
Не так давно состоялся очередной хакатон от Microsoft. На этот раз, он был посвящен машинному обучению. Тема очень актуальная и перспективная, однако, для меня достаточно туманная. На момент начала хакатона я имел только общее представление о том, что это такое, зачем оно нужно и пару раз видел результаты работы обученных моделей. Узнав, что анонс обещал множество экспертов в помощь новичкам, я решил объединить приятное с полезным и попробовать использовать машинное обучение при работе с каким нибудь IoT решением. Далее я расскажу что из этого получилось.
Я достаточно давно занимаюсь системами охраны периметра, основанными на анализе вибраций забора, так что сразу возникла идея поработать с акселерометром. Идея была проста: научить систему отличать виброзвонки нескольких телефонов, основываясь на данных акселерометра. Похожие эксперименты были уже с успехом проведены моими коллегами, по этому я не сомневался что это возможно.
Изначально, я хотел сделать все на Raspberry Pi 2 и Windows IoT. Была заготовлена специальная плата (на фото ниже) с цифровым и аналоговым акселерометрами, но попробовать ее в деле я не успел, решив все сделать на хакатоне. На всякий случай я захватил еще наш датчик, который так же позволяет поучать “сырые” данные о колебаниях.

На хакатоне всем участниками предлагалось разделиться на команды и решить одну из 3х задач, используя заранее заготовленные данные. Моя же задача получилась “вне конкурса”, однако команда собралась достаточно быстро:

Опыта использования Azure Machine learning ни у кого из нас не было, так что сделать предстояло очень много! Спасибо коллегам, среди которых был и psfinaki, за их труды!
Решено было разделиться на 3 направления:
- подготовка данных для анализа
- загрузка данных в облако
- работа с Azure Machine Learning
Подготовка данных заключалась в том, чтобы получить их из акселерометра, а затем представить в виде, доступном для загрузки в облако. Загружать в облако планировалось через Event Hub. Ну а дальше нужно было понять как использовать эти данные в Azure Machine Learning.
Проблемы начались по всем трем пунктам.

Много времени ушло на настройку Windows IoT на Raspberry. Она никак не выдавала картинку на монитор. Решить это удалось только, внеся следующие строчки в config.txt:
hdmi_ignore_edid=0xa5000080hdmi_drive=2hdmi_group=2hdmi_mode=16Это настраивало видеодрайвер на нужный формат, разрешение и частоту.

Однако, время, потраченное на это занятие, давало понять, что можно просто не успеть организовать получение данных из акселерометра. Поэтому было принято решение использовать датчик, захваченный мной про запас.
Для датчика было уже написано множество приложений. Одно из них выводило на экран график “сырых” данных:
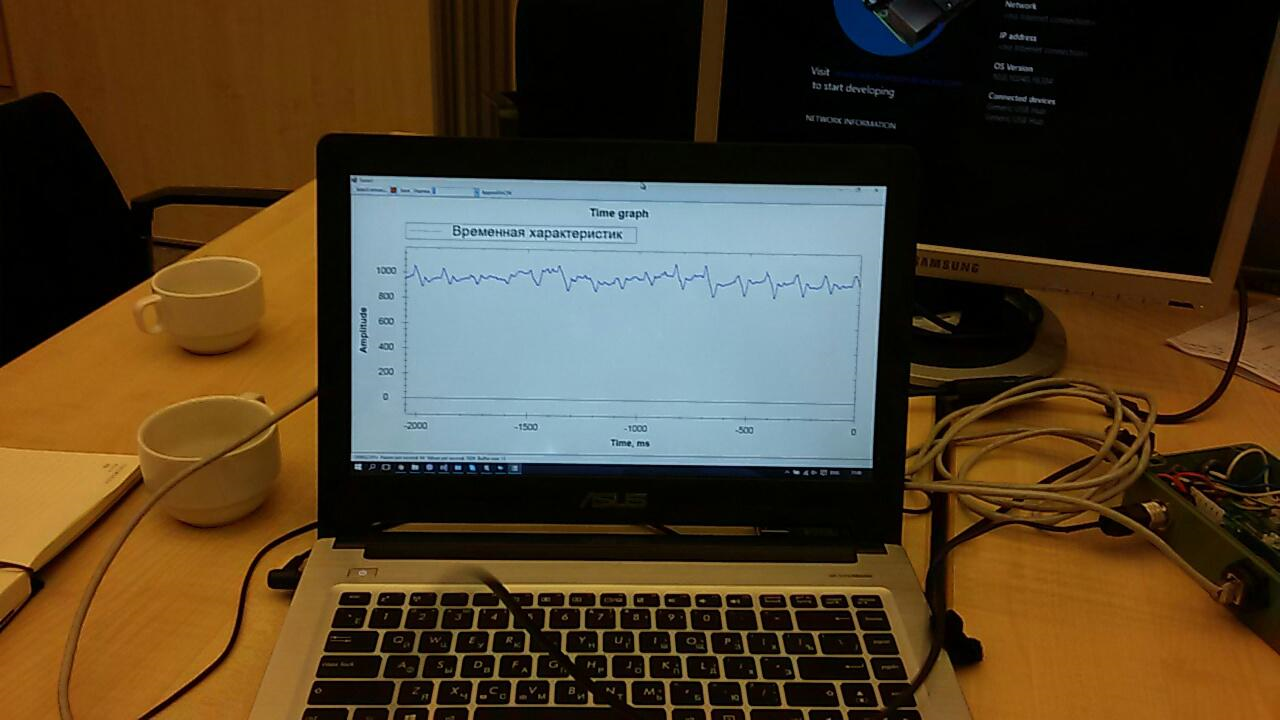
Нужно было немного его доделать, чтобы подготовить данные к отправке в облако.
Event Hub тоже заработал не сразу. Для начала, мы пытались отправить туда просто случайную последовательность. Но данные никак не хотели появляться в отчетах. Проблем было несколько, и, как оказалось, все они были “детскими”: где-то не так настроили, где-то использовали не тот ключ и так далее. Работа на этом направлении была трудна и отняла много сил:

Но, к вечеру первого дня мы смогли отправлять и получать данные из датчика на лету… Правда, в финальном решении это оказалось не нужно. О причинах скажу чуть позже.
С Machine Learning было вообще ничего не понятно. Сначала мы дружно изучали прекрасную статью с примером использования мобильного приложения как клиента. Затем выясняли формат данных и как с ними работать. Потом думали как же создать обучающие последовательности.
В Azure Mashine Learning есть множество алгоритмов для различной классификации. Эти алгоритмы должны быть обучены на тестовом наборе данных. Затем, те, которые дают лучший результат, можно опубликовать как web-сервис и подключаться к ним из приложения.
Обучение алгоритма называется “экспериментом”. Все действия ведутся в визуальном редакторе:

Перетаскивая элементы из списка слева можно получать данные, изменять и преобразовывать их, обучать модели и оценивать их работу.
Вот так выглядит типичный эксперимент:
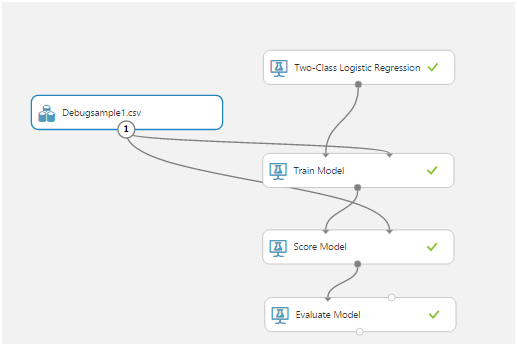
Самыми важными оказались Train Model, Score Model и Evaluate Model.
Первая, используя входные данные, обучает алгоритм, вторая тестирует обученный алгоритм на наборе данных, третья дает оценку результату тестирования.
Исходные данные в нашем случае представляют собой csv файл. Но что в нем должно содержаться?
Чувствительный элемент нашего датчика опрашивается 1024 раза в секунду. Каждый опрос представляет собой двухбайтовое значение, соответствующее амплитуде текущего колебания. Причем амплитуда отсчитывается не от нуля, а от опорного числа, соответствующего неподвижному датчику.
Поразмыслив, мы решили использовать временные срезы. Например, все опросы датчика за 256 мс давали нам одну строчку в csv таблице. Эти данные, в дополнительном столбце, можно было пометить тем или иным образом, в зависимости от происходящего с датчиком. Например, мы использовали 0 для обозначения шума (тряска датчика руками, постукивания и т.д.) и 1 для обозначения сигнала (на датчике лежит вибрирующий телефон).
Вот так мы записывали тестовые последовательности:
Получив данные, и поняв, что с ними нужно делать, мы начали учить первую модель:

Первый блин получился комом:

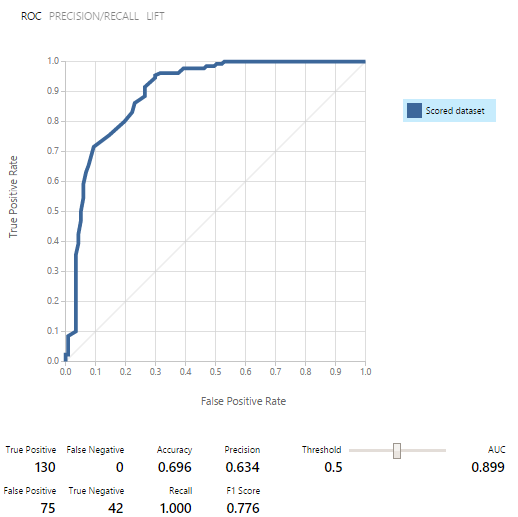
На тот момент даже смысл этих показателей был не понятен. Нас спас представитель команды поддержки, Евгений Григоренко, рассказав о ROC кривых. Главным оказалось то, что если график ниже средней линии в некотором месте, то модель работает даже хуже, чем если бы она давала результат случайным образом! Евгений и дальше помогал нам чем мог, за что ему большое спасибо!

Дальше мы долго переписывали обучающую последовательность и смотрели результаты:

Оказалось, что более менее оптимальной является работа с 2х секундной записью (2048 опросов датчика). Это позволяло делать строки csv таблицы более осмысленными. Но результат все же был далек от хорошего.
На этом закончился первый день.
Ночь я потратил на изучение материала. Очень помогла статья про бинарную классификацию. А еще внимательно перечитал статью с советами для этого хакатона. В общем, к началу работы я был полон новых идей.
Всю первую половину второго дня мы потратили на изучение разных моделей. Результатом работы стала вот такая “простыня”:

К этому моменту стало уже понятно, что различить два виброзвонка мы просто не успеем, так как качество данных для обучения оставляло желать лучшего, а записывать новые времени не хватало. По этому мы сосредоточились на разделении данных на “сигнал” и “шум”.
Для работы мы использовали 3 набора данных:
- Набор для обучения, в котором были и сигнал (строки csv файла, помеченные 1), и шум (строки, помеченные 0)
- Набор, содержащий только шум (строки с 0)
- Набор, содержащий только сигнал (строки с 1)
Модели сначала обучались, потом проверялись и оценивались на каждом из наборов данных. Результаты обнадеживали:
В итоге, из девяти моделей бинарной классификации, мы выбрали пять.
Как оказалось, использовать модель как Web-сервис гораздо проще, чем прикручивать ее к Event hub. По этому мы решили опубликовать все 5 моделей и поработать с ними через REQUEST/RESPONSE, который сопровождается очень хорошим примером.
Запрос представляет собой входной массив из 2048 значений, снятых с датчика. Ответ выглядит так:
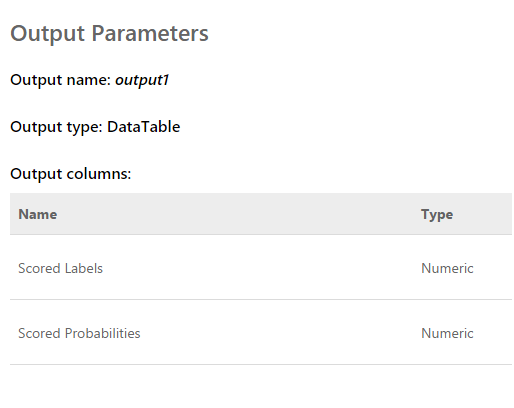
Scored labels — это 0 или 1. То есть результат классификации. Scored Probabilities — десятичное число, отражающее правильность оценки. Насколько я понял, первое значение — это округление второго. То есть, чем ближе второе значение к 0 тем оценка 0 более вероятная, и наоборот. Чем ближе значение к 1 тем оценка 1 более вероятная.
Доработав программу, выводящую график “сырых данных” на экран, мы смогли параллельно, из нескольких потоков, получать данные со всех пяти web-сервисов. Далее, немного понаблюдав за оценками, мы исключили один, так как он давал результат, совсем не похожий на остальные и портил всю картину.
В итоге получилось следующее:
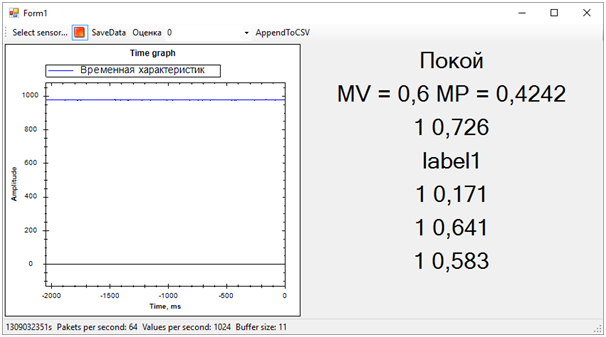
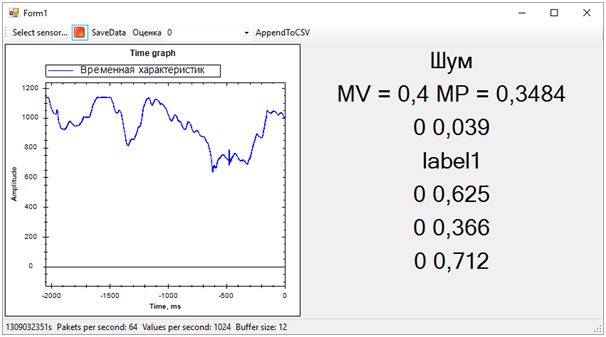
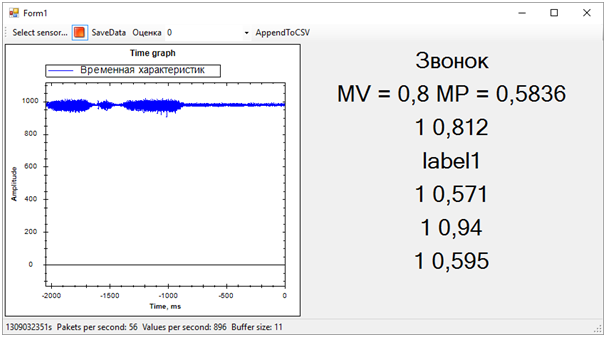
Тут сразу вылезли все проблемы обучающей последовательности. Хотя мы и пытались отделить виброзвонок от всего остального (шума и покоя), состояние покоя получилось очень близким к звонку, по этому определялось далеко не всегда. Разницу между звонком и покоем мы определяли по среднему числу probabilities для каждой модели. Значение ближе к 1 означает звонок, значение около 0.5 при score равной 1 — это покой. Ну а если score равен 0 — это однозначно шум.
На этом время хакатона подошло к концу. Мы даже толком не успели показать экспертам результата, так как они были заняты оценками конкурсных работ.
Но это все уже не имело особой важности. Самое главное, что мы добились вполне вменяемого результата и при этом узнали много нового!
За два дня напряженной работы мы выполнили, хотя и частично, поставленную задачу. Спасибо коллегам из команды и экспертам, помогавшим нам!
Сейчас можно отметить пути развития нашего проекта. Мы использовали временные характеристики для разделения событий. Однако, если перейти в частотную область, эффективность работы алгоритмов должна быть выше. Шум, покой и звонок имеют заметно отличающиеся спектральные характеристики.
Кроме того, опытные люди подсказали, что данные лучше нормализовать. То есть числа входной последовательности должны лежать в пределах от -1 до +1. С такими данными алгоритмы работают эффективнее.
Ну и еще, нужно поработать над формированием обучающих последовательностей, чтобы более четко разделять сигнал от шума.
Эти доработки должны существенно увеличить точность определения состояний, что я и хочу проверить в будущем.
raptor
Несколько странно, что у вас на это много времени ушло. Вы параметры не могли подобрать правильные или просто долго искали как настраивать мониторы на Windows IoT?!
AlexandrSurkov
Мы делали все. Начиная с разворачивания Windows IoT, заканчивая поиском причины и ее устранением. Ушло на это часа два.
Естественно, мы сразу нашли много форумов, где люди обсуждают такие же проблемы. Там были и списки параметров. Но HDMI-VGA переходник, который мы использовали, никак не хотел работать. По сути, параметры пришлось подбирать перебором. В итоге, родное для монитора разрешение так и не удалось поставить.
Aspire89
а зачем вообще монитор подключали?
AlexandrSurkov
Чтобы сделать какую-нибудь визуализацию процесса.
Скриншоты в конце статьи добавляют наглядности результату. Что-то такое хотелось сделать и на Raspberry