Всем привет!
Я думаю, что многие слышали о Google DeepMind. О том как они обучают программы играть в игры Atari лучше человека. Сегодня я хочу представить вам статью о том, как сделать нечто подобное. Данная статья — это обзор идеи и кода примера применения Q-learning, являющегося частным случаем обучения с подкреплением. Пример основан на статье сотрудников Google DeepMind.
Игра
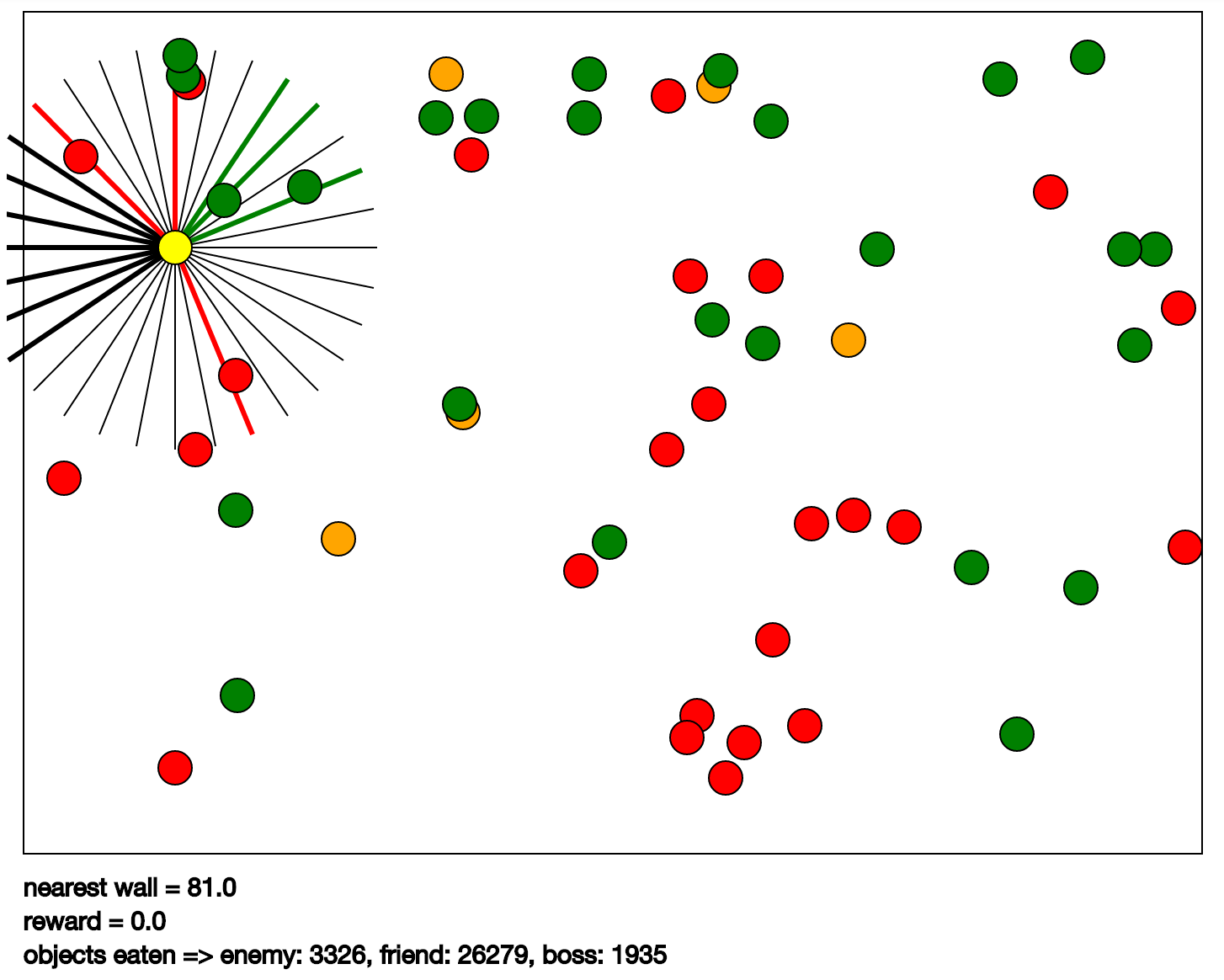
В примере рассматривается игра Karpathy game. Она изображена на КПДВ. Суть ее заключается в следующем: необходимо управлять желтым шариком таким образом, чтобы «есть» зеленые шарики и не есть красные и оранжевые. За оранжевые дается больший штраф, чем за красные. У желтого шарика имеются радиально расходящиеся отрезки ответственные за зрение (в программе они называются eye). С помощью такого отрезка программа чувствует тип ближайшего объекта в направлении отрезка, его скорость и удаление. Типом объекта может быть цвет шарика или стена. Набор входных данных получается следующим: данные с каждого глаза и собственная скорость. Выходные данные — это команды управления желтым шариком. По сути — это ускорения по четырем направлениям: вверх, влево, вниз, вправо.
Идея
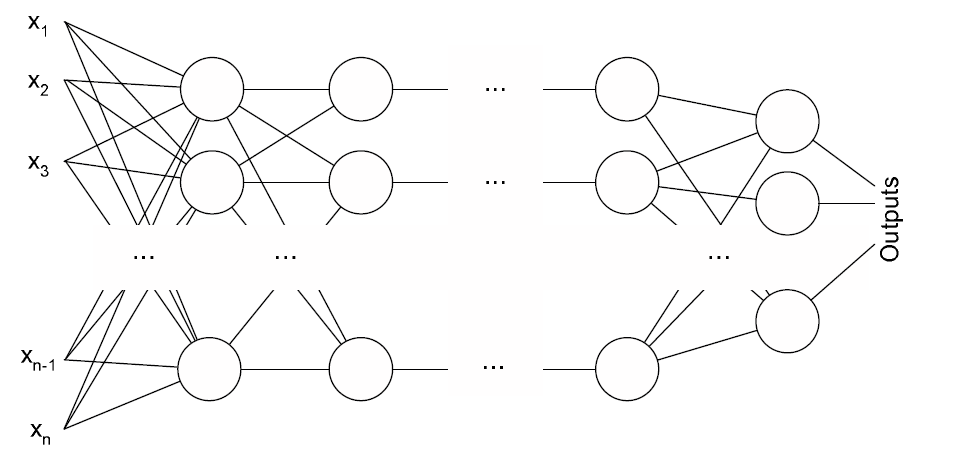
В эту игру играет многослойный перцептрон. На входе у него описанные выше входные данные. На выходе полезность каждого из возможных действий. Перцептрон обучается методом обратного распространения ошибки. А конкретно используется метод RMSProp. Особенность его в том, что он использует для оптимизации сразу пачку примеров, но это не единственная его особенность. Чтобы узнать больше о методе можете посмотреть эти слайды. Они рассказывают не только о RMSProp. Ничего лучше я пока не нашел. Ошибка выхода нейронной сети вычисляется с помощью того самого Q-learning.
TensorFlow
Почти все это можно более менее легко закодить не углубляясь в написание собственных реализаций алгоритмов, благодаря недавно увидевшей свет библиотеке TensorFlow. Программирование с использованием этой библиотеки сводится к описанию графа вычислений, требуемых для получения результата. Затем этот граф отправляется в сессию TensorFlow, где и производятся сами вычисления. RMSProp взят целиком из TensorFlow. Нейронная сеть реализована на матрицах оттуда же. Q-learning реализован также на обычных операциях TensorFlow.
Код
Теперь давайте посмотрим в наиболее интересные места кода примера.
models.py - многослойный перцептрон
import math
import tensorflow as tf
from .utils import base_name
# Для начала посмотрите ниже класс MLP
# Один слой перцептрона
class Layer(object):
# input_sizes - массив количеств входов, почему массив см конструктор MLP ниже
# output_size - количество выходов
# scope - строчка, переменные в TensorFlow можно организовывать в скоупы
# для удобного переиспользования (см https://www.tensorflow.org/versions/master/how_tos/variable_scope/index.html)
def __init__(self, input_sizes, output_size, scope):
"""Cretes a neural network layer."""
if type(input_sizes) != list:
input_sizes = [input_sizes]
self.input_sizes = input_sizes
self.output_size = output_size
self.scope = scope or "Layer"
# входим в скоуп
with tf.variable_scope(self.scope):
# массив нейронов
self.Ws = []
for input_idx, input_size in enumerate(input_sizes):
# идентификатор нейрона
W_name = "W_%d" % (input_idx,)
# инициализатор весов нейрона - равномерное распределение
W_initializer = tf.random_uniform_initializer(
-1.0 / math.sqrt(input_size), 1.0 / math.sqrt(input_size))
# создание нейрона - как матрицы input_size x output_size
W_var = tf.get_variable(W_name, (input_size, output_size), initializer=W_initializer)
self.Ws.append(W_var)
# создание вектора свободных членов слоя
# этот вектор будет прибавлен к выходам нейронов слоя
self.b = tf.get_variable("b", (output_size,), initializer=tf.constant_initializer(0))
# использование слоя нейронов
# xs - вектор входных значений
# возвращает вектор выходных значений
def __call__(self, xs):
if type(xs) != list:
xs = [xs]
assert len(xs) == len(self.Ws), "Expected %d input vectors, got %d" % (len(self.Ws), len(xs))
with tf.variable_scope(self.scope):
# рассчет выходных значений
# так как каждый нейрон - матрица
# то вектор выходных значений - это сумма
# умножений матриц-нейронов на входной вектор + вектор свободных членов
return sum([tf.matmul(x, W) for x, W in zip(xs, self.Ws)]) + self.b
# возвращает список параметров слоя
# это нужно для работы алгоритма обратного распространения ошибки
def variables(self):
return [self.b] + self.Ws
def copy(self, scope=None):
scope = scope or self.scope + "_copy"
with tf.variable_scope(scope) as sc:
for v in self.variables():
tf.get_variable(base_name(v), v.get_shape(),
initializer=lambda x,dtype=tf.float32: v.initialized_value())
sc.reuse_variables()
return Layer(self.input_sizes, self.output_size, scope=sc)
# Многослойный перцептрон
class MLP(object):
# input_sizes - массив размеров входных слоев, не знаю зачем,
# но здесь реализована поддержка нескольких входных слоев,
# выглядит это как один входной слой разделенный на части,
# по факту эта возможность не используется, то есть входной слой один
# hiddens - массив размеров скрытых слоев, по факту
# используется 2 скрытых слоя по 100 нейронов
# и выходной слой - 4 нейрона, что интересно, не делать ничего
# нейросеть не может, такого варианта у нее нет
# nonlinearities - массив передаточных функций нейронов слоев, про передаточные функции см <a href="https://ru.wikipedia.org/wiki/%D0%98%D1%81%D0%BA%D1%83%D1%81%D1%81%D1%82%D0%B2%D0%B5%D0%BD%D0%BD%D1%8B%D0%B9_%D0%BD%D0%B5%D0%B9%D1%80%D0%BE%D0%BD">Искусственный нейрон</a>
# scope - строчка, переменные в TensorFlow можно организовывать в скоупы
# для удобного переиспользования
# given_layers - можно передать уже созданные слои
def __init__(self, input_sizes, hiddens, nonlinearities, scope=None, given_layers=None):
self.input_sizes = input_sizes
self.hiddens = hiddens
self.input_nonlinearity, self.layer_nonlinearities = nonlinearities[0], nonlinearities[1:]
self.scope = scope or "MLP"
assert len(hiddens) == len(nonlinearities), "Number of hiddens must be equal to number of nonlinearities"
with tf.variable_scope(self.scope):
if given_layers is not None:
# использовать переданные слои
self.input_layer = given_layers[0]
self.layers = given_layers[1:]
else:
# создать слои
# создание входного слоя
self.input_layer = Layer(input_sizes, hiddens[0], scope="input_layer")
self.layers = []
# создать скрытые слои
for l_idx, (h_from, h_to) in enumerate(zip(hiddens[:-1], hiddens[1:])):
self.layers.append(Layer(h_from, h_to, scope="hidden_layer_%d" % (l_idx,)))
# использование нейросети
# xs - вектор входных значений
# возвращается выход выходного слоя
def __call__(self, xs):
if type(xs) != list:
xs = [xs]
with tf.variable_scope(self.scope):
# применение входного слоя к вектору входных значений
hidden = self.input_nonlinearity(self.input_layer(xs))
for layer, nonlinearity in zip(self.layers, self.layer_nonlinearities):
# применение скрытых слоев в выходам предидущих слоев
hidden = nonlinearity(layer(hidden))
return hidden
# список параметров всей нейронной сети от входного слоя к выходному
def variables(self):
res = self.input_layer.variables()
for layer in self.layers:
res.extend(layer.variables())
return res
def copy(self, scope=None):
scope = scope or self.scope + "_copy"
nonlinearities = [self.input_nonlinearity] + self.layer_nonlinearities
given_layers = [self.input_layer.copy()] + [layer.copy() for layer in self.layers]
return MLP(self.input_sizes, self.hiddens, nonlinearities, scope=scope,
given_layers=given_layers)
discrete_deepq.py - реализация Q-learning
import numpy as np
import random
import tensorflow as tf
from collections import deque
class DiscreteDeepQ(object):
# Описание параметров ниже
def __init__(self, observation_size,
num_actions,
observation_to_actions,
optimizer,
session,
random_action_probability=0.05,
exploration_period=1000,
store_every_nth=5,
train_every_nth=5,
minibatch_size=32,
discount_rate=0.95,
max_experience=30000,
target_network_update_rate=0.01,
summary_writer=None):
# Этот большой комментарий я просто переведу ниже
"""Initialized the Deepq object.
Based on:
https://www.cs.toronto.edu/~vmnih/docs/dqn.pdf
Parameters
-------
observation_size : int
length of the vector passed as observation
num_actions : int
number of actions that the model can execute
observation_to_actions: dali model
model that implements activate function
that can take in observation vector or a batch
and returns scores (of unbounded values) for each
action for each observation.
input shape: [batch_size, observation_size]
output shape: [batch_size, num_actions]
optimizer: tf.solver.*
optimizer for prediction error
session: tf.Session
session on which to execute the computation
random_action_probability: float (0 to 1)
exploration_period: int
probability of choosing a random
action (epsilon form paper) annealed linearly
from 1 to random_action_probability over
exploration_period
store_every_nth: int
to further decorrelate samples do not all
transitions, but rather every nth transition.
For example if store_every_nth is 5, then
only 20% of all the transitions is stored.
train_every_nth: int
normally training_step is invoked every
time action is executed. Depending on the
setup that might be too often. When this
variable is set set to n, then only every
n-th time training_step is called will
the training procedure actually be executed.
minibatch_size: int
number of state,action,reward,newstate
tuples considered during experience reply
dicount_rate: float (0 to 1)
how much we care about future rewards.
max_experience: int
maximum size of the reply buffer
target_network_update_rate: float
how much to update target network after each
iteration. Let's call target_network_update_rate
alpha, target network T, and network N. Every
time N gets updated we execute:
T = (1-alpha)*T + alpha*N
summary_writer: tf.train.SummaryWriter
writer to log metrics
"""
"""Инициализация Deepq
Основано на:
https://www.cs.toronto.edu/~vmnih/docs/dqn.pdf
Параметры
-------
observation_size : int
длина вектора входных данных (этот вектор
будем называть наблюдением или состоянием)
num_actions : int
количество возможных действий или же
длина вектора выходных данных нейросети
observation_to_actions: dali model
модель (в нашем случае нейросеть),
которая принимает наблюдение или набор наблюдений
и возвращает оценку очками каждого действия или
набор оценок для каждого действия каждого из наблюдений
входной размер: матрица [batch_size, observation_size]
выходной размер: матрица [batch_size, num_actions]
optimizer: tf.solver.*
алгоритм рассчета обратого распространения ошибки
в нашем случае будет использоваться RMSProp
session: tf.Session
сессия TensorFlow в которой будут производится вычисления
random_action_probability: float (0 to 1)
вероятность случайного действия,
для обогощения опыта нейросети и улучшения качесва управления
с определенной вероятностью выполняется случайное действие, а не
действие выданное нейросетью
exploration_period: int
период поискового поведения в итерациях,
в течении которого вероятность выполнения случайного
действия падает от 1 до random_action_probability
store_every_nth: int
параметр нужен чтобы сохранять не все обучающие примеры
а только определенную часть из них.
Сохранение происходит один раз в указаное в параметре
количество обучающих примеров
train_every_nth: int
обычно training_step (шаг обучения)
запускается после каждого действия.
Иногда получается так, что это слишком часто.
Эта переменная указывает сколько шагов
пропустить перед тем как запускать шаг обучения
minibatch_size: int
размер набора обучающих примеров который
используется на одном шаге обучения
алгоритмом RMSProp.
Обучающий пример включает в себя
состояние, предпринятое действие, награду и
новое состояние
dicount_rate: float (0 to 1)
параметр Q-learning
насколько сильно влияет будущая награда при
расчете пользы действия
max_experience: int
максимальное количество сохраненных
обучающих примеров
target_network_update_rate: float
параметр скорости обучения нейросети,
здесь используется 2 нейросети
T - target_q_network
она используется для расчета вклада будущей пользы и
N - q_network
она испольщуется для выбора действия,
также эта сеть подвергается обучению
методом обратного распространения ошибки.
Сеть T с определенной скоростью стремится к сети N.
Каждый раз при обучении N,
Т модифицируется следующим образом:
alpha = target_network_update_rate
T = (1-alpha)*T + alpha*N
summary_writer: tf.train.SummaryWriter
запись логов
"""
# memorize arguments
self.observation_size = observation_size
self.num_actions = num_actions
self.q_network = observation_to_actions
self.optimizer = optimizer
self.s = session
self.random_action_probability = random_action_probability
self.exploration_period = exploration_period
self.store_every_nth = store_every_nth
self.train_every_nth = train_every_nth
self.minibatch_size = minibatch_size
self.discount_rate = tf.constant(discount_rate)
self.max_experience = max_experience
self.target_network_update_rate = tf.constant(target_network_update_rate)
# deepq state
self.actions_executed_so_far = 0
self.experience = deque()
self.iteration = 0
self.summary_writer = summary_writer
self.number_of_times_store_called = 0
self.number_of_times_train_called = 0
self.create_variables()
# расчет вероятности случайного действия
# с учетом уменьшения с итерациями
# (линейный отжиг)
def linear_annealing(self, n, total, p_initial, p_final):
"""Linear annealing between p_initial and p_final
over total steps - computes value at step n"""
if n >= total:
return p_final
else:
return p_initial - (n * (p_initial - p_final)) / (total)
# создание графов TensorFlow для
# для расчета управляющего действия
# и реализации Q-learning
def create_variables(self):
# создание нейросети T копированием из исходной нейросети N
self.target_q_network = self.q_network.copy(scope="target_network")
# расчет управляющего действия
# FOR REGULAR ACTION SCORE COMPUTATION
with tf.name_scope("taking_action"):
# входные данные вектора состояния
self.observation = tf.placeholder(tf.float32, (None, self.observation_size), name="observation")
# расчитать очки оценки полезности каждого действия
self.action_scores = tf.identity(self.q_network(self.observation), name="action_scores")
tf.histogram_summary("action_scores", self.action_scores)
# взять действие с максимальным количеством очков
self.predicted_actions = tf.argmax(self.action_scores, dimension=1, name="predicted_actions")
# расчет будущей пользы
with tf.name_scope("estimating_future_rewards"):
# FOR PREDICTING TARGET FUTURE REWARDS
# входной параметр - будущие состояния
self.next_observation = tf.placeholder(tf.float32, (None, self.observation_size), name="next_observation")
# входной параметр - маски будущих состояний
self.next_observation_mask = tf.placeholder(tf.float32, (None,), name="next_observation_mask")
# оценки полезности
self.next_action_scores = tf.stop_gradient(self.target_q_network(self.next_observation))
tf.histogram_summary("target_action_scores", self.next_action_scores)
# входной параметр - награды
self.rewards = tf.placeholder(tf.float32, (None,), name="rewards")
# взять максимальные оценки полезностей действий
target_values = tf.reduce_max(self.next_action_scores, reduction_indices=[1,]) * self.next_observation_mask
# r + DF * MAX(Q,s) см статью о Q-learning в википедии
self.future_rewards = self.rewards + self.discount_rate * target_values
# обученте сети N
with tf.name_scope("q_value_precition"):
# FOR PREDICTION ERROR
# входной параметр маски действий в наборе обучающих примеров
self.action_mask = tf.placeholder(tf.float32, (None, self.num_actions), name="action_mask")
# расчет полезностей действий набора обучающих примеров
self.masked_action_scores = tf.reduce_sum(self.action_scores * self.action_mask, reduction_indices=[1,])
# разности текущих полезностей и будущих
# - (r + DF * MAX(Q,s) — Q[s',a'])
temp_diff = self.masked_action_scores - self.future_rewards
# ключевой момент обучения сети
# RMSProp минимизирует среднее от вышеуказанных разностей
self.prediction_error = tf.reduce_mean(tf.square(temp_diff))
# работа RMSProp, первый шаг - вычисление градиентов
gradients = self.optimizer.compute_gradients(self.prediction_error)
for i, (grad, var) in enumerate(gradients):
if grad is not None:
gradients[i] = (tf.clip_by_norm(grad, 5), var)
# Add histograms for gradients.
for grad, var in gradients:
tf.histogram_summary(var.name, var)
if grad:
tf.histogram_summary(var.name + '/gradients', grad)
# второй шаг - оптимизация параметров нейросети
self.train_op = self.optimizer.apply_gradients(gradients)
# то самое место где настраивается сеть T
# T = (1-alpha)*T + alpha*N
# UPDATE TARGET NETWORK
with tf.name_scope("target_network_update"):
self.target_network_update = []
for v_source, v_target in zip(self.q_network.variables(), self.target_q_network.variables()):
# this is equivalent to target = (1-alpha) * target + alpha * source
update_op = v_target.assign_sub(self.target_network_update_rate * (v_target - v_source))
self.target_network_update.append(update_op)
self.target_network_update = tf.group(*self.target_network_update)
# summaries
tf.scalar_summary("prediction_error", self.prediction_error)
self.summarize = tf.merge_all_summaries()
self.no_op1 = tf.no_op()
# управление
def action(self, observation):
"""Given observation returns the action that should be chosen using
DeepQ learning strategy. Does not backprop."""
assert len(observation.shape) == 1, "Action is performed based on single observation."
self.actions_executed_so_far += 1
# расчет вероятности случайного действия
exploration_p = self.linear_annealing(self.actions_executed_so_far,
self.exploration_period,
1.0,
self.random_action_probability)
if random.random() < exploration_p:
# случайное действие
return random.randint(0, self.num_actions - 1)
else:
# действие выбранное нейросетью
return self.s.run(self.predicted_actions, {self.observation: observation[np.newaxis,:]})[0]
# сохранение обучающего примера
# обучающий примеры берутся из действий нейросети
# во время управления
def store(self, observation, action, reward, newobservation):
"""Store experience, where starting with observation and
execution action, we arrived at the newobservation and got thetarget_network_update
reward reward
If newstate is None, the state/action pair is assumed to be terminal
"""
if self.number_of_times_store_called % self.store_every_nth == 0:
self.experience.append((observation, action, reward, newobservation))
if len(self.experience) > self.max_experience:
self.experience.popleft()
self.number_of_times_store_called += 1
# шаг обучения
def training_step(self):
"""Pick a self.minibatch_size exeperiences from reply buffer
and backpropage the value function.
"""
if self.number_of_times_train_called % self.train_every_nth == 0:
if len(self.experience) < self.minibatch_size:
return
# из всего сохраненного опыта случайно выбираем
# пачку из minibatch_size обучающих примеров
# sample experience.
samples = random.sample(range(len(self.experience)), self.minibatch_size)
samples = [self.experience[i] for i in samples]
# представляем обучающие примеры
# в нужном виде
# bach states
states = np.empty((len(samples), self.observation_size))
newstates = np.empty((len(samples), self.observation_size))
action_mask = np.zeros((len(samples), self.num_actions))
newstates_mask = np.empty((len(samples),))
rewards = np.empty((len(samples),))
for i, (state, action, reward, newstate) in enumerate(samples):
states[i] = state
action_mask[i] = 0
action_mask[i][action] = 1
rewards[i] = reward
if newstate is not None:
newstates[i] = newstate
newstates_mask[i] = 1
else:
newstates[i] = 0
newstates_mask[i] = 0
calculate_summaries = self.iteration % 100 == 0 and self.summary_writer is not None
# запускаем вычисления
# сначала считаем ошибку сети
# потом запускаем оптимизацию сети
# далее собираем статистику (необязательный шаг
# нужный для построения графиков обучения)
cost, _, summary_str = self.s.run([
self.prediction_error,
self.train_op,
self.summarize if calculate_summaries else self.no_op1,
], {
self.observation: states,
self.next_observation: newstates,
self.next_observation_mask: newstates_mask,
self.action_mask: action_mask,
self.rewards: rewards,
})
# подстраиваем нейросеть Т
self.s.run(self.target_network_update)
if calculate_summaries:
self.summary_writer.add_summary(summary_str, self.iteration)
self.iteration += 1
self.number_of_times_train_called += 1
karpathy_game.py - игра, в которую играет нейросеть
import math
import matplotlib.pyplot as plt
import numpy as np
import random
import time
from collections import defaultdict
from euclid import Circle, Point2, Vector2, LineSegment2
import tf_rl.utils.svg as svg
# Игровой объект
# это шарик определенного цвета
# данный класс рассчитывает перемещение
# столкновения и занимается отрисовкой
class GameObject(object):
def __init__(self, position, speed, obj_type, settings):
"""Esentially represents circles of different kinds, which have
position and speed."""
self.settings = settings
self.radius = self.settings["object_radius"]
self.obj_type = obj_type
self.position = position
self.speed = speed
self.bounciness = 1.0
def wall_collisions(self):
"""Update speed upon collision with the wall."""
world_size = self.settings["world_size"]
for dim in range(2):
if self.position[dim] - self.radius <= 0 and self.speed[dim] < 0:
self.speed[dim] = - self.speed[dim] * self.bounciness
elif self.position[dim] + self.radius + 1 >= world_size[dim] and self.speed[dim] > 0:
self.speed[dim] = - self.speed[dim] * self.bounciness
def move(self, dt):
"""Move as if dt seconds passed"""
self.position += dt * self.speed
self.position = Point2(*self.position)
def step(self, dt):
"""Move and bounce of walls."""
self.wall_collisions()
self.move(dt)
def as_circle(self):
return Circle(self.position, float(self.radius))
def draw(self):
"""Return svg object for this item."""
color = self.settings["colors"][self.obj_type]
return svg.Circle(self.position + Point2(10, 10), self.radius, color=color)
# Игра. Здесь все довольно просто
# Сначала, в соответствии с настройками,
# создаются стенки и объект, которым управляет
# алгоритм. Здесь я не буду комментировать
# все, так как тут^ в принципе, по коду понятно,
# что происходит, ниже откомментирую функцию
# observe, так как она имеет непосредственное
# отношение к входным данным алгоритма
class KarpathyGame(object):
def __init__(self, settings):
"""Initiallize game simulator with settings"""
self.settings = settings
self.size = self.settings["world_size"]
self.walls = [LineSegment2(Point2(0,0), Point2(0,self.size[1])),
LineSegment2(Point2(0,self.size[1]), Point2(self.size[0], self.size[1])),
LineSegment2(Point2(self.size[0], self.size[1]), Point2(self.size[0], 0)),
LineSegment2(Point2(self.size[0], 0), Point2(0,0))]
self.hero = GameObject(Point2(*self.settings["hero_initial_position"]),
Vector2(*self.settings["hero_initial_speed"]),
"hero",
self.settings)
if not self.settings["hero_bounces_off_walls"]:
self.hero.bounciness = 0.0
self.objects = []
for obj_type, number in settings["num_objects"].items():
for _ in range(number):
self.spawn_object(obj_type)
self.observation_lines = self.generate_observation_lines()
self.object_reward = 0
self.collected_rewards = []
# Каждый радиальный отрезок видит объект или стенку
# и два числа представляющих собой скорость объекта
# every observation_line sees one of objects or wall and
# two numbers representing speed of the object (if applicable)
self.eye_observation_size = len(self.settings["objects"]) + 3
# и, в конце, к состоянию добавляются
# два числа - скорость управляемого объекта
# additionally there are two numbers representing agents own speed.
self.observation_size = self.eye_observation_size * len(self.observation_lines) + 2
self.last_observation = np.zeros(self.observation_size)
self.directions = [Vector2(*d) for d in [[1,0], [0,1], [-1,0],[0,-1]]]
self.num_actions = len(self.directions)
self.objects_eaten = defaultdict(lambda: 0)
def perform_action(self, action_id):
"""Change speed to one of hero vectors"""
assert 0 <= action_id < self.num_actions
self.hero.speed *= 0.8
self.hero.speed += self.directions[action_id] * self.settings["delta_v"]
def spawn_object(self, obj_type):
"""Spawn object of a given type and add it to the objects array"""
radius = self.settings["object_radius"]
position = np.random.uniform([radius, radius], np.array(self.size) - radius)
position = Point2(float(position[0]), float(position[1]))
max_speed = np.array(self.settings["maximum_speed"])
speed = np.random.uniform(-max_speed, max_speed).astype(float)
speed = Vector2(float(speed[0]), float(speed[1]))
self.objects.append(GameObject(position, speed, obj_type, self.settings))
def step(self, dt):
"""Simulate all the objects for a given ammount of time.
Also resolve collisions with the hero"""
for obj in self.objects + [self.hero] :
obj.step(dt)
self.resolve_collisions()
def squared_distance(self, p1, p2):
return (p1[0] - p2[0]) ** 2 + (p1[1] - p2[1]) ** 2
def resolve_collisions(self):
"""If hero touches, hero eats. Also reward gets updated."""
collision_distance = 2 * self.settings["object_radius"]
collision_distance2 = collision_distance ** 2
to_remove = []
for obj in self.objects:
if self.squared_distance(self.hero.position, obj.position) < collision_distance2:
to_remove.append(obj)
for obj in to_remove:
self.objects.remove(obj)
self.objects_eaten[obj.obj_type] += 1
self.object_reward += self.settings["object_reward"][obj.obj_type]
self.spawn_object(obj.obj_type)
def inside_walls(self, point):
"""Check if the point is inside the walls"""
EPS = 1e-4
return (EPS <= point[0] < self.size[0] - EPS and
EPS <= point[1] < self.size[1] - EPS)
# возвращает вектор состояния
def observe(self):
"""Return observation vector. For all the observation directions it returns representation
of the closest object to the hero - might be nothing, another object or a wall.
Representation of observation for all the directions will be concatenated.
"""
num_obj_types = len(self.settings["objects"]) + 1 # and wall
max_speed_x, max_speed_y = self.settings["maximum_speed"]
# расстояние видимости
observable_distance = self.settings["observation_line_length"]
# получение всех объектов в зоне видимости
relevant_objects = [obj for obj in self.objects
if obj.position.distance(self.hero.position) < observable_distance]
# сортировка объектов по расстоянию
# сначала ближние
# objects sorted from closest to furthest
relevant_objects.sort(key=lambda x: x.position.distance(self.hero.position))
observation = np.zeros(self.observation_size)
observation_offset = 0
# начинаем перебирать отрезки зрения
for i, observation_line in enumerate(self.observation_lines):
# shift to hero position
observation_line = LineSegment2(self.hero.position + Vector2(*observation_line.p1),
self.hero.position + Vector2(*observation_line.p2))
observed_object = None
# проверяем видим ли мы стену
# if end of observation line is outside of walls, we see the wall.
if not self.inside_walls(observation_line.p2):
observed_object = "**wall**"
# перебираем объекты в зоне видимости
for obj in relevant_objects:
if observation_line.distance(obj.position) < self.settings["object_radius"]:
# нашли объект
observed_object = obj
break
# параметры найденного объекта
# тип, скорость и расстояние до него
object_type_id = None
speed_x, speed_y = 0, 0
proximity = 0
if observed_object == "**wall**": # wall seen
# видим стену
object_type_id = num_obj_types - 1
# в примере стена всегда обладает
# нулевой скоростью, я подумал,
# что лучше, все таки, использовать
# ее относительную скорость
# в результате
# качество управление улучшилось
# a wall has fairly low speed...
# speed_x, speed_y = 0, 0
# I think relative speed is better than absolute
speed_x, speed_y = tuple (-self.hero.speed)
# best candidate is intersection between
# observation_line and a wall, that's
# closest to the hero
best_candidate = None
for wall in self.walls:
candidate = observation_line.intersect(wall)
if candidate is not None:
if (best_candidate is None or
best_candidate.distance(self.hero.position) >
candidate.distance(self.hero.position)):
best_candidate = candidate
if best_candidate is None:
# assume it is due to rounding errors
# and wall is barely touching observation line
proximity = observable_distance
else:
proximity = best_candidate.distance(self.hero.position)
elif observed_object is not None: # agent seen
# видим объект
# тип объекта
object_type_id = self.settings["objects"].index(observed_object.obj_type)
# здесь я тоже использовал скорость относительно
# управляемого объекта
speed_x, speed_y = tuple(observed_object.speed - self.hero.speed)
intersection_segment = obj.as_circle().intersect(observation_line)
assert intersection_segment is not None
# вычисление расстояние до объекта
try:
proximity = min(intersection_segment.p1.distance(self.hero.position),
intersection_segment.p2.distance(self.hero.position))
except AttributeError:
proximity = observable_distance
for object_type_idx_loop in range(num_obj_types):
# здесь 1.0 означает отсутствие в поле видимости
# объекта заданного типа
observation[observation_offset + object_type_idx_loop] = 1.0
if object_type_id is not None:
# если объект найден то в ячейке типа объекта
# задается расстояние меньше от 0.0 до 1.0
# расстояние меряется относительно длины отрезка
observation[observation_offset + object_type_id] = proximity / observable_distance
# скорость найденного объекта
observation[observation_offset + num_obj_types] = speed_x / max_speed_x
observation[observation_offset + num_obj_types + 1] = speed_y / max_speed_y
assert num_obj_types + 2 == self.eye_observation_size
observation_offset += self.eye_observation_size
# после заполнения данных со всех отрезков
# добавляется скорость управляемого объекта
observation[observation_offset] = self.hero.speed[0] / max_speed_x
observation[observation_offset + 1] = self.hero.speed[1] / max_speed_y
assert observation_offset + 2 == self.observation_size
self.last_observation = observation
return observation
def distance_to_walls(self):
"""Returns distance of a hero to walls"""
res = float('inf')
for wall in self.walls:
res = min(res, self.hero.position.distance(wall))
return res - self.settings["object_radius"]
def collect_reward(self):
"""Return accumulated object eating score + current distance to walls score"""
wall_reward = self.settings["wall_distance_penalty"] * np.exp(-self.distance_to_walls() / self.settings["tolerable_distance_to_wall"])
assert wall_reward < 1e-3, "You are rewarding hero for being close to the wall!"
total_reward = wall_reward + self.object_reward
self.object_reward = 0
self.collected_rewards.append(total_reward)
return total_reward
def plot_reward(self, smoothing = 30):
"""Plot evolution of reward over time."""
plottable = self.collected_rewards[:]
while len(plottable) > 1000:
for i in range(0, len(plottable) - 1, 2):
plottable[i//2] = (plottable[i] + plottable[i+1]) / 2
plottable = plottable[:(len(plottable) // 2)]
x = []
for i in range(smoothing, len(plottable)):
chunk = plottable[i-smoothing:i]
x.append(sum(chunk) / len(chunk))
plt.plot(list(range(len(x))), x)
def generate_observation_lines(self):
"""Generate observation segments in settings["num_observation_lines"] directions"""
result = []
start = Point2(0.0, 0.0)
end = Point2(self.settings["observation_line_length"],
self.settings["observation_line_length"])
for angle in np.linspace(0, 2*np.pi, self.settings["num_observation_lines"], endpoint=False):
rotation = Point2(math.cos(angle), math.sin(angle))
current_start = Point2(start[0] * rotation[0], start[1] * rotation[1])
current_end = Point2(end[0] * rotation[0], end[1] * rotation[1])
result.append( LineSegment2(current_start, current_end))
return result
def _repr_html_(self):
return self.to_html()
def to_html(self, stats=[]):
"""Return svg representation of the simulator"""
stats = stats[:]
recent_reward = self.collected_rewards[-100:] + [0]
objects_eaten_str = ', '.join(["%s: %s" % (o,c) for o,c in self.objects_eaten.items()])
stats.extend([
"nearest wall = %.1f" % (self.distance_to_walls(),),
"reward = %.1f" % (sum(recent_reward)/len(recent_reward),),
"objects eaten => %s" % (objects_eaten_str,),
])
scene = svg.Scene((self.size[0] + 20, self.size[1] + 20 + 20 * len(stats)))
scene.add(svg.Rectangle((10, 10), self.size))
num_obj_types = len(self.settings["objects"]) + 1 # and wall
observation_offset = 0;
for line in self.observation_lines:
# getting color of the line
linecolor = 'black';
linewidth = '1px';
for object_type_idx_loop in range(num_obj_types):
if self.last_observation[observation_offset + object_type_idx_loop] < 1.0:
if object_type_idx_loop < num_obj_types - 1:
linecolor = self.settings["colors"][self.settings["objects"][object_type_idx_loop]];
linewidth = '3px';
observation_offset += self.eye_observation_size
scene.add(svg.Line(line.p1 + self.hero.position + Point2(10,10),
line.p2 + self.hero.position + Point2(10,10),
color = linecolor,
stroke = linecolor,
stroke_width = linewidth))
for obj in self.objects + [self.hero] :
scene.add(obj.draw())
offset = self.size[1] + 15
for txt in stats:
scene.add(svg.Text((10, offset + 20), txt, 15))
offset += 20
return scene
Если вы захотите посмотреть как все это работает вам будет необходим IPython Notebook. Так как все это собирается воедино в сценарии для него. Сценарий находится по адресу notebooks/karpathy_game.ipynb.
Результат
Пока писал статью, запустил на несколько часов обучение. Ниже видео: как у меня в итоге обучилась сетка за довольно небольшое время.
Куда двигаться дальше
Дальше я планирую попробовать внедрить этот метод в свой виртуальный квадрокоптер. Сначала хочу попробовать сделать стабилизацию. Потом, если получится, попробую сделать чтобы оно летало, но там уже, скорее всего, понадобится сверточная сеть вместо многослойного перцептрона.
Пример заботливо выложен на гитхаб пользователем nivwusquorum, за что хочется выразить ему огромное человеческое спасибо.
sys_int64
Это как? я думал таких в природе не существует.
Parilo
Я тоже так думал, но даже в той самой статье упоминается термин multilayer perceptrons, так же как и в коде примера. Видимо это указывает на нелинейную передаточную функцию.
rocknrollnerd
Нет, это так просто обычные feedforward-сети называют) Не перцептрон Розенблатта.
avonar
Спасибо!
Я почитал более подробно.
Теперь я понял, почему еще в институте не мог найти общий язык с преподавателями. Я подразумевал под перцептроном как раз feedforward сеть, а они только господина Розенблатта!
rocknrollnerd
Бывает, ага. В своем институте на меня тоже иногда так непонимающе смотрят, в духе «нейронные сети, втф? про них же еще в 60-х сказали, что это неинтересно»)
kxx
Знакомая картина. Особенно, когда профессор 85-ти лет начинает рассуждать про то, что это уже давно было
в Симпсонах, и вообще — адаптивные фильтры решают все проблемы -)masai
Персептрон — это не обязательно персептрон Розенблатта, это ещё и обобщения — многослойные ИНС прямого распространения. У Хайкина вот целая глава называется «Многослойный персептрон». Хотя в старой литературе персептрон был только однослойным (но и там есть вопросы, что считать слоем).
7voprosov
На сколько я понимаю исторически есть небольшая путаница с понятиями, но сейчас более или менее принято (опять же как я понимаю) считать перцептрон без срытых обучаемых слоев перцептроном Розенблатта (при этом сами «слои» могу быть, но обучается только последний слой методом коррекции ошибки), остальные же считаются «многослойными» и обучаются различными вариациями backpropagation.
P.S Лично я считаю что называть backpropagation «обучающим» несколько странно — обучают нейронную сеть различные алгоритмы нахождения оптимума (градиентный спуск, bfgs и т.д)
Parilo
так backpropagation же вроде является градиентным спуском
7voprosov
Ну это как считать. Это алгоритм на выходе дает градиент весов. А как по этому градиенту найти оптимум — это уже задача следующего алгоритма. При этом такие алгоритмы как bfgs пытаются еще по значению и градиенту оценить и вторую производную (хотя тут я совсем профан) и уже с помощью всего этого ищут оптимум.
kmike
Backpropogation — это алгоритм вычисления производной. Причем, если не ошибаюсь, в Tensorflow (как и в Theano) он не используется, т.к. производные вычисляются символьно, а не численно. Производные (градиенты) нужны алгоритмам оптимизации — градиентному спуску, например. Обычный градиентный спуск почти не используется, применяют обычно SGD, всякие его модификации с моментами, отдельными learning rate для каждого параметра и т.д.
7voprosov
Ну, иногда точно вычисляет:
www.tensorflow.org/versions/master/tutorials/mnist/beginners/index.html
«Now that we know what we want our model to do, it's very easy to have TensorFlow train it to do so. Because TensorFlow knows the entire graph of your computations, it can automatically use the backpropagation algorithm to efficiently determine how your variables affect the cost you ask it minimize. Then it can apply your choice of optimization algorithm to modify the variables and reduce the cost.»
Кстати, численное значение градиента (за место аналитики, пусть и автоматической) в ML вычисляют только из за проблем с размерами матриц или есть ещё какие причины?
rocknrollnerd
Если вы под «численным» имеете в виду вот эту штуку, то так как раз не делают — это очень медленно. Для нейронов ищут такие функции, чтобы у них были легкие аналитические производные — скажем, для сигмоиды это f(x) * (1 — f(x)), а для RELU вообще просто либо 0, либо 1. Сами производные вычисляются аналитически, а в коде вы просто используете полученную формулу.
Если вы имеете в виду, что такого делает Theano/TensorFlow, чего не умели раньше, то ничего особенного) Чтобы получить производную от ошибки (которая считается на выходе) по весу отдельного нейрона, нужно много-много раз (в зависимости от глубины сети) применить chain rule (вот тут подробности, а вот тут подробности человеческим языком). Чтобы не выписывать для каждого нейрона длинное выражение, проще делать это итеративно — посчитать производную для последнего слоя, вычислить нужную дельту, сделать шаг назад на один слой, использовать дельту для производной следующего слоя, вычислить новую дельту и т.д. Theano может составлять выражение для chain rule автоматически, поэтому ему это не сложно) А так — механизм получается абсолютно одинаковый.
7voprosov
Да, я имел ввиду второй вариант. Спасибо за ссылки и пояснения :)