Часть 1 тут.
Данный цикл статей нацелен на то, чтобы дать интуитивное понимание того, как работает глубокое обучение, какие есть задачи, архитектуры сетей, почему одно лучше другого. Здесь будет мало конкретных вещей в духе «как это реализовать». Если вдаваться в каждую деталь, то материал станет слишком сложным для большинства аудитории. Про то, как работает граф вычислений или про то, как работает обратное распространение через сверточные слои уже написано. И, главное, написано куда лучше, чем я бы объяснил.
В предыдущей статье мы обсуждали FCNN — что это и какие есть проблемы. Решение тех проблем лежит в архитектуре сверточных нейронных сетей.
Сверточная нейронная сеть. Выглядит примерно так (архитектура vgg-16):
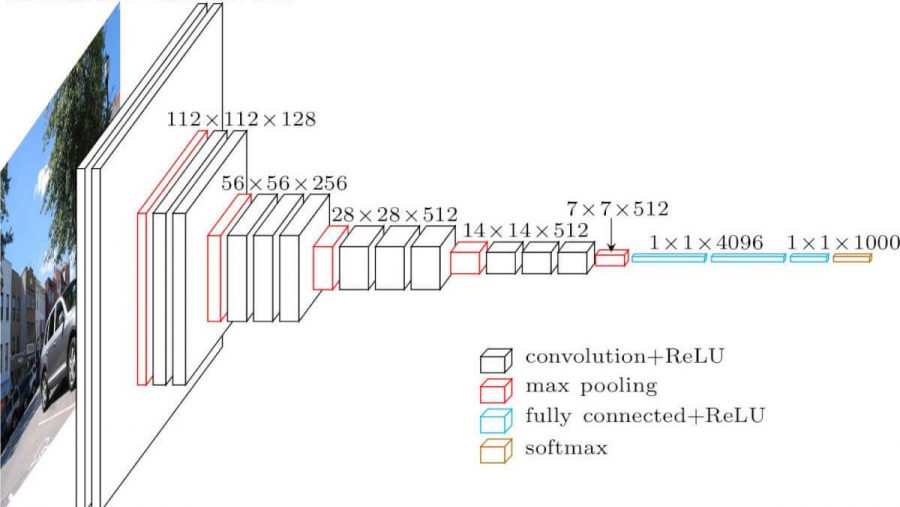
Какие отличия от полносвязной сети? В скрытых слоях теперь происходит операция свертки.
Так выглядит свертка (same convolution):

Просто берем изображение(пока что — одноканальное), берем ядро свертки(матрицу), состоящее из наших обучаемых параметров, «накладываем» ядро(обычно оно 3х3) на изображение, производим поэлементное умножение всех значений пикселей изображения, попавших на ядро. Затем все это суммируется(еще нужно добавить параметр bias — смещение), и мы получаем какое-то число. Это число является элементом выходного слоя. Двигаем это ядро по нашему изображению с каким-то шагом(stride) и получаем очередные элементы. Из таких элементов строится новая матрица, на нее же применяется(после применения к ней функции активации) следующее ядро свертки. В случае, когда входное изображение трехканальное, ядро свертки тоже трехканальное — фильтр.
Но здесь не все так просто. Те матрицы, которые мы получаем после свертки, называются картами признаков (feature maps), потому что хранят в себе некие признаки предыдущих матриц, но уже в неком другом виде. На практике применяют сразу несколько фильтров для свертки. Это делается для того, чтобы «вынести» как можно больше фич на следующий слой свертки. С каждым слоем свертки наши признаки, которые были во входном изображении, представляются все более в абстрактных формах.
Еще пара замечаний:
Выглядит это так:
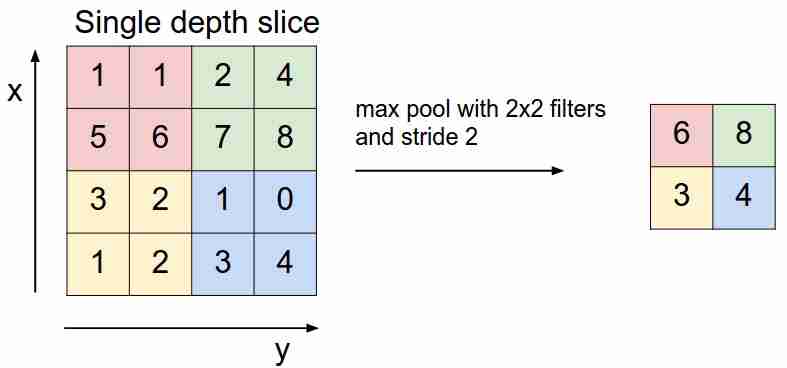
Мы «скользим» по нашей feature map фильтром и выбираем только самые важные(в плане входящего сигнала, как некоторого значения) признаки, уменьшая размерность feature map. Есть еще average(weighted) pooling, когда мы усредняем значения, попавшие в фильтр, но на практике более применим именно max pooling.
Мы подаем на вход сети X, доходим до выхода, вычисляем значение функции потерь, выполняем алгоритм обратного распространения ошибки — именно так учатся современные нейронные сети(пока речь только об обучении с учителем — supervised learning).
В зависимости от задач, которые решают нейронные сети, используются разные функции потерь:
Другие задачи мы пока не рассматриваем — об этом будет в следующих статьях. А почему именно такие функции для таких задач? Тут нужно въезжать в maximum likelihood estimation и математику. Кому интересно — я писал об этом тут.
Также хочу обратить внимание на две вещи, используемые в архитектурах нейронных сетей, в том числе и сверточных, — это dropout(можно почитать тут) и batch normalization. Настоятельно рекомендую ознакомиться.
В следующей статье разберем архитектуры CNN, поймем почему одна лучше другой.
В этой статье вы узнаете
- Что такое CNN и как это работает
- Что такое карта признаков
- Что такое max pooling
- Функции потерь для различных задач глубокого обучения
Небольшое вступление
Данный цикл статей нацелен на то, чтобы дать интуитивное понимание того, как работает глубокое обучение, какие есть задачи, архитектуры сетей, почему одно лучше другого. Здесь будет мало конкретных вещей в духе «как это реализовать». Если вдаваться в каждую деталь, то материал станет слишком сложным для большинства аудитории. Про то, как работает граф вычислений или про то, как работает обратное распространение через сверточные слои уже написано. И, главное, написано куда лучше, чем я бы объяснил.
В предыдущей статье мы обсуждали FCNN — что это и какие есть проблемы. Решение тех проблем лежит в архитектуре сверточных нейронных сетей.
Convolutional Neural Networks (CNN)
Сверточная нейронная сеть. Выглядит примерно так (архитектура vgg-16):
Какие отличия от полносвязной сети? В скрытых слоях теперь происходит операция свертки.
Так выглядит свертка (same convolution):
Просто берем изображение(пока что — одноканальное), берем ядро свертки(матрицу), состоящее из наших обучаемых параметров, «накладываем» ядро(обычно оно 3х3) на изображение, производим поэлементное умножение всех значений пикселей изображения, попавших на ядро. Затем все это суммируется(еще нужно добавить параметр bias — смещение), и мы получаем какое-то число. Это число является элементом выходного слоя. Двигаем это ядро по нашему изображению с каким-то шагом(stride) и получаем очередные элементы. Из таких элементов строится новая матрица, на нее же применяется(после применения к ней функции активации) следующее ядро свертки. В случае, когда входное изображение трехканальное, ядро свертки тоже трехканальное — фильтр.
Но здесь не все так просто. Те матрицы, которые мы получаем после свертки, называются картами признаков (feature maps), потому что хранят в себе некие признаки предыдущих матриц, но уже в неком другом виде. На практике применяют сразу несколько фильтров для свертки. Это делается для того, чтобы «вынести» как можно больше фич на следующий слой свертки. С каждым слоем свертки наши признаки, которые были во входном изображении, представляются все более в абстрактных формах.
Еще пара замечаний:
- После свертки наш feature map становится меньше (по ширине и высоте). Иногда, чтобы слабее уменьшать ширину и высоту, или вовсе ее не уменьшать(same convolution), используют метод zero padding — заполнение нулями «по контуру» входной feature map.
- После самого последнего сверточного слоя в задачах классификации и регрессии используют несколько fully-connected слоев.
Почему это лучше, чем FCNN
- У нас теперь может быть меньше обучаемых параметров между слоями
- Теперь мы, извлекая признаки из изображения, учитываем не только какой-то отдельный пиксель, но и пиксели возле него(выявление неких паттернов на изображении)
Max pooling
Выглядит это так:
Мы «скользим» по нашей feature map фильтром и выбираем только самые важные(в плане входящего сигнала, как некоторого значения) признаки, уменьшая размерность feature map. Есть еще average(weighted) pooling, когда мы усредняем значения, попавшие в фильтр, но на практике более применим именно max pooling.
- У этого слоя нет обучаемых параметров
Функции потерь
Мы подаем на вход сети X, доходим до выхода, вычисляем значение функции потерь, выполняем алгоритм обратного распространения ошибки — именно так учатся современные нейронные сети(пока речь только об обучении с учителем — supervised learning).
В зависимости от задач, которые решают нейронные сети, используются разные функции потерь:
- Задача регрессии. В основном используют функцию средней квадратичной ошибки (mean squared error — MSE).
- Задача классификации. В основном используют кросс-энтропию (cross-entropy loss).
Другие задачи мы пока не рассматриваем — об этом будет в следующих статьях. А почему именно такие функции для таких задач? Тут нужно въезжать в maximum likelihood estimation и математику. Кому интересно — я писал об этом тут.
Заключение
Также хочу обратить внимание на две вещи, используемые в архитектурах нейронных сетей, в том числе и сверточных, — это dropout(можно почитать тут) и batch normalization. Настоятельно рекомендую ознакомиться.
В следующей статье разберем архитектуры CNN, поймем почему одна лучше другой.