- изменение котировок
- действия пользователей в онлайн-игре
- отображала агрегированную информацию из соцсетей в различных проекциях
и т.д. Если вы так не умеете, то смузи уже не нальют.

Все чаще мы слышим про лямбда-архитектуру. Все чаще хотят кластеризацию данных в онлайн. Все больше слышим об использовании онлайн машинного обучения (дообучения). Караул.

Можно начать рвать на голове волосы, а можно и скорее нужно методично тренироваться, развивать понимание технологий и алгоритмов и на практике, в условиях «жесткого боя» и высоких нагрузок, — отделять полезные и эффективные технологические решения от академического теоретизирования.
Сегодня расскажу, как мы сделали интерактивную карту наших клиентов с помощью Apache Spark Streaming и API Яндекс.Карт. Но прежде, повторим архитектурные подходы и бегло по сути пройдем по доступным инструментам.
Подходы к обработке массивов данных
Этой проблематике уже более 50 лет. Суть в том, что существует грубо 2 принципиальных подхода к задаче обработки больших массивов информации — Data Parallelizm и Task Parallelizm.
В первом случае, одинаковая цепочка вычислений запускается параллельно над непересекающимися неизменными частями исходных данных. Именно по этому принципу работают Apache Spark и Hadoop MapReduce.
Во втором случае, все наоборот — над одним фрагментом данных начинает параллельно выполняться несколько цепочек вычислений: по этому принципу работают популярные Apache Spark Streaming, Apache Storm и, с некоторой натяжкой, Apache Flume.
Эти концепции очень важно понять и усвоить, ибо систем для пакетной и потоковой обработки данных, по причине их относительной простоты, наплодили уже кучу, как грибов после дождя, что, конечно, сбивает с толку начинающих.

По сути, что Apache Spark Streaming (спасибо UC Berkeley и DataBricks), что Apache Storm (спасибо, Twitter) — реализуют концепцию потоковой обработки данных в архитектуре Task Parallel, однако Spark Streaming пошел дальше и позволяет обработать пакет (дискретизированный RDD) также параллельно в духе Data Parallel. Такая особенность позволяет легко «прикрутить» онлайн кластеризацию пакета — сгруппируем данные в кластера для визуализации, пригласим девушек на ужин… так, о чем это я.
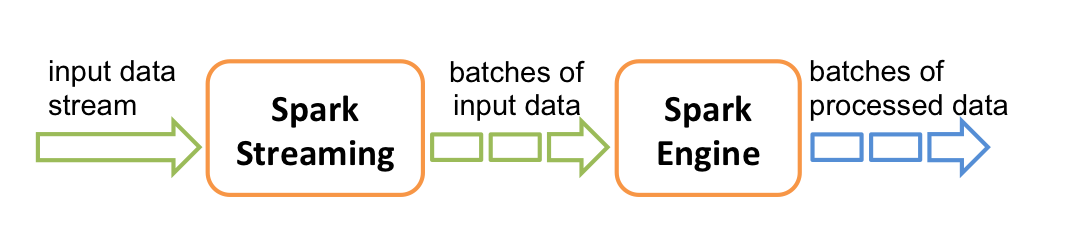
Как работает Apache Spark Streaming
Документацию прочитать вы и сами можете, я лишь объясню 2-3 словами саму суть. Ненавижу популизм, умничание и жонглирование непонятными терминами — хочется, чтобы знания передавались на простом, доступном языке и процесс передачи приносил удовольствие. Вы собираете данные, поступающие много раз в секунду в:
и куда душа пожелает. Данные, для простоты, упорядочены. Вам нужно обработать каждый элемент данных:
- добавить хит к сумме хитов за сутки
- зарегистрировать координату клиента по IP-адресу
- отправить push-уведомление пользователю о совершении операции
Spark Streaming собирает элементы данных в упорядоченный неизменяемый RDD за определенный фиксированный интервал времени (допустим, за 10 секунд) и вызывает ваш обработчик, передавая RDD на вход. RDD — это просто коллекция собранных за интервал данных, не больше.
Если за интервал удалось собрать довольно большой RDD, вам нужно его постараться обработать ДО того, как придет следующий RDD за следующий интервал. Поэтому RDD практично обрабатывать параллельно на нескольких серверах кластера. Чем больше поток данных на входе, тем больше серверов добавляется в потоковый кластер. Надеюсь, понятно все объяснил.
А если все упало? Отвалился кусок кластера, случился null pointer exception в вашем обработчике пакета…

«Кошерные» и «православные» архитектуры очередей сообщений
Небольшая аркадная вставка. Не так давно, при упоминании RabbitMQ или ZeroMQ воцарялась тишина и благоговейный трепет снисходил на группу разработчиков, архитекторов и случайно заблудившегося верстальщика. А бывалые бойцы с опытом выживания в enterprise — вспоминали Message-oriented middleware и пускали слезу.
Но, как мы сказали в начале поста, Бигдата напирает. Причем делает это грубо и бесцеремонно. Все чаще мы слышим, что архитектура очередей сообщений, в которой Consumers координируются и мультиплексируются централизованно на сервере(ах) очередей, становится «некошерной», т.к. при возрастании нагрузки и числа клиентов ей становится плохо (еще бы, нужно держать все контексты со счетчиками всех клиентов, пробегать по готовым к обработке сокетам путем select/pool и заниматься прочим садомазахизмом). И «православной» архитектурой все больше считается реализованная в Apache Kafka, где свою позицию в очереди помнит и сохраняет каждый клиент-consumer, а сервер(ы) занимается лишь выдачей сообщений, по переданному клиентом итератору (а точнее — переданному смещению в файле, в котором сообщения и хранятся на старом, добром, бородатом жестком диске). Конечно это халтура и переваливание ответственности на клиентов — но… Бигдата — напирает и оказалось, что архитектурка не такая уж и безответственная. И даже Amazon Kinesis взял ее на вооружение. Почитайте про нее — полезно. Только там текста много, наливайте чашку с кофе побольше и с арабикой.

Восстановление после аварии
На чем мы там остановились? Все упало… у кого, какие девушки? А, вспомнил. Так вот, когда все упало, consumer, в данном случае его роль выполняет драйвер (их несколько из коробки), который тянет сообщения из очередей, должен снова передать сохраненную позицию в очереди и начать читать сообщения заново. В нашем случае мы читаем сообщения в Spark Streaming из Amazon Kinesis и драйвер регулярно (настраивается), сохраняет прочитанную из очереди позицию в табличку DymanoDB (это доступно из коробки).
Как устроен наш проект — «Интерактивная карта клиентов»
Источники событий
Во время работы клиентов с порталами «Битрикс24» javascript отправляет в облако пакет, описывающий действие клиента, IP-адрес и обезличенную информацию, которая используется в системе персональных рекомендаций, CRM, бизнес-аналитике и различных моделях машинного обучения внутри компании.
Приходит в пике ежесекундно больше 1000 событий. События собираются в Amazon Kinesis (который, как помним, с «кошерной архитектурой»).
Передача событий в Spark Streaming
Для обработки этих >1000 событий в секунду поднят небольшой кластер Yarn с Spark Streaming (2 машины). Обратите внимание на объем памяти, выделенный Spark driver. Похоже, можно выделить памяти еще меньше:
Еще интереснее следующий скриншот. На нем видно, что мы успеваем обрабатывать >1000 хитов в секунду до того, как придет следующий пакет за 30 секундный интервал:

Да, точно, память драйвер Spark расходует меньше 200МБ, поэтому прямо сейчас мы ему ее подрежем :-):

В общем видно, что памяти используется довольно мало и вся обработка потока легко помещается на 2 железки, а при желании можно и на одной это делать и никто не заметит. Круто. Эффективная технология: >1000 событий в секунду на «дохлом» железе.
Обработка событий
Теперь самое интересное. Нам нужно получить у каждого хита клиента его IP-адрес и… отобразить его домен точкой на Яндекс.Карте, но так, чтобы зум по карте работал и ничего не тормозило!
Для трансляции IP-адресов в координаты мы используем одну из популярных библиотек. Одна проблемка — из коробки объекты библиотечки на java не сериализуются, поэтому трансляция IP-адресов в координаты пока выполняется в один поток внутри драйвера Spark. При желании, конечно, можно поднять отдельный ресолвер адресов на каждой partition RDD интервала — но пока производительности хватает за глаза.
Далее у каждого хита определяем домен проекта и сохраняем в хэш-таблицу пару: домен — координаты и время обновления. Пары старше нескольких дней — убираем.
Выгрузка данных для Яндекс.Карты
Через определенные интервалы времени (настраивается), мы выгружаем привязку доменов к координатам, т.е. будущие точки на карте, в json-файл для дальнейшего отображения на Яндекс.Карте. На данный момент точек около 20к.

Растеризатор-кластеризатор для Яндекс.Карт
Пришлось вспомнить javascript :-). Подводный камень при отображении точек на Яндекс.Карту оказался один — 20к точек на карте с встроенной кластеризацией ужасно тормозят браузер клиента и карта открывается минуты. Поэтому мы воспользовались возможностью серверной кластеризации — написали свой простенький растеризатор-кластеризатор, к которому и подключили карту.
Про то, как реализована сама карта, как мы делаем серверную растеризацию и подводные камни, — я напишу отдельный пост, если интересно, скажите. Общая архитектура получилась такая:
- Карта обращается к серверному растеризатору, передавая координаты отображаемой области
- Растеризатор считывает json-файл с парами: домен-координата, кластеризует точки на лету и отдает результат
- Карта отображает результаты серверной растеризации-кластеризации
Получилось быстро и просто. Да, можно не считывать json-файл, а обращаться к NoSQL… но пока и так все работает быстро и есть такое слово — лень :-)
Растеризатор написан на PHP, и на лету выполнять k-means конечно самоубийство — поэтому все упрощено и вместо кластеризации делается растеризация. Если интересно, опишу отдельным постом.
Итоги
Вот как выглядит карта активных доменов клиентов Битрикс24 (https://www.bitrix24.ru/online-domains-map):

Вот зум:

Получилась симпатичная онлайн-карта доменов Битрикс24. Зум и серверная кластеризация работают довольно шустро. Порадовал Spark Streaming и довольно приятный процесс создания карты через API Яндекс.Карт. Пишите, что может быть еще интересно на эту тему, — мы постараемся подробно рассказать. Всем удачи!
Комментарии (18)

Eternalko
25.12.2015 18:43Работали с Druid'ом? Или просто картинка?

AlexSerbul
25.12.2015 18:44+1Пока просто картинка. Работа с аналогом — Amazon Redshift.
xhumanoid
25.12.2015 20:39+1Druid к Redshift это как теплое к мягкому
второй это честный sql
первый заточенность на агрегациях поверх псевдо-olap, да еще и без join'ов (хотя свое дело и делает хорошо в этой части если данные денормализованы)AlexSerbul
25.12.2015 21:56Ну column-ориентированные же? Для анализа и агрегации задуманы :-)
AlexSerbul
25.12.2015 21:57И нечестный SQL в Redshift — очень урезанный, без joins, без внешних ключей, так, игрушечный
AlexSerbul
25.12.2015 22:25Ой, простите, Вы конечно правы — joins в Redshift есть конечно. Нет уникальных ключей и т.п. docs.aws.amazon.com/redshift/latest/dg/c_unsupported-postgresql-features.html
Я помню когда его смотрел, осталось впечатление урезанного SQL до небалуй :-)xhumanoid
26.12.2015 00:42а в druid просто нету sql, от слова СОВСЕМ
хотя сейчас imply что-то и пытается делать транслятор, но работы еще вагон
я бы понял, если бы сравнили druid c Pinot, но с редшифтом это уж слишком.
>> Ну column-ориентированные же?
по хорошему, сегмент в друиде это bitmap индекс, что и объясняет, почему select у них появился совсем не сразу, да и сейчас используется только для отладки, так как тормозной до ужаса.
column-ориентированные зачастую преподносят почему вам не нужны индексы, тут же только индексы и есть.
>> Нет уникальных ключей и т.п
в друид вообще нету понятий ключей, есть dimention и событие в append-only виде, ни обновлений ни изменений нету
Eternalko
26.12.2015 01:52Как быстро он индексирует входящие данные? По вашему опыту/мнени, сколько INSERT'ов в секунду одна приличная нода выдержит? 50к? 100к?
xhumanoid
26.12.2015 15:05вот тут не могу сказать сразу, так как у нас пока и нагрузка не 50к и стоит реалтайм за кафкой, что еще больше сглаживает пики
Eternalko
26.12.2015 21:25Ну это понятно что будет стоять lb/mq (:
Все хотел его погонять. Обещают аналитику, следовательно много записей и агрегация.
Только руки не доходят. И Docker'a официального у них нет.
Не подойти просто )xhumanoid
26.12.2015 21:48докер есть, отдельно есть уже более гранулированные (брокер, ноды)
в свое время вообще делал просто «скачал, распаковал, запустил дефолт», а уже дальше думаешь что тебе нужно
для начала хватит и одной машинки-инстанса, на котором все 3 типа запустить, примеры у них тоже неплохие
для визуализации (пока еще достаточно сырое, но уже от реста избавляет в простейших случаях) Imply. да и quickstart там описывает как запустить в одну команду, к тому же у него есть и свежий docker
плохо искали ;)Eternalko
26.12.2015 22:32Действительно. Я по привычке на докер хабе глянул, не увидел официального / с большим количеством скачиваний и оставил «на потом».
Спасибо за наводку. Теперь у меня нет отмазок чтобы не попробовать (:
Попробую его помучать приличной нагрузкой (:

lonelylockley
26.12.2015 14:561к сообщений в секунду как-то несерьезно. Сколько экзекуторов/железа потребуется, чтобы обрабатывать хотя бы 1-10кк сообщений в секунду?
AlexSerbul
27.12.2015 21:15ну это реальная боевая нагрузка, честная
lonelylockley
30.12.2015 20:46Я ни в коем случае не ставлю это под сомнение. Просто на моем проекте планируется нагрузка в тысячу раз выше и я надеялся, что может вы уже делали сайзинг.
kirichenko
биг-дата такая биг-дата
Что интересно, во времена MapReduce статей дальше wordcount днём с огнём не сыщешь, появился спарк и по 2-3 статьи в неделю только на хабре. Вот она, сила маркетинга!
AlexSerbul
да уж, данных становится все больше, скорости растут и смузи уже за простой Hadoop MapReduce не наливают :-)
kirichenko
Те, кто знают MapReduce, за еду не работают…