Существует множество решений для построения катастрофоустойчивых систем с использованием технологий консолидации и виртуализации вычислительных ресурсов, кластерных систем, технологий репликации и непрерывной защиты данных, и заказчик может построить катастрофоустойчивый ЦОД либо самостоятельно, либо с использованием площадок коммерческих дата-центров и услуг провайдеров.
Сегодня почти в каждой компании, активно использующей ИТ для поддержки бизнеса, существует свой центр обработки данных (ЦОД). Повышение требований к надежности ЦОД – одна из тенденций рынка. Поскольку дата-центр нередко является ключевым элементом бизнеса компании, специалисты давно ищут экономичные способы повышения его надежности. Причем рано или поздно возникает необходимость обеспечить не только аппаратную надежность ЦОД, но и его катастрофоустойчивость.

По данным исследования EMC, 82% организаций в мире не полностью уверены в том, что смогут восстановить свои системы и данные. Внеплановые простои и потери данных обходятся организациям по всему миру ежегодно более чем в 1,7 млрд. долларов. Согласно исследованию Acronis, в России только 2% опрошенных компаний абсолютно уверены в том, что их ИТ-инфраструктура выдержит любые испытания. 49% российских специалистов ожидают длительных перебоев в её работе в случае стихийного бедствия или аварии.
По данным зарубежной статистики, наиболее частые причины аварий – это отказы оборудования (24%), систем электропитания (16%), ураганы (16%) и наводнения (15%).

В любых технически сложных системах аварии неизбежны, однако их можно сделать не критичными для бизнеса. Для предотвращения таких ситуаций создаются катастрофоустойчивые системы – на территориально удаленной площадке развертываются резервные мощности. Но для начала определимся с терминами, описывающими системы высокой надежности.

Катастрофоустойчивость (Disaster Recovery, DR) – это способность к восстановлению после катастрофы, то есть устойчивость к воздействию природных катаклизмов и террористических актов. Отказоустойчивость (Fault-Tolerance, FT) – свойство системы сохранять работоспособность после отказа одного или нескольких компонентов. О высокой доступности (High Availability, HA) говорят в том случае, когда системы в состоянии выполнять требуемую функцию при заданных условиях в данный момент времени или в течение заданного интервала времени. Непрерывность бизнеса (Business Continuity, ВС) – это процессы, методы и оборудование для безостановочного выполнение критичных бизнес-функций. И, наконец, RTO (Recovery Time Objective) – время, за которое возможно восстановить ИТ-систему, RPO (Recovery Point Objective) – сколько данных будет потеряно при аварийном восстановлении, RCO (Recovery Capacity Objective) – какую часть нагрузки должна обеспечивать резервная система.
Для защиты от природных, техногенных катастроф или терактов и обеспечения непрерывности бизнес-процессов необходимо резервирование основных систем хранения и обработки данных. В случае катастрофы может пострадать здание центра обработки данных, поэтому необходимо создание территориально удаленной площадки – резервного дата-центра. Когда уровня надежности Tier III не хватает, географически распределенная катастрофоустойчивая инфраструктура ЦОД способна гарантировать доступность четыре и даже пять девяток.
Распределение ЦОД по нескольким площадкам требует организации резервируемых каналов связи, репликации данных между хранилищами, планирования резервного копирования и восстановления систем. Нужен механизм синхронизации данных для обеспечения их актуальности данных в случае отказа одного из узлов и для поддержки работы тех информационных систем, которым требуется такая синхронизация. Критическим параметром, помимо пропускной способности, является задержка передачи данных.

Возможны две основных стратегии использования распределенных ЦОД – «активный/активный», когда инфраструктурные приложения и сервисы распределены между площадками, и пользователи работают с ближайшим ЦОД, либо «активный/пассивный», при которой приложения централизованы, и пользователи работают с основным узлом. В случае отказа системы, нагрузка автоматически переключается на резервный ЦОД. Возможность применения той или иной стратегии зависит от приложения.
Нередко в основе устойчивого к катастрофам ЦОД – территориально-распределенная кластерная конфигурация серверов с подключением к общей сети хранения данных (SAN). Узлы разнесенного кластера размещаются на основной и резервной площадках, образуя единую систему. Это обеспечивает непрерывную доступность сервисов даже в случае потери основного ЦОД. С помощью кластеризации можно обеспечить автоматическое переключение нагрузки между площадками распределенного ЦОД в случае аварии. Возможна и экономичная модификация решения, при которой удаленный ЦОД функционирует в резервном режиме и в случае отказа основного ЦОД поддерживает ограниченный набор сервисов.

В зависимости от расстояния и архитектуры решения для коммуникаций между площадками можно использовать Ethernet, протоколы MPLS или IP. Расстояния между ЦОД при синхронной репликации может составлять до 80-100 км – оно ограничивается допустимыми для приложений задержками в сети. При синхронной репликации приложение получает подтверждение завершения операции ввода/вывода после ее выполнения на обеих сторонах. По технологии FCIP через отдельные коммутаторы можно организовать также асинхронное взаимодействие между ЦОД, удаленными друг от друга на тысячи километров, использовать аппаратное сжатие трафика. По сравнению с протоколом Fibre Channel (FC) на расстоянии более 100 км FCIP работает быстрее. При использовании FCIP, пакеты Fibre Channel инкапсулируются в TCP/IP, а затем передаются через IP-туннель. FCIP – основной практически работающий способ связи ЦОД, когда передача FC по темной оптике или через xWDM невозможна или нецелесообразна. Поддерживается как прямое подключение FCIP устройств друг к другу, так и соединение через WAN.
Ключевой элемент катастрофоустойчивого решения – территориально распределенная система хранения данных. Современные СХД предусматривают встроенные средства для построения катастрофоустойчивых решений. Например, системы хранения данных на указанных площадках могут полностью дублировать друг друга, а сами площадки связывают резервированными высокоскоростными каналами связи, что позволяет реализовать проекты с самыми высокими требованиями к надежности передачи данных и их доступности, включая синхронную репликацию данных. Либо резервирование данных может осуществляться в асинхронном режиме.
У некоторых СХД есть возможность «растягивать» тома между площадками при помощи средств самого дискового массива. В результате создается недорогое катастрофоустойчивое решение, не требующее перестройки архитектуры хранения данных. Другой вариант – использование для резервного копирования данных облачной инфраструктуры Microsoft Azure.

Типичный сценарий – резервный ЦОД в другом городе в пределах региона (расстояние — 300-400 км). Для связи по LAN используется IP или MPLS/VPLS, DWDM; для связи по SAN – FCIP, DWDM. В этом случае можно применять ряд «метрокластерных» технологий, использовать асинхронную репликацию. Синхронная репликация на таком расстоянии требует ограничений и дополнительных инструментов. При разнесении площадок на тысячи километров говорят уже о «геокластере».
Способы кластеризации предлагают поставщики операционных систем, сред виртуализации, разработчики приложений, производители ИТ-систем и сетевого оборудования. Например, в основе метрокластера на базе VMware vSphere лежит дублирование систем хранения данных на двух территориально разделенных площадках с возможным балансированием нагрузки на уровне сети ЦОД. При недоступности одного из дата-центров виртуальные машины будут автоматически запущены на второй площадке. При этом скорость восстановления виртуальной среды (RTO) составляет обычно несколько минут.
Не стоит забывать, что реализация стратегии DR требует серьезных инвестиций. Реализация подобного проекта, как правило, связана с большими финансовыми затратами. Обосновать и принять решение о построении такого класса систем весьма сложно. Причем вполне вероятно, что планом резервного восстановления вы никогда не воспользуетесь. Однако в случае чрезвычайной ситуации хороший план восстановления сэкономит время и деньги, поможет свести к минимуму убытки из-за простоя. Серьезная авария может привести к потере дата-центра, а это серьезная проблема для бизнеса. Согласно мировой статистике, 93% компаний, лишившихся своего дата-центра всего на 10 дней, разоряются в течение года.
Нужно найти баланс между затратами на поддержание катастрофоустойчивости и потерями бизнеса в случае катастрофы с учетом времени полного восстановления всех бизнес-процессов. Приведенные ниже иллюстрации помогут получить некоторое представление о затратах на внедрение распределенного ЦОД в компании, точнее оценить объем неизбежных затрат и избежать возможного недопонимания руководителей. В целом зависимость такова: чем меньше требуемое время восстановления, тем дороже обходятся методы защиты данных (по информации Gartner):
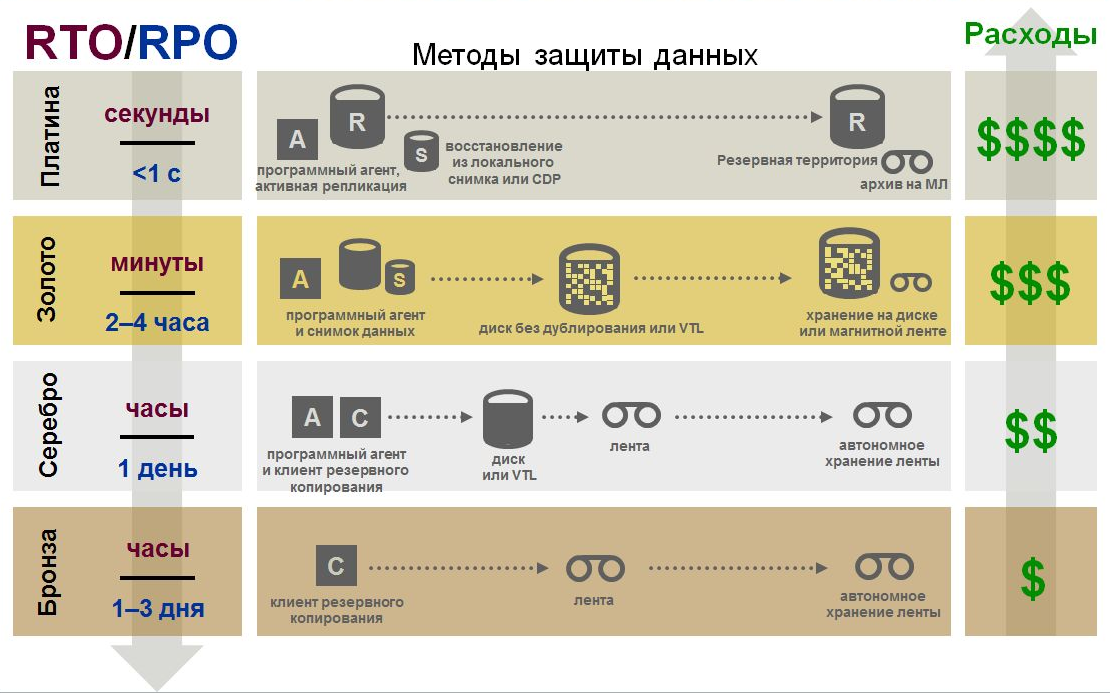
Если же говорить не просто о резервировании и восстановлении систем и данных, а о катастрофоустойчивости, то выбор оптимального по тем или иным параметрам решения – это также всегда компромисс (по данным Compulink).

Нулевые показатели RTO/RPO имеет лишь система высокой доступности. Конечно, это самый дорогостоящий вариант (по данным Cisco).
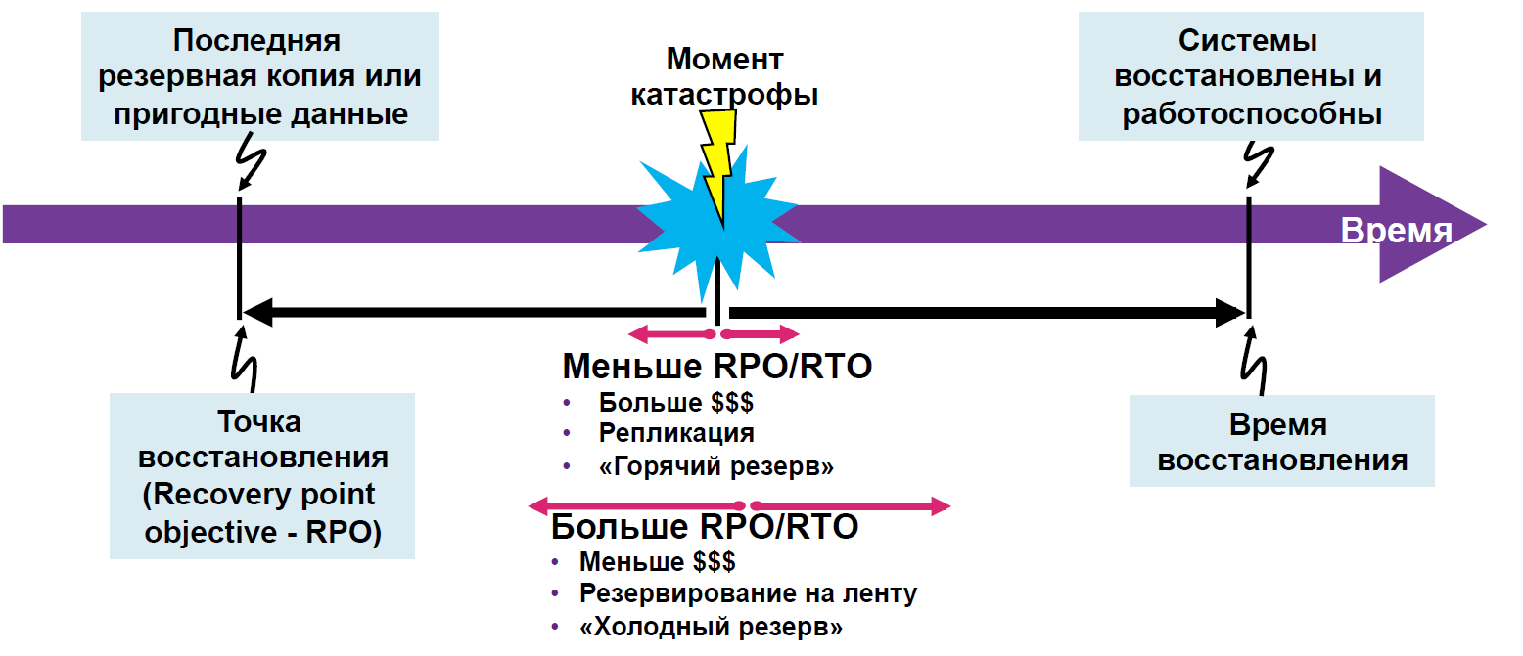
Обеспечение катастрофоустойчивости всегда требовало существенных затрат, временных и финансовых. Нужно иметь две разнесенных площадки, быстрый канал связи между ними, сеть передачи данных, системы хранения данных с поддержкой репликации, вычислительные мощности и инженерное оборудование для бесперебойного электроснабжение и охлаждения ЦОД. Понадобится штат высококвалифицированных ИТ-специалистов, которые могут все это настроить и поддерживать. Требуется уделить внимание проектированию систем их внедрению и тестированию. Однако у этой задачи существуют решения и без крупных капитальных инвестиций.
С распространением виртуализации и облачных технологий появились новые способы защиты от катастроф:

По данным EMC, проводившей в 2014 году опрос российских компаний, лишь 6% респондентов делают ставку на режим работы «активный/активный». Эти компании реже сталкиваются с потерей данных, чем те, что полагаются на резервное копирование: 13% против 24%.
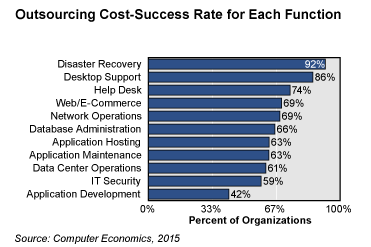
Если возможностей создания инфраструктуры DR у компании нет, разумным решением может стать аутсорсинг. Такие услуги сегодня вполне доступны. Интересно, что по данным недавно опубликованного исследования Computer Economics IT Outsourcing Statistics 2015/2016, аварийное восстановление имеет самый высокий потенциал по экономии затрат клиентов среди наиболее распространенных видов аутсорсинга. Его отметили 92% опрошенных организаций.
 Вместо создания собственной резервной площадки организация может использовать виртуальный (облачный) ЦОД провайдера или вовсе отказаться от собственного дата-центра и перейти на облачную модель. Такой вариант пригоден он для многих организаций. Этот современный подход к обеспечению катастрофоустойчивости получил название «резервный ЦОД как услуга» (Disaster Recovery as a Service, DRaaS). DRaaS исключает влияние аварий на бизнес-процессы, обеспечивает бесперебойную работу, а также снимает с клиента многие вопросы материально-технического и организационного характера.
Вместо создания собственной резервной площадки организация может использовать виртуальный (облачный) ЦОД провайдера или вовсе отказаться от собственного дата-центра и перейти на облачную модель. Такой вариант пригоден он для многих организаций. Этот современный подход к обеспечению катастрофоустойчивости получил название «резервный ЦОД как услуга» (Disaster Recovery as a Service, DRaaS). DRaaS исключает влияние аварий на бизнес-процессы, обеспечивает бесперебойную работу, а также снимает с клиента многие вопросы материально-технического и организационного характера.
Надежность услуг провайдера обеспечивается двумя (или более) географически удаленными дата-центрами, представляющими собой специализированные здания с высоким уровнем надежности. В случае полностью виртуального ЦОД в каждом из них работает экземпляр виртуального дата-центра клиента – основной и резервный. Все изменения в основном экземпляре в реальном времени отражаются в резервном. Выход из строя любого из экземпляров никак не повлияет на работу организации. Когда случается авария, вместо основного дата-центра мгновенно подключается резервный, и все сотрудники и клиенты продолжают работать в обычном режиме. По данным опроса OSP Data, более половины (54%) российских респондентов считают важным наличие у поставщика услуг нескольких территориально удаленных ЦОД для обеспечения катастрофоустойчивости.

Один из примеров описанного выше подхода – BDС (Backup Data Center) или «Пакет услуг резервного ЦОД» компании SAFEDATA. На самом деле он не ограничивается рамками DRaaS. Это целый комплекс услуг проектирования и создания резервной площадки для основного ЦОД заказчика. В качестве основного дата-центра заказчика может выступать как физическая инфраструктура, размещенная на площадке заказчика, так и виртуальная ИТ-инфраструктура.
Компания SAFEDATA имеет собственную распределенную сеть ЦОД на территории Москвы, соединенную собственными волоконно-оптическими линиями связи. Это позволяет предоставлять заказчикам не только услуги по созданию и размещению резервной площадки, но и размещение основного ЦОД, распределенного между двумя удаленными площадками.
Услуги BDC могут включать в себя размещение оборудования и виртуальных вычислительных ресурсов, предоставление волоконно-оптических линий связи и каналов L2, синхронизацию данных между двумя площадками, предоставление интернет-каналов с гарантированной полосой пропускания, защиту от DDoS-атак и резервное копирование.
Выбирая ЦОД SAFEDATA в качестве площадки для создания резервного ЦОД, заказчик получает доступ к экспертизе в области проектирования, построения и обслуживания дата-центров, выделенной круглосуточной службе технической поддержки. Возможна и аренда офисных и складских помещений.
Катастрофоустойчивых решений и услуг сегодня предлагается немало. Пожалуйста, поделитесь в комментариях, что используете вы, как эти решения вас выручали.
Сегодня почти в каждой компании, активно использующей ИТ для поддержки бизнеса, существует свой центр обработки данных (ЦОД). Повышение требований к надежности ЦОД – одна из тенденций рынка. Поскольку дата-центр нередко является ключевым элементом бизнеса компании, специалисты давно ищут экономичные способы повышения его надежности. Причем рано или поздно возникает необходимость обеспечить не только аппаратную надежность ЦОД, но и его катастрофоустойчивость.
По данным исследования EMC, 82% организаций в мире не полностью уверены в том, что смогут восстановить свои системы и данные. Внеплановые простои и потери данных обходятся организациям по всему миру ежегодно более чем в 1,7 млрд. долларов. Согласно исследованию Acronis, в России только 2% опрошенных компаний абсолютно уверены в том, что их ИТ-инфраструктура выдержит любые испытания. 49% российских специалистов ожидают длительных перебоев в её работе в случае стихийного бедствия или аварии.
По данным зарубежной статистики, наиболее частые причины аварий – это отказы оборудования (24%), систем электропитания (16%), ураганы (16%) и наводнения (15%).
В любых технически сложных системах аварии неизбежны, однако их можно сделать не критичными для бизнеса. Для предотвращения таких ситуаций создаются катастрофоустойчивые системы – на территориально удаленной площадке развертываются резервные мощности. Но для начала определимся с терминами, описывающими системы высокой надежности.
Катастрофоустойчивость (Disaster Recovery, DR) – это способность к восстановлению после катастрофы, то есть устойчивость к воздействию природных катаклизмов и террористических актов. Отказоустойчивость (Fault-Tolerance, FT) – свойство системы сохранять работоспособность после отказа одного или нескольких компонентов. О высокой доступности (High Availability, HA) говорят в том случае, когда системы в состоянии выполнять требуемую функцию при заданных условиях в данный момент времени или в течение заданного интервала времени. Непрерывность бизнеса (Business Continuity, ВС) – это процессы, методы и оборудование для безостановочного выполнение критичных бизнес-функций. И, наконец, RTO (Recovery Time Objective) – время, за которое возможно восстановить ИТ-систему, RPO (Recovery Point Objective) – сколько данных будет потеряно при аварийном восстановлении, RCO (Recovery Capacity Objective) – какую часть нагрузки должна обеспечивать резервная система.
Катастрофоустойчивые ЦОД
Для защиты от природных, техногенных катастроф или терактов и обеспечения непрерывности бизнес-процессов необходимо резервирование основных систем хранения и обработки данных. В случае катастрофы может пострадать здание центра обработки данных, поэтому необходимо создание территориально удаленной площадки – резервного дата-центра. Когда уровня надежности Tier III не хватает, географически распределенная катастрофоустойчивая инфраструктура ЦОД способна гарантировать доступность четыре и даже пять девяток.
Распределение ЦОД по нескольким площадкам требует организации резервируемых каналов связи, репликации данных между хранилищами, планирования резервного копирования и восстановления систем. Нужен механизм синхронизации данных для обеспечения их актуальности данных в случае отказа одного из узлов и для поддержки работы тех информационных систем, которым требуется такая синхронизация. Критическим параметром, помимо пропускной способности, является задержка передачи данных.
Возможны две основных стратегии использования распределенных ЦОД – «активный/активный», когда инфраструктурные приложения и сервисы распределены между площадками, и пользователи работают с ближайшим ЦОД, либо «активный/пассивный», при которой приложения централизованы, и пользователи работают с основным узлом. В случае отказа системы, нагрузка автоматически переключается на резервный ЦОД. Возможность применения той или иной стратегии зависит от приложения.
Нередко в основе устойчивого к катастрофам ЦОД – территориально-распределенная кластерная конфигурация серверов с подключением к общей сети хранения данных (SAN). Узлы разнесенного кластера размещаются на основной и резервной площадках, образуя единую систему. Это обеспечивает непрерывную доступность сервисов даже в случае потери основного ЦОД. С помощью кластеризации можно обеспечить автоматическое переключение нагрузки между площадками распределенного ЦОД в случае аварии. Возможна и экономичная модификация решения, при которой удаленный ЦОД функционирует в резервном режиме и в случае отказа основного ЦОД поддерживает ограниченный набор сервисов.
В зависимости от расстояния и архитектуры решения для коммуникаций между площадками можно использовать Ethernet, протоколы MPLS или IP. Расстояния между ЦОД при синхронной репликации может составлять до 80-100 км – оно ограничивается допустимыми для приложений задержками в сети. При синхронной репликации приложение получает подтверждение завершения операции ввода/вывода после ее выполнения на обеих сторонах. По технологии FCIP через отдельные коммутаторы можно организовать также асинхронное взаимодействие между ЦОД, удаленными друг от друга на тысячи километров, использовать аппаратное сжатие трафика. По сравнению с протоколом Fibre Channel (FC) на расстоянии более 100 км FCIP работает быстрее. При использовании FCIP, пакеты Fibre Channel инкапсулируются в TCP/IP, а затем передаются через IP-туннель. FCIP – основной практически работающий способ связи ЦОД, когда передача FC по темной оптике или через xWDM невозможна или нецелесообразна. Поддерживается как прямое подключение FCIP устройств друг к другу, так и соединение через WAN.
Ключевой элемент катастрофоустойчивого решения – территориально распределенная система хранения данных. Современные СХД предусматривают встроенные средства для построения катастрофоустойчивых решений. Например, системы хранения данных на указанных площадках могут полностью дублировать друг друга, а сами площадки связывают резервированными высокоскоростными каналами связи, что позволяет реализовать проекты с самыми высокими требованиями к надежности передачи данных и их доступности, включая синхронную репликацию данных. Либо резервирование данных может осуществляться в асинхронном режиме.
У некоторых СХД есть возможность «растягивать» тома между площадками при помощи средств самого дискового массива. В результате создается недорогое катастрофоустойчивое решение, не требующее перестройки архитектуры хранения данных. Другой вариант – использование для резервного копирования данных облачной инфраструктуры Microsoft Azure.
Типичный сценарий – резервный ЦОД в другом городе в пределах региона (расстояние — 300-400 км). Для связи по LAN используется IP или MPLS/VPLS, DWDM; для связи по SAN – FCIP, DWDM. В этом случае можно применять ряд «метрокластерных» технологий, использовать асинхронную репликацию. Синхронная репликация на таком расстоянии требует ограничений и дополнительных инструментов. При разнесении площадок на тысячи километров говорят уже о «геокластере».
Способы кластеризации предлагают поставщики операционных систем, сред виртуализации, разработчики приложений, производители ИТ-систем и сетевого оборудования. Например, в основе метрокластера на базе VMware vSphere лежит дублирование систем хранения данных на двух территориально разделенных площадках с возможным балансированием нагрузки на уровне сети ЦОД. При недоступности одного из дата-центров виртуальные машины будут автоматически запущены на второй площадке. При этом скорость восстановления виртуальной среды (RTO) составляет обычно несколько минут.
Экономика катастрофоустойчивости
Не стоит забывать, что реализация стратегии DR требует серьезных инвестиций. Реализация подобного проекта, как правило, связана с большими финансовыми затратами. Обосновать и принять решение о построении такого класса систем весьма сложно. Причем вполне вероятно, что планом резервного восстановления вы никогда не воспользуетесь. Однако в случае чрезвычайной ситуации хороший план восстановления сэкономит время и деньги, поможет свести к минимуму убытки из-за простоя. Серьезная авария может привести к потере дата-центра, а это серьезная проблема для бизнеса. Согласно мировой статистике, 93% компаний, лишившихся своего дата-центра всего на 10 дней, разоряются в течение года.
Нужно найти баланс между затратами на поддержание катастрофоустойчивости и потерями бизнеса в случае катастрофы с учетом времени полного восстановления всех бизнес-процессов. Приведенные ниже иллюстрации помогут получить некоторое представление о затратах на внедрение распределенного ЦОД в компании, точнее оценить объем неизбежных затрат и избежать возможного недопонимания руководителей. В целом зависимость такова: чем меньше требуемое время восстановления, тем дороже обходятся методы защиты данных (по информации Gartner):
Если же говорить не просто о резервировании и восстановлении систем и данных, а о катастрофоустойчивости, то выбор оптимального по тем или иным параметрам решения – это также всегда компромисс (по данным Compulink).
Нулевые показатели RTO/RPO имеет лишь система высокой доступности. Конечно, это самый дорогостоящий вариант (по данным Cisco).
Обеспечение катастрофоустойчивости всегда требовало существенных затрат, временных и финансовых. Нужно иметь две разнесенных площадки, быстрый канал связи между ними, сеть передачи данных, системы хранения данных с поддержкой репликации, вычислительные мощности и инженерное оборудование для бесперебойного электроснабжение и охлаждения ЦОД. Понадобится штат высококвалифицированных ИТ-специалистов, которые могут все это настроить и поддерживать. Требуется уделить внимание проектированию систем их внедрению и тестированию. Однако у этой задачи существуют решения и без крупных капитальных инвестиций.
Виртуализация, облака и катастрофоустойчивость
С распространением виртуализации и облачных технологий появились новые способы защиты от катастроф:
- Репликация в облако. Технологии частных и публичных облаков упростили репликацию между площадками. Процесс репликации может охватывать все виртуальные машины, конкретные базы данных или снимки данных. Кроме того, облачные технологии помогают организациям выбрать наиболее подходящий по финансовым условиям вариант DR – появилась гибкость выбора допустимого времени простоя. То есть нередко можно выбрать приемлемое время простоя и при этом вписаться в бюджет.
- Виртуализация как механизм резервного копирования/восстановления. Здесь идея проста: намного проще восстановить виртуальную машину, чем физический сервер. Можно сохранять в резервном ЦОД «снимки состояния» ВМ или зеркалировать виртуальные машины. В последнем случая получается конфигурация «активный/активный» – при отказе на основной площадке ВМ, выполняющей критичные задачи, происходит переключение на такую же ВМ на резервной площадке.
- Использование технологий программного конфигурирования (Software Defined, SD). По сути, это развитие виртуализации. Программно-конфигурируемые платформы (сетевое оборудование, системы хранения, устройство безопасности, балансировщики нагрузки и пр.) позволяют получить гибкую отказоустойчивую среду с «виртуальными устройствами» различного назначения, функционирующими как виртуальные машины на стандартных серверах. Например, если задействовать для DR механизмы балансирования нагрузки (Global Server Load Balancing, GSLB), можно автоматически переключать пользователей на резервную площадку при отказе основной. Для пользователей процесс будет прозрачным.
- IaaS (инфраструктура по требованию). Облачные платформы и среды виртуализации позволяют быстро выделять необходимые ИТ-ресурсы. Для DR важна возможность быстрого восстановления виртуальных машин и данных. Облачные технологии и виртуализация отлично подходят для этой цели. Можно создавать очень экономичные решения IaaS – «активный/активный» или «активный/пассивный». Например, задается регулярное резервное копирование ВМ и данных в ЦОД провайдера. В случае аварии развертывается новая среда – запускаются ВМ с их резервированными данными. Процесс это не мгновенный, но достаточно быстрый. В IaaS главное – гибкость. При реализации стратегии DR провайдер поможет заказчику извлечь из этой гибкости максимум.
По данным EMC, проводившей в 2014 году опрос российских компаний, лишь 6% респондентов делают ставку на режим работы «активный/активный». Эти компании реже сталкиваются с потерей данных, чем те, что полагаются на резервное копирование: 13% против 24%.
Если возможностей создания инфраструктуры DR у компании нет, разумным решением может стать аутсорсинг. Такие услуги сегодня вполне доступны. Интересно, что по данным недавно опубликованного исследования Computer Economics IT Outsourcing Statistics 2015/2016, аварийное восстановление имеет самый высокий потенциал по экономии затрат клиентов среди наиболее распространенных видов аутсорсинга. Его отметили 92% опрошенных организаций.
Резервный ЦОД как услуга
Вместо создания собственной резервной площадки организация может использовать виртуальный (облачный) ЦОД провайдера или вовсе отказаться от собственного дата-центра и перейти на облачную модель. Такой вариант пригоден он для многих организаций. Этот современный подход к обеспечению катастрофоустойчивости получил название «резервный ЦОД как услуга» (Disaster Recovery as a Service, DRaaS). DRaaS исключает влияние аварий на бизнес-процессы, обеспечивает бесперебойную работу, а также снимает с клиента многие вопросы материально-технического и организационного характера.Надежность услуг провайдера обеспечивается двумя (или более) географически удаленными дата-центрами, представляющими собой специализированные здания с высоким уровнем надежности. В случае полностью виртуального ЦОД в каждом из них работает экземпляр виртуального дата-центра клиента – основной и резервный. Все изменения в основном экземпляре в реальном времени отражаются в резервном. Выход из строя любого из экземпляров никак не повлияет на работу организации. Когда случается авария, вместо основного дата-центра мгновенно подключается резервный, и все сотрудники и клиенты продолжают работать в обычном режиме. По данным опроса OSP Data, более половины (54%) российских респондентов считают важным наличие у поставщика услуг нескольких территориально удаленных ЦОД для обеспечения катастрофоустойчивости.
Один из примеров описанного выше подхода – BDС (Backup Data Center) или «Пакет услуг резервного ЦОД» компании SAFEDATA. На самом деле он не ограничивается рамками DRaaS. Это целый комплекс услуг проектирования и создания резервной площадки для основного ЦОД заказчика. В качестве основного дата-центра заказчика может выступать как физическая инфраструктура, размещенная на площадке заказчика, так и виртуальная ИТ-инфраструктура.
Компания SAFEDATA имеет собственную распределенную сеть ЦОД на территории Москвы, соединенную собственными волоконно-оптическими линиями связи. Это позволяет предоставлять заказчикам не только услуги по созданию и размещению резервной площадки, но и размещение основного ЦОД, распределенного между двумя удаленными площадками.
Услуги BDC могут включать в себя размещение оборудования и виртуальных вычислительных ресурсов, предоставление волоконно-оптических линий связи и каналов L2, синхронизацию данных между двумя площадками, предоставление интернет-каналов с гарантированной полосой пропускания, защиту от DDoS-атак и резервное копирование.
Выбирая ЦОД SAFEDATA в качестве площадки для создания резервного ЦОД, заказчик получает доступ к экспертизе в области проектирования, построения и обслуживания дата-центров, выделенной круглосуточной службе технической поддержки. Возможна и аренда офисных и складских помещений.
Катастрофоустойчивых решений и услуг сегодня предлагается немало. Пожалуйста, поделитесь в комментариях, что используете вы, как эти решения вас выручали.
Комментарии (3)

Han_Solo
29.12.2015 10:53Вы может и не слышали, а такое исследование есть: www.e-janco.com/Articles/2012/20121202-10-Charateristics-of-a-good-plan.html
И здесь не говорится именно об атаке на дата-центры…
gydex
30.12.2015 19:02В современных условиях к причинам катастроф стоит добавить «маски-шоу» и судебное преследование.
Сами же — используем бэкап и резервное облако.
caveeagle
Хотелось бы узнать про «5% — Bomb». А то как-то не слышал про террористов, уничтожающих датацентры, да ещё и в таких количествах (1/20 всех повреждений).