В наших проектах нам приходится решать различные задачи. Для решения некоторых из них мы используем dynamic T-Sql (далее по тексту dynamic sql).
Для чего нужен dynamic sql? Каждый решает для себя. В одном из проектов с помощью dynamic sql мы решили задачи построения динамичных отчетов, в других — миграцию данных. Также dynamic sql незаменим в случаях, когда требуется создать/изменить/получить данные или объекты, но значения/названия приходят в качестве параметров. Да, это может показаться абсурдом, но есть и такие задачи.

Дальше мы покажем несколько примеров, как это можно реализовать с помощью dynamic sql.
Выполнить динамическую команду можно несколькими способами:
Данные способы отличаются между собой кардинально. На небольшом примере мы постараемся пояснить, чем они отличаются.
Как видно из запроса выше, мы формируем динамическую команду. Если выполнить
Что же тут плохого? — Запрос отработает, и все будут довольны. Но все же, есть несколько причин, почему так делать не стоит:
Что изменится при использовании
Что же изменилось?
Для обоих подходов планы запросов кэшируются, но они отличаются. Эти отличия приведены на рисунке 1 и рисунке 2.
Также одно из преимуществ использования
Далее приведем пример, как мы решили одну из проблем в проекте с использованием dynamic sql.
Допустим, у нас есть товар (да неважно, собственно, что это: товар, анкета на должность, персональная анкета). Смысл в том, что каждый объект имеет свой набор свойств (атрибутов), который его характеризует, а их может быть разное количество, и они будут разного типа. Как хранить в БД – это проблема архитектуры.
Для клиента нужен был отчет, который из себя представлял n строк на m столбцов. Где m и был наш набор атрибутов. Отчет собирался по группе объектов или для какого-то объекта из группы. Но смысл остается все тот же: каждый отчет содержит разное количество столбцов для каждой группы объектов.
Поскольку изначально существовала связь между объектами, то решение проблемы выбрали без изменения архитектуры БД. На наш взгляд, решений данной проблемы может быть несколько:
Ссылка на скрипты для создания таблиц и запроса.
В основе отчета будет лежать обычный запрос:
Давайте рассмотрим, что же мы тут написали:
Для чего нужен dynamic sql? Каждый решает для себя. В одном из проектов с помощью dynamic sql мы решили задачи построения динамичных отчетов, в других — миграцию данных. Также dynamic sql незаменим в случаях, когда требуется создать/изменить/получить данные или объекты, но значения/названия приходят в качестве параметров. Да, это может показаться абсурдом, но есть и такие задачи.
Дальше мы покажем несколько примеров, как это можно реализовать с помощью dynamic sql.
Выполнить динамическую команду можно несколькими способами:
- С использование ключевого слова
EXEC/EXECUTE; - C использование хранимой процедуры
sp_executesql
Данные способы отличаются между собой кардинально. На небольшом примере мы постараемся пояснить, чем они отличаются.
Пример кода с EXEC/EXECUTE
DECLARE @sql varchar(1000)
DECLARE @columnList varchar(75)
DECLARE @city varchar(75)
SET @columnList = 'CustomerID, ContactName, City'
SET @city = 'London'
SELECT @sql = ' SELECT CustomerID, ContactName, City ' +
' FROM dbo.customers WHERE 1 = 1 '
SELECT @sql = @sql + ' AND City LIKE ''' + @city + ''''
EXEC (@sql)
Как видно из запроса выше, мы формируем динамическую команду. Если выполнить
select @sql, то результат будет следующий: SELECT CustomerID, ContactName, City FROM customers WHERE City = 'London'
Что же тут плохого? — Запрос отработает, и все будут довольны. Но все же, есть несколько причин, почему так делать не стоит:
- При написании команды очень легко ошибиться с количеством «’», т.к. необходимо указывать дополнительные «’», чтобы передать текстовое значение в запрос.
- При таком запросе возможны Sql инъекции (SQL Injection). Например, стоит задать значение для
@cityвроде такого
— и результат будет печальный, т.к. операцияset @city = '''DROP TABLE customers--'''selectвыполнится успешно, как и операцияDROP TABLE customers. - Возможна ситуация, когда у вас будет несколько переменных, содержащих коды ваших команд. Что-то типа такой
EXEC(@sql1 + @sql2 + @sql3).
Какие трудности могут возникнуть тут?
Нужно помнить, что каждая команда отработает отдельно, хотя на первый взгляд, может показаться, что будет выполнена операция конкатенации(@sql1 + @sql2 + @sql3), а затем выполнится общая команда. Также нужно помнить, что накладывается общее ограничение на параметр команды EXEC в 4000 символов. - Происходит неявное приведение типов, т.к. параметры передаются в виде строки.
Что изменится при использовании
sp_executesql? – Разработчику проще писать код и его отлаживать, т.к. код будет написан практически как обычный Sql запрос.Пример кода с sp_executesql
DECLARE @sqlCommand varchar (1000)
DECLARE @columnList varchar (75)
DECLARE @city varchar (75)
SET @city = 'London'
SET @sqlCommand = 'SELECT CustomerID, ContactName, City FROM customers WHERE City = @city'
EXECUTE sp_executesql @sqlCommand, N'@city nvarchar(75)', @city = @city
Что же изменилось?
- В отличие от
EXECUTEпри использованииsp_executesql, не нужно никакое приведение типов, если мы используем типизированные параметрыsp_executesql. - Это решает проблему с дополнительными «’».
- Решается проблема безопасности — Sql инъекции (SQL Injection).
Для обоих подходов планы запросов кэшируются, но они отличаются. Эти отличия приведены на рисунке 1 и рисунке 2.
Получение плана запроса
SELECT q.TEXT,cp.usecounts,cp.objtype,p.*, q.*, cp.plan_handle
FROM
sys.dm_exec_cached_plans cp
CROSS apply sys.dm_exec_query_plan(cp.plan_handle) p
CROSS apply sys.dm_exec_sql_text(cp.plan_handle) AS q
WHERE
q.TEXT NOT LIKE '%sys.dm_exec_cached_plans %'
and cp.cacheobjtype = 'Compiled Plan'
AND q.TEXT LIKE '%customers%'
План запрос при использование Exec
План запроса при использовании sp_executesql
Также одно из преимуществ использования
sp_executesql – это возможность возвращать значение через OUT параметр.Далее приведем пример, как мы решили одну из проблем в проекте с использованием dynamic sql.
Допустим, у нас есть товар (да неважно, собственно, что это: товар, анкета на должность, персональная анкета). Смысл в том, что каждый объект имеет свой набор свойств (атрибутов), который его характеризует, а их может быть разное количество, и они будут разного типа. Как хранить в БД – это проблема архитектуры.
Для клиента нужен был отчет, который из себя представлял n строк на m столбцов. Где m и был наш набор атрибутов. Отчет собирался по группе объектов или для какого-то объекта из группы. Но смысл остается все тот же: каждый отчет содержит разное количество столбцов для каждой группы объектов.
Поскольку изначально существовала связь между объектами, то решение проблемы выбрали без изменения архитектуры БД. На наш взгляд, решений данной проблемы может быть несколько:
- Использовать систему отчетности, например, MS Sql Reporting Service. Создать матричный отчет, а в качестве запроса у нас будет «простой»
Select. Почему мы так не сделали? В проекте не так много было отчетов, чтобы внедрять туда SSRS. - Использовать тот же «простой»
selectи на серверной стороне уже создавать DataSet необходимой «формы». Да, так задача была решена изначально, когда данных о товарах было очень мало. Как только данных стало достаточно много, то время сбора отчета стало выходит за установленный timeout. - Использовать
Pivotв sql. Да, отличное решение, когда вы знаете, что у вас только эти атрибуты, и новых не будет. А что делать, когда количество атрибутов часто меняется. И опять же, для каждой группы объектов у нас свой набор атрибутов, мы снова вернемся к созданию процедуры для каждой группы объектов. Не очень удобное решение, не правда ли? - А если использовать Pivot, но добавить туда немного dynamic sql? – Да, это решение, которое имеет право на жизнь. Его мы и опишем, как пример использования dynamic sql…
Ссылка на скрипты для создания таблиц и запроса.
В основе отчета будет лежать обычный запрос:
Основной код для отчета
SELECT p.Id as ProductID,
p.Name as [Наименование],
pcp.Name as PropertiesName,
vpp.Value as Value
FROM dbo.Products p
INNER JOIN dbo.PropertiesCategoryOfProducts pcp ON pcp.CategoryOfProductsId = p.CategoryOfProductsId
INNER JOIN dbo.ValueOfProductProperty vpp ON vpp.ProductID = p.Id
and vpp.PropertiesCategoryOfProductsId = pcp.Id
where p.CategoryOfProductsId = @CategoryOfProductsId
Код запроса для построения отчета
SELECT p.Id as ProductID,
p.Name as [Наименование],
pcp.Name as PropertiesName,
vpp.Value as Value
FROM dbo.Products p
INNER JOIN dbo.PropertiesCategoryOfProducts pcp ON pcp.CategoryOfProductsId = p.CategoryOfProductsId
INNER JOIN dbo.ValueOfProductProperty vpp ON vpp.ProductID = p.Id
and vpp.PropertiesCategoryOfProductsId = pcp.Id
where p.CategoryOfProductsId = @CategoryOfProductsId
Код запроса для построения отчета
declare @CategoryOfProductsId int = 1
declare @PivotColumnHeaders nvarchar(max)=
REVERSE(STUFF(REVERSE((select '[' + Name + ']' + ',' as 'data()'
from dbo.PropertiesCategoryOfProducts t
where t.CategoryOfProductsId = @CategoryOfProductsId
FOR XML PATH('')
)),1,1,''))
if(@PivotColumnHeaders>'')
declare @PivotTableSQL nvarchar(max)
BEGIN
SET @PivotTableSQL = N'
SELECT *
from (SELECT p.Id as ProductID,
p.Name as [Наименование],
pcp.Name as PropertiesName,
vpp.Value as Value
FROM dbo.Products p
INNER JOIN dbo.PropertiesCategoryOfProducts pcp ON pcp.CategoryOfProductsId = p.CategoryOfProductsId
INNER JOIN dbo.ValueOfProductProperty vpp ON vpp.ProductID = p.Id
and vpp.PropertiesCategoryOfProductsId = pcp.Id
where p.CategoryOfProductsId = @CategoryOfProductsId
) as Pivot_Data
PIVOT (
MIN(Value)
FOR PropertiesName IN (
' + @PivotColumnHeaders + '
)
) AS PivotTable
'
EXECUTE sp_executesql @PivotTableSQL, N'@CategoryOfProductsId int', @CategoryOfProductsId = @CategoryOfProductsId;
END
Давайте рассмотрим, что же мы тут написали:
- Инициализируем переменную со значением нашей категории товаров —
declare @CategoryOfProductsId int = 1 - Далее нам нужно получить список колонок для нашей категории товаров, но при этом они должны быть заключены в “[]” скобки и перечислены через “,” как этого требует синтаксис функции
Pivot—
Получение списка колонок для категории товаровdeclare @PivotColumnHeaders nvarchar(max)= REVERSE(STUFF(REVERSE((select '[' + Name + ']' + ',' as 'data()' from dbo.PropertiesCategoryOfProducts t where t.CategoryOfProductsId = @CategoryOfProductsId FOR XML PATH('') )),1,1,''))
Ну а дальше все просто: при выполнении кода список колонок для функцииPivotбудет подставлен из@PivotColumnHeaders
Если выполнитьselect @PivotTableSQL, то мы получим тот запрос, который без использования dynamic sql нам бы пришлось писать вручную.
Результатом выполнения данного запроса будет отчет такого вида:
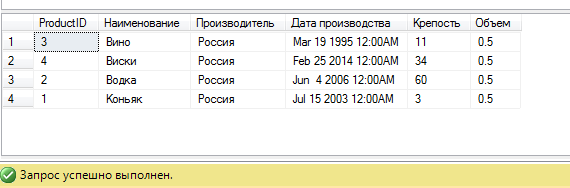
В заключение стоит еще раз отметить используя dynamic sql, мы можем решать на первый взгляд нетривиальные задачи тривиальными способами. Для этого порой требуется посмотреть на проблему с другой стороны.
Комментарии (7)

AlanDenton
10.12.2015 13:28+3Для обоих подходов планы запросов кэшируются, но они отличаются.
Не хватает слова «параметризация», чтобы неподготовленные читатели смогли увидеть фундаментальную разницу. Вот хороший пример:
USE AdventureWorks2012 GO DBCC FREEPROCCACHE DECLARE @str VARCHAR(MAX) = 'SELECT * FROM Person.Person WHERE FirstName = ' , @param VARCHAR(50) = 'David' EXEC (@str + '''' + @param + '''') SET @param = 'Tom' EXEC (@str + '''' + @param + '''') SELECT st.[text], cp.plan_handle FROM sys.dm_exec_cached_plans cp CROSS APPLY sys.dm_exec_sql_text(cp.plan_handle) st WHERE st.[text] LIKE '%SELECT * FROM Person.Person%' AND st.[text] NOT LIKE '%select st.text%' GO DBCC FREEPROCCACHE EXEC sys.sp_executesql N'SELECT * FROM Person.Person WHERE FirstName = @val', N'@val VARCHAR(200)', 'David' EXEC sys.sp_executesql N'SELECT * FROM Person.Person WHERE FirstName = @val', N'@val VARCHAR(200)', 'Tom' SELECT st.[text], cp.plan_handle FROM sys.dm_exec_cached_plans cp CROSS APPLY sys.dm_exec_sql_text(cp.plan_handle) st WHERE st.[text] LIKE '%SELECT * FROM Person.Person%' AND st.[text] NOT LIKE '%select st.text%'
Если кратко, то когда параметризации нет (пример EXEC), с каждым новым значением параметра будет свой план генерироваться:
text plan_handle ------------------------------------------------------------ ---------------------------------------------- SELECT * FROM Person.Person WHERE FirstName = 'Tom' 0x06000B00CA31691380824B12020000000100000000 SELECT * FROM Person.Person WHERE FirstName = 'David' 0x06000B007BF4203740804B12020000000100000000
и когда параметризация есть (один план на «все случаи жизни», который формируется на основе значений при первом выполнении):
text plan_handle --------------------------------------------------------------------------- ---------------------------------------- (@val VARCHAR(200))SELECT * FROM Person.Person WHERE FirstName = @val 0x06000B00632CDD0440804B12020000000100
Такие вот нюансы сильно на производительность влияют.AlanDenton
10.12.2015 14:19+1Первый коммент слишком рано нажал опубликовать… Еще не хватает сказать про Parameter Sniffing, который при использовании sp_executesql может снижать производительность. Когда у нас на каждый запрос свой план выполнения создается:
DBCC FREEPROCCACHE SET STATISTICS IO ON SELECT * FROM Person.[Address] WHERE City = 'Bothell' SELECT * FROM Person.[Address] WHERE City = 'Seattle'
то все хорошо:
(26 row(s) affected) Table 'Address'. Scan count 1, logical reads 268, ... (141 row(s) affected) Table 'Address'. Scan count 1, logical reads 346, ...
А теперь ситуация из жизни. По первому запросу построился оптимальный план — проблем нет. При запуске второго запроса значение параметра другое, но план используется от первого:
DBCC FREEPROCCACHE SET STATISTICS IO ON EXEC sys.sp_executesql N'SELECT * FROM Person.[Address] WHERE City = @val', N'@val VARCHAR(200)', 'Bothell' EXEC sys.sp_executesql N'SELECT * FROM Person.[Address] WHERE City = @val', N'@val VARCHAR(200)', 'Seattle'
что может сильно портить жизнь в реальной жизни:
(26 row(s) affected) Table 'Address'. Scan count 1, logical reads 268, ... (141 row(s) affected) Table 'Address'. Scan count 1, logical reads 498, ... логических чтений больше
Лучшее, что я читал про Parameter Sniffing:
aboutsqlserver.com/2014/08/05/plan-cache-parameter-sniffing
Это все что я хотел сказать. Спасибо Вам за пост.
akotelevets
10.12.2015 14:27Спасибо Вам за отличные дополнения. Хотя Parameter Sniffing проблема актуально, не только для запрос dynamic sql. Такая же проблема существует и для хранимых процедур.

pportnoy
10.12.2015 17:29Судя по структуре БД, предоставленной в запросе, есть таблица с продуктами, таблица со справочником различных параметров для продукта, и таблица со значениями параметров.
Вопрос: а куда делся вариант с CROSS APPLY + UNPIVOT? Мне почему-то кажется, что он будет значительно быстрее чем вариант с Dynamic SQL.
BelAnt
Внедрение SSRS занимает не так много времени, но даёт много доп. возможностей — подписки на отчеты, выгрузку в разных форматах и т.п. Плюс пользователи смогут самостоятельно задавать параметры для отчета (выбирать группу объектов).
Со временем количество отчетов будет только расти, потратив время сейчас вы сэкономите его в будущем.
akotelevets
Конечное решение принимали не мы, клиенту довели досведения все возможные решения