DocumentFragment обрабатывается в большинстве алгоритмов DOM особым образом. В этой статье мы рассмотрим некоторые методы API, разработанные для использования вместе с DocumentFragment. Также мы узнаем, что понятие контейнера узлов играет важную роль в прочих современных веб-технологиях, таких как элемент template или в API всего теневого DOM. Но прежде чем мы начнем, давайте вкратце рассмотрим парсинг фрагментов, который не связан напрямую с DocumentFragment.
Парсинг фрагментов
Парсер HTML5 можно использовать не только для анализа целого документа. Также он может использоваться для парсинга части документа. Чтобы вызвать парсинг фрагмента, необходимо настроить такие свойства как innerHTML или outerHTML. Анализ фрагмента выполняется таким же образом, что и обычный парсинг, за некоторыми исключениями. Самое существенное отличие заключается в необходимости контекстуального корня.
Анализируемый фрагмент, скорее всего, будет размещаться как дочерний элемент какого-либо другого элемента, который может иметь или не иметь дополнительные родительские элементы. Данная информация крайне важна для определения текущего режима парсинга, который зависит от текущей иерархии дерева. Кроме того, парсинг фрагмента не приводит к выполнению скрипта из соображений безопасности.
Поэтому мы можем использовать код подобный нижеприведенному, но мы не получим дополнительных результатов. Это не приведет к выполнению скрипта.
var foo = document.querySelector('#foo');
foo.innerHTML = '<b>Hallo World!</b><script>alert("Hi.");</script>';
Использование парсинга фрагмента – это легкий способ сократить количество DOM-операций. Вместо того чтобы создавать, изменять и добавлять узлы, каждый из которых включает переключение контекста, а значит и DOM-операции, мы работаем исключительно с построением строки, которая потом оценивается и обрабатывается парсером. Таким образом, у нас получается всего одна или две DOM-операции. Недостаток данного метода заключается в том, что нам нужен парсер, и мы должны проделать больше работы в JavaScript. Основной вопрос заключается в следующем: Что требует больше времени? Являются ли различные DOM-операции более затратными, чем все необходимые манипуляции в JavaScript, или наоборот?
Понятно, что все зависит от ситуации. Что касается данного сценария, Гргур Гризогоно сравнил производительность с помощью нескольких методов. Все это также зависит от браузера, особенно от того, насколько быстрый в нем движок JavaScript. Чем выше значение – тем больше операций, и тем более желателен такой результат.
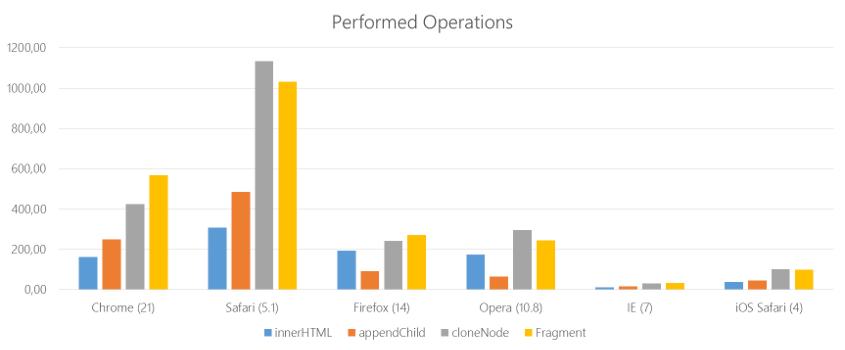
Несмотря на то, что сегодня браузеры намного быстрее, относительное поведение все еще имеет значение. Это должно мотивировать нас искать оптимальные решения и более подробно изучать DocumentFragment.
Обобщенные DOM-операции
Смысл узла DocumentFragment довольно прост: это контейнер для объектов Node. Когда добавляется DocumentFragment, он расширяется до той степени, чтобы добавлять только содержимое контейнера, а не сам контейнер. Когда запрашивается полная копия DocumentFragment, его контент также клонируется. Сам контейнер никогда не прилагается к другому узлу, даже если он должен иметь владельца, которым является document, из которого создан фрагмент.
Создание DocumentFragment выглядит следующим образом:
var fragment = document.createDocumentFragment();
С этой точки зрения, fragment ведет себя точно так же, как и любой другой родительский узел DOM. Мы можем добавлять, удалять узлы или получать доступ к уже существующим узлам. Здесь доступна опция запуска запросов CSS с помощью querySelector и querySelectorAll. Наиболее важно то, что, как уже упоминалось, мы можем клонировать узел с помощью cloneNode().
Создание шаблонов в HTML
По сути DocumentFragment нельзя построить в чистом HTML, так как данная концепция может реализовываться только через DOM API. Поэтому контейнеры можно создавать только в JavaScript. Это значительно преуменьшает имеющиеся преимущества. Мы начнем с помещения нашего шаблона в псевдо-элемент script. Этот элемент является псевдо-элементом, потому что атрибут type будет установлен в недействительный mime-тип. Таким образом, ничего не будет выполняться, но текстовый контент элемента будет использовать другие правила парсинга.
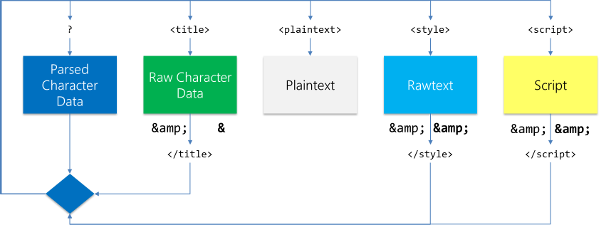
Приведенное выше изображение демонстрирует состояния токенизации. Для тегов script используются особенные правила парсинга, так как парсинг будет выполняться в особенном состоянии токенизации. В HTML существует пять состояний токенизации, но пятое, Plaintext, нам не особо интересно.
Состояние Rawtext очень похоже на Script, а потому нам нужно объяснить только три состояния.
Давайте рассмотрим пример. Мы используем три элемента, которые неплохо отражают каждое из оставшихся состояний. Элемент div, как и многие другие, находится в режиме анализируемых символов (PCData). textarea использует RCData вроде элемента title. Состояние Rawtext даже больше похоже на свободные символы, которые можно представить с использованием элемента style. Между выходом из состояния Rawtext и Script существуют довольно незначительные различия. Поэтому в дальнейшем обсуждении мы будем считать их одинаковыми.
var example = '<br>me & you > them';
var types = ["div", "textarea", "script"];
types.forEach(function (type) {
var foo = document.createElement(type);
foo.innerHTML = example;
console.log(foo.innerHTML);
})
Возможно, мы могли бы ожидать получить одинаковый результат, но, даже понимая, что существуют различия, каким будет конечный результат?
<br>me & you > them
<br>me & you > them
<br>me & you > them
Только в последнем случае строка ввода идеально совпадает. То есть, у нас есть победитель. Но здесь начинается самое интересное. Большинство движков создают функцию из строки, которая берет модель и разбивает ее для просмотра на список сгенерированных DOM-узлов.
Некоторые могут заранее связывать значения, в зависимости от модели. Важнейшей частью является генерирование узла, которое наиболее ориентировано на строку, как минимум при первой итерации.
W3C распознало ситуацию и среагировало путем введения элемента template. Элемент может распознаться как носитель DocumentFragment. Так как DocumentFragment не участвует напрямую в дереве DOM, он прилагается к узлу через свойство.
Использовать элемент довольно просто, что и демонстрирует следующий пример:
<template>
<img src="{src}" alt="{alt}">
<div class="comment">{comment}</div>
</template>
В DOM мы не встретим ни одного дочернего объекта этого элемента. Все дочерние объекты прилагаются к вложенному экземпляру DocumentFragment, доступ к которому можно получить через свойство content.
Давайте получим эти дочерние элементы:
var fragment = document.querySelector('template').content;
var img = fragment.querySelector('img');
var comments = fragment.querySelectorAll('.comment');
Текст, заключен в фигурные скобки, что отображает наше намерение относиться к нему как к заглушке. Здесь нет системы для его автоматического заполнения.
Давайте создадим функцию для возврата обработанных узлов. Для этого подгоним код под предыдущий пример.
function createNodes (model) {
var fragment = document.querySelector('template').content;
var instance = fragment.clone(true);//deep cloning!
var img = instance.querySelector('img');
img.setAttribute('src', model.src);
img.setAttribute('alt', model.alt);
var div = instance.querySelector('div');
div.textContent = model.comment;
return instance;
}
Обобщение возможно путем итерации всех атрибутов элементов и дочерних узлов, заменяя в атрибутах и текстовых узлах текст, соответствующий предварительно заданной структуре. И наконец, обработанные узлы можно куда-нибудь добавить:
var nodes = createNodes({
src: 'image.png',
alt: 'Image',
comment: 'Great!'
});
document.querySelector('#comments').appendChild(nodes);
Существует три важных аспекта элемента template:
- Он вызывает другой режим парсинга. Поэтому он является чем-то большим, чем просто элемент.
- Его дочерний элемент не будет прилагаться к DOM, но будет доступен DocumentFragment через content.
- Нам нужно сделать точную копию фрагмента, прежде чем его использовать.
И наконец, DocumentFragment настолько полезен, что его можно использовать даже для того, чтобы сделать небольшие части сайтов многоразовыми и более гибкими.
Теневой DOM
В последнее время спрос на веб-компоненты существенно вырос. Большинство front-end фреймворков пытаются повторять их структуру. Однако все равно необходимо иметь реальную поддержку DOM, даже несмотря на возможность использовать полифилы.
Теневой DOM позволяет нам добавлять DocumentFragment в любой Element. Существует три ограничения:
- DocumentFragment должен быть специфичным – он должен представлять собой ShadowRoot.
- Каждый Element может содержать только один ShadowRoot, или ни одного.
- Содержимое ShadowRoot должно быть отделено от оригинального DOM.
У этих ограничений есть свои последствия.
Одно из последствий приложения ShadowRoot к элементу заключается в том, что элемент не отображается, вместо него отображается содержимое корневого элемента теневого дерева. Контент имеет особое назначение, что означает, что он может следовать своим собственным правилам оформления.
Также весь процесс обработки события будет немного отличаться. В результате появляется еще одно новое понятие: слоты. Мы можем определить слоты в своем теневом DOM, которые заполнены узлами из элемента, содержащего ShadowRoot. Кажется очевидным, что создание пользовательских элементов, которые содержат теневой DOM – это хорошая идея. Вся спецификация пользовательских элементов является реакцией на это.
Так как же мы можем использовать теневой DOM? Чтобы разобраться в API, выполним немного JavaScript. Начнем со следующего фрагмента HTML:
<div id="#shadow-dialog">
<span slot="header">
My header title
</span>
<div slot="content">
<strong>Some very important content</strong>
</div>
</div>
В этой точке все ведет себя как обычно. Здесь нам потребуются навыки работы с JavaScript:
var context = document.querySelector('#shadow-dialog');
var root = context.attachShadow({ mode: 'open' });
var headerSlot = document.createElement('slot');
headerSlot.name = 'header';
root.appendChild(headerSlot);
var contentSlot = document.createElement('slot');
contentSlot.name = 'content';
root.appendChild(contentSlot);
На данном этапе мы добились немногого. Мы начали с нескольких элементов и вернулись к ним же. Эффективно составленное дерево DOM выглядит следующим образом:
<div id="#shadow-dialog">
<slot name="header">
<span slot="header">
My header title
</span>
</slot>
<slot name="content">
<div slot="content">
<strong>Some very important content</strong>
</div>
</slot>
</div>
По умолчанию всем узлам нашего теневого корня назначен стандартный слот, если он есть. Слот по умолчанию не имеет свойства name. Так чего же мы добились? Мы интегрировали несколько прозрачных элементов. Но, что более важно, – чтобы изменить структуру, атрибуты или разметку нашего древа DOM, не обязательно изменять нашу изначальную разметку. Нам нужно только изменить то, какие элементы будут добавляться в теневой корень, и все. Мы разбили front-end на модули.
Теперь можно подумать, что у нас уже были подобные техники на сервере. И конечно же, некоторые клиентские фреймворки также пытались обобщить код подобным образом. Однако здесь есть некоторые основные отличия.
Во-первых, у нас есть полная поддержка браузера.
Во-вторых, песочница упрощает отрисовку данного модуля по особым правилам – никаких накладок с существующими правилами CSS. Это гарантирует, что модуль будет работать на каждой странице. Больше никакой отладки в поиске, где правила CSS мешают друг другу. И наконец, у нас получается более аккуратный код. Его легко генерировать и переносить, и мы можем ожидать большей производительности.
Заключение
DocumentFragment – это эффективный помощник, который обладает способностью существенно сокращать количество DOM-операций. Также он является важным краеугольным камнем современных технологий, особенно в сфере веб-компонентов. Он уже привел к появлению двух выдающихся технологий: элемента template и ShadowRoot. В то время, как первый значительно упрощает создание шаблонов, позволяя неплохо повысить производительность и легко переносить предварительно сгенерированные узлы, второй является основой компонентов.
Быстрее ли виртуальный DOM реального? Конечно, но он может оказаться не настолько быстрым, если не использовать DocumentFragment для обобщения множественных операций.
> Принимайте оплату от компаний через Интернет. Без сайта, ИП и ООО.
> Приём платежей от компаний для Вашего сайта. С документооборотом и обменом оригиналами.
> Автоматизация продаж и обслуживание сделок с юр.лицами. Без посредника в расчетах.
Комментарии (7)

grobitto
16.12.2015 02:49+3Какой же плохой перевод

withkittens
16.12.2015 14:49+3Зря человека минусуете.
Возможно, мы могли бы ожидать получить одинаковый результат, но, даже зная, в чем заключаются различия, кто знает, как они выглядят?
Оригинал:
<br>me & you > them <br>me & you > them <br>me & you > them
Maybe we would expect that the output is the same, but even knowing that there are differences: Who knows what they look like?
Мало того, что английские конструкции переводили дословно, причём неправильно (см. болд), так ведь парсер съел все теги, смысл текста потерялся от слова совсем, и переводчику по фиг! У меня в голове не укладывается, как может быть не стыдно выкладывать на хабр такие помои? Или это и есть новый уровень хабра?
<br>me & you > them <br>me & you > them <br>me & you > themgrobitto
16.12.2015 15:27Угу, я пока читал, было ощущение, что читаю про предметную область, в которой ничего не понимаю. Прочитал оригинал и все встало на свои места.
Для себя кстати отличное решение открыл — чистить html от вредного кода на клиенте через обработку DOM DocumentFragment. Через обычный DOM нельзя — могут выполниться скрипты на onerror, например, а через фрагмент — скрипты не выполняются.
Оказалось, что такое решение уже есть: github.com/cure53/DOMPurify

Nookie-Grey
16.12.2015 14:58Chrome 21, IE7… Ребят, какого года данные? Зависит от браузера? А от ОС, а от машины?
Оппа… Реклама на хабре…
Хотя, справедливости ради надо сказать, что виртуальный дум — это очень интересная тема
Irina_Ua
16.12.2015 15:29Следующая фраза подчеркивает тот момент, что тестирование проводилось несколько ранее
Несмотря на то, что сегодня браузеры намного быстрее...
rozhik
Хороший выбор статьи для перевода.
P.S. «является ocumentFragment» — пропущена 'd'.
Irina_Ua
Спасибо