Ещё один шаг в самообучении машин
Конечно, в Data Science существует множество самообучающихся моделей, но действительно ли они являются таковыми? На самом деле, нет: сейчас в машинном обучении сложилась ситуация, когда человеческий фактор играет решающую роль в построении эффективных моделей.
Data Science сейчас представляет собой некий сплав науки и интуиции, потому что не существует формализованного знания о том, как правильно предобрабатывать предикторы, какую модель выбрать из десятков существующих, и как настраивать множество параметров в этой модели. Всё это плохо поддается формализации, и поэтому получается парадоксальная ситуация – машинное обучение требует человеческого фактора.
Именно человек должен выстроить цепочку обучения, и настроить параметры, которые легко могут превратить самую лучшую модель в абсолютно бесполезную. Построение этой цепочки, превращающей исходные данные в предсказательную модель – может занимать несколько недель, в зависимости от сложности задачи, и часто делается просто методом проб и ошибок.
Это серьезный недостаток, и поэтому возникла идея: может ли машинное обучение — обучить себя тому же, что делает человек? Такая система была создана, и удивительно, что эта новость еще не добралась до хабрасообщества!
ТРОТ (Tree-based Pipeline Optimization Tool)
Ренди Ольсон (Randy Olson), аспирант из Computational Genetics Lab (University of Pennsylvania) в качестве своего дипломного проекта разработал систему ТРОТ (Tree-based Pipeline Optimization Tool).
Эта система позиционируется как Data Science помощник. Она автоматизирует самую утомительную часть машинного обучения, изучая и подбирая среди тысячи возможных цепочек построения именно ту, которая лучше всего подойдёт для обработки ваших данных.
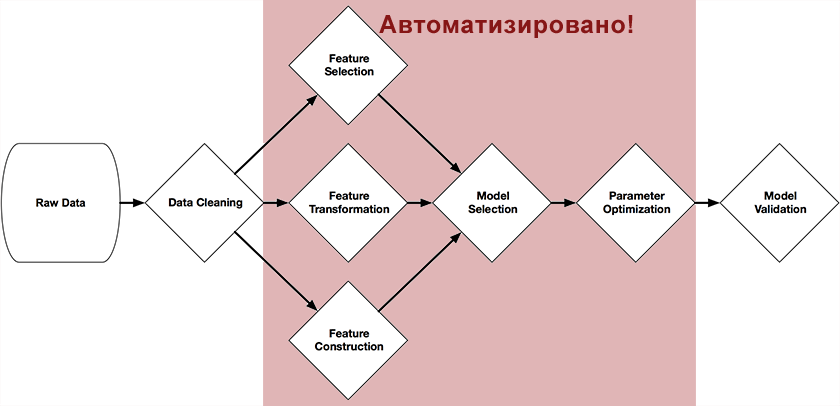
Система была написана на Питоне с использованием библиотеки scikit-learn, и посредством генетических алгоритмов самостоятельно строит полную цепочку подготовки и построения модели. На рисунке в начале этой статьи представлены те части цепочки, которые можно автоматизировать с её помощью: предобработка и выбор предикторов, выбор моделей, оптимизация их параметров.
Идея достаточно проста – генетический алгоритм.
Это алгоритм поиска нужной нам цепочки путём случайного подбора, с использованием механизмов, аналогичных естественному отбору в природе. О них достаточно подробно написано в википедии, на хабре, или в книге «Самообучающиеся системы» (рекомендую для интересующихся этой темой, есть в сети в электронном виде).
В качестве функции отбора (Fitness функции) выступает точность предсказания в тестовой выборке, в качестве объекта популяции – scikit-методы и их параметры.
Результаты
У автора представлен простой пример того, как можно использовать TPOT для решения эталонной задачи по классификации рукописных цифр из набора MNIST
from tpot import TPOT
from sklearn.datasets import load_digits
from sklearn.cross_validation import train_test_split
digits = load_digits()
X_train, X_test, y_train, y_test = train_test_split(digits.data, digits.target, train_size=0.75)
tpot = TPOT(generations=5, verbosity=2)
tpot.fit(X_train, y_train)
print( tpot.score(X_train, y_train, X_test, y_test) )
tpot.export('tpot_exported_pipeline.py')
При запуске кода, через пару минут TPOT может получить цепочку построения модели, точность которой достигает 98%. Это произойдёт в том случае, когда TPOT обнаружит что классификатор Random Forest отлично работает на данных MNIST.
Правда, так как этот процесс вероятностный, для повторяемости результатов рекомендуется задавать параметр random_state – у меня, например, за 5 поколений нашлась только цепочка с SVC и KNeighborsClassifier.
Проверка системы на ещё одной классической задаче, ирисах Фишера, дало точность 97% за 10 поколений.
Будущее
ТРОТ – это опенсорсный проект, который возник всего месяц назад (что для таких систем вообще детский возраст) и сейчас активно развивается. На сайте проекта автор призывает сообщество Data Scientists присоединятся к развитию системы, код которой доступен на гитхаб (https://github.com/rhiever/tpot)
Конечно, сейчас система очень далека от идеала, но идея этой системы выглядит крайне логичной – полная автоматизация всего процесса машинного обучения. И если идея будет развиваться – то возможно, скоро появятся системы, где от человека требуется лишь загрузить данные, и получить результат. И тогда возникнет другой вопрос: А нужен ли вообще человек для построения самообучающихся моделей?

Комментарии (4)
zim32
18.12.2015 21:52А есть уже системы которые строят нейросети из обычных персональных компьютеров?

Sadler
22.12.2015 11:24В каком смысле «из персональных компьютеров»? Обсчёт слоёв можно проводить независимо, а затем распараллелить на сколько нужно компьютеров любой библиотекой под Ваш любимый язык программирования. Другое дело, GPU для таких расчётов подходит куда больше, нежели CPU в силу необходимости обработки огромного числа связей нейронов, поэтому пришлось бы ещё повозиться с той же CUDA.
SantyagoSeaman
Это может работать только на небольших датасетах. В ситуации, приближенной к боевой, когда одна модель может считаться сутки, рандомный перебор предикторов и поиск цепочки алгоритмов займёт время начиная приближенное к бесконечности.
Очистку данных, генерацию композитных предикторов вообще вряд ли получится автоматизировать.
И самое главное. Получение модели — это прекрасно для теоретиков и конкурсов. Главная задача — получить модель, пригодную к использовании в продакшене. И тут без человека точно не обойтись.