Эта публикация написана по материалам выступления AlexSerbul на осенней конференции BigData Conference.
Большие данные — тема модная и востребованная. Но многих по-прежнему отпугивает избыток теоретических рассуждений и некоторый недостаток практических рекомендаций. В этом посте я хочу отчасти заполнить этот пробел и рассказать об использовании параллельных алгоритмов для обработки больших данных на примере кластеризации товарного каталога из 10 млн позиций.
К сожалению, когда у вас много данных, то придётся «изобретать» классический алгоритм заново, чтобы он работал параллельно с помощью MapReduce. И это — большая проблема.
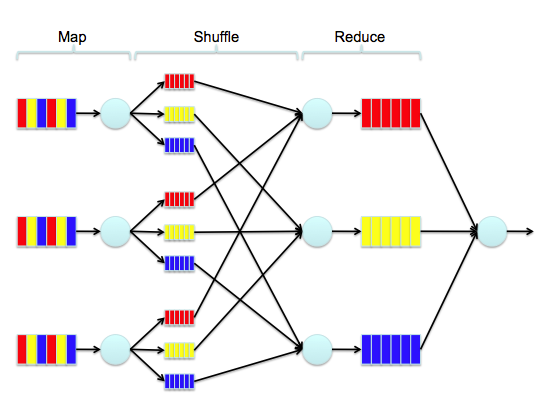
Какой есть выход? Ради экономии времени и денег можно конечно попытаться найти библиотеку, которая позволит реализовать алгоритм параллельной кластеризации. На Java-платформе что-то конечно есть: умирающий Apache Mahout и развивающийся Apache Spark MLlib. К сожалению, Mahout поддерживает мало алгоритмов под MapReduce — большинство из них последовательны.
Обещающий горы Spark MLlib пока тоже не богат на алгоритмы кластеризации. А с нашими объёмами дело еще хуже — вот что предлагается:
Когда у вас 10-20 миллионов сущностей для кластеризации, вышеупомянутые решения уже не помогут, нужен хардкор. Но обо всём по порядку.
Итак, нам нужно кластеризовать каталог из 10 млн товарных позиций. Зачем это нужно? Дело в том, что наши пользователи могут использовать в своих интернет-магазинах рекомендательную систему. А её работа основана на анализе агрегированного каталога товаров всех сайтов, работающих на нашей платформе. Допустим, в одном из магазинов покупателю порекомендовали выбрать топор, чтобы тёщу зарубить (да, это корпоративный блог, но без шуток про бигдату и математику говорить просто нельзя — все заснут). Система об этом узнает, проанализирует и в другом магазине порекомендует тому же покупателю баян, чтобы он играл и радовался. То есть первая задача, решаемая с помощью кластеризации, — передача интереса.
Вторая задача: обеспечить создание корректных логических связей товаров для увеличения сопутствующих продаж. Например, если пользователь купил фотоаппарат, то система порекомендует к нему аккумулятор и карту памяти. То есть нам нужно собрать в кластеры похожие товары, и в разных магазинах работать уже на уровне кластеров.
Как было отмечено выше, наша база товаров состоит из каталогов нескольких десятков тысяч интернет-магазинов, работающих на платформе «1С-Битрикс». Пользователи вводят туда текстовые описания разной длины, кто-то добавляет марки товаров, модели, производителей. Составить непротиворечивую точную единую систему сбора и классификации всех товаров из десятка тысяч магазинов было бы дорого, долго и тяжело. А мы хотели найти способ, как быстро склеить похожие товары между собой и заметно повысить качество коллаборативной фильтрации. Ведь если система хорошо знает покупателя, то неважно, какими конкретными товарами и их марками он интересуется, система всегда найдёт, что ему предложить.
В первую очередь необходимо было выбрать систему хранения, подходящую для работы с «большими» данными. Я немного повторюсь, но это полезно для закрепления материала. Для себя мы выделили четыре «лагеря» баз данных:
Занявшись вплотную вопросом кластеризации, мы выяснили, что готовых предложений на рынке не так уж много.
В итоге мы остановились на SparkMLlib, поскольку там, как показалось, есть надежные параллельные алгоритмы кластеризации.
Нам нужно было сначала придумать, каким образом объединять в кластроиды текстовые описания товаров (названия и краткие описания). Обработка текстов на естественных языках — это отдельная огромная область Computer Science, включающая в себя и машинное обучение и Information retrieval
и лингвистику и даже (тадам!) Deep Learning.
Когда данных для кластеризации десятки, сотни, тысячи — подойдет практически любой классический алгоритм, даже иерархической кластеризации. Проблема в том, что алгоритмическая сложность иерархической кластеризации равна примерно O(N3). То есть надо ждать «миллиарды лет», пока он отработает на нашем объёме данных, на огромном кластере. А ограничиваться обработкой лишь какой-то выборки было нельзя. Поэтому иерархическая кластеризация в лоб нам не подошла.
Потом мы обратились к «бородатому» алгоритму K-means:
Это очень простой, хорошо изученный и распространённый алгоритм. Однако и он работает на больших данных очень медленно: алгоритмическая сложность равна примерно О(nkdi). При n = 10 000 000 (количество товаров), k = 1 000 000 (ожидаемое количество кластеров), d = <1 000 000 (видов слов, размерность вектора), i = 100 (примерное количество итераций), О = 1021 операций. Для сравнения, возраст Земли составляет 1,4*1017 секунд.
Алгоритм C-means хоть и позволяет сделать нечёткую кластеризацию, но тоже работает на наших объёмах медленно, как и спектральная факторизация. По этой же причине нам не подошли DBSCAN и вероятностные модели.
Чтобы осуществить кластеризацию, мы решили на первом этапе превратить текст в векторы. Вектор — это некая точка в многомерном пространстве, скопления которых и будут искомыми кластерами.
Нам нужно было кластеризовать описания товаров, состоящие из 2-10 слов. Самое простое, классическое решение в лоб или в глаз — bag of words. Раз у нас есть каталог, то мы можем определить и словарь. В результате, у нас получился корпус размером примерно миллион слов. После стемминга их осталось около 500 тыс. Отбросили высокочастотные и низкочастотные слова. Конечно, можно было использовать tf/idf, но решили не усложнять.
Какие есть недостатки у этого подхода? Получившийся огромный вектор дорого потом обсчитывать, сравнивая его похожесть с другими. Ведь что представляет собой кластеризация? Это процесс поиска схожих между собой векторов. А когда они размером по 500 тыс., поиск занимает очень много времени, поэтому надо научиться их сжимать. Для этого можно использовать Kernel hack, хэшируя слова не в 500 тыс. атрибутов, а в 100 тыс. Хороший, рабочий инструмент, но могут возникать коллизии. Мы его не стали использовать.
И напоследок расскажу ещё об одной технологии, которую мы отбросили, но сейчас всерьёз подумываем начать её использовать. Это Word2Vec, методика статистической обработки текста путем сжатия размерности текстовых векторов двуслойной нейронной сетью, разработанная в Google. По сути, это развитие старых добрых вечных статистических N-gram моделей текста, только используется skip-gram вариация.
Первая задача, которая красиво решается с помощью Word2Vec: уменьшение размерности за счёт «матричной факторизации» (в кавычках специально, т.к. никаких матриц там нет, но эффект очень похож). То есть, получается, например, не 500 тыс. атрибутов, а всего лишь 100. Когда встречаются похожие «по контексту» слова, система считает их «синонимами» (с натяжкой конечно, кофе и чай могут объединиться). Получается, что точки этих похожих слов в многомерном пространстве начинают совпадать, то есть близкие по значению слова кластеризуются в общее облако. Скажем, «кофе» и «чай» будут близкими по значению словами, ведь они часто встречаются в контексте вместе. Благодаря библиотеке Word2Wec можно уменьшить размер векторов, а сами они получаются более осмысленными.
Этой теме много лет: Latent semantic indexing и её вариации через PCA/SVD изучили хорошо, да и решение в лоб через кластеризацию колонок или строк матрицы term2document, по сути, даст похожий результат — только делать это придётся очень долго.
Весьма вероятно, что мы всё же начнём применять Word2Vec. К слову, её использование также позволяет находить опечатки и играться с векторной алгеброй предложений и слов.
В итоге, после всех долгих поисков по научным публикациям, мы написали свой вариант k-Means — Clustering by Bootstrap Averaging для Spark.
По сути, это иерархический k-Means, делающий предварительный послойный сэмплинг данных. На обработку 10 млн товаров ушло достаточно разумное время, часы, хотя и потребовалось задействовать кучу серверов. Но результат не устроил, т.к. часть текстовых данных кластеризовать не удалось — носки клеились с самолетами. Метод работал, но очень грубо и неточно.
Оставалась надежда на старые, но подзабытые сейчас вероятностные методики поиска дубликатов или «почти дубликатов» — locality-sensitive hashing.
Вариант метода, описанный тут , требовал использования преобразованных из текста векторов одинакового размера, для дальнейшего «раскидывания» их по хэш-функциям. И мы взяли MinHash.
MinHash — технология сжатия векторов большой размерности в маленький вектор с сохранением из взаимной Jaccard-похожести. Как она работает? У нас есть некоторое количество векторов или наборов множеств, и мы определяем набор хэш-функций, через которые прогоняем каждый вектор/множество.

Определяем, например, 50 хэш-функций. Потом каждую хэш-функцию прогоняем по вектору/множеству, определяем минимальное значение хэш-функции, и получаем число, которое записываем в N-позицию нового сжатого вектора. Делаем это 50 раз.
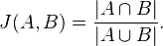
Pr[ hmin(A) = hmin(B) ] = J(A, B)
Таким образом мы решили задачу сжатия измерений и приведения векторов к единому количеству измерений.
Я совсем забыл рассказать, что мы отказались от векторизации текстов в лоб, т.к. названия и краткие описания товаров создавали чрезвычайно разряженные вектора, страдающие от «проклятья размерности».
Названия товаров обычно были примерно такого вида и размера:
«Штаны красные махровые в полоску»
«Красные полосатые штаны»
Эти две фразы разнятся по набору слов, по их количеству и местоположению. Кроме того, люди делают опечатки при наборе текста. Поэтому сравнивать слова нельзя даже после стемминга, ведь все тексты будут математически непохожи, хотя по смыслу они близки.
В подобной ситуации часто используется алгоритм шинглов (shingle, чешуйки, черепица). Мы представляем текст в виде шинглов, кусков.
{«штан», «таны», «аны », «ны к», «ы кра», «крас», …}
И при сравнении множества кусочков выясняется, что два текста разных текста могут вдруг обрести схожесть друг с другом. Мы долго экспериментировали с обработкой текста, и по нашему опыту, только так и можно сравнивать короткие текстовые описания в нашем товарном каталоге. Этот способ используется и для определения похожих статей, научных работ, с целью обнаружения плагиата.
Повторюсь ещё раз: мы отказались от сильно разреженных текстовых векторов, заменили каждый текст на множество (set) шинглов, а затем привели их к единому размеру с помощью MinHash.
В результате мы решили задачу векторизации каталога следующим образом. С помощью MinHash-сигнатуры получили векторы небольшого размера от 100 до 500 (размер выбирается одинаковым для всех векторов). Теперь их нужно сравнить каждый с каждым, чтобы сформировать кластеры. В лоб, как мы уже знаем, это очень долго. А благодаря алгоритму LSH (Locality-Sensitive Hashing) задача решилась в один проход.
Идея в том, что похожие объекты, тексты, векторы коллизируют в один набор хэш-фукций, в один bucket. И потом остаётся пройти по ним и собрать похожие элементы. После кластеризации получается миллион bucket’ов, каждый из которых и будет кластером.
Традиционно используют несколько bands — наборов хэш-функций. Но мы ещё больше упростили задачу — оставили всего один band. Допустим, берутся первые 40 элементов вектора и заносятся в хэш-таблицу. А дальше туда попадают элементы, которые имеют такой же кусок сначала. Вот и всё! Для начала — прекрасно. Если нужна большая точность, то можно работать с группой bands, но тогда на финальной части алгоритма придётся дольше собирать из них взаимно похожие объекты.
После первой же итерации мы получили неплохие результаты: у нас склеились почти все дубли и почти все похожие товары. Оценивали визуально. А для дальнейшего уменьшения количества микрокластеров мы предварительно убрали часто встречающиеся и редко встречающиеся слова.
Теперь у нас всего за два-три часа на 8 spot-серверах кластеризуется 10 млн. товаров в примерно один миллион кластеров. Фактически, в один проход, потому что band лишь один. Поэкспериментировав с настройками, мы получили достаточно адекватные кластеры: яхты, автомобили, колбаса и т.д., уже без глупостей вроде «топор + самолет». И теперь эта сжатая кластерная модель используется для улучшения точности работы системы персональных рекомендаций.
В коллаборативных алгоритмах мы стали работать уже не с конкретными товарами, а с кластерами. Появился новый товар, мы нашли кластер, положили его туда. И обратный процесс — рекомендуем кластер, затем выбираем из него самый популярный товар и возвращаем его пользователю. Использование кластерного каталога в разы улучшило точность рекомендаций (измеряем recall текущей модели и за месяц ранее). И это всего лишь за счёт сжатия данных (названий) и объединения их по смыслу. Поэтому хочу посоветовать вам — ищите простые решения ваших задач, связанных с большими данными. Не пытайтесь что-то усложнять. Я верю в то, что всегда можно найти простое, эффективное решение, которое за 10% усилий решит 90% задач! Всем удачи и успехов в работе с большими данными!
Большие данные — тема модная и востребованная. Но многих по-прежнему отпугивает избыток теоретических рассуждений и некоторый недостаток практических рекомендаций. В этом посте я хочу отчасти заполнить этот пробел и рассказать об использовании параллельных алгоритмов для обработки больших данных на примере кластеризации товарного каталога из 10 млн позиций.
К сожалению, когда у вас много данных, то придётся «изобретать» классический алгоритм заново, чтобы он работал параллельно с помощью MapReduce. И это — большая проблема.
Какой есть выход? Ради экономии времени и денег можно конечно попытаться найти библиотеку, которая позволит реализовать алгоритм параллельной кластеризации. На Java-платформе что-то конечно есть: умирающий Apache Mahout и развивающийся Apache Spark MLlib. К сожалению, Mahout поддерживает мало алгоритмов под MapReduce — большинство из них последовательны.
Обещающий горы Spark MLlib пока тоже не богат на алгоритмы кластеризации. А с нашими объёмами дело еще хуже — вот что предлагается:
- K-means
- Gaussian mixture
- Power iteration clustering (PIC)
- Latent Dirichlet allocation (LDA)
- Streaming k-means
Когда у вас 10-20 миллионов сущностей для кластеризации, вышеупомянутые решения уже не помогут, нужен хардкор. Но обо всём по порядку.
Итак, нам нужно кластеризовать каталог из 10 млн товарных позиций. Зачем это нужно? Дело в том, что наши пользователи могут использовать в своих интернет-магазинах рекомендательную систему. А её работа основана на анализе агрегированного каталога товаров всех сайтов, работающих на нашей платформе. Допустим, в одном из магазинов покупателю порекомендовали выбрать топор, чтобы тёщу зарубить (да, это корпоративный блог, но без шуток про бигдату и математику говорить просто нельзя — все заснут). Система об этом узнает, проанализирует и в другом магазине порекомендует тому же покупателю баян, чтобы он играл и радовался. То есть первая задача, решаемая с помощью кластеризации, — передача интереса.
Вторая задача: обеспечить создание корректных логических связей товаров для увеличения сопутствующих продаж. Например, если пользователь купил фотоаппарат, то система порекомендует к нему аккумулятор и карту памяти. То есть нам нужно собрать в кластеры похожие товары, и в разных магазинах работать уже на уровне кластеров.
Как было отмечено выше, наша база товаров состоит из каталогов нескольких десятков тысяч интернет-магазинов, работающих на платформе «1С-Битрикс». Пользователи вводят туда текстовые описания разной длины, кто-то добавляет марки товаров, модели, производителей. Составить непротиворечивую точную единую систему сбора и классификации всех товаров из десятка тысяч магазинов было бы дорого, долго и тяжело. А мы хотели найти способ, как быстро склеить похожие товары между собой и заметно повысить качество коллаборативной фильтрации. Ведь если система хорошо знает покупателя, то неважно, какими конкретными товарами и их марками он интересуется, система всегда найдёт, что ему предложить.
Выбор инструментария
В первую очередь необходимо было выбрать систему хранения, подходящую для работы с «большими» данными. Я немного повторюсь, но это полезно для закрепления материала. Для себя мы выделили четыре «лагеря» баз данных:
- SQL на MapReduce: Hive, Pig, Spark SQL. Загрузите в РСУБД один миллиард строк и выполните агрегацию данных — станет понятно, что этот класс систем хранения «не очень» подходит для данной задачи. Поэтому, интуитивно, можно попробовать использовать SQL через MapReduce (что и сделал когда-то Facebook). Очевидные минусы тут — скорость выполнения коротких запросов.
- SQL на MPP (massive parallel processing): Impala, Presto, Amazon RedShift, Vertica. Представители этого лагеря утверждают, что SQL через MapReduce – это тупиковый путь, поэтому нужно, фактически, на каждой ноде, где хранятся данные, поднимать драйвер, который будет быстро обращаться к этим данным. Но многие из перечисленных систем страдают от нестабильности.
- NoSQL: Cassandra, HBase, Amazon DynamoDB. Третий лагерь говорит: BigData — это NoSQL. Но мы же понимаем, что NoSQL — это, фактически, набор «memcached-серверов», объединённых в кольцевую структуру, которые могут быстро выполнить запрос типа «взять по ключу значение и вернуть ответ». Ещё могут вернуть отсортированный в оперативной памяти по ключу набор данных. Это почти всё — забудьте про JOINS.
- Классика: MySQL, MS SQL, Oracle и т.д. Монстры не сдаются и утверждают, что всё вышеперечисленное — фигня, горе от ума, и реляционные базы прекрасно работают с BigData. Кто-то предлагает фрактальные деревья (https://en.wikipedia.org/wiki/TokuDB), кто-то — кластеры. Монстры ведь тоже жить хотят.
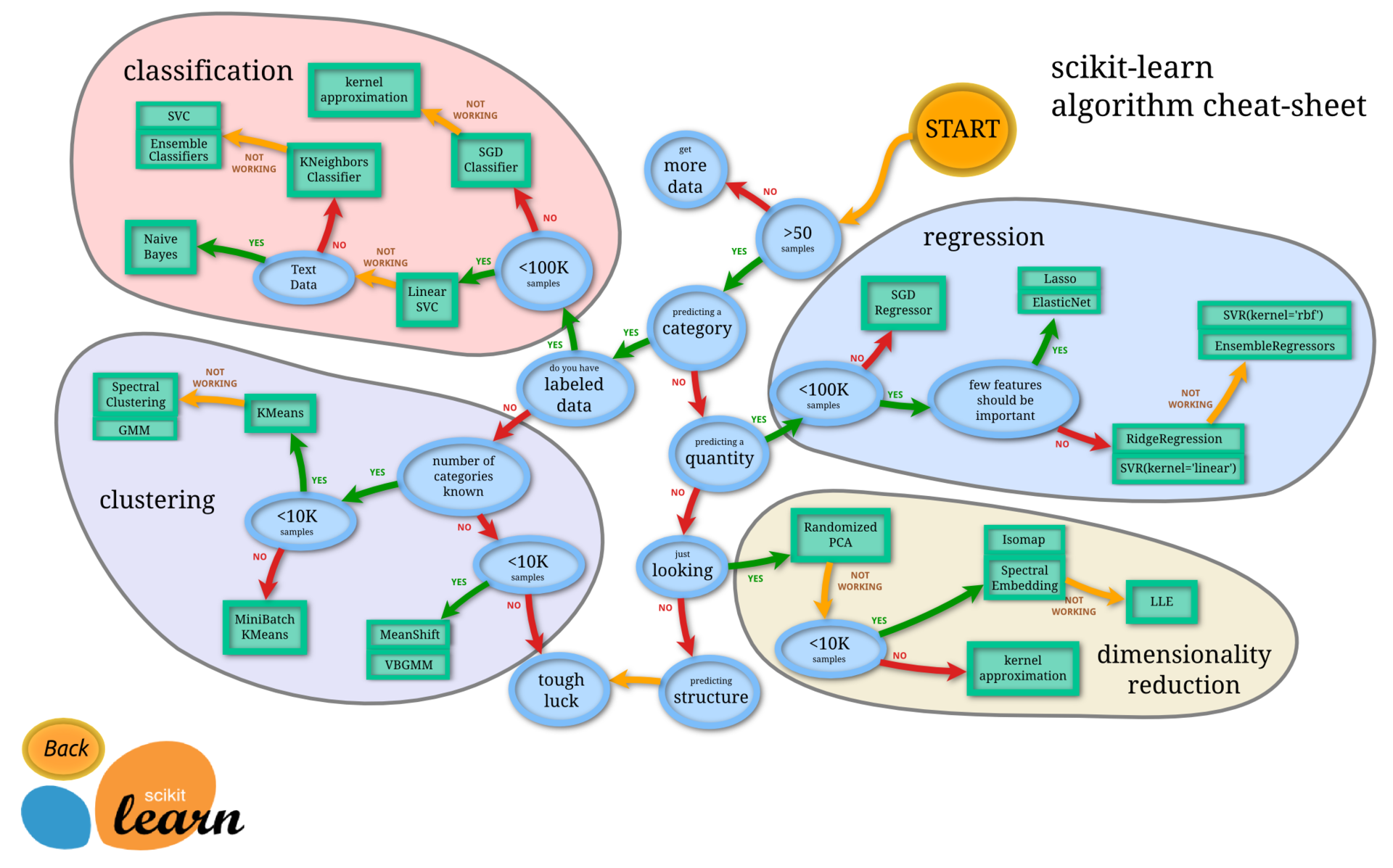
Занявшись вплотную вопросом кластеризации, мы выяснили, что готовых предложений на рынке не так уж много.
- Spark MLlib (Scala/Java/Python/R) — когда много данных.
- scikit-learn.org (Python) — когда мало данных.
- R — вызывает противоречивые чувства по причине жуткой кривизны реализации (доверь программирование математикам и статистам), но готовых решений много, а недавняя интеграция со Spark очень радует.
В итоге мы остановились на SparkMLlib, поскольку там, как показалось, есть надежные параллельные алгоритмы кластеризации.
Поиск алгоритма кластеризации
Нам нужно было сначала придумать, каким образом объединять в кластроиды текстовые описания товаров (названия и краткие описания). Обработка текстов на естественных языках — это отдельная огромная область Computer Science, включающая в себя и машинное обучение и Information retrieval
и лингвистику и даже (тадам!) Deep Learning.
Когда данных для кластеризации десятки, сотни, тысячи — подойдет практически любой классический алгоритм, даже иерархической кластеризации. Проблема в том, что алгоритмическая сложность иерархической кластеризации равна примерно O(N3). То есть надо ждать «миллиарды лет», пока он отработает на нашем объёме данных, на огромном кластере. А ограничиваться обработкой лишь какой-то выборки было нельзя. Поэтому иерархическая кластеризация в лоб нам не подошла.
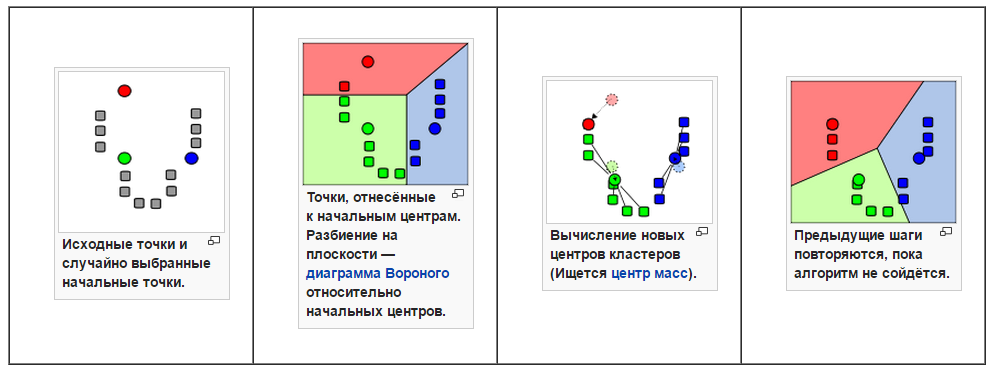
Потом мы обратились к «бородатому» алгоритму K-means:
Это очень простой, хорошо изученный и распространённый алгоритм. Однако и он работает на больших данных очень медленно: алгоритмическая сложность равна примерно О(nkdi). При n = 10 000 000 (количество товаров), k = 1 000 000 (ожидаемое количество кластеров), d = <1 000 000 (видов слов, размерность вектора), i = 100 (примерное количество итераций), О = 1021 операций. Для сравнения, возраст Земли составляет 1,4*1017 секунд.
Алгоритм C-means хоть и позволяет сделать нечёткую кластеризацию, но тоже работает на наших объёмах медленно, как и спектральная факторизация. По этой же причине нам не подошли DBSCAN и вероятностные модели.
Чтобы осуществить кластеризацию, мы решили на первом этапе превратить текст в векторы. Вектор — это некая точка в многомерном пространстве, скопления которых и будут искомыми кластерами.
Нам нужно было кластеризовать описания товаров, состоящие из 2-10 слов. Самое простое, классическое решение в лоб или в глаз — bag of words. Раз у нас есть каталог, то мы можем определить и словарь. В результате, у нас получился корпус размером примерно миллион слов. После стемминга их осталось около 500 тыс. Отбросили высокочастотные и низкочастотные слова. Конечно, можно было использовать tf/idf, но решили не усложнять.
Какие есть недостатки у этого подхода? Получившийся огромный вектор дорого потом обсчитывать, сравнивая его похожесть с другими. Ведь что представляет собой кластеризация? Это процесс поиска схожих между собой векторов. А когда они размером по 500 тыс., поиск занимает очень много времени, поэтому надо научиться их сжимать. Для этого можно использовать Kernel hack, хэшируя слова не в 500 тыс. атрибутов, а в 100 тыс. Хороший, рабочий инструмент, но могут возникать коллизии. Мы его не стали использовать.
И напоследок расскажу ещё об одной технологии, которую мы отбросили, но сейчас всерьёз подумываем начать её использовать. Это Word2Vec, методика статистической обработки текста путем сжатия размерности текстовых векторов двуслойной нейронной сетью, разработанная в Google. По сути, это развитие старых добрых вечных статистических N-gram моделей текста, только используется skip-gram вариация.
Первая задача, которая красиво решается с помощью Word2Vec: уменьшение размерности за счёт «матричной факторизации» (в кавычках специально, т.к. никаких матриц там нет, но эффект очень похож). То есть, получается, например, не 500 тыс. атрибутов, а всего лишь 100. Когда встречаются похожие «по контексту» слова, система считает их «синонимами» (с натяжкой конечно, кофе и чай могут объединиться). Получается, что точки этих похожих слов в многомерном пространстве начинают совпадать, то есть близкие по значению слова кластеризуются в общее облако. Скажем, «кофе» и «чай» будут близкими по значению словами, ведь они часто встречаются в контексте вместе. Благодаря библиотеке Word2Wec можно уменьшить размер векторов, а сами они получаются более осмысленными.
Этой теме много лет: Latent semantic indexing и её вариации через PCA/SVD изучили хорошо, да и решение в лоб через кластеризацию колонок или строк матрицы term2document, по сути, даст похожий результат — только делать это придётся очень долго.
Весьма вероятно, что мы всё же начнём применять Word2Vec. К слову, её использование также позволяет находить опечатки и играться с векторной алгеброй предложений и слов.
«Я построю свой лунапарк!..»
В итоге, после всех долгих поисков по научным публикациям, мы написали свой вариант k-Means — Clustering by Bootstrap Averaging для Spark.
По сути, это иерархический k-Means, делающий предварительный послойный сэмплинг данных. На обработку 10 млн товаров ушло достаточно разумное время, часы, хотя и потребовалось задействовать кучу серверов. Но результат не устроил, т.к. часть текстовых данных кластеризовать не удалось — носки клеились с самолетами. Метод работал, но очень грубо и неточно.
Оставалась надежда на старые, но подзабытые сейчас вероятностные методики поиска дубликатов или «почти дубликатов» — locality-sensitive hashing.
Вариант метода, описанный тут , требовал использования преобразованных из текста векторов одинакового размера, для дальнейшего «раскидывания» их по хэш-функциям. И мы взяли MinHash.
MinHash — технология сжатия векторов большой размерности в маленький вектор с сохранением из взаимной Jaccard-похожести. Как она работает? У нас есть некоторое количество векторов или наборов множеств, и мы определяем набор хэш-функций, через которые прогоняем каждый вектор/множество.
Определяем, например, 50 хэш-функций. Потом каждую хэш-функцию прогоняем по вектору/множеству, определяем минимальное значение хэш-функции, и получаем число, которое записываем в N-позицию нового сжатого вектора. Делаем это 50 раз.
Pr[ hmin(A) = hmin(B) ] = J(A, B)
Таким образом мы решили задачу сжатия измерений и приведения векторов к единому количеству измерений.
Text shingling
Я совсем забыл рассказать, что мы отказались от векторизации текстов в лоб, т.к. названия и краткие описания товаров создавали чрезвычайно разряженные вектора, страдающие от «проклятья размерности».
Названия товаров обычно были примерно такого вида и размера:
«Штаны красные махровые в полоску»
«Красные полосатые штаны»
Эти две фразы разнятся по набору слов, по их количеству и местоположению. Кроме того, люди делают опечатки при наборе текста. Поэтому сравнивать слова нельзя даже после стемминга, ведь все тексты будут математически непохожи, хотя по смыслу они близки.
В подобной ситуации часто используется алгоритм шинглов (shingle, чешуйки, черепица). Мы представляем текст в виде шинглов, кусков.
{«штан», «таны», «аны », «ны к», «ы кра», «крас», …}
И при сравнении множества кусочков выясняется, что два текста разных текста могут вдруг обрести схожесть друг с другом. Мы долго экспериментировали с обработкой текста, и по нашему опыту, только так и можно сравнивать короткие текстовые описания в нашем товарном каталоге. Этот способ используется и для определения похожих статей, научных работ, с целью обнаружения плагиата.
Повторюсь ещё раз: мы отказались от сильно разреженных текстовых векторов, заменили каждый текст на множество (set) шинглов, а затем привели их к единому размеру с помощью MinHash.
Векторизация
В результате мы решили задачу векторизации каталога следующим образом. С помощью MinHash-сигнатуры получили векторы небольшого размера от 100 до 500 (размер выбирается одинаковым для всех векторов). Теперь их нужно сравнить каждый с каждым, чтобы сформировать кластеры. В лоб, как мы уже знаем, это очень долго. А благодаря алгоритму LSH (Locality-Sensitive Hashing) задача решилась в один проход.
Идея в том, что похожие объекты, тексты, векторы коллизируют в один набор хэш-фукций, в один bucket. И потом остаётся пройти по ним и собрать похожие элементы. После кластеризации получается миллион bucket’ов, каждый из которых и будет кластером.
Кластеризация
Традиционно используют несколько bands — наборов хэш-функций. Но мы ещё больше упростили задачу — оставили всего один band. Допустим, берутся первые 40 элементов вектора и заносятся в хэш-таблицу. А дальше туда попадают элементы, которые имеют такой же кусок сначала. Вот и всё! Для начала — прекрасно. Если нужна большая точность, то можно работать с группой bands, но тогда на финальной части алгоритма придётся дольше собирать из них взаимно похожие объекты.
После первой же итерации мы получили неплохие результаты: у нас склеились почти все дубли и почти все похожие товары. Оценивали визуально. А для дальнейшего уменьшения количества микрокластеров мы предварительно убрали часто встречающиеся и редко встречающиеся слова.
Теперь у нас всего за два-три часа на 8 spot-серверах кластеризуется 10 млн. товаров в примерно один миллион кластеров. Фактически, в один проход, потому что band лишь один. Поэкспериментировав с настройками, мы получили достаточно адекватные кластеры: яхты, автомобили, колбаса и т.д., уже без глупостей вроде «топор + самолет». И теперь эта сжатая кластерная модель используется для улучшения точности работы системы персональных рекомендаций.
Итоги
В коллаборативных алгоритмах мы стали работать уже не с конкретными товарами, а с кластерами. Появился новый товар, мы нашли кластер, положили его туда. И обратный процесс — рекомендуем кластер, затем выбираем из него самый популярный товар и возвращаем его пользователю. Использование кластерного каталога в разы улучшило точность рекомендаций (измеряем recall текущей модели и за месяц ранее). И это всего лишь за счёт сжатия данных (названий) и объединения их по смыслу. Поэтому хочу посоветовать вам — ищите простые решения ваших задач, связанных с большими данными. Не пытайтесь что-то усложнять. Я верю в то, что всегда можно найти простое, эффективное решение, которое за 10% усилий решит 90% задач! Всем удачи и успехов в работе с большими данными!