Сфера деятельности нашей компании распространяется далеко за пределы игровой разработки. Параллельно с ней мы ведем десятки внутренних проектов, и Data Driven Realtime Rule Engine (DDRRE) – один из наиболее амбициозных.
Data Driven Realtime Rule Engine – специальная система, которая при помощи анализа больших массивов данных в режиме реального времени позволяет персонифицировать взаимодействие с игроком через рекомендации, поступающие пользователю исходя из контекста его последнего игрового опыта.
DDRRE позволяет нашим игрокам получать больше удовольствия от игры, улучшает их пользовательский опыт, а также избавляет от просмотра ненужных рекламных и промо-сообщений.
Архитектура DDRRE
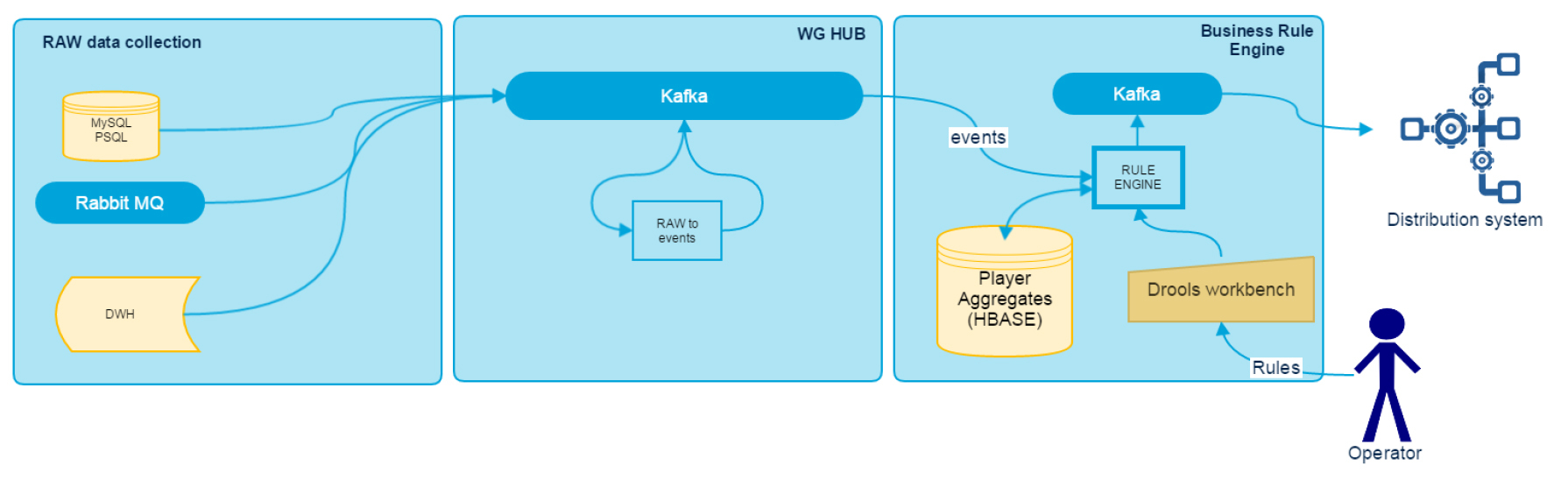
Data Driven Realtime Rule Engine можно условно разделить на несколько компонентов: RAW Data Collection, WG HUB и Business Rule Engine. Их архитектуру можно увидеть на схеме.
В этой статье мы расскажем об адаптерах для сбора и анализа данных, а в следующих публикациях подробно рассмотрим другие компоненты системы.
Сбор данных ведется при помощи общей шины, в качестве которой используется Kafka. Все подсистемы World of Tanks Blitz в режиме реального времени записывают логи установленного формата в шину. Для подсистем, которые в силу технических ограничений не могут этого сделать, мы написали адаптеры, собирающие и перенаправляющие логи в Kafka. В частности, наш стек содержит адаптеры для MySQL, PSQL, RabbitMQ, а также адаптер для загрузки архивных данных из DWH, через Hive JDBC-интерфейс. Каждый из них экспортирует метрики о скорости обработки и отставании от источника в JMX, где для визуализации данных используется Grafana, а для нотификации о проблемах — Zabbix. Все адаптеры разработаны как standalone Java-приложения на Java 8 и Scala.
Адаптер для MySQL, PSQL
За основу взят Tungsten replicator, к которому написан продюсер в Kafka. Мы используем репликацию, так как это надёжный способ получения данных без дополнительной нагрузки на сервер БД источника данных.
Текущий pipeline в Tungsten выглядит следующим образом:
где модуль asynckafka написан нами.
Asynckafka получает данные от предыдущего stage и записывает в Kafka. Последний записанный offset сохраняется в zookeeper, ведь он всегда есть вместе с Kafka. Как вариант tungsten может сохранять данные в файл или MySQL, но это не очень надёжно в случае потери хоста с адаптером. В нашем случае, при крэше модуль вычитывает offset и обработка бинлогов продолжается с последнего сохранённого в Kafka значения.
Запись в Kafka
Сохранение offset
Восстановление offset
Адаптер для RabbitMQ
Достаточно простой адаптер, который перекладывает данные из одной очереди в другую. Записи по одной переносятся в Kafka, после чего проводится acknowledge в RabbitMQ. Сервис гарантировано доставляет сообщение как минимум один раз, дедупликация происходит на стороне обработки данных.
Адаптер для DWH
Когда необходимо обработать исторические данные, мы обращаемся в DWH. Хранилище построено на технологиях Hadoop, поэтому для получения данных мы используем Hive или Impala. Чтобы интерфейс загрузки был более универсален, мы реализовали его через JDBC. Основной проблемой работы с DWH является то, что данные в нем нормализованы, а для сбора документа целиком, необходимо объединить несколько таблиц.
Что имеем на входе:
• данные необходимых таблиц партиционированы по дате
• известен период, за который хотим загрузить данные
• известен ключ группировки документа для каждой таблицы.
Чтобы сгруппировать таблицы:
• используем Spark SQL Data Frame
• интегрируем циклом по датам из заданного диапазона
• несколько DataFrame объединяем по ключу группировки в один документ и записываем в Kafka с использованием Spark.
Пример настройки Datasource с помощью property файла.
В этом примере мы строим два DataFrame.
Приложение считает количество дней между указанными датами и выполняет цикл из конфигурационного файла:
hdfs_kafka.from=2015-06-25
hdfs_kafka.to=2015-06-26
О том, как проводится обработка собранной информации, а также других компонентах DDRRE, мы расскажем в следующем посте. Если у вас есть какие-то вопросы об описанных технологиях – обязательно задавайте их в комментариях.
Data Driven Realtime Rule Engine – специальная система, которая при помощи анализа больших массивов данных в режиме реального времени позволяет персонифицировать взаимодействие с игроком через рекомендации, поступающие пользователю исходя из контекста его последнего игрового опыта.
DDRRE позволяет нашим игрокам получать больше удовольствия от игры, улучшает их пользовательский опыт, а также избавляет от просмотра ненужных рекламных и промо-сообщений.
Архитектура DDRRE
Data Driven Realtime Rule Engine можно условно разделить на несколько компонентов: RAW Data Collection, WG HUB и Business Rule Engine. Их архитектуру можно увидеть на схеме.
В этой статье мы расскажем об адаптерах для сбора и анализа данных, а в следующих публикациях подробно рассмотрим другие компоненты системы.
Сбор данных ведется при помощи общей шины, в качестве которой используется Kafka. Все подсистемы World of Tanks Blitz в режиме реального времени записывают логи установленного формата в шину. Для подсистем, которые в силу технических ограничений не могут этого сделать, мы написали адаптеры, собирающие и перенаправляющие логи в Kafka. В частности, наш стек содержит адаптеры для MySQL, PSQL, RabbitMQ, а также адаптер для загрузки архивных данных из DWH, через Hive JDBC-интерфейс. Каждый из них экспортирует метрики о скорости обработки и отставании от источника в JMX, где для визуализации данных используется Grafana, а для нотификации о проблемах — Zabbix. Все адаптеры разработаны как standalone Java-приложения на Java 8 и Scala.
Адаптер для MySQL, PSQL
За основу взят Tungsten replicator, к которому написан продюсер в Kafka. Мы используем репликацию, так как это надёжный способ получения данных без дополнительной нагрузки на сервер БД источника данных.
Текущий pipeline в Tungsten выглядит следующим образом:
replicator.pipelines=slave
replicator.pipeline.slave=d-binlog-to-q,q-to-kafka
replicator.pipeline.slave.stores=parallel-queue
replicator.pipeline.slave.services=datasource
replicator.pipeline.slave.syncTHLWithExtractor=false
replicator.stage.d-binlog-to-q=com.continuent.tungsten.replicator.pipeline.SingleThreadStageTask
replicator.stage.d-binlog-to-q.extractor=dbms
replicator.stage.d-binlog-to-q.applier=parallel-q-applier
replicator.stage.d-binlog-to-q.filters=replicate,colnames,schemachange
replicator.stage.d-binlog-to-q.blockCommitRowCount=${replicator.global.buffer.size}
replicator.stage.q-to-kafka=com.continuent.tungsten.replicator.pipeline.SingleThreadStageTask
replicator.stage.q-to-kafka.extractor=parallel-q-extractor
replicator.stage.q-to-kafka.applier=asynckafka
replicator.stage.q-to-kafka.taskCount=${replicator.global.apply.channels}
replicator.stage.q-to-kafka.blockCommitRowCount=${replicator.global.buffer.size}
где модуль asynckafka написан нами.
Asynckafka получает данные от предыдущего stage и записывает в Kafka. Последний записанный offset сохраняется в zookeeper, ведь он всегда есть вместе с Kafka. Как вариант tungsten может сохранять данные в файл или MySQL, но это не очень надёжно в случае потери хоста с адаптером. В нашем случае, при крэше модуль вычитывает offset и обработка бинлогов продолжается с последнего сохранённого в Kafka значения.
Запись в Kafka
override def commit(): Unit = {
try {
import scala.collection.JavaConversions._
val msgs : java.util.concurrent.ConcurrentLinkedQueue[(String,String,String,Option[Callback])] = new java.util.concurrent.ConcurrentLinkedQueue[(String,String,String,Option[Callback])]()
data.foreach(e => {
msgs.addAll(ruleProcessor.get.processToMsg(e._1, e._2).map(e => (e._1, e._2, e._3, None)))
})
kafkaSender.get.send(msgs.toSeq:_*)
} catch {
case kpe:
KafkaProducerException => {
logger.error(kpe.getMessage, kpe)
throw new ReplicatorException(kpe);
}
}
lastHeader.map(saveLastHeader(_))
resetEventsToSend()
}
Сохранение offset
def saveLastHeader(header: ReplDBMSHeader): Unit = {
zkCurator.map {
zk =>
try {
val dhd = DbmsHeaderData(
header.getSeqno,
header.getFragno,
header.getLastFrag,
header.getSourceId,
header.getEpochNumber,
header.getEventId,
header.getShardId,
header.getExtractedTstamp.getTime,
header.getAppliedLatency,
if (null == header.getUpdateTstamp) {
0
} else {
header.getUpdateTstamp.getTime
},
if (null == header.getTaskId) {
0
} else {
header.getTaskId
})
logger.info("{}", writePretty(dhd))
zk.setData().forPath(getZkDirectoryPath(context), writePretty(dhd).getBytes("utf8"))
} catch {
case t: Throwable => logger.error("error while safe last header to zk", t)
}
}
}
Восстановление offset
override def getLastEvent: ReplDBMSHeader = {
lastHeader.getOrElse {
var result = new ReplDBMSHeaderData(0, 0, false, "", 0, "", "", new Timestamp(System.currentTimeMillis()), 0)
zkCurator.map {
zk =>
try {
val json = new String(zk.getData().forPath(getZkDirectoryPath(context)), "utf8")
logger.info("found previous header {}", json)
val headerDto = read[DbmsHeaderData](json)
result = new ReplDBMSHeaderData(headerDto.seqno, headerDto.fragno, headerDto.lastFrag, headerDto.sourceId, headerDto.epochNumber, headerDto.eventId, headerDto.shardId, new Timestamp(headerDto.extractedTstamp), headerDto.appliedLatency, new Timestamp(headerDto.updateTstamp), headerDto.taskId)
} catch {
case t: Throwable => logger.error("error while safe last header to zk", t)
}
}
result
}
}
Адаптер для RabbitMQ
Достаточно простой адаптер, который перекладывает данные из одной очереди в другую. Записи по одной переносятся в Kafka, после чего проводится acknowledge в RabbitMQ. Сервис гарантировано доставляет сообщение как минимум один раз, дедупликация происходит на стороне обработки данных.
RabbitMQConsumerCallback callback = new RabbitMQConsumerCallback() {
@Override
public void apply(String consumerTag, Envelope envelope, AMQP.BasicProperties properties, byte[] body) { // callback-функция при получении данных от RabbitMQ
String routingKey = envelope.getRoutingKey();
Tuple3<String, String, String> routingExpr = routingExprMap.get(routingKey); // Получение topic и ключ партиционирования Kafka по конфигу в зависимости от входящего routingKey
if (routingExpr == null)
throw new RuntimeException("No mapping for routing key " + routingKey);
String expr = routingExpr._1(),
topic = Objects.firstNonNull(routingExpr._2(), kafkaProducerMainTopic),
sourceDoc = routingExpr._3();
Object data = rabbitMQConsumerSerializer.deserialize(body); // десериализация входящего сообщения, десериализатор указан в конфиге
RabbitMQMessageEnvelope msgEnvelope = new RabbitMQMessageEnvelope(envelope, properties, data, sourceDoc); //создание исходящего сообщения в соответствии с установленным форматом
byte[] key = getValueByExpression(data, expr).getBytes();
byte[] msg = kafkaProducerSerializer.serialize(msgEnvelope);
kafkaProducer.addMsg(topic, key, msg, envelope.getDeliveryTag()); // отсылка сообщения в Kafka
try {
checkForSendBatch();
} catch (IOException e) {
this.errBack(e);
}
}
@Override
public void errBack(Exception e) {
logger.error("{}", e.fillInStackTrace());
close();
}
Адаптер для DWH
Когда необходимо обработать исторические данные, мы обращаемся в DWH. Хранилище построено на технологиях Hadoop, поэтому для получения данных мы используем Hive или Impala. Чтобы интерфейс загрузки был более универсален, мы реализовали его через JDBC. Основной проблемой работы с DWH является то, что данные в нем нормализованы, а для сбора документа целиком, необходимо объединить несколько таблиц.
Что имеем на входе:
• данные необходимых таблиц партиционированы по дате
• известен период, за который хотим загрузить данные
• известен ключ группировки документа для каждой таблицы.
Чтобы сгруппировать таблицы:
• используем Spark SQL Data Frame
• интегрируем циклом по датам из заданного диапазона
• несколько DataFrame объединяем по ключу группировки в один документ и записываем в Kafka с использованием Spark.
Пример настройки Datasource с помощью property файла.
hdfs_kafka.dataframe.df1.uri="jdbc:hive2://[HiveUri]:10000/test;user=hdfs" // jbdc uri
hdfs_kafka.dataframe.df1.sql=select * from test.log_arenas_p1_v1 where dt='%s' hdfs_kafka.dataframe.df1.keyField=arena_id // SQL-выражение про ‘%s’ плейсхолдер
hdfs_kafka.dataframe.df1.outKeyField=arena_id // указывает, по какому полю из датафрейма достаётся ключ.
hdfs_kafka.dataframe.df1.tableName=test.log_arenas_p1_v
hdfs_kafka.dataframe.df2.uri="jdbc:hive2://[HiveUri]:10000/test;user=hdfs"
hdfs_kafka.dataframe.df2.sql=select * from test.log_arenas_members where dt='%s' hdfs_kafka.dataframe.df2.keyField=arena_id
hdfs_kafka.dataframe.df2.outKeyField=arena_id // поле, которое является ключом для записи в Kafka
hdfs_kafka.dataframe.df2.tableName=test.log_arenas_members_p1_v // имя таблицы, идёт в тело сообщения
В этом примере мы строим два DataFrame.
Приложение считает количество дней между указанными датами и выполняет цикл из конфигурационного файла:
hdfs_kafka.from=2015-06-25
hdfs_kafka.to=2015-06-26
val dates = Utils.getRange(configuration.dateFormat, configuration.from, configuration.to) // Получить список дат, для которых выполнять sql выражения из настройки датафреймов
dates.map( date => { // Основной цикл приложения
val dataFrames = configuration.dataframes.map( dfconf => {
val df = executeJdbc(sqlContext, Utils.makeQuery(dfconf.sql, date), dfconf.uri)
(dfconf, df)
})
val keysExtracted = dataFrames.map( e => { // Построение массива DataFrame
dataFrameProcessor.extractKey(e._2.rdd, e._1.keyField, e._1.tableName)
}) //Метод для получения RDD[Key, Row] используя keyBy по полю keyField в настройке
val grouped = keysExtracted.reduce(_.union(_)).map( e => (e._1, Seq(e._2))) // Объединение всех dataFrame в один
grouped.reduceByKey(_ ++ _) // Группировка Row по ключу
dataFrameProcessor.applySeq(grouped)
}) // Обработка и отправка сообщений
О том, как проводится обработка собранной информации, а также других компонентах DDRRE, мы расскажем в следующем посте. Если у вас есть какие-то вопросы об описанных технологиях – обязательно задавайте их в комментариях.
Комментарии (8)



m52
23.12.2015 13:28> PRMP позволяет нашим игрокам получать больше удовольствия от игры, улучшает их пользовательский опыт
Забавно читать такое от компании, которую игроки уже больше пары лет поливают говном. Если ваша система должна помогать получать больше удовольствия от игры, то спешу разочаровать — она не выполняет своих функций.
aleks_raiden
23.12.2015 13:31я вас расстрою — нет ни одной игры в мире, которая бы нравилась всем прям. Но глядя на статистику, цифры говорят всегда обратное.
facha
Пожалуйста, расскажите подробней, какую задачу решает вся эта инфраструктура. Вы вскользь упомянули про «при помощи анализа больших массивов данных в режиме реального времени позволяет персонифицировать взаимодействие с игроком через рекомендации». Но что именно там такое анализируется и зачем оно пользователю? Могли бы привести конкретные примеры?
Wargaming
Анализ в режиме реального времени позволяет собирать боевую и финансовую активность игроков и, исходя из опытных данных, выстраивать с коммуникацию. Например, мы видим, что новичок в игре не понимает особенности тактики. Свои первые 100 боев он с мучениями и проблемами отыграл на ПТ САУ. Процент побед низкий, удовольствия от игры мало. В такой ситуации мы предлагаем ему несколько обучающих материалов, которые помогут ознакомиться с стратегией ведения боя на ПТ САУ.