MySQL, MongoDB, CouchDB, Redis, Neo4j, Twitter, LDAP, File, Hadoop и других… |
| Бизнес логика | Распределена по клиентским приложениям | Централизована с триггерами и хранимыми процедурами, или распределена по клиентским приложениям |
| Доступность обучающих ресурсов | Трудно найти | Легко найти |
| Первичное использование | Большие данные (миллиарды записей) с большим количеством параллельных обновлений, где целостность и согласованность данных не требуется. | Транзакционные и операционные приложения, выгода которых в нормализованной форме, объединениях, ограничениях данных и поддержке транзакций. |
Источник: сайт EnterpriseDB.
Документ в MongoDB автоматически снабжается полем _id, если оно не присутствует. Когда Вы хотите получить этот документ, Вы можете использовать использовать _id — он ведет себя в точности как первичный ключ в реляционных базах данных. PostgreSQL хранит данные в полях таблиц, MongoDB хранит их в виде JSON документов. С одной стороны, MongoDB выглядит как прекрасное решение, так как вы можете иметь все различные данные из нескольких таблиц в PostgreSQL в одном JSON документе. Эта гибкость достигается отсутствием ограничений на структуре данных, которые могут быть действительно привлекательными в первый момент и реально ужасающими на большой базе данных, в которой некоторые записи имеют неправильные значения, или пустые поля.
PostgreSQL 9.3 идет в комплекте с прекрасным функционалом, который позволяет превратить его в NoSQL базу данных, с полной поддержкой транзакций и хранением JSON документов с ограничениями на полях с данными.
Простой пример
Я покажу как это сделать, используя очень простой пример таблицы Служащих. Каждый Служащий имеет имя, описание, некий номер id и зарплату.
Версия PostgreSQL
Простая таблица в PostgreSQL может выглядеть следующим образом:
CREATE TABLE emp (
id SERIAL PRIMARY KEY,
name TEXT,
description TEXT,
salary DECIMAL(10,2)
);
Эта таблица позволяет нам добавлять служащих вот так:
INSERT INTO emp (name, description, salary) VALUES ('raju', ' HR', 25000.00);
Увы, вышеприведенная таблица позволяет добавлять пустые строки без некоторых важных значений:
INSERT INTO emp (name, description, salary) VALUES (null, -34, 'sdad');
Этого можно избежать, добавив ограничения в базу данных. Предположим что мы всегда хотим иметь непустое уникальное имя, непустое описание, не негативную зарплату. Такая таблица с ограничениями будет выглядеть:
CREATE TABLE emp (
id SERIAL PRIMARY KEY,
name TEXT UNIQUE NOT NULL,
description TEXT NOT NULL,
salary DECIMAL(10,2) NOT NULL,
CHECK (length(name) > 0),
CHECK (description IS NOT NULL AND length(description) > 0),
CHECK (salary >= 0.0)
);
Теперь все операции, такие как добавление, или обновление записи, которые противоречат каким-то из этих ограничений, будут отваливаться с ошибкой. Давайте проверим:
INSERT INTO emp (name, description, salary) VALUES ('raju', 'HR', 25000.00);
--INSERT 0 1
INSERT INTO emp (name, description, salary) VALUES ('raju', 'HR', -1);
--ERROR: new row for relation "emp" violates check constraint "emp_salary_check"
--DETAIL: Failing row contains (2, raju, HR, -1).
NoSQL версия
В MongoDB, запись из таблицы выше будет выглядеть как следующий JSON документ:
{
"id": 1,
"name": "raju",
"description": "HR,
"salary": 25000.00
}
подобным образом, в PostgreSQL мы можем сохранить эту запись как строку в таблице emp:
CREATE TABLE emp (
data TEXT
);
Это работает как в большинстве нереляционных баз данных, никаких проверок, никаких ошибок с плохими полями. В результате, вы можете преобразовывать данные как захотите, проблемы начинаются тогда, когда ваше приложение ожидает что зарплата это число, а на деле это либо строка, либо она вообще отсутствует.
Проверяя JSON
В PostgreSQL 9.2 для этих целей есть хороший тип данных, он называется JSON. Этот тип может хранить в себе только корректный JSON, перед преобразованием в этот тип происходит проверка на валидность.
Давайте изменим описание таблицы на:
CREATE TABLE emp (
data JSON
);
Мы можем добавить какой-нибудь корректный JSON в эту таблицу:
INSERT INTO emp(data) VALUES('{
"id": 1,
"name": "raju",
"description": "HR",
"salary": 25000.00
}');
--INSERT 0 1
SELECT * FROM emp;
{ +
"id": 1, +
"name": "raju", +
"description": "HR",+
"salary": 25000.00 +
}
--(1 row)
Это сработает, а вот добавление некорректного JSONa завершится ошибкой:
INSERT INTO emp(data) VALUES('{
"id": 1,
"name": "raju",
"description": "HR",
"price": 25000.00,
}');
--ERROR: invalid input syntax for type json
Проблема с форматированием может быть трудно заметной (я добавил запятую в последнюю строку, JSONу это не нравится).
Проверяя поля
Итак, у нас имеется решение, которое выглядит почти как первое чистое PostgreSQL решение: у нас есть данные, которые проверяются. Это не значит, что данные имеют смысл. Давайте добавим проверки для валидации данных. В PostgreSQL 9.3 имеется новый мощный функционал для управления JSON объектами. Есть определенные операторы для типа JSON, которые дадут Вам легкий доступ к полям и значениям. Я буду использовать только оператор "->>", но Вы можете найти больше информации в документации Postgres.
Кроме того, мне необходимо проверять типы полей, включая поле id. Это то, что Postgres просто проверяет из-за определения типов данных. Я буду использовать другой синтаксис для проверок, так как я хочу дать ему имя. Будет намногоп роще искать проблему в конкретной поле, а не по всему огромному JSON документу.
Таблица с ограничениями будет выглядеть следующим образом:
CREATE TABLE emp (
data JSON,
CONSTRAINT validate_id CHECK ((data->>'id')::integer >= 1 AND (data->>'id') IS NOT NULL ),
CONSTRAINT validate_name CHECK (length(data->>'name') > 0 AND (data->>'name') IS NOT NULL )
);
Оператор "->>" позволяет мне извлекать значение из нужного поля JSON'a, проверять существует ли оно и его валидность.
Давайте добавим JSON без описания:
INSERT INTO emp(data) VALUES('{
"id": 1,
"name": "",
"salary": 1.0
}');
--ERROR: new row for relation "emp" violates check constraint "validate_name"
Осталась еще одна проблема. Поля name и id должны быть уникальными. Этого легко добиться следующим образом:
CREATE UNIQUE INDEX ui_emp_id ON emp((data->>'id'));
CREATE UNIQUE INDEX ui_emp_name ON emp((data->>'name'));
Теперь, если попробовать добавить JSON документ в базу, id которого уже содержится в базе, то появится следующая ошибка:
--ERROR: duplicate key value violates unique constraint "ui_emp_id"
--DETAIL: Key ((data ->> 'id'::text))=(1) already exists.
--ERROR: current transaction is aborted, commands ignored until end of transaction block
Производительность
PostgreSQL справляется с самыми требовательными запросами крупнейших страховых компаний, банков, брокерских, государственных учреждений, и оборонных подрядчиков в мире на сегодняшний, равно как и справлялся на протяжении многих лет. Улучшения производительности PostgreSQL непрерывны с ежегодным выпуском версий, и включают в себя улучшения и для его неструктурированных типов данных в том числе.
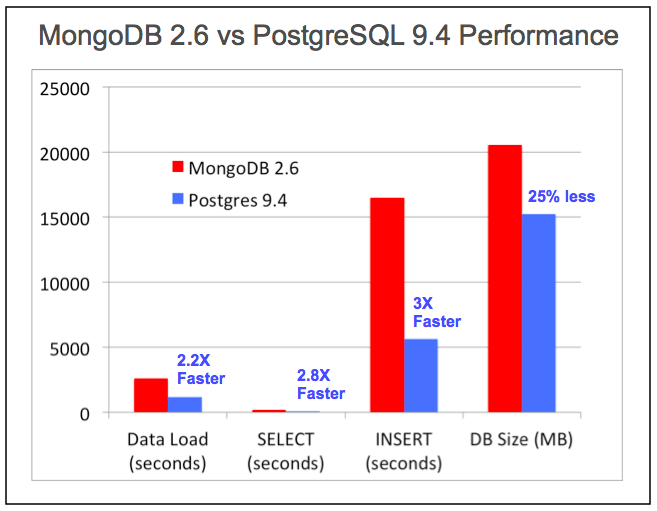
Источник: EnterpriseDB White Paper: Используя возможности NoSQL в Postgres
Чтобы собственноручно испытать производительность NoSQL в PostgreSQL, скачайте pg_nosql_benchmark с GitHub.
Комментарии (70)

ice2heart
09.12.2015 15:40+23Какой интересный тест. Сравнивать новую версию постгреса (postgresql94-9.4beta1-1) и олд стейбл для монги (mongodb-org-2.6.3-1). Ещё неизвестно с каким движком.

the_unbridled_goose
09.12.2015 15:47+2Версия Монги 3.0 вышла 3 марта 2015. Оригинал статьи опубликован 24 февраля 2015.

vitvad
09.12.2015 23:46+8А сегодня вышла MongoDB 3.2 в которой есть «left outer join» организаваный через $lookup в aggregation framework.
Если быть точным то 3.2 для enterprise была доступно еще раньше, сегодня появилась для остальных.
un1t
10.12.2015 09:41+2Круто, глядишь скоро и валадация с транзакциями появится.
un1t
10.12.2015 09:43+2Оу, валидацию уже добавили
docs.mongodb.org/manual/release-notes/3.2/#document-validation
the_unbridled_goose
09.12.2015 15:42Выбирая статью для перевода я понимал, что все кто постоянно использует Монго и очень хорошо относится к ней, воспримут эту информацию в штыки. Тем не менее, в статье не один раз встречается фраза типа «выбрать решение для своих потребностей». У каждой из вышеупомянутых систем есть свои плюсы, равно как и минусы — это вечный спор. А сам факт использования jsonов в Постгрес не может не радовать и не привлекать, хотя бы в качестве эксперимента. Для сравнения, для саморазвития. Тем более, если такое решение подойдет под потребности проекта, на котором преимущественно используется Постгрес.
mugrigoriev
09.12.2015 15:53+11За статью спасибо, саморазвитие — это хорошо, но также неплохо было бы публиковать актуальную информацию.
the_unbridled_goose
09.12.2015 15:57-3Для начала надо чтобы актуальная информация существовала. Свежайшей аналитики еще не видел, увы.
Тем лучше будут видны изменения в более свежей сравнительной характеристике на фоне этой.mugrigoriev
09.12.2015 16:02+8На главной сайта MongoDB, наверное, уже месяц висел алерт «MongoDB 3.2 is coming» с перечислением всех будущих вкусняшек…
Будем ждать свежего, актуального сравнения, чтобы снова накинуться и растерзать автора =)the_unbridled_goose
09.12.2015 16:04Это не побуждало многочисленных авторов такого рода сравнений к написанию чего-то нового. А я, увы и ах, не обладаю достаточным багажом знаний, дабы уместно и правильно сопоставлять и комментировать сходства и различии вышеупомянутых баз.

romario13
09.12.2015 22:56+3Сравнивать нужно для конкретных задач. Сравнивать фичи — дело неблагодарное, бесполезное и холиваное. Тем более без собственного багажа знаний по сравниваемым объектам.
Великую ценность имеют аргументы по использованию нужного инструмента в определенных условиях. Сравнения инструментов в вакууме не несут пользы.
romario13
10.12.2015 00:56+2>У каждой из вышеупомянутых систем есть свои плюсы, равно как и минусы — это вечный спор
Для продуктивного спора нужен контекст а не набор фич.
bormotov
10.12.2015 13:59+1даже можно сказать не «контекст», а набор требований и тестов, которые проверяют метрики, согласно этому набору требований.

maxp
10.12.2015 05:12+5Дело даже не в том. Лично я с удовольствием использую и Монгу и Постгрес, но автор статьи не вникая в суть вопроса пытается строить какие-то таблички с да/нет, которые выглядят в результате притянутыми за уши.
То есть мотив написания статьи примерно такой — «многие люди хвалят Монгу, а я альтернативный чувак, похвалю Постгрес». А в результате фигня получается.

rumkin
10.12.2015 09:22+4Если автор хотел показать альтернативу, то ему нужно было не писать холиварную статью на тему Postgres vs Mongo, а показать как Postgres позволяет решать задачи, которые я сегодня решаю на Mongo, приведя примеры разнообразных операций, свойственных для работы с документами. И желательно не слишком тривиальных примеров.
Общий месседж статьи остался не понятен. Переходить с Mongo на Postgres после этого я не стану, разве что усомнюсь в компетентности сообщества.lega
10.12.2015 10:05+4Вот кстати да, заметил, что многие кто утверждают что postgresql лучше, в процессе разговора выяснялось, что они с монгой либо не знакомы, либо знакомы поверхностно. Так же и с автором jsonb когда он участвовал в радио-т (хоть он и профи в своем деле), утверждал, что сделал «конкурента» монге, но при этом не знал фич монги.
Я около года-двух назад, для себя, делал сравнение — чтобы обновить одно поле json в postgresql, нужно было написать хранимую процедуру которая распаковывала весь json, меняла значение поля, потом запаковывала все обратно. Оно работало неожиданно быстро, но все равно медленней, как минимум, в 10-20 раз чем на монге. barsulka правильно упомянул — где сравнения с обновлением полей, массивов и т.п.? — все то что хорошо работает в монге.
VolCh
10.12.2015 13:12+2Скорее общий мессадж такой:
1. Если вы используете Postgre как РСУБД, но вам нужны фичи, свойственные документным и(или) key-value СУБД, то не спешите думать о переходе (полностью или частично) на них, не изучив возможности Postgre в этой области.
2. Если вы используете Mongo как документную и(или) key-value СУБД, но вам жутко не хватает фич, свойственных РСУБД, то подумайте о переходе на Postgre.
Обобщая: если вам нужны фичи, свойственные как РСУБД, так и документным и(или) key-value СУБД, то Postgre с двумя «режимами» может оказаться лучшим выбором, чем попытки использовать Mongo как РСУБД или использование двух СУБД.

mechkladenets
10.12.2015 13:30В своем проекте-стартапе я решил перейти на Постгрес с Монго, и это при том, что у меня специфика такая, что данные поступают в большом количестве из внешних источников в JSON виде. Что послужило причиной? Я использую Django и начали мы с Монго, т.к. легко потоки данных в него сохранять. Для этого Монго абсолютно устраивала.
НО появились проблемы: Монго достаточно новая, и мало доков по ней и ответов на Stackoverflow, долго разработка идет. Но главное, что решив локально задачу быстрого сохранения данных в json без создания структуры данных в бд, я лишился возможности использовать почти все модули Джанго, т.к. они все предполагают наличие реляционной базы: нет join и тп. А разработка этих модулей или адаптация их под Монго это долгий и сложный процесс, и не факт что получится.
Вот поэтому перешел на Постгре, хотя это может казаться нелогичным: ведь потом данные разрастутся. Конечно, пришлось пожертвовать некоторой частью собираемых данных, т.к. трудно повторить структуру json в базе, но что делать, берем только то, что нужно. Но с 9.5 есть поддержка Nosql и в случае, если это понадобится, легко можно будет переходить постепенно на нее, не меняя при этом базу на другую.

LionAlex
09.12.2015 15:49+18Как-то странно читать статью про Mongo 2.6 на следующий день после релиза 3.2 c left join'ом и валидацией.

Blumfontein
09.12.2015 18:03-9«left join'ом и валидацией»
Шел 2015 год…bormotov
10.12.2015 14:07+7В каком году можно будет за 15 минут работы руками развернуть кластер postgresql на шести узлах, в котором данные шардятся на 6 частей, при этом пятикратное резервирование?
А еще, одним нажатием кнопки обновлять postgresql 9.5 до 9.6 на всех узлах, без остановки работы кластера?
Ок, это вопрос про горизонтальное масштабирование, видимо ниже пояса. Скажите, в каком году будет удобный инструмент для table partitioning? Судя по www.postgresql.org/docs/current/interactive/ddl-partitioning.html в том же 2015 году мне всё еще предлагают этим заниматься руками, писать самому триггеры и вот это всё.



barsulka
09.12.2015 16:09+22Программирование на стороне сервера | Нет
Доступность обучающих ресурсов | Трудно найти
Вы меня простите, но это не сравнение, а ерунда с запахом холивара.
Кроме того, как и в других подобных статьях, тут ловко обходят стороной такую операцию, как «update одного значения в документе».


Infanty
09.12.2015 16:48+2Судя по тестам mongodb 2.6 vs 3, версия 3 mongodb должна отставать не более чем в полтора раза, это гораздо менее страшно, чем в 3 раза с mongodb 2.6. Такими темпами скоро её можно будет не брать во внимание. Если бы в Postgres NoSQL появился бы лет 5 назад…

SirEdvin
09.12.2015 23:07+6Очень странно видеть такие пункты как:
Доступность обучающих ресурсов
Легче найти обучения для postgresql, чем для mongodb?
Для mongodb все знают доступный и бесплатный официальный MOOC, а что там есть для postgresql… Ах да, сразу сертификации от EnterpriseDB с ценами от 200$.
Даже сложно определить, что доступнее…
Простая интеграция с другими источниками данных
То есть, эта таблица утверждает, что цепочка:
Получил данные в JSON -> запихнул их в mongodb
сложнее чем:
разработал схему таблиц для конкретного случая -> получил данные и собрал из них запрос (каким-то образом отложив невалидные и пустые данные) -> выполнил sql запрос
Если тут идется про существующие инструменты, то строчку стоило назвать по другому.
К тому же, тогда первый столбик уже давно устарел.VolCh
10.12.2015 08:18+2сложнее чем:
В последнее время всё чаще применяем при начале разработке схему: для новой сущности создаём таблицу с двумя полями: id uuid и raw_data jsonb и запихиваем туда данные. По сути полный аналог коллекций однотипных документов в NoSQL. Дальше по ходу дела анализируем юзкейсы и или часть полей дублируем в новых столбцах возможно в новых таблицах, заполняя их в приложении, а то и в insert/update триггерах, или накладываем индексы и ограничения прямо на jsonb, или тупо оставляем, если значения определенных полей нужны бизнесу только «на посмотреть» — они не участвуют в бизнес-логике приложения, нужны только операторам для принятия решений с неформализованными алгоритмами.
lega
10.12.2015 10:16+1часть полей дублируем в новых столбцах возможно в новых таблицах, заполняя их в приложении
При этом вы переписываете приложение (на новые поля), или за вас это делает orm?
Ведь хранить «перенесенные» поля в json смысла нет, а то и вредно если разойдутся с таблицей.
Какие есть подводные камни такого подхода? Интересуюсь, на случай если мне понадобится posgresql в проекте.VolCh
10.12.2015 13:35Ближе к переписыванию ORM, чем приложения. При желании интерфейсы объектов модели можно оставлять без изменений, типа get('some_property') или set('some_property'), но обычно сначала происходит такое изменение интерфейса, а лишь потом выделение столбцов на уровне базы данных.
Мы храним, даже если все поля перенесены. По разным причинам, в том числе оптимизация вывода сущностей в API и хранение ввода API как лога. Некоторая денормализация есть конечно, но в одних случаях можно вообще забить, в других достаточно периодических проверок/исправлений, в третьих — проверка при вставке-обновлении в пре-триггерах или констрэйтах. Но как показывает практика, обычно расхождения возникают только при лазании в базу «ручками».
AxVPast
10.12.2015 01:09+5Тут уже есть красивая статья про то как народ с Монго в Постгресс слезал.
В реальности из постгресса получается шикарное монго. Код выглядит где-то так:
const mainFilelds = {
id: true, time: true, user: true
};
function flatToSql( obj ){
var o = { other: {} };
_.each( obj, function (val, key){
if( mainFilelds[key] ){
o[key] = val;
} else {
o.other[key] = val;
}
});
return o;
}
+ соответсвующая обратная операция.
Дальше для хранения поля other используем JSONB, то что не в other ключевые поля которые индексируются и участвуют активно в запросах. Дальше для сохранения/чтения используем удобную ORM прослойку.
Да и самое интересное в Монго хранили порядка 2х миллиардов записей, база занимала 6ТБ и постоянно глючила (любимое развлечение мастера поссориться со слейвом или грохнуть индекс и начать переиндекасацию всего). После того, как перенесли в постгресс… получили 300ГБ и полное отсутствие необъяснимых проблем.
lazant
10.12.2015 12:30+2А как насчет поиска по JSON полям в Postgresql? Мне кажется тут с Монгой тягаться сложно.

voidnugget
10.12.2015 13:37+1Есть полнотекстовый поиск и GIN индекс — они себя обычно ведут шустрее простого B-tree.
Если почитать прошлогодний https://www.pgcon.org/2014/schedule/events/696.en.html CREATE INDEX… USING VODKA, то это в принципе должно быть очевидно.
Если читать внимательно хабр, недавно выходила серия (4шт) хороших статей от the_unbridled_goose о специфике разработки документ-ориентированного API на PostgreSQL.lazant
10.12.2015 13:45+2Есть чего-то похожее на docs.mongodb.org/manual/reference/operator/query?
voidnugget
10.12.2015 14:29Если почитать офф доки PostgreSQL'я http://www.postgresql.org/docs/9.5/static/functions-json.html
То станет понятно что там происходит ручная распаковка jsonb в один из существующих типов, можно даже в табличку или в представление, после чего можно выполнять любые доступные запросы.lazant
10.12.2015 15:07+1Давайте конкретно
JSON
'{«a»:«foo», «c»:{«d»:30}, «b»:«bar»}'
Напишите, пожалуйста, запрос, который вернет boolean значение истинно ли утверждение что c.d>30?
chersanya
10.12.2015 18:18А в чём проблема-то, вы на приведённые доки смотрели вообще? Будет что-то вроде
(obj#>>'{c,d}')::int > 30
где obj — название поля в таблице, где этот json лежит.
voidnugget
10.12.2015 13:26-2Бэнчмарк чуть морально устарел, уже есть MongoDB 3.2, c нормальным MVCC.
Горизонтальное масштабирование у MongoDB это большой и толстый кот в мешке, с кучей заморочек, и их не меньше чем у PostgreSQL'я.
По производительности на одну ноду, понятное дело, лидирует PostgreSQL.
Мне вот один товарищ с пеной изо рта пытался доказать что MongoDB это «нереляционная, документо-ориентированная БД» — если бы это было бы действительно так, то в ней бы не использовался банальный B-tree индекс и она не подчинялась бы всем существующим правилам нормализации. По этому разводить документо-ориентированный трёп нет особо то и смысла — это выдуманное понятие, не более чем маркетинговый трюк для привлечения инвестиций.
Нужно понимать что MongoDB строилась по принципу: мы придумаем много новых умных слов, скажем что, мол, такие все инновационные NoSQL подонки, и пофигу что оно нифига не работает, — на нас ведь посыпется дождик вечнозелёных от наивных инвесторов, потом может когда-то починим, если будут громко орать и пускать лучи ненависти. И да, чинят, на самом деле, очень неохотно.
Извините, если оскорбил чувства свято верующих в бесконечное и неосязаемое величие MongoDB, считаю что пора вам спускаться на землю.rumkin
10.12.2015 15:26+7Вот интересно! Как это использование B-tree автоматически делает базу реляционной?
Документарные базы не отменяют необходимость нормализации для создания отношений, как и сами отношения. Суть в том поддерживается ли реляционная модель на уровне движка.
А MongoDB строилась по принципу хранения документов с произвольной структурой с использованием JS и v8.
Я бы советовал вам для начала разобраться в понятиях прежде чем советовать другим спускаться на землю.voidnugget
10.12.2015 15:50-5Потому что B-tree, по определению, хранит ключи которые определяют отношение между существующими сущностями, это помогает получить неглубокое дерево, первые 2-3 три уровня ключей которого могут хранится в оперативке, а остальные на винте. Что собственно позволяет значительно уменьшить количество дисковых операций. Ещё там фигурируют разнообразные cache-oblivious вещи, но это уже тема отдельной статьи.
Так как информация которую хранит B-tree априори требует определения отношений между существующими сущностями — любую СУБД, которая использует его для индексации, можно назвать реляционной.
Если сравнивать с другими структурами, типа lsm-tree(sstable) / R-tree / X-tree / MVP-tree / Fusion-tree, то у них совсем другие задачи, они не хранят отношений и их ключи используются сугубо для адресации. Соответственно их использование совсем не связано с реляционными моделями.VolCh
10.12.2015 20:09+3Потому что B-tree, по определению, хранит ключи которые определяют отношение между существующими сущностями
Можно с таким определением ознакомиться?
maxp
11.12.2015 06:52+6Как это внезапно алгоритм (b-tree) для доступа к записи на двух сильно отличающихся по скорости средах (ram/disk) вдруг стал напрямую связан с отношениями между сущностями?
voidnugget
11.12.2015 18:59-2Я думаю мне бесполезно писать о том как формируется иерархия ключей Б-дерева на основе существующих отношений схемы БД.
voidnugget
11.12.2015 15:11-3https://ru.wikipedia.org/wiki/B-дерево
B-дерево может применяться для структурирования (индексирования) информации на жёстком диске (как правило, метаданных). Время доступа к произвольному блоку на жёстком диске очень велико (порядка миллисекунд), поскольку оно определяется скоростью вращения диска и перемещения головок. Поэтому важно уменьшить количество узлов, просматриваемых при каждой операции. Использование поиска по списку каждый раз для нахождения случайного блока могло бы привести к чрезмерному количеству обращений к диску, вследствие необходимости осуществления последовательного прохода по всем его элементам, предшествующим заданному; тогда как поиск в B-дереве, благодаря свойствам сбалансированности и высокой ветвистости, позволяет значительно сократить количество таких операций.
Может стоит научится читать, хотя бы википедию?
deniskreshikhin
Тогда почему нет строчки типа:
Документно-ориентированная Да Нет
hummerd
А что значит документно-ориентированная?
Есть строчка «Поддержка общих форматов данных (MongoDB) JSON (Document), Key-Value, XML — (Postgres) JSON (Document), Key-Value, XML». Или вы что-то большее вкладываете в это понятие?
deniskreshikhin
В английской вики есть исчерпывающее объяснение.
Relational databases are strongly typed during database creation, and store repeated data in separate tables that are defined by the programmer. In an RDB, every instance of data has the same format as every other, and changing that format is generally difficult.
Document databases get their type information from the data itself, normally store all related information together, and allow every instance of data to be different from any other. This makes them more flexible in dealing with change and optional values, maps more easily into program objects, and often reduces database size.
Опять же поддержка JSON в Postgres не на таком уровне как в Mongo, т.к. это всего лишь особенное поле со специальными свойствами и ограниченным количеством операторов www.postgresql.org/docs/9.5/static/functions-json.html которые выбиваются из общей концепции запросов в реляционных базах данных.
Другими словами, в MongoDB имея коллекцию типа:
Можно сделать запрос
И получить всех пользователей которые сделали заказ более чем на 1000. В Postgres это все нужно вытащить из JSON в поля, что бы можно было сделать SELECT запрос с оператором >.
hell0w0rd
Гм, да, вы обвиняете Postgres в том что он строго типизированный. В общем случае это скорее плюс, нежели минус.
deniskreshikhin
Хорошо, и как увеличить эту сумму в два раза таким же образом у всех пользователей?
chersanya
Есть функция jsonb_set: www.postgresql.org/docs/9.5/static/functions-json.html. Правда только начиная с 9.5.
deniskreshikhin
Даже если бы такая функция была бы сейчас, эта практика не соответствует общепринятому подходу при проектировании БД на Postgres.
Если разработчик решит закомитить в Postgres проект с миграциями и всем таким, что-нибудь стиле`select * from users where (order->>'total')::int > 1000;` то его очевидно будут бить, возможно даже ногами. Т.к. общепринятый подход — все значимые с позиции бизнес логики поля добавлять в схему.
В MongoDB обращение к подполям, к встроенным документам и т.п. это общепринятая практика, т.к. Document databases get their type information from the data itself… this makes them more flexible in dealing with change and optional values
VolCh
Это общепринятый для реляционных баз данных. Начиная использовать документные возможности Postgre, мы должны использовать и новые подходы, иначе в большинстве случаев не стоит и заморачиваться.
Да и вообще, документные поля введены скорее как замена EAV-костылей, чем основных схем, где даже Null значение имеет семантику бОльшую чем «пользователь оставил поле пустым»
deniskreshikhin
Там где это действительно нужно, я думаю должны действительно использоваться документные поля.
Речь же шла о том, что есть разница между реляционными (или объектно-реляционными как позиционируется postgres) базами данными и документно-ориентированными. То что общепринято в первых, не общепринято во вторых. И наоборот.
VolCh
Ну так Postgre уже по факту реляционно-объектно-документная база. В нём общепринято должно быть и то, и другое в зависимости от контекста использования.
chersanya
Вы так говорите, как будто это что-то плохое :) Да, обычная практика для реляционных баз такая, но ведь никто не мешает хранить данные в json, если это имеет смысл. В postgres есть нужные возможности для обоих случаев — и для фиксированной схемы, и для «все данные в json», что только добавляет гибкости. Ниже вон писали, что успешно использовали postgres как json-хранилище безо всяких проблем.
Что же касается «если бы такая функция была сейчас», то она уже есть, хотя и в бета-версии. По надёжности бета-версия постгреса явно обойдёт стабильную монгу :)
deniskreshikhin
Я не говорил что это плохо) Просто один подход реляционных, другой документно-ориентированный. Postgres позиционируется в основном как реляционная БД (или объектно-реляционная).
Лично я когда работал в проектах с Postgres, то сталкивался с тем, что команды этих проектов защищали реляционность как священную корову. Возможно есть команды, которые действительно воспринимают Postgres в более широком плане.
В общем-то странная ветка получилось, началось все с вопроса «а что такое документно-ориентированная бд», а закончилось что все рассказывают что в Postgres документные возможности не хуже чем в MongoDB.
VolCh
Хуже. Но, во-первых, есть надежда, что Постгри будет догонять Монгу в этом плане, а, во-вторых, далеко не всегда нужна полноценная работа с документной частью записей, типа быстрого обновления конкретного поля.
Regis
Немного оффтоп: а вы уверены, что хотите сделать такую операцию по изменению данных, при то том что вам не гарантируется атомарность её исполнения и в случае ошибки у вас нет возможности определить, к каким записям в базе она была применена, а к каким нет? )
deniskreshikhin
Не скажу за всех, но на практике я делаю так.
Если потеря информации не критична, то смиряюсь с этим.
Если это действительно критичная информация (баланс, оплата и все такое), то я завожу поле вроде payment_history, balance_history. Поэтому если что-то накрывается, можно всегда проследить что именно накрылось и когда автоматически.
Т.е. если вы у пользователя что-то списываете, то он в любом случае должен это знать. Поэтому неплохо бы в его модели иметь историю операций. Соответственно если какая-то операция не сработает, то можно это устранить автоматически.
VolCh
Неплохо бы в его модели иметь не историю операций для проверки баланса, а баланс, агрегируемый из операций :)
OnYourLips
Документно-ориентированная Да Да
deniskreshikhin
habrahabr.ru/post/272735/#comment_8683893