Предположим есть аккаунт в Твиттере, в который пишут на достаточно ограниченный круг тем, на который подписано несколько сотен или тысяч человек. Как понять какая доля аудитории ещё не охвачена? Как найти этих людей?
Для примера рассмотрим аккаунт @Russia_Direct. Это небольшое издание, которое освещает события в России для англоязычных читателей. Что-то типа Russia Today, но с более глубокими и академичными материалами.

Сейчас на них подписаны ~4000 человек — студенты, журналисты, преподаватели университетов:

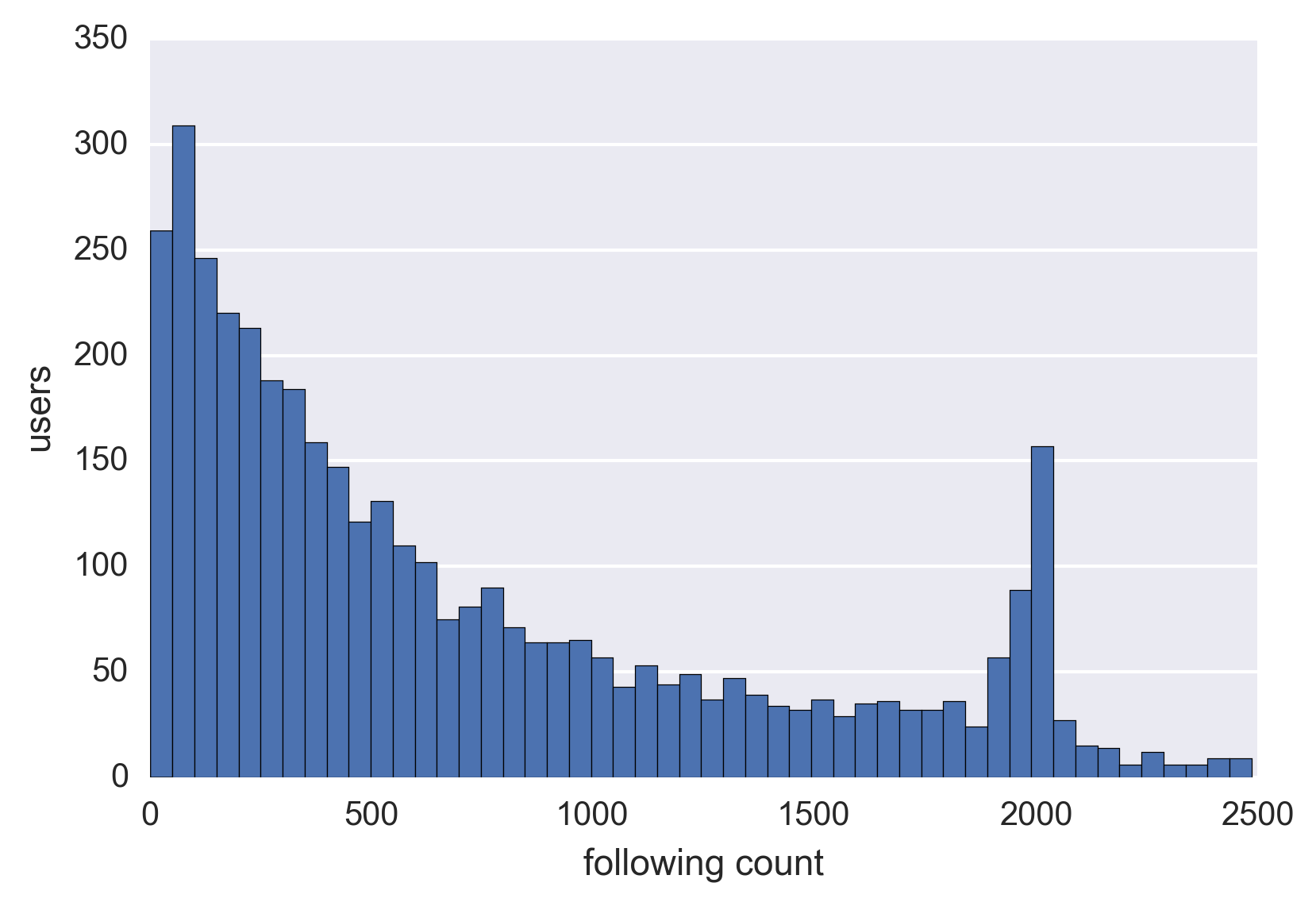
В среднем их подписчики фолловят 500 аккаунтов. Есть какой-то странный гребень в районе 2000. То есть аномально много людей фолловят ~2000 аккаунтов. Возможно, это роботы? Кто знает, напишите в комментариях.
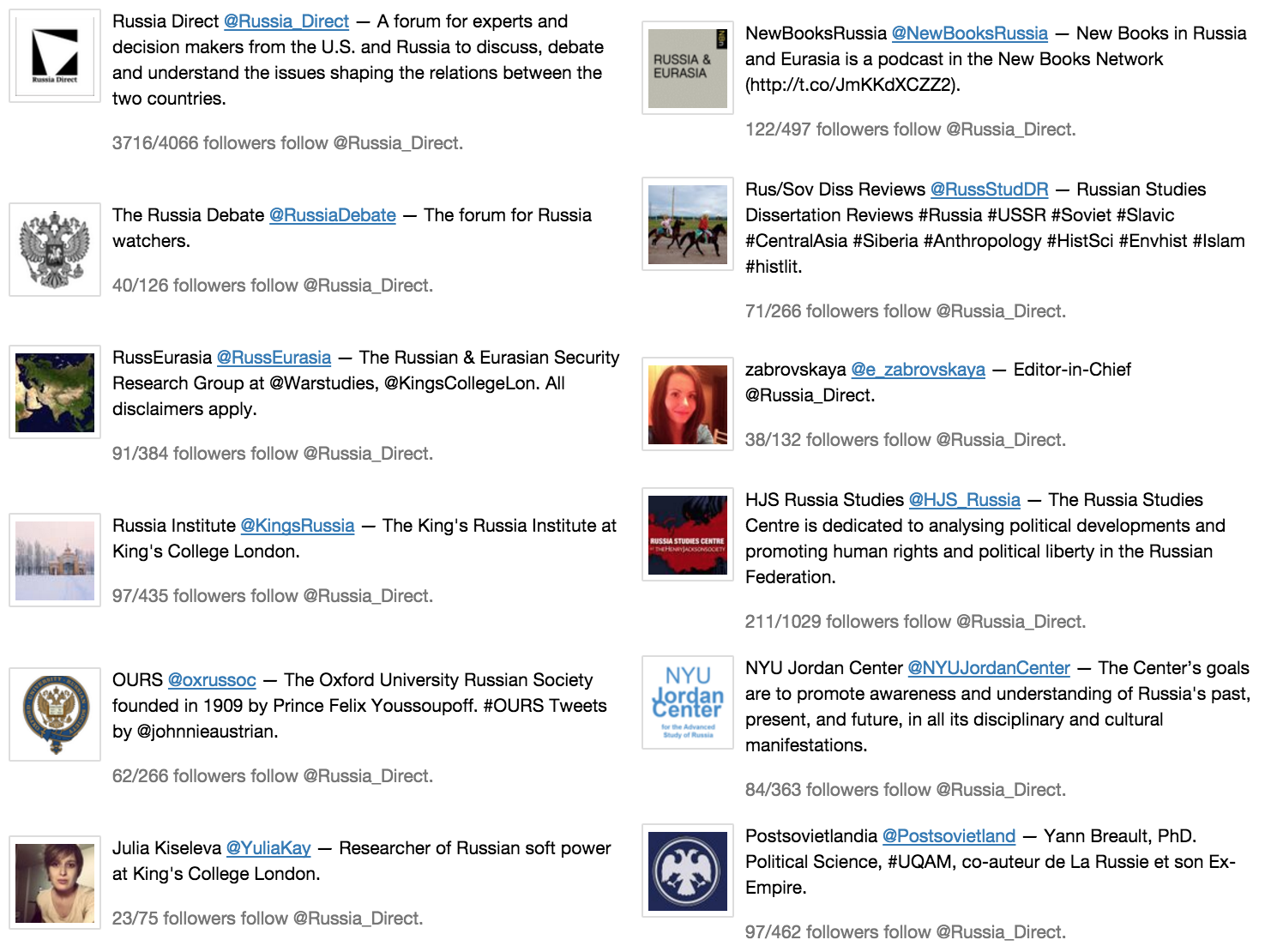
Посмотрим кого кроме RD фолловят эти люди. У Твиттера совершенно драконовские лимиты на обращения к АПИ, забирать список подписок можно только раз минуту. Поэтому на 4000 пользователей нужно потратить 4000 минут. Ничего, ждём пол недели, получаем список из 4 000 000 аккаунтов. Сортируем его по доле аудитории, которая подписана на RD, смотрим на топ и видим интересное:
Здесь нужно упомянуть, что просто так считать долю подписчиков нельзя, в топе будут аккаунты, у которых всего 1 фолловер, из них доля подписанных на RD автоматически 100%. Можно выкидывать мелкие аккаунты, но непонятно по какому порогу. 50 фолловеров — это мало или достаточно? В таких случаях я люблю использовать для сортировки не долю (n / N), а вот такой показатель n / N — 3 sqrt(n (N — n + 1) / N3). Почему именно его, можно понять, например, из Probabilistic Programming and Bayesian Methods for Hackers.
Таким образом, у нас на руках оказывается список аккаунтов похожих на RD. Этот список сам по себе полезен. Можно посмотреть какие есть конкуренты, о чём они пишут. Собрать потенциальных фолловеров теперь несложно, нужно скачать списки фолловеров похожих аккаунтов и посмотреть, какие пользователи встречаются несколько раз. Вот, например, некий румынский чиновник подписан на 5 похожих на RD аккаунтов, а на RD не подписан:

И таких очень много.


Может возникнуть необходимость отделить аккаунты людей от аккаунтов организаций. В первом приближении можно считать, что если на аватарке есть лицо, значит это человек. Простейший код с использованием OpenCV неплохо справляется с задачей:
Дальше этих людей можно исследовать, писать им сообщения и твиты, фолловить и настраивать рекламные кампании.
Для примера рассмотрим аккаунт @Russia_Direct. Это небольшое издание, которое освещает события в России для англоязычных читателей. Что-то типа Russia Today, но с более глубокими и академичными материалами.
Сейчас на них подписаны ~4000 человек — студенты, журналисты, преподаватели университетов:
В среднем их подписчики фолловят 500 аккаунтов. Есть какой-то странный гребень в районе 2000. То есть аномально много людей фолловят ~2000 аккаунтов. Возможно, это роботы? Кто знает, напишите в комментариях.
Посмотрим кого кроме RD фолловят эти люди. У Твиттера совершенно драконовские лимиты на обращения к АПИ, забирать список подписок можно только раз минуту. Поэтому на 4000 пользователей нужно потратить 4000 минут. Ничего, ждём пол недели, получаем список из 4 000 000 аккаунтов. Сортируем его по доле аудитории, которая подписана на RD, смотрим на топ и видим интересное:
- Например, из 497 подписчиков @NewBooksRussia 122 подписаны на RD. Значит аудитория этих двух аккаунтов очень похожа. Грубо говоря, можно считать, что остальные 375 подписчиков @NewBooksRussia — это потенциальные фолловеры RD.
- На первом месте, конечно, RD. Почему не 100% подписчиков RD подписаны на RD? В силу ряда технических причин. Некоторые профили под замочком, для них список подписок получить нельзя. Иногда АПИ отвечает странными ошибками.
Здесь нужно упомянуть, что просто так считать долю подписчиков нельзя, в топе будут аккаунты, у которых всего 1 фолловер, из них доля подписанных на RD автоматически 100%. Можно выкидывать мелкие аккаунты, но непонятно по какому порогу. 50 фолловеров — это мало или достаточно? В таких случаях я люблю использовать для сортировки не долю (n / N), а вот такой показатель n / N — 3 sqrt(n (N — n + 1) / N3). Почему именно его, можно понять, например, из Probabilistic Programming and Bayesian Methods for Hackers.
Таким образом, у нас на руках оказывается список аккаунтов похожих на RD. Этот список сам по себе полезен. Можно посмотреть какие есть конкуренты, о чём они пишут. Собрать потенциальных фолловеров теперь несложно, нужно скачать списки фолловеров похожих аккаунтов и посмотреть, какие пользователи встречаются несколько раз. Вот, например, некий румынский чиновник подписан на 5 похожих на RD аккаунтов, а на RD не подписан:
И таких очень много.
Может возникнуть необходимость отделить аккаунты людей от аккаунтов организаций. В первом приближении можно считать, что если на аватарке есть лицо, значит это человек. Простейший код с использованием OpenCV неплохо справляется с задачей:
Дальше этих людей можно исследовать, писать им сообщения и твиты, фолловить и настраивать рекламные кампании.

and7ey
Было бы здорово, если бы вы поделились кодом.