SPARK для «малышей» 17.04.2024 13:57 vladislav_shevchenko 0 Hadoop Блог компании Альфа-Банк Data Engineering
Оптимизация запроса и запрос оптимизации +2 25.11.2023 20:11 Falcon_eye 11 Администрирование баз данных SQL Hadoop Data Engineering
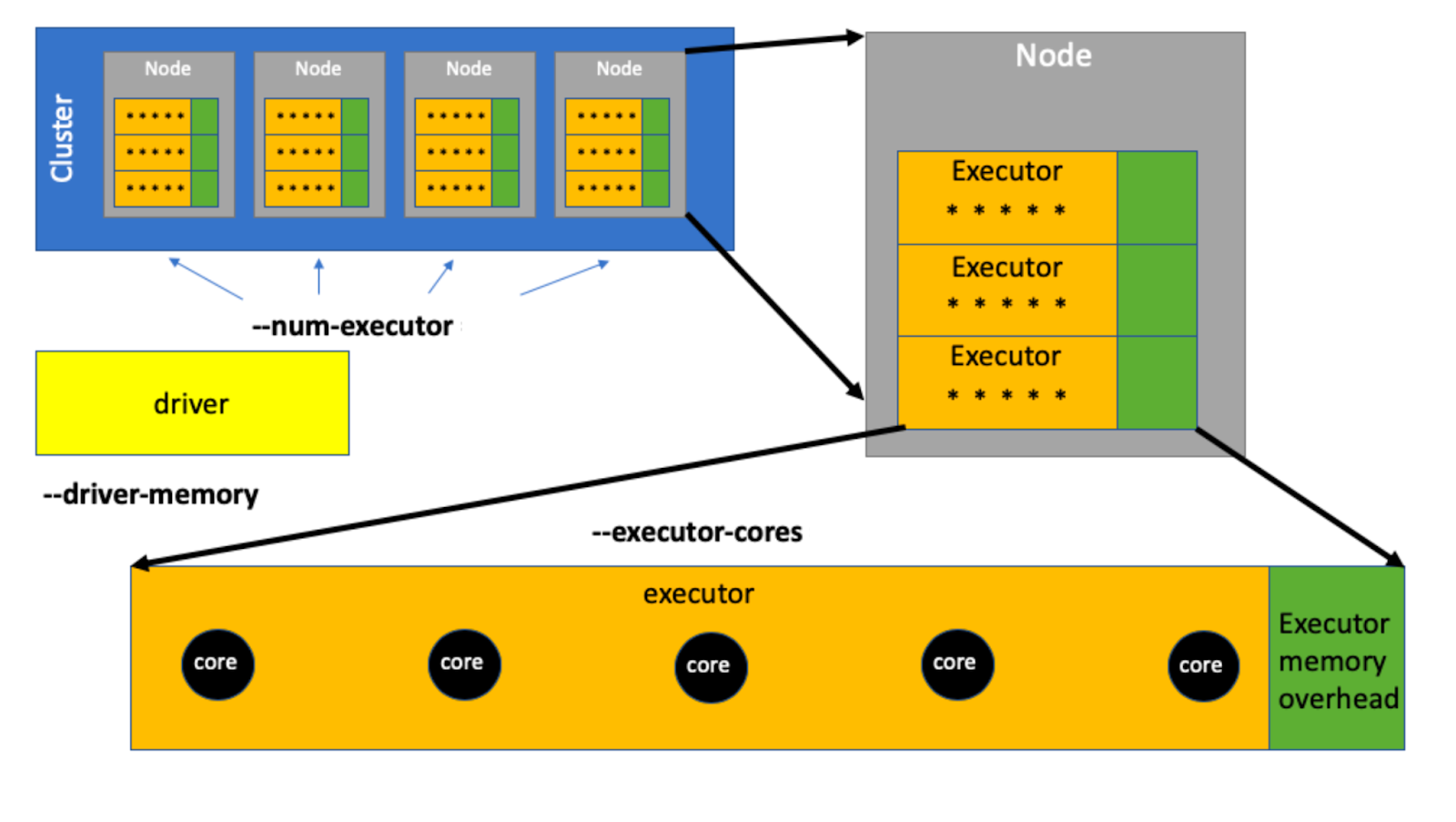
Подбираем параметры сессии в Apache Spark, чтобы не стоять в очереди +12 07.11.2023 10:53 vladislav_shevchenko 7 Big Data Apache DevOps Блог компании Альфа-Банк Data Engineering
Hadoop в любой непонятной ситуации. Как выжить кластеру в большой ML команде -1 29.09.2023 14:51 sle_mary 0 Python Big Data Машинное обучение Hadoop Блог компании МегаФон
Data Engineering: концепции, процессы и инструменты 24.07.2023 09:57 kucev 0 Анализ и проектирование систем Хранение данных Data Mining Машинное обучение Data Engineering
PySpark для аналитика. Как выгружать данные с помощью toPandas и его альтернатив +3 09.06.2023 07:19 aledovskiy 12 Python Анализ и проектирование систем Data Mining Big Data Аналитика мобильных приложений Блог компании AvitoTech
PySpark для аналитика. Как правильно просить ресурсы и как понять, сколько нужно брать +10 04.05.2023 10:36 aledovskiy 14 Python Data Mining Big Data Блог компании AvitoTech
Проблемы приземления данных из Kafka и их решения на Apache Flink +8 27.04.2023 09:17 olegbunin 0 Высокая производительность Big Data Apache Блог компании Конференции Олега Бунина (Онтико)
Как мы распараллелили CatBoost на Spark +5 16.02.2023 14:44 val_vor 0 Big Data Apache Kubernetes Data Engineering Блог компании X5 Tech
Pyspark. Анализ больших данных, когда Pandas не достаточно +4 29.12.2022 15:27 rufous86 3 Python Big Data Hadoop
Практический опыт проектирования систем графового анализа +8 15.12.2022 18:25 EvgenyVilkov 6 Анализ и проектирование систем Big Data Хранилища данных Блог компании GlowByte
Как найти «слона» в песочнице на Hadoop: решаем проблему с ограничением объёма выделенной памяти +6 05.12.2022 16:40 Sber 0 Администрирование баз данных Big Data Hadoop Блог компании Сбер