Сегодня я расскажу о не совсем простой концепции быстрого (до часа после нескольких тренировок) развёртывания проекта для работы команды, состоящей как минимум из отдельных фронтенд и бэкенд разработчиков.
Исходные данные у нас такие: начинается разработка проекта, в которой планируется «тонкий бэкенд». Т.е. бэк у нас состоит из закешированных страниц (рендерятся любым шаблонизатором), объёмных моделей с сопутствующей логикой (ORM) и REST API, выполняющего роль контроллера. Фактически, View в такой системе редуцировано и вынесено в JS, благо есть разные реакты, ангуляры и прочие вещи, которые позволяют фронтендщикам считать себя «белыми людьми».
Среда разработки у нас выглядит так: Ubuntu LTS (14.04), PyCharm, Python любой версии (мы возьмём 2.7 для запуска виртуальной среды, на которой будет стоять аналогичная версия). Django (1.8)
Решаем мы следующие проблемы:
- Необходимо полностью эмулировать пространство Production, а ещё лучше — поставлять код участникам процесса разработки вместе со средой.
- Необходимо отделить среду выполнения нашего проекта от среды операционной системы. Нам нафиг не нужны проблемы с версиями пайтона, настройками node.js или развёртыванием БД. Пусть наша настольная система будет чистой и светлой.
- Необходимо автоматизировать развёртывание проекта, над которым будет трудиться ещё и гуру JS, и, возможно, крутой верстальщик. Да так, чтобы проект можно было поднять и у тестировщика, и у менеджера с начальными знаниями в технической области.
- Необходимо без особых проблем отделить dev версию от production. Даунтайм должен быть минимальным. Никто не будет ждать, пока ведущий программист исправит все переменные в settings и пофиксит прочие проблемы.
- Нужно сделать так, чтобы участники разработки не решали проблемы друг-друга. JS разработчик не должен вникать в тонкости запуска Celery, слияния JS файлов и т.д. Верстальщика не должно интересовать что компилирует его Sass код и т.д. Это относится к автоматизации развёртывания, но важно подчеркнуть, что эти проблемы могут создать неудобство и потребуется тратить время на написание подробной инструкции по развёртыванию, если оно будет происходить в ручном режиме.
Установка Docker
Для нашего приложения мы будем использовать Docker. Об этом инструменте на Хабре сказано много. Сразу оговорюсь, что мы пока не планируем усложнять Production сервер. Нам важно построить среду разработки с заделом на последующее применение концепции CI. Но, в рамках текущей статьи будем работать только с docker-compose и не затронем методы быстрого деплоймента. Благо, у Docker таковых имеется в избытке.
Docker может с переменным успехом устанавливаться на Mac и Windows машины. Но мы рассмотрим его установку на Ubuntu 14.04. Есть инструкция по установке Docker на этой системе, но она может вызвать проблемы. От части, можно списать их на нотик из этой инструкции:
Note: Ubuntu Utopic 14.10 exists in Docker’s apt repository but it is no longer officially supported.
Поэтому, не выпендриваемся и ставим так, как рекомендует другая инструкция:
$ sudo apt-get update
$ sudo apt-get install wget
wget -qO- https://get.docker.com/ | sh
И проверяем установку командой:
$ docker run hello-world
Теперь создадим виртуальную среду для запуска Docker:
$ mkdir ~/venvs
$ virtualenv ~/venvs/docker
$ source ~/venvs/docker/bin/activate
(docker) $ pip install docker-compose
(docker) $ docker-compose -v
Создаём проект
Откроем PyCharm и создадим проект для работы.

Проект создаём для любого интерпретатора. Пусть это будет pure python проект. На схеме выше вы видите минимальный состав проекта. За запуск сервера у нас будет отвечать supervisord. Файлы .gitignore и .dockerignore позволят указать те файлы, которые не будут закоммичены в репозиторий проекта или не будут смонтированы в docker контейнеры. Контейнерами будет управлять файл docker-compose.yml, поскольку он прост как палка и эффективен как автомат Калашникова. Для основного проекта мы дополнительно создадим Dockerfile, чтобы установить отсутствующие библиотеки.
Папка dockerfiles имеет подпапку pgdata — в ней у нас будет храниться БД от PostgreSQL на случай, если мы захотим перенести данные из одного места в другое. В dockerfiles/sshdconf поместим настройки для SSH сервера. Для прямого соединения он нам не понадобится, но для настройки окружения в PyCharm — ещё как. Ключ id_rsa.pub позволит PyCharm соединяться с контейнером без плясок вокруг пароля. Всё что вам нужно — это создать связку SSH ключей и скопировать (или перенести) публичный ключ в директорию dockerfiles.
Директория src — корень нашего проекта. Сейчас наша задача — развернуть контейнеры.
Создаём контейнеры
Файл docker-compose.yml будет у нас выглядеть так:
postgresql:
image: postgres:9.3
env_file: .env
volumes:
- ./dockerfiles/pgdata:/var/lib/postgresql/data/pgdata
ports:
- "5433:5432"
project:
build: ./
env_file: .env
working_dir: /opt/project
command: bash -c "sleep 3 && /etc/init.d/ssh start && supervisord -n"
volumes:
- ./src:/opt/project
- ./dockerfiles/sshdconf/sshd_config:/etc/ssh/sshd_config
- ./dockerfiles/id_rsa.pub:/root/.ssh/authorized_keys
- /home/USERNAME/.pycharm_helpers/:/root/.pycharm_helpers/
- ./supervisord.conf:/etc/supervisord.conf
- ./djangod.conf:/etc/djangod.conf
links:
- postgresql
ports:
- "2225:22"
- "8005:8000"
Обратите внимание на первый контейнер — postgresql. Ему мы однозначно передаём .env для формирования первичных данных. Директива ports отвечает за проброс портов. Первая цифра перед двоеточием — номер порта, по которому будет доступна эта база в нашей убунте. Вторая цифра — это номер порта, который пробрасывается с контейнера. Дефолтный PostgreSQL порт
Второй контейнер будем собирать из Dockerfile. Поэтому, здесь стоит build. Команда запуска идёт с небольшой задержкой — на случай, если нам нужно будет время для запуска БД и других инструментов внутри контейнеров. Здесь же видим все подключаемые директории и файлы. При пробросе портов имеем порт 2225 — для SSH и 8005 — для сервера. В sshd_config нам нужно настроить под себя вот эти директивы:
PermitRootLogin without-password
StrictModes no
RSAAuthentication yes
PubkeyAuthentication yes
AuthorizedKeysFile %h/.ssh/authorized_keys
Помните, что всё это добро будет работать только у команды разработчиков. На продакшн мы это не выложим. Хотя, в принципе, ssh сервер будет доступен только локально.
/home/USERNAME/.pycharm_helpers/:/root/.pycharm_helpers/ — Эта команда на монтирование позволит нам запускать тесты и дебаг прямо из PyCharm. Не забудьте прописать тут свой USERNAME
В supervisord.conf пропишем следующее:
[unix_http_server]
file=/opt/project/daemons/supervisor.sock; path to your socket file
[supervisord]
logfile=/opt/project/logs/supervisord.log; supervisord log file
logfile_maxbytes=50MB; maximum size of logfile before rotation
logfile_backups=10; number of backed up logfiles
loglevel=info; info, debug, warn, trace
pidfile=/opt/project/daemons/supervisord.pid; pidfile location
nodaemon=false; run supervisord as a daemon
minfds=1024; number of startup file descriptors
minprocs=200; number of process descriptors
user=root; default user
childlogdir=/opt/project/logs/; where child log files will live
[rpcinterface:supervisor]
supervisor.rpcinterface_factory = supervisor.rpcinterface:make_main_rpcinterface
[supervisorctl]
serverurl=unix:///opt/project/daemons/supervisor.sock; use unix:// schem for a unix sockets.
[include]
# Uncomment this line for celeryd for Python
files=djangod.conf
В djangod.conf:
[program:django_project]
command=python /opt/project/manage.py runserver 0.0.0.0:8000
directory=/opt/project/
stopasgroup=true
stdout_logfile=/opt/project/logs/django.log
stderr_logfile=/opt/project/logs/django_err.log
Тот кто внимательно читает конфиги, должен обратить внимание на то, что мы объявили две не созданные ещё папки. Так что создадим в src директории logs и daemons. В .gitignore добавим соответственно /src/logs/* и /src/daemons/*
Обратите внимание на то, что в django, обычно, stdout_logfile не пишется. Все логи осыпаются в stderr_logfile. Настройка была взята из какой-то готовой инструкции, а удалять строчку не слишком хочется, ведь stdout_logfile — довольно стандартная директива.
Теперь не забудем про наш .env файл:
POSTGRES_USER=habrdockerarticle
POSTGRES_DB=habrdockerarticle
POSTGRES_PASSWORD=qwerty
POSTGRES_HOST=postgresql
POSTGRES_PORT=5432
PGDATA=/var/lib/postgresql/data/pgdata
C_FORCE_ROOT=true
Его можно добавить или не добавлять в .gitignore — значения не имеет.
В конце заполним Dockerfile
FROM python:2.7
RUN apt-get update && apt-get install -y openssh-server \
&& apt-get purge -y --auto-remove -o APT::AutoRemove::RecommendsImportant=false -o APT::AutoRemove::SuggestsImportant=false $buildDeps
COPY ./src/requirements.txt ./requirements.txt
RUN pip install -r requirements.txt
Docker Hub не скрывает от нас того, что наш контейнер будет обслуживаться Debian Jessie. В Dockerfile мы запланировали установку ssh сервера, чистку ненужных нам списков пакетов и установку requirements. Кстати, файл зависимостей у нас ещё не создан. Надо исправить этот недочёт и создать requirements.txt в папке src:
Django==1.8
psycopg2
supervisor
Первый запуск
Проект готов к первому запуску! Запускать будем поочерёдно. Сперва выполним:
(docker) $ docker-compose run --rm --service-ports postgresql
Эта операция скачает нам образ, необходимый для запуска postgresql сервера. Сервер запустится, пользователь и база, указанные в .env создадутся автоматически. Команда заблокирует нам ввод данных, но пока не будем её останавливать. Убедимся в наличии базы и ролей входа, подключившись через pgadmin

Как мы видим, всё уже создано для работы:
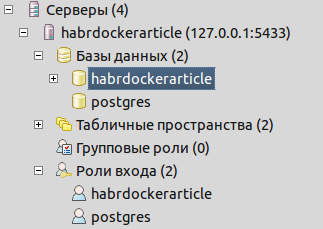
Теперь комбинацией клавиш ctrl+C в консоли остановим процесс. Нам надо собрать образ проекта. Так что выполним:
(docker) $ docker-compose build project
Эта команда соберёт нам проект, а также, выполнит все команды из Dockerfile. Т.е. у нас будет установлен ssh сервер, а также, установлены зависимости из requirements.txt. Теперь у нас возникает вопрос создания Django проекта. Создать его можно нескольким способами. Самый пуленепробиваемый — это поставить в нашу docker virtualenv на убунте нужную версию Django:
(docker) $ pip install django==1.8
(docker) $ cd ./src
(docker) $ django-admin startproject projectname
(docker) $ cd ../
Django из venv можно удалить или оставить для других проектов. Всё что нам осталось — это перенести внутренности проекта в корень папки src.
Теперь нам следует проверить наш проект и настроить соединение с БД. Сперва поменяем настройки в settings.py:
DATABASES = {
'default': {
'ENGINE': 'django.db.backends.postgresql_psycopg2',
'NAME': os.getenv('POSTGRES_DB'),
'USER': os.getenv('POSTGRES_USER'),
'PASSWORD': os.getenv('POSTGRES_PASSWORD'),
'HOST': os.getenv('POSTGRES_HOST'),
'PORT': int(os.getenv('POSTGRES_PORT'))
}
}
Потом запустим контейнеры проекта:
(docker) $ docker-compose up -d
И убедимся в положительном результате:
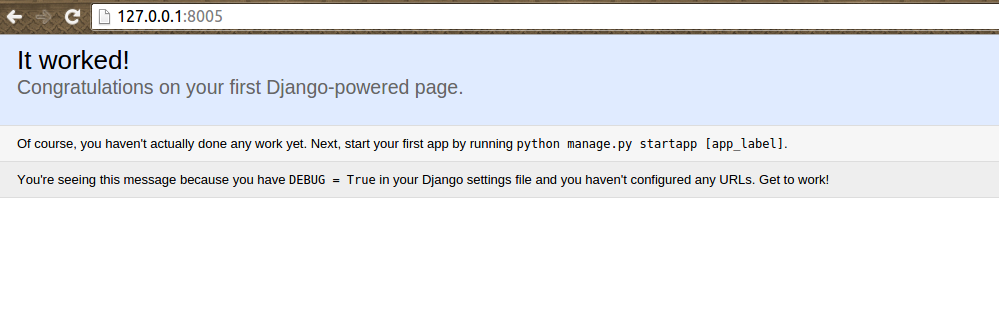
Для остановки проекта и удаления временных файлов можно использовать:
(docker) $ docker-compose stop && docker-compose rm -f
Если у нас меняется что-то в requirements.txt, используем следующую команду для быстрого пересбора
(docker) $ docker-compose stop && docker-compose rm -f && docker-compose build --no-cache project && docker-compose up -d
Давайте, проверим какая структура проекта у нас получилась:
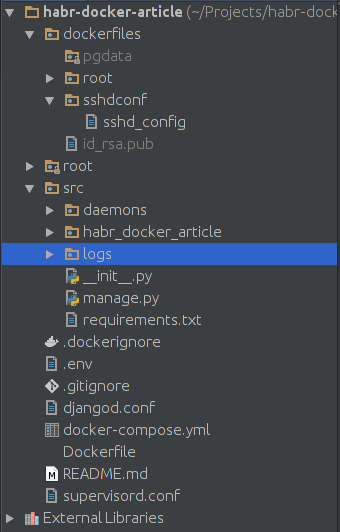
Папка root в моём коде содержит готовые helpers PyCharm'а.
Подключаем контейнер для JS программиста
Теперь можно сделать то, ради чего мы всё это и затевали — подключить Gulp для управления статикой. Файл docker-compose.yml теперь будет выглядеть так:
...
gulp:
build: ./src/gulp
command: bash -c "sleep 3 && gulp"
volumes:
- ./src/gulp:/app
- ./src/static/scripts:/app/build
project:
...
links:
- postgresql
- gulp
...
Я добавил новый контейнер и указал его в зависимостях к project.
Теперь мне нужно создать папку gulp в src для исходников и static/scripts для скомпилированных файлов. В папке src/gulp создадим файл package.json со следующим содержимым:
{
"name": "front",
"version": "3.9.0",
"description": "",
"main": "gulpfile.js",
"scripts": {
"test": "echo \"Error: no test specified\" && exit 1"
},
"author": "",
"license": "BSD-2-Clause",
"devDependencies": {
"gulp": "~3.9.0",
"gulp-uglify": "~1.4.2",
"gulp-concat": "~2.6.0",
"gulp-livereload": "~3.8.1",
"gulp-jade": "~1.1.0",
"gulp-imagemin": "~2.3.0",
"tiny-lr": "0.2.1"
}
}
Создадим gulpfile.js. в папке src/gulp. Я использовал свой старый файл для образца:
/**
* Created by werevolff on 18.10.15.
*/
var gulp = require('gulp'),
uglify = require('gulp-uglify'),
concat = require('gulp-concat'),
refresh = require('gulp-livereload'),
lr = require('tiny-lr'),
server = lr();
/**
* Mainpage
*/
gulp.task('mainpage', function () {
gulp.src(['./front/jquery/*.js', './front/bootstrap/*.js', './front/angularjs/angular.min.js',
'./front/angularjs/i18n/angular-locale_ru-ru.js', './front/project/**/*.js'])
.pipe(uglify())
.pipe(concat('mainpage.js'))
.pipe(gulp.dest('./build'))
.pipe(refresh(server));
});
/**
* Rebuild JS files
*/
gulp.task('lr-server', function () {
server.listen(35729, function (err) {
if (err) return console.log(err);
});
});
/**
* Gulp Tasks
*/
gulp.task('default', ['mainpage', 'lr-server'], function () {
gulp.watch('./front/**/*.js', ['mainpage']);
});
Как мы видим из конфига, нам следует залить в папку src/gulp/front некоторые популярные библиотеки и создать папку src/gulp/front/project для написанных JS программистом скриптов. Также, не забываем о создании Dockerfile в src/gulp
FROM neo9polska/nodejs-bower-gulp
COPY package.json ./package.json
COPY node_modules ./node_modules
RUN npm install --verbose
Теперь довольно важный вопрос — node_modules. Без этой папки контейнер с Gulp будет откровенно лажать. Здесь у нас два варианта получения этой папки:
- Собрать проект на локальной машине и перенести из него папку с модулями
- Убрать из Dockerfile всё что ниже директивы FROM, выполнить docker-compose run --rm gulp npm install --verbose, а потом поменять права на директорию с node_modules и вернуть то, что было ниже FROM обратно.
Однако, менять права не обязательно. Просто разработчики будут вынуждены постоянно выполнять команду на пересборку gulp. Впрочем, весь код, описанный в статье, я выложу на Github и можно взять node_modules оттуда. Проблема эта связана с docker-compose. Но победить её легко.
Итак, в результате запуска контейнеров
(docker) $ docker-compose up -d
Мы должны получить вот такой скомпилированный файл:
 .
.Готово! Проект можно залить в git и начинать работать с ним.
Полная команда перезапуска с пересборкой выглядит так:
(docker) $ docker-compose stop && docker-compose rm -f && docker-compose build --no-cache gulp && docker-compose build --no-cache project && docker-compose up -d
Для запуска проекта у нового участника процесса достаточно выполнить:
(docker) $ docker-compose build --no-cache gulp && docker-compose build --no-cache project && docker-compose up -d
Для просмотра основного журнала контейнера с запущенным приложением:
(docker) $ docker-compose logs CONTAINER NAME
Логи Django из project пишутся в папку src/logs.
Исходный код проекта вы можете посмотреть в моём GitHub.
P.S. Ещё один важный аспект — настройка интерпретатора python в PyCharm. Для этой настройки достаточно добавить remote interpreter:

И обратите внимание на то, что PyCharm имеет плагин для интеграции с Docker. Мы же используем SSH соединение, поскольку не затрагивали вопрос развёртывания проекта на docker-machine.
Комментарии (41)
Lol4t0
10.12.2015 20:48Не могли бы вы пояснить, какие сервисы в итоге в каких контейнерах/каком окружении будут выполняться, а то я что-то ничего не понял

werevolff
10.12.2015 21:00-1База данных, Gulp и бэкенд на Django. Gulp будет служить для компиляции независимого js приложения, которое будет обмениваться с бэкендом данными через Rest. Docker упростит развёртывание проекта и задаст общий стиль разработки: в нём будет работать livereload и запускаться локальный dev сервер. Также, docker избавит разработчиков от необходимости самостоятельно ставить postgresql, python, django, node.js, gulp и запускать все серверы и демоны. Рассматриваемая архитектура выходит за рамки данной статьи, так что это может означать продолжение, в котором контейнер с проектом обзаведётся nginx, добавится контейнер с redis для кеширования, а связь между сервером и клиентом будет раскрыта. В данной статье рассмотрена возможность один раз настроить окружение так, чтобы на остальных машинах оно ставилось одной — тремя командами.
Lol4t0
10.12.2015 22:18+1Мне все-таки хотелось бы подробнее этот вопрос разобрать. Потому что архитектура тут в стиле Дали, и свзяи между контейнерами и хост-машиной довольно необычны на мой взгляд. Мне интересно, почему решено сделать именно так? Все-таки классически контейнеры обычно независимы друг от друга и от хост-системы, а у вас все сплетено в один клубок
werevolff
11.12.2015 05:35А что не так со связью контейнеров и хост-системы?
VolCh
11.12.2015 07:03+1Очень много volumes как на мой взгляд. Плюс жесткая проброска портов контейнеров на хост машину.
werevolff
11.12.2015 07:22Пробрасывается три нужных порта: БД, SSH, HTTP. Есть альтернативный вариант — ставить listen 0.0.0.0 на всех контейнерах. Тогда пробрасывать порты не надо вообще. Лично я предпочитаю localhost В дальнейшем, если делаем деплоймент в контейнерах (облачные сервисы позволяют такой вариант), нам остаётся оставить только один проброшенный порт — HTTP. Впрочем, вариант с одной сетью на все контейнеры выглядит красивым и логичным.
В volumes тоже можно сделать оптимизацию. Например, конфиги супервайзора поместить в одну папку. Остальные тома все на своём месте.VolCh
11.12.2015 07:30Проброс БД порта не нужен, для этого есть link. Контейнер приложения всё равно связывается с контейнером СУБД напрямую по стандартному порту независимо от того на какой порт проброшен он на хосте. Зачем SSH вообще непонятно. Конфиги супервизора, да и вообще все можно копировать в контейнеры при билде, а не шарить с хостом.
werevolff
11.12.2015 07:51И ответы на это уже размещены в различных комментариях этой статьи. SSH используется для отладки и тестирования. Поскольку плагин для docker желает видеть docker-machine. Копирование конфигов при билде, как я писал ниже — оптимальный вариант. По поводу link вместо проброса портов хотелось бы уточнить: чем это лучше? Есть авторитетные источники, которые подтверждали бы это? Я пока вижу только одно обоснование: вам так больше нравится. А мне больше нравится проброс портов. На этапе оптимизации я бы использовал директиву net и связал бы все контейнеры в одну сеть, вывернув наружу только 80 порт.
К тому же, я не совсем понимаю как вы планируете использовать link и зачем? postgresql и так прекрасно доступен в project на одноимённом хосте. Проброс портов делается только для хоста. Вы, видимо, путаете тёплое с мягким.VolCh
14.12.2015 09:01По поводу link вместо проброса портов хотелось бы уточнить: чем это лучше?
Не занимаются эксклюзивно ресурсы хост-машины, а значит можно запускать множество инстансов множества приложений одновременно без конфликтов. Ваша схема позволяет одновременно поднять два инстанса из разных веток одного приложения?
werevolff
11.12.2015 08:07Вы посмотрите для чего вообще был сделан проброс портов: я использую pgadmin, использую Remote interpreter в PyCharm. Я не использую проброс портов для доступа к БД или для ssh управления сервером. Надо же различать области применения. При этом, если от порта БД можно отказаться, то от SSH — с трудом. Он используется в IDE. Для базы данных есть альтернативный вариант — узнать на хосте IP контейнера, сделать expose и коннектиться к базе. Либо, связать контейнеры директивой net и использовать ssh туннель. Только делать мне больше нечего: на dev среде настраивать туннелирование. Всё прекрасно работает при использовании ports.

kuznetsovin
12.12.2015 11:46Мне вот хотелось бы узнать, на сколько на практике это разворачивать для fontend разработчика? Просто мы по началу тоже хотели использовать такую систему, но вот с разворачиваем ее на Мак'ах возникли проблемы, так как на них докер работает из-под virtualbox, то ощутимой разницы с Vagrant не заметно. Да и плюс наш фронтэндщик работает без idе.
VolCh
11.12.2015 07:23Как-то в статье не освещено основное, видимо, требование к системе развертывания: разработчик разворачивает исходники проекта (например из гита) локально, работает с ними локально, и система должна подхватывать изменения на лету или с минимумом движений. Отсюда куча томов с привязкой к хосту — отслеживание изменений файлов хоста на лету.
werevolff
11.12.2015 07:34Конфиги можно подключить и из Dockerfile. Но тогда для перезапуска службы с новым конфигом, надо будет заново делать build. Это не совсем удобно. Вообще, в предложенном варианте не используется Docker hub для хранения получившихся сборок. И это главная причина почему в volumes так много томов. Мы исходим из того, что заказчик не будет оплачивать приватный репозиторий на Docker hub.
Lol4t0
11.12.2015 10:01+1docker build делается буквально за доли секунды
А для хранения контейнеров можно развернуть собственную registrywerevolff
11.12.2015 10:09Существенное замечание. Только build не всегда делается за доли секунды, и не всегда есть необходимость в специализированном репозитории. Описанный пример позволяет хранить конфигурацию для развёртывания среды непосредственно в исходниках. Кстати, при docker pull должен получиться билд без исходного кода, иначе харам и побивание камнями. Поэтому, в принципе, docker hub или registry это красиво, но не нужно. Тем более, что билд выполняется не так долго. Даже если в Dockerfile стоит несколько команд на установку определённых пакетов. А такая команда в приведённом примере, прошу обратить внимание, имеется.
Lol4t0
11.12.2015 10:15Нет, вы просто разносите процессы разработки и развертывания.
При разработке вы что-то там делаете в virtualenv, тестируете, а когда все готово — генерируете артифкат — docker image, самодостаточный, который уже заливаете на удаленный сервер, и который там встает в строй из других таких же контейнеров.
Только build не всегда делается за доли секунды
Там как бы есть кеширование. После того, как вы один раз собрали базовый образ, ваши __изменения__ в него, вызванные __вашим__ кодом, накатываются __буквально__ за доли секунды
Lol4t0
11.12.2015 10:10+2И в итоге получается система, которой на host-машине нужен git, docker-composer и сам docker. И на которую лучше не дышать. Захотели вынести БД на отдельный сервер — что может быть проще, он же в контенере! Ой, а у нас теперь конфиги недоступны, потому что репозитория там нет.
Docker build не настолько страшный зверь, чтобы вытворять такие кульбиты в попытках его избежатьwerevolff
11.12.2015 12:35Контейнер с БД идёт без специфичных конфигов. Если мы захотим перенести контейнер на другой сервер, проблем не возникнет. Напомню, что в реальных условиях данные, содержащиеся в БД в git не коммитятся. К тому же, я бы не стал в репозиторий докера коммитить свои файлы. Всё должно прекрасно подниматься с нуля, а вот мешать репозиторий среды с репозиторием проекта — не хорошо. В нашем случае, проект поставляется со всеми конфигами и описанием среды. Докер автоматизирует сборку среды с нуля. Производить овероптимизэйшн не имеет смысла. К тому же, как видно из примера, два контейнера билдятся и ничто не мешает сделать им пулл. При этом, проект в репозиторий среды не попадёт. Что вы пытаетесь критиковать — я не понимаю. Разделение среды и проекта сделано вполне осознано. Вопрос сохранения билда не поднимался.
VolCh
14.12.2015 09:23+1Насколько среда готова к деплою на хотя бы стейджинг с учетом разноса отдельных сервисов на разные хосты?
Разделение среды выполнения и проекта вполне нормально. Ненормальна привязка контейнеров среды исполнения к файлам и конкретным портам на хост-машине.

renskiy
10.12.2015 23:45Мы недавно зарелизили один проект на Python 3.4 + Django. Это был наш первый эксперимент с Docker. Для разворачивания среды разработчика решили использовать vagrant — он умеет запускать образы Docker. И команда для «запуска всего» получилась короче:
vagrant up
При этом состав компонентов схож с вашим (у нас дополнительно поднимаются контейнеры с CRON, админкой и пр.).
Хотелось немного прокомментировать ваше решение использовать supervisor внутри контейнера. В вашей ситуации не вижу смысла использовать его для запуска manage.py runserver, который при создании контейнера можно запускать напрямую, например так:
docker run --name django_app --detach --publish 8005:8000 django_image bash -c "manage.py runserver"
Supervisor в вашем случае, насколько я понял, нужен только для управления логами. Мы оставили вопрос управления логами на потом (пока не ротируем), но вроде Docker имеет свою мощную систему управления логами, умеющую интегрироваться с несколькими популярными решениями. Например, при создании контейнера вышеописанным способом логи можно смотреть так:
docker logs -f django_app
Также спорным решением, на мой взгляд, является необходимость установки SSH внутри образа Docker. Pycharm вроде умеет конектиться к контейнерам Docker напрямую, а если нужно запустить консоль внутри работающего контейнера, то это можно сделать так:
docker exec --tty --interactive django_app /bin/bash
Понравилась ваша идея запускать тесты внтури контейнера Docker, сейчас мы это делаем снаружи.
Хотелось бы послушать ваш рассказ про деплой на боевую инфраструктуру.werevolff
11.12.2015 04:58-2В приведённом примере pure docker не используется. Это порождает некоторые проблемы, но избавляет от других. К примеру, перелинковка контейнеров проходит проще. Спор о том что лучше: Vagrant или Docker, на мой взгляд, не имеет смысла. Vagrant, безусловно, позволяет работать с монолитной инфраструктурой. Только для этого запускается целая виртуальная машина. docker-machine делает то же самое, но здесь он не используется. Поэтому, PyCharm и не поддерживает прямого выхода на Docker контейнер. Сам плагин для докера сделан для Win и Mac, видимо, поэтому требует запуска docker-machine.
Деплоймент может происходить разными способами. Самое первое что приходит на ум: многие облачные серверы поддерживают .yml синтаксис для развёртывания docker. Хотя, docker-machine позволяет делать деплой одной-двумя командами с локального компа. А есть еще и настраиваемая CI среда с поддержкой Docker, которая называется CIrcleCI.
werevolff
11.12.2015 05:02С supervisor согласен полностью. Разумно использовать его, к примеру, если нужно запустить celery или, хотя бы, связку web-серверов. В прошлый раз работал с celery, поэтому, supervisor вошёл в пример статьи. Если говорить о шаблоне Docker системы, то в нём проще оставить supervisor, чем убрать, а потом при необходимости поднимать заново. Хотя, это дело личное.

Eternalko
11.12.2015 11:08вроде Docker имеет свою мощную систему управления логами
Не нужно ее использовать. Она для дебага при разработке.

Degibenz
11.12.2015 01:06-1Вопрос пожалуй один — почему контейнеры описсаны в одном docker-compose файле? Почему бы каждый «контейнер» не описать отдельно? Я понимаю, что поднять все целиком очень просто, но все же.
werevolff
11.12.2015 05:33+1Потому, что в docker-compose файлах описывается, как-раз, несколько контейнеров. Для описания отдельных контейнеров используются Dockerfile's. Несколько docker-compose файлов необходимо, скажем, для того, чтобы отдельно описать инфраструктуру dev и production. Предположим, что у нас используется amazon для баз данных, а web сервер стоит жёстко на хосте, а не внутри контейнера. Тогда у нас будет отдельный файл для такого боевого сервера (но только в том случае, если мы используем прод с совместимым yml синтаксисом файлов для деплоймента). Другой вариант: один из участников команды использует специфические инструменты. Скажем, инструменты статистики и/или дебага. Ему не нужно запускать сервер разработки — только снимать результаты выполнения. Тогда для него будет создан отдельный файл.
К тому же, если под каждый контейнер будет свой файл, его придётся запускать отдельно. Больше команд для запуска. А значит, в использовании compose нет смысла. С тем же успехом можно запускать обычную команду docker.Degibenz
13.12.2015 14:07Сложность проекта я понимаю так: есть код(backend часть, без JS, без статики)и вот нам надо сделать так, чтобы он подружился с уже готовой инфраструктурой и притащил еще свои сервисы(DNS, nginx). На сервере уже есть контейнеры или набор контейнеров(кластер) или Рэбита, Постгриса(вот он как раз из тех сервисов, который должен быть для всех един(не важно в каком виде, кластер или нет)).
Где подобная сложность у вас? Насколько я понял, у вас все сводится к разделению окружения. Окей. Почему тогда не использрвать Вагратн, Отто?
К тому же, если под каждый контейнер будет свой файл, его придётся запускать отдельно. Больше команд для запуска. А значит, в использовании compose нет смысла. С тем же успехом можно запускать обычную команду docker.
Глупости говорите, товарищ. Про Фабрик слышали? А про баш-скрипты?
Вопрос пока один — зачем городить такие огороды? Может есть путь проще?werevolff
14.12.2015 10:46-1Вы хотите стартовать контейнеры bash скриптом или фабриком? Ну-ну.
Degibenz
14.12.2015 10:57А что в этом такого? Вы боитесь или просто ленитесь писать?
werevolff
14.12.2015 11:44-1Я думаю, что скорее, вы ленитесь читать. Docker — не вагрант. У него свои особенности. В частности, возможность обслуживать каждый контейнер отдельно. Хорошо это или плохо — предмет холивара. Тот же вагрант может использоваться для запуска полного образа или docker контейнеров. Всё зависит от необходимости. Если вам нравится вагрант, то зачем писать здесь или пытаться сделать вагрант из докера? Docker-compose тоже отдельный инструмент, который для того и создан, чтобы разворачивать среду из одного файла, который описывает все контейнеры. Нет, конечно, можно на каждый контейнер сделать свой yml файл, написать bash скрипт, чтобы запустить всё это дело вместе и насмешить других разработчиков. Особенно, тех, которые потом будут ваш проект обслуживать. Я думаю, что они поступят проще: соберут всё в один yml файл и воспользуются docker-compose для работы. Либо, сделают отдельные Dockerfile's и обернут в вагрант для запуска. Вариантов много, на самом деле. Мне больше нравится вариант с compose. Нахожу yml файл более простым для переноса и более информативным. Фабрик и bash скрипты удобно использовать внутри контейнера, а не снаружи. Для запуска Docker контейнеров и так достаточно инструментов.
Degibenz
14.12.2015 11:58+1Внутри контейнера? Realy? А знаете ли вы, что если у вас код на серверной машине, и там лежит fab.py вы можете удаленно налить весь свой проект внутрь докера? Фантастика? Или вы по ssh заходите и делаете deploy?
Простите, но я вас не понимаю. Наверное, мне стоит употреблять те же вещества, что и вы употребляли перед тем, как приняли такое очень странное решение. Все что вы описали в своих проблемах: разделение версий, разграниченный доступ, бла-бла-бла путь в Вагрант. Если у вас это конечно сервер — окей докер. В таком случае — вы очень странно, а почти что никак не можете внятно объяснить где у вас сложный проект? Почему выбрана система хранить все в одном файле? Что будет если c контейнерам если надо «перезагрузить» контейнеры? Что произойдет с вашей БД, которая во-время перезагрузки будет недоступна?
Видите как много бывает вопросов, если это реально сложный проект, а не состоящий из двух контейнеров, именно это я и ожидал тут увидеть, а не конфиг их двух контейнеров.werevolff
15.12.2015 11:04Я не понимаю, зачем fabric нужен на этапе dev. И, тем более, не понимаю как вы хотите оправдать фабриком написание по одному yml файлу на каждый контейнер. Велосипеды какие-то изобретаете. Про вагрант я уже говорил: здесь рассматривается применение докера. Вопрос «почему не вагрант» бессмысленный. Здесь просто рассматривается docker + docker-compose. Если вам интересно применение вагранта, не занимайтесь ерундой и напишите об этом свою статью. Может, хоть из минусов вылезете.
werevolff
15.12.2015 11:17-1С моей БД во время перезагрузки не произойдёт ничего страшного. Во-первых, статья не рассматривает production, где подразумевается использовать Database as Service. Во-вторых, yml файл compose прекрасно стартует контейнеры, в той очерёдности, которая предписана links. Суть ваших претензий вообще не очень понятна. Docker-compose прекрасно автоматизирует запуск N контейнеров вместе без плясок на локальном компе с баш скриптами и fab-файлом. Разумеется, для деплоймента можно использовать fab и предложенная архитектура прекрасно справится с этим. Вопрос в другом: где вы в данной статье видели попытку задеплоить проект? Здесь речь шла о том, как паковать продукт вместе с окружением. Минимум места на диске, минимум ресурсов, минимум времени на развёртывание с нуля. Пока я вижу только одну претензию. Вы так не делаете, поэтому считаете архитектуру слабой. Вопрос о разделении контейнеров по разным yml файлам вообще бессмысленный. Вопрос с fabric ещё неплохой. Можно задуматься о том, чтобы все команды compose обернуть в него. Только тогда на второй план уйдёт забота о правильном запуске контейнеров. Docker-compose и так не обладает полными возможностями Pure Docker commands, ограничивая процесс только жизненно необходимыми командами. Если это упросить ещё и до трёх fab команд, получится какой-то перегруз системы ненужным попечением о ней. Хотя, после выбора решения для CI, можно будет написать скрипт деплоймента под fab.
Degibenz
15.12.2015 11:54-1Товарищ, вы можете ответить на мои вопросы выше, или так и будите ходить вокруг да около?
Легенда ваша разъезжается.
Необходимо полностью эмулировать пространство Production, а ещё лучше — поставлять код участникам процесса разработки вместе со средой.
А потом у вас:
Во-первых, статья не рассматривает production, где подразумевается использовать Database as Service
Так полностью или частично?
С моей БД во время перезагрузки не произойдёт ничего страшного.
Вы в этом уверены? Логи смотрели?
Вопрос в другом: где вы в данной статье видели попытку задеплоить проект?
Ваше же?
Необходимо автоматизировать развёртывание проекта, ....
werevolff
15.12.2015 12:04-1Что вас смущает в эмуляции Production? Эмулируется среда, а не инструмент CI. Давайте ещё тесты тестами покроем и дебаг отдебажим, чтобы вы были счастливы.
Да и автоматизация, если вы внимательно почитаете, относилась к развёртыванию на машине разработчика.
Lol4t0
13.12.2015 17:16Потому что тут смешались в кучу кони люди
— Есть контейнеры — см. Dockerfile
— Есть система управления контейенрами (ну чтоб не bash-скриптами все запускать, а по-модному — напрмиер, docker-composer).
По идее, они служат для разных целей, а то, что тут наверчено — просто пример плохой архитектуры и ничего более.
freylis
У меня вот какой вопрос возникает, когда периодически приходится допиливать чужие проекты на django:
Вы наверняка jquery и/или bootstrap ставите с помощью bower
Однако в задаче для gulp говорите минифицировать и склеивать весь *.js из перечисленных директорий. А вас не заботит, что в репозитории bower хранится как оригинал, так и .min.js? В итоге они ведь оба попадают в mainpage.js
Может быть стоит склеивать только те скрипты/стили, которые реально подключаются на страницу?
werevolff
Можно. Это просто образец. Думаю, что у меня в этом плане определённо ошибка, поскольку наиболее правильно действительно жёстко прописывать имена файлов для слияния. А вот в папке project уже можно создать под отдельные страницы или группы страниц свои поддиректории и компилировать из них все файлы.
gulp.src(['./front/jquery/jquery-xxx.min.js', './front/bootstrap/bootstrap.min.js', './front/angularjs/angular.min.js',
'./front/angularjs/i18n/angular-locale_ru-ru.js', './front/project/pages/mainpage/**/*.js', './front/project/plugins/statistics/**/*.js'])
Вот, скажем пример того, что может получиться. На выходе имеем 1 сжатый рабочий JS файл.
Ещё добавлю, что я вообще не гарантирую правильную работу приведённого gulp сценария. Поскольку я его даже не оптимизировал и сильно не углублялся. Статья предназначена прежде-всего для бэкенд и фулл-стек разработчиков, которые могут самостоятельно настроить gulp/grunt/compass и т.д.
freylis
В таком случае вы дублируете список файлов в base.html и в gulp.js. Я ищу список подключенных в base.html javascript файлов (в простейшем случае весь js подключается там. Js, который подключается на других шаблонах, но не подключается в base.js — отсутствует), их уже сжимаем и склеиваем
werevolff
В этом нет нужды. Мы знаем, что на главной странице будет скомпилированный файл mainpage.js. Его и подключаем. Для тестов можно использовать что-то вроде Jasmine. Так что в большинстве случаев отдельное подключение каждого скрипта не требуется. Другой вариант — писать отдельный JS для различных регионов одного и того же шаблона. В таком случае, опять же, отдельное подключение скриптов не нужно. Есть ещё require.js, с которым Gulp может работать. Так что мы можем обойтись вообще подключением одного файла сжатого или не сжатого — не имеет значения.
freylis
Если каждый человек в вашей команде обязан пользоваться livereload — ваша правда.
Ситуация с подключением различных скриптов в зависимости от определенных условий требует решения как в вашем, так и в моём варианте
werevolff
Это решается на уровне JS. Livereload обеспечивается докером только на локальной машине. На продакшн gulp будет выполняться один раз — перед стартом сервера. Мы чётко определяем, что на этой странице или на этой группе страниц будет подключен один скрипт. Мы прописываем его генерацию в Gulp. Если отключить сжатие, склейка будет происходить меньше секунды. JS программер не меняет ничего в теге script — всё происходит в настройках Gulp. Программист вполне свободно делит приложение на отдельные модули и на выходе получает 1 файл. Это даже лучше: программер сразу видит что происходит после склейки, есть ли конфликты. А на проде уже включится сжатие, которое может занимать продолжительное время, но, в любом случае, там оно будет проходить один раз.