Вашему вниманию предлагается обзор решения VMware NSX на основе доклада-демонстрации на выставке МУК-Экспо 2015. Видеозапись демонстрации в хорошем качестве — 720p — все отчетливо видно. Для тех, кто не хочет смотреть видео — под катом расшифровка демонстрации и скриншоты.
Дисклеймеры:
1. Стенограмма с небольшой редактурой.
2. Просим помнить о разнице в письменной и устной речи.
3. Скриншоты в большом размере, иначе ничего не разобрать.
2. Просим помнить о разнице в письменной и устной речи.
3. Скриншоты в большом размере, иначе ничего не разобрать.
Коллеги, добрый день. Мы начинаем демонстрацию VMware NSX. Итак, что бы хотелось сегодня показать. Наша демо-инфраструктура развернута на базе нашего дистрибьютора MUK. Инфраструктура достаточно небольшая — это три сервера, серверы есть ESXI в 6-й версии апдейт 1 v-центр обновленный, то есть самое свежее, что мы можем предложить.
В этой структуре мы до использования NSX получили от сетевых инженеров MUK-а несколько VLan-ов, в которых можно было разместить серверный сегмент, видео-десктопы, сегмент, который имеет доступ в интернет, для того чтобы от видео-десктопа можно было получить доступ в интернет, ну и доступ к транзитным сетям для того, чтобы коллеги из MUK могли из внутренней своей сети подключаться, да? Любые операции, связанные, например, если я захочу для какого-то демо или какого-то пилота создать еще несколько каких-то там сетей порт-груп сделать более сложную конфигурацию, надо обратиться к коллегам из MUK, попросить, чтобы они на оборудовании что-то там наделали.
Если мне нужно взаимодействие между сегментами, то либо опять же договариваться с сетевиками, либо по-простому — маленькую машинку, роутер внутри, два интерфейса, туда-сюда, как все мы привыкли делать.
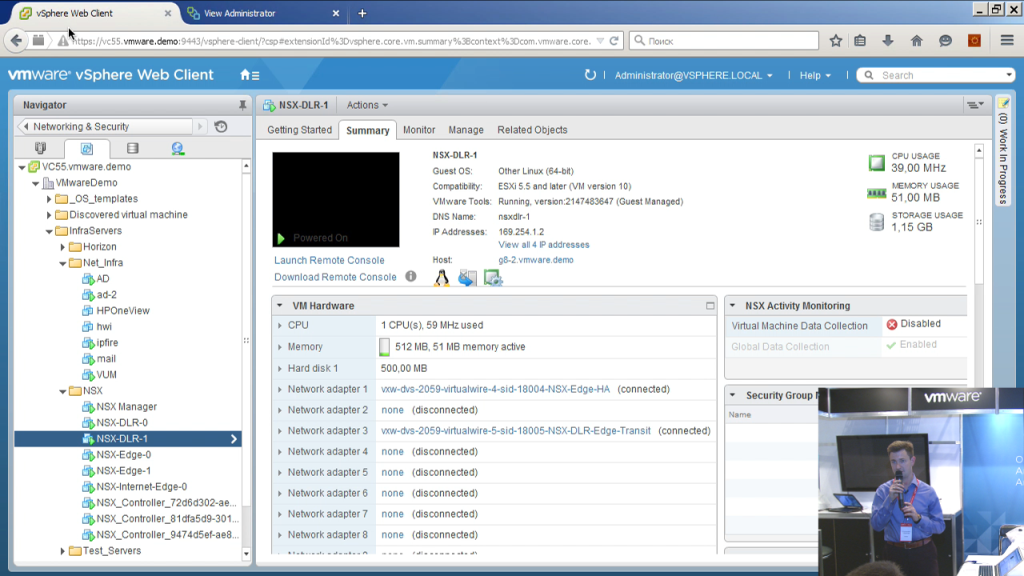
Соответственно использование NSX 10 преследует две цели: с одной стороны, это показать, как это работает не на виртуалках, на железе, да, что это реально работает и это удобно; второй момент, это действительно упростить определенные свои задачи. Соответственно, что мы видим в данный момент? В данный момент мы видим, какие виртуальные машины появились в этой инфраструктуре после того, как NSX был внедрен. Некоторые из них являются обязательными, без них нельзя. Некоторые появились вследствие определенного сетапа самой инфраструктуры.
Соответственно, обязательными являются NSX-менеджер — это основной сервер, через который мы можем взаимодействовать с NSX, он предоставляет веб-клиент V-центра свой графический интерфейс, он позволяет обращаться к нему через rest api для того, чтобы автоматизировать какие-то действия, которые можно делать с NSX либо какими-то скриптами, либо, например, из различных облачных порталов. Например, VMware vRealize Automation либо порталы других вендоров. Для работы технически NSX-у нужен кластер из NSX-контроллеров, то есть эти серверы выполняют служебную роль. Они определяют, они знают, да, они хранят в себе информацию о том, на каком физическом esxi-сервере, какие ip-адреса и mac-адреса в данный момент присутствуют, какие у нас новые сервера добавились, какие отвалились, распространяют эту информацию на esxi -сервера, то есть фактически, когда у нас есть созданный при помощи NSX, L2 сегмент, который должен быть доступен на нескольких esxi -серверах и виртуальная машина пытается отправить ip-пакет другой виртуальной машине в том же самом L2-сегменте, NSX-контроллеры точно знают, на какой хост на самом деле сетевой пакет нужно доставить. И они эту информацию регулярно хостам отдают. Каждый хост владеет таблицей, какие ip, какие mac-адреса на каких хостах находятся, какие реально, физически пакеты надо передавать.
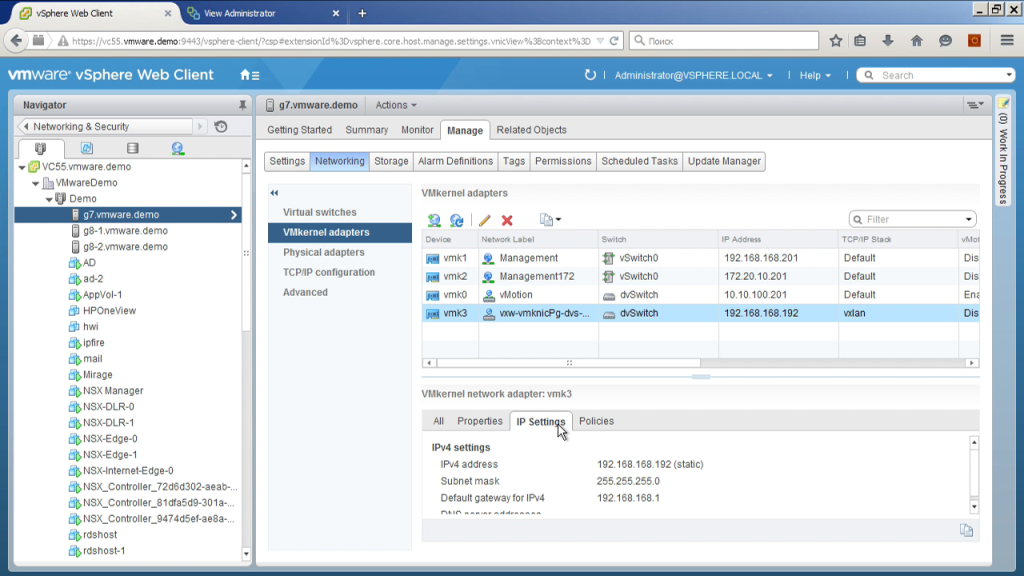
Если мы откроем конфигурацию какого-либо хоста, то мы можем увидеть тот самый интерфейс, через который пакеты будут по сети передаваться. То есть у нас параметры VMkernel адаптера, данный хост будет, используя этот ip-адрес в сеть VXLan пакеты. Немножко у нас тут маленький монитор, поэтому приходится выкручиваться.

И мы видим, что отдельный TCP/IP stack используется для передачи этих пакетов, то есть может быть отдельный default gateway отличный от обычного VMkernel интерфейса. То есть с точки зрения физики: для того, чтобы в демо это развернуть, мне понадобился один VLan, в который я могу разместить эти интерфейсы; желательно — и я проверил, что этот VLan он не только на эти три сервера распространяется, он растянут немножко дальше, если появится там четвертый-пятый сервер, например, не в том же самом шасси, где эти лезвия стоят, а где-то отдельный, может быть, даже не в этом VLan-е, но который маршрутизируется сюда, я смогу добавить, например, четвертый сервер, который будет в другой сети, но они между собой смогут общаться, я смогу растянуть свои L2-сети, созданные при помощи NSX с этих трех серверов в том числе и на этот новый четвертый.
Ну и собственно теперь переходим к тому, как выглядит сам NSX, то есть: что мы можем с ним сделать мышкой и клавиатурой, да? Мы не говорим сейчас о rest api, когда мы хотим что-либо автоматизировать.

Раздел Installation (сейчас мы туда, я надеюсь, переключимся) позволяет нам посмотреть, кто у нас менеджер, сколько контроллеров, сами контроллеры разворачиваются отсюда. То есть менеджер мы скачиваем с сайта VMware, это template, мы его разворачиваем и внедряем в V-центр. Далее мы настраиваем менеджер, указываем ему логин-пароль для подключения к V-центр серверу, для того чтобы он смог зарегистрировать плагин здесь. После этого мы подключаемся к этому уже интерфейсу, говорим: «Надо внедрить контроллеры».
Минимально, если мы говорим, например, о каком-то тестовом стенде, контроллер может быть даже один, система будет работать, но это не рекомендуется. Рекомендуемая конфигурация — это три контроллера, желательно на разных серверах, на разных хранилках, для того, чтобы выход из строя какого-то компонента не мог привести к потере всех трех контроллеров сразу.

Также мы можем определить, какие хосты и какие кластеры под управлением этого V-центр сервера будут взаимодействовать с NSX. На самом деле, не обязательно вся инфраструктура под управлением одного V-центр сервера будет с этим работать, могут быть некие выборочные кластеры. Выбрав кластеры, мы должны выполнить установку на них дополнительных модулей, которые позволяют esxi серверу делать инкапсуляцию/декапсуляцию VXLan пакетов, делается это, опять же, из этого интерфейса. То есть не надо ходить в SSH, не надо никакие модули вручную копировать, отсюда нажали кнопку, отследили статус «получилось/не получилось».
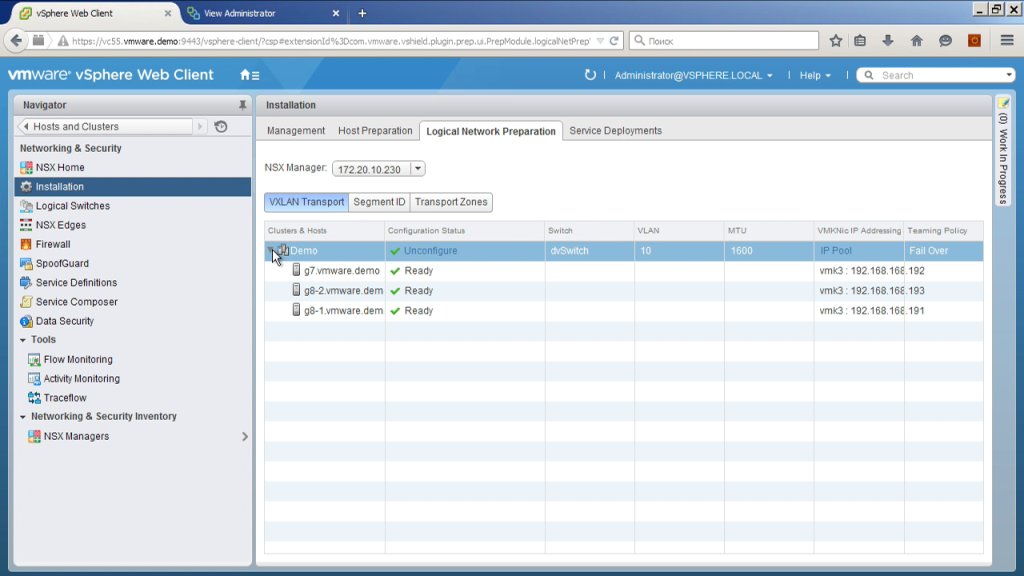
Далее мы должны выбрать, собственно говоря, каким образом вот эта настройка VMkernel интерфейса будет происходить. То есть мы выбираем распределенный коммутатор, выбираем аплинки, то есть где это произойдет; выбираем параметры балансировки нагрузки, когда линков несколько, в зависимости от этого, когда у нас на один хост только один ip-адрес такого типа, иногда их может быть несколько. Сейчас мы используем в режиме по одному.
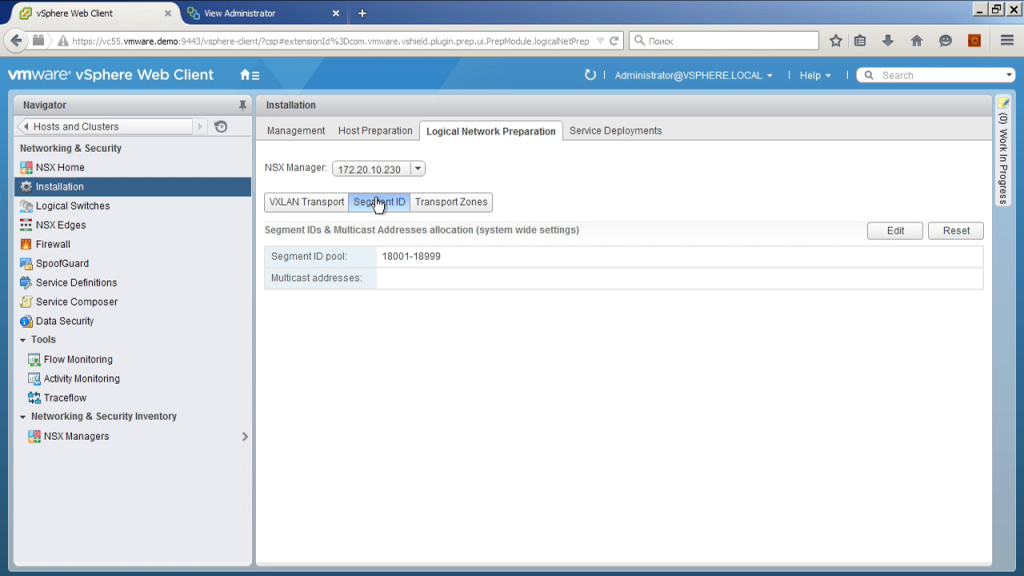
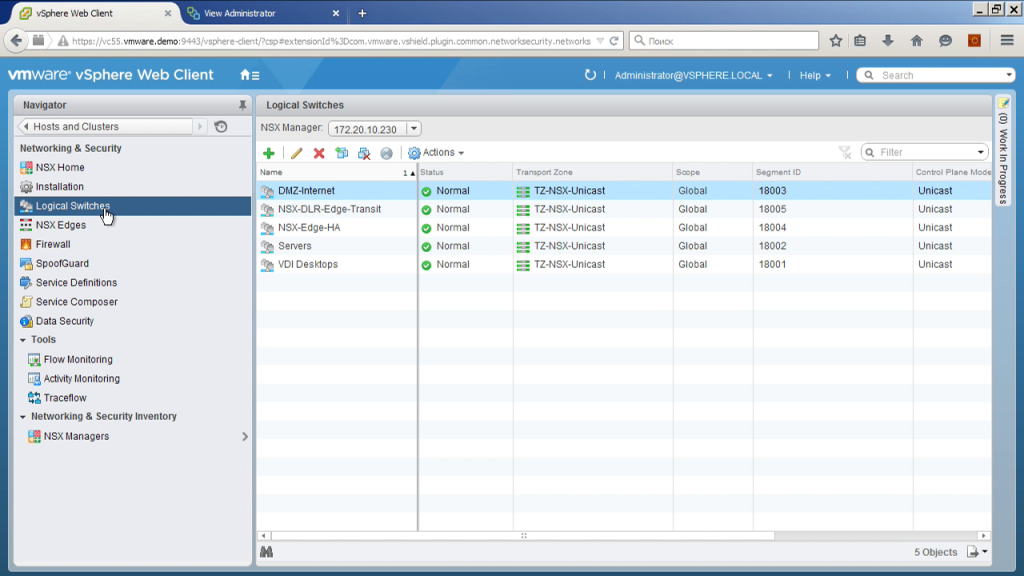
Далее мы должны выбрать идентификатор VXLan. То есть VXLan — это технология, напоминающая VLan, но это дополнительные метки, позволяющие в одном реальном сегменте изолировать разные виды трафика. Если VLan идентификаторов — их 4 тыс., VXLan идентификаторов— их 16 млн. Здесь мы фактически выбираем некий диапазон номеров VXLan сегментов, которые при автоматическом создании логических свичей, будут им присваиваться.
Как их выбирать? Собственно говоря, как хотите, из вот этого диапазона, если у вас большая инфраструктура и может быть несколько NSX внедрений так, чтобы они не пересекались. Просто-напросто. Собственно, так же, как и VLan. То есть я использую диапазон с 18001 по 18999.

Далее мы можем создать так называемую транспортную зону. Что такое транспортная зона? Если инфраструктура достаточно большая, представьте себе, у вас есть там порядка сотни esxi-серве ров, примерно по 10 серверов на кластер, у вас есть 10 кластеров. Мы можем не все из них задействовать для работы с NSX. Те из них, которые мы задействовали, мы можем использовать как одну инфраструктуру, а можем разбить, например, на несколько групп. Сказать, что у нас первые три кластера — это один островок, с четвертого по десятый — это некий другой островок. То есть, создав транспортные зоны, мы указываем, как далеко этот VXLan-сегмент может распространяться. У меня здесь три сервера, особо не разживешься, да? Поэтому здесь все по-простому. Просто все хосты у меня попадают в эту зону.
И еще один важный момент. При настройке зоны мы управляем, каким образом будет идти обмен информацией для поиска информации об ip-адресах, mac-адресах. Это может быть Unicast, это может быть Multycast уровня L2, это может быть Unicast, маршрутизируемый через уровень L3. Опять же, в зависимости от сетевой топологии.
Это такие некие предварительные вещи, то есть еще раз повторюсь: все, что потребовалось от сетевой инфраструктуры — это то, чтобы у меня все хосты, на которых должен работать NSX, могли взаимодействовать между собой по ip, используя, если нужно, в том числе и обычную маршрутизацию. И второй момент — это то, чтобы MTU вот в этом сегменте, где они взаимодействуют, был 1600 байт, а не 1500 — как это происходит обычно. Если же я не могу получить 1600 байт, поэтому мне просто придется во всех конструкциях, которые я создаю в NSX-е, явным образом прикручивать MTU, например в 1400, чтобы я в физическим транспорте в 1500 поместился.
Далее. Использую NSX, я могу создать логический коммутатор. Это проще всего в сравнении с традиционной сетью (VLan нарезать). Единственное что, как бы я не знаю, куда подключены мои физические серверы, да, здесь — это одни и те же коммутаторы. Теоретически сеть может быть более сложной. У вас может быть часть серверов подключена к одному коммутатору, часть к другому, где-то L2, где-то L3. В итоге, фактически создавая логический свитч, мы нарезаем VLan сразу на всех коммутаторах, через которые трафик будет ходить. Почему? Потому что на самом деле мы создаем VXLan, а реальный физический трафик, который будут видеть коммутаторы, — это трафик с ip-адреса на одного гипервизора на ip-адрес другого гипервизора, тип udp, внутри VXLan-содержимое.
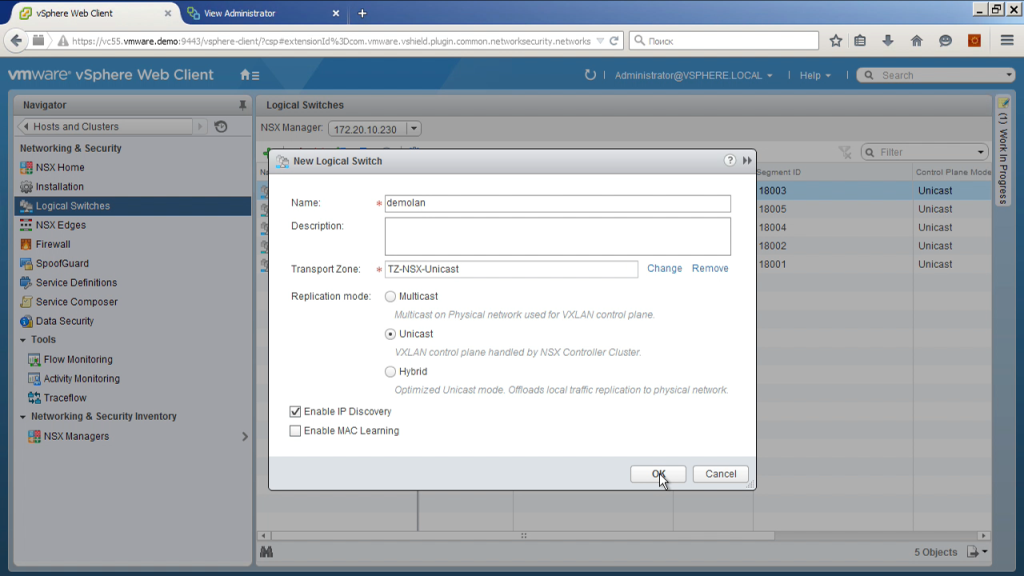
То есть таким образом нарезка сетей происходит очень легко. Мы просто говорим: «Создать новый сегмент», выбираем тип транспорта unicast, выбираем, через какую транспортную зону, то есть фактически на каких esxi-кластерах этот сегмент будет доступен. Немножко ждем — и сейчас этот сегмент появится. На самом деле, что происходит, когда мы создаем эти сегменты? То есть, как подключить туда виртуальную машину? Для этого есть два варианта.
Вариант номер раз.
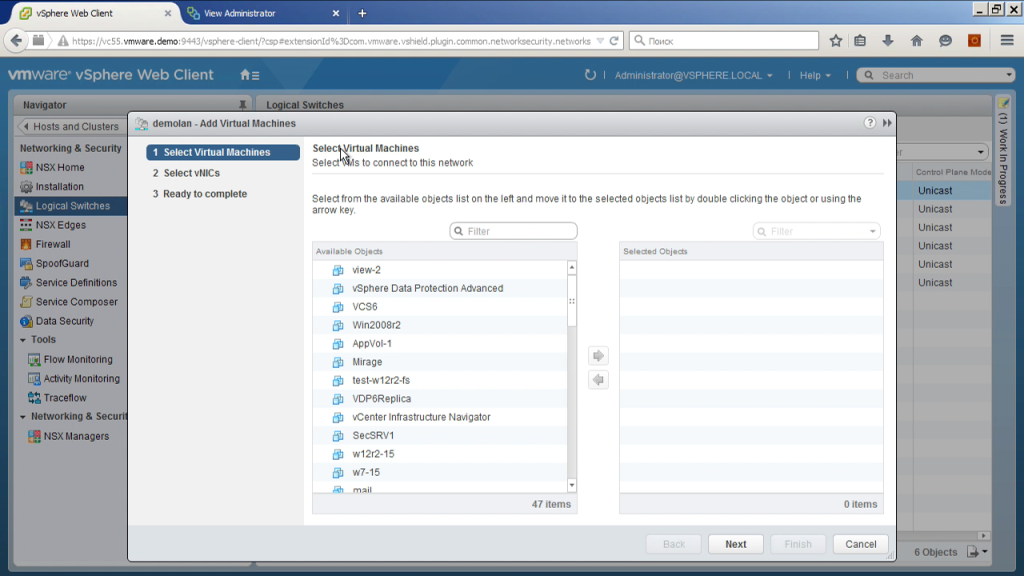
Мы прямо отсюда говорим, что подключить к физической сети виртуальную машину. И некоторые наши заказчики сказали: «О, это то, что хотят наши сетевики». Они идут в настройки сети, и говорит, вот у тебе вот, шнурок от машины, включая в порт логического коммутатора, да? И выбираем, здесь — машину, здесь, соответственно, интерфейс.
Либо второй вариант. На самом деле, при создании логического коммутатора NSX-менеджер обращается к V-центру сервера и создает порт-группу на распределенном коммутаторе. Поэтому на самом деле мы можем пойти просто в свойства виртуальной машины, выбрать нужную порт-группу, включить виртуальную машину туда. Поскольку имя генерируется программно, в нем будет включено имя этого логического коммутатора, номер VXLan-сегмента. То есть в принципе из обычного V-центр-клиента достаточно понятно, в камкой логический сегмент вы включите виртуальную машину.

Далее. Еще несколько машинок, которые были видны в самом начале, да? И вот, откуда они взялись. Некоторые функции NSX реализует напрямую на уровне модуля в ядре esxi-я. Это, например, маршрутизация между этими сегментами, это файервол при переходе между этими сегментами, либо даже внутри этого сегмента некоторые функции реализовываются при помощи дополнительных виртуальных машин. Так называемые EDGE gateways или дополнительные сервисы, когда они нужны. Что мы видим здесь? Мы видим, что в моей инфраструктуре их три, один из них называется NSX-dlr, dlr — это distributed logical router. Это служебная виртуальная машина, которая позволяет распределенному маршрутизатору в NSX-е работать, через нее не идет сетевой трафик, она не является дата-плэйном, но если у нас распределенный маршрутизатор участвует, например, в обмене маршрутами по протоколам динамической маршрутизации bgp, ospf, откуда-то эти все маршруты должны попадать, другие маршрутизаторы должны к кому-то обращаться и обмениваться этой информацией. Кто-то должен отвечать за статус «работает распределенный маршрутизатор или нет». То есть это фактически некий менеджмент-модуль распределенного маршрутизатора. При его настройке мы можем указать, что он должен работать надежно, соответственно, будет внедрено две виртуальных машины в HA-паре. Если одна почему-то стала недоступна, то на ее место будет работать вторая. Два других edge, которые имеют тип NSX edge, – это виртуальные машины, через которые роутится или натится трафик, который выходит во внешние сети, которые не управляются NSX-ом. В моем сценарии они используются для двух задач: NSX edge просто подключен ко внутренним сетям дата-центра MUK, то ест, например, мой V-центр – он как был на обычной стандартной порт-группе, он там и работает. Для того, чтобы я мог с какой-то виртуальной машиной на NSX logical свитче добежать до V-центра, мне нужен кто-то, кто их свяжет. Связывает их у меня вот эта виртуальная машина. У нее, действительно, один интерфейс подключен к логическому свитчу, другой интерфейс подключен к обычной порт-группе на standart свитче на esxi, который называется NSX Internet edge. Угадайте, чем отличается? Примерно то же самое, но порт-группа, к которой он подключит — та порт-группа, которая подключеня в DNZ-сеть, в которой работают честные белые интернет-адреса. То есть на нем сейчас, на одном из его интерфейсов, настроен белый ip-адрес и можно подключиться к этой демо-среде, используя уже NSX Networking. Соответственно дополнительные сервисы такие, как распределенная маршрутизация, мы настраиваем здесь в пункте фаервол, если же мы хотим делать фаерволинг, если мы хотим делать нат, если мы хотим делать log balancing либо, например, VPN, при внешнем подключении, для этого мы открываем свойства интернет edge.

Мы немножко закругляемся по времени, поэтому не покажу все, что хотел показать.
Соответственно, в свойствах edge мы можем управлять фаерволом, это фаервол, который будет применятся, когда трафик через эту виртуальную машину проходит, то есть это фактически некий наш периметр фаервол получается. Далее, на нем может быть dhсp-сервер, либо он может делать проброс как ip-helper, так как dhсp-helper. Он может делать NAT — то, что мне нужно здесь для edge, который смотрит одной стороной в честный Интернет, а другой во внутренние сети. На нем есть балансировщик нагрузки. Он может выступать в качестве точки для VPN тоннеля либо в качестве терминатора для клиентских подключений. Вот две закладки: VPN и VPN Plus. VPN — это сайт ту сайт, между edge и другим edge, между edge и нашим облаком, между edge и облаком провайдера, который использует наши технологии VCNS либо NSX. SSL VPN Plus — есть клиент для различных операционных систем, который можно поставить вам на свой ноутбук либо пользователя, они смогут к инфраструктуре подключиться к VPN.
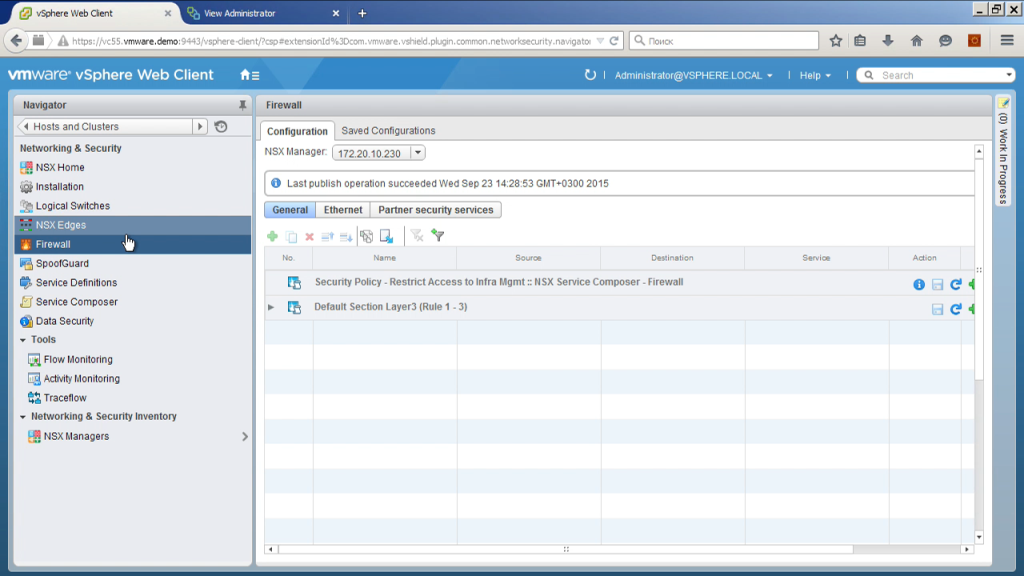
Ну и буквально несколько последних моментов. Распределенный фаервол, то есть фаерволлинг, применяется на каждом хосте, в качестве правил мы можем указывать здесь ip-адреса, номера пакетов, номера портов, имя виртуальных машин, включая маски, например. Сделать правило, что со всех машин, имя которых начинается с up, разрешить ходить по 14:33 на все машины, имя которых начинается с db. разрешить трафик с машинки, которая в папочке V-центра одной, будет ходить в папочке другой, подключиться к active directory, сказать, что если у нас машина входит в определенную группу ad, тогда этот трафик разрешить, если не входит, то трафик запретить. Ну и различные другие варианты.
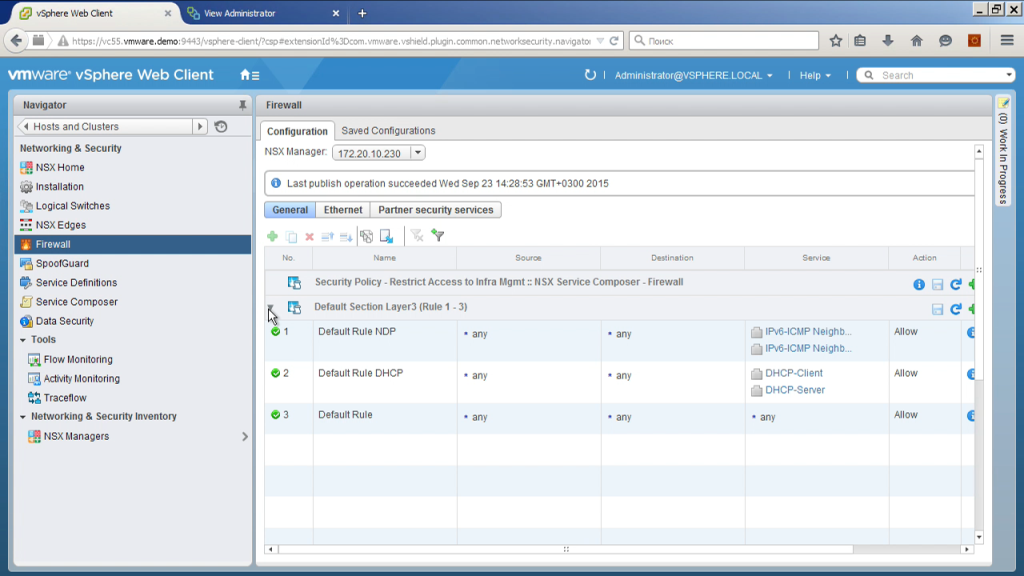
Плюс опять же, что делать с трафиком? Три действия: разрешить, запретить, отказать. Чем отличается запретить от отказать? И одно, и другое блокирует трафик. Но одно просто делает это тихонечко, а второе присылает обратно сообщение, что ваш трафик убили. И гораздо проще потом в диагностике.
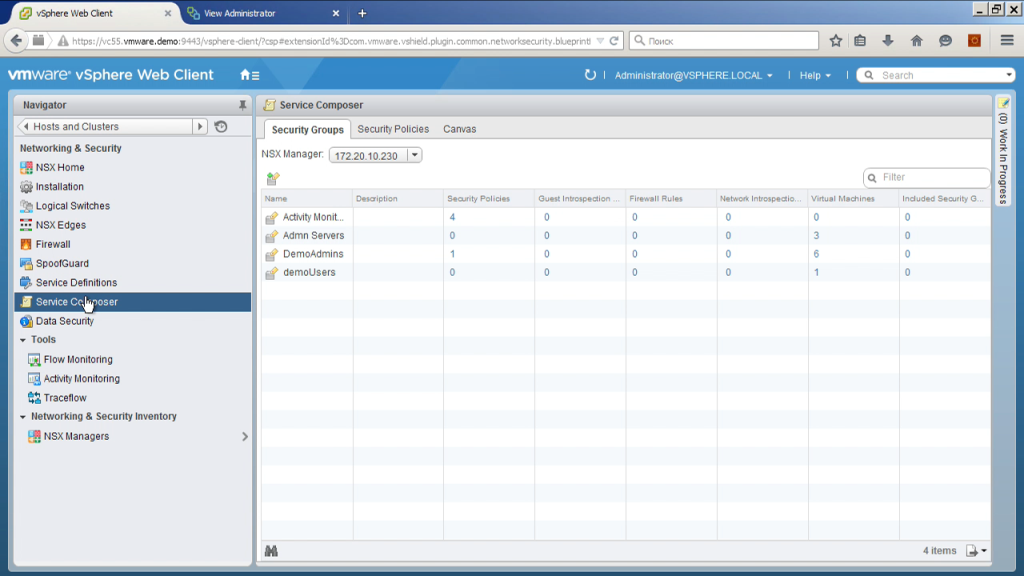
И буквально важное дополнение в конце. То есть такой компонент как service composer. Здесь мы можем интегрировать NSX какими-то дополнительными модулями, например, это внешний балансировщик нагрузки, это антивирус, это какая-либо IDS/IPS-система. То есть мы их можем зарегистрировать. Мы можем увидеть здесь, какие конфиги есть, можем описать те самые секьюрити-группы. Например, группа demoUsers — это группа, включающая себя в машины, на которых залогонился пользователь из группы demoUsers. Что мы видим сейчас? Что сейчас в эту группу попадает одна виртуальная машина. Где она? Вот.
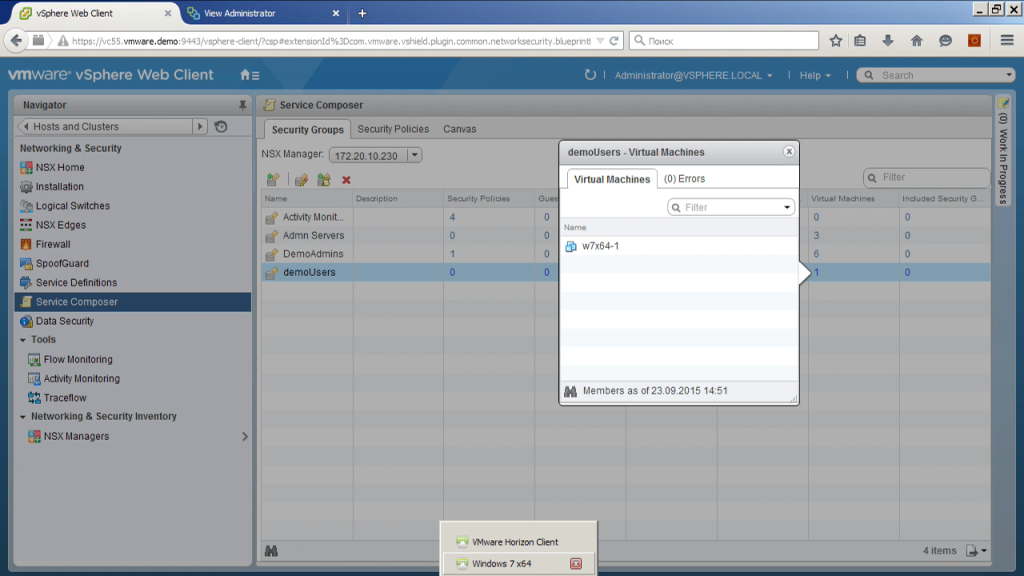
Виртуальный десктоп, пользователь туда подключен. Я могу сделать правило в фаерволе, в котором сказать, что разрешить пользователям одной группы доступ к одним файловым серверам, а пользователям другой группы разрешить доступ к другим файловым серверам. И даже если это два пользователя, которые заходят на один и тот же, например, VDI десктоп, но в разное время, фаервол динамически будет применять разные политики к разным пользователям. Таким образом можно гораздо более гибкую инфраструктуру построить. Нет необходимости выделять отдельные какие-то сетевые сегменты, отдельные машины для разных типов пользователей. То есть сетевые политики могут динамически перенастраиваться в зависимости от того, кто сейчас сетью пользуется.
Дистрибуция решений VMware в Украине, Беларуси, Грузии, странах СНГ
Учебные курсы VMware
МУК-Сервис — все виды ИТ ремонта: гарантийный, не гарантийный ремонт, продажа запасных частей, контрактное обслуживание