Вернулся с дататона DSW 2015, где мы заняли второе место и, пока ничего не забылось, хотел бы поделиться впечатлениями.
Для нас подготовили три задачи. Все достаточно интересные и сложные. Чтобы получить нормальное качество для каждой из них, я думаю, нужно потратить не одну неделю. Нам предложили уложиться в сутки.
Первая задача была про предсказание зарплат по описанию вакансий. На HH часто вместо суммы, на которую может рассчитывать соискатель, пишут «з/п не указана». Предлагалось как-то исправить это обстоятельно и заполнить пробелы примерными значениями. Нам предоставили ~700 000 записей вида
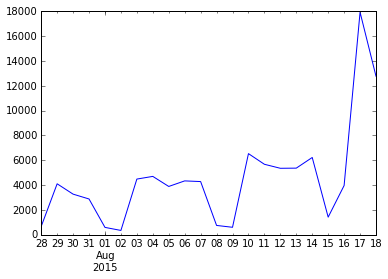
И тестовый набор с пустыми полями «salary.to» и «salary.from», которые нужно было заполнить. Вообще данные очень интересные. Думаю, с их помощью можно много чего понять про рынок труда в России. Мы, для начала, посмотрели на какие-то базовые вещи. Данные нам дали свежие. За несколько дней до выгрузки есть скачок числа новых вакансий. Ребята объясняют это тем, что рекрутеры часто в начале недели перезаливают объявления, чтобы их увидело побольше людей:
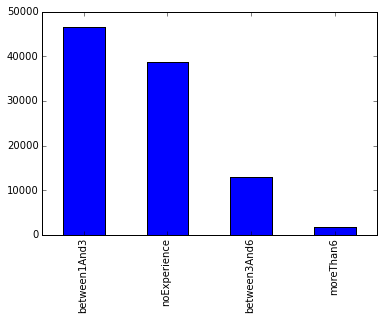
На удивление часто требуются люди без опыта:
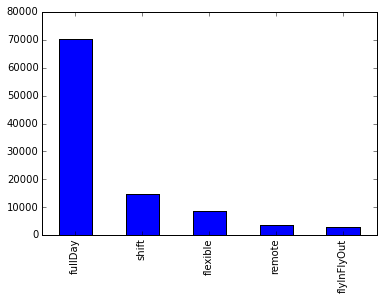
Обычно нужны люди на полный день:
Пока я с интересом изучал данные и периодически делился наблюдениями, Диман, не особо вникая с содержание, запихнул всё в Vowpal Wabbit и получил модель, которая сразу заняла первой место и пребывала там в гордом одиночестве почти до самого конца хакатона. В чём там заключалась суть я не понял, поэтому слово Диме:
И вот ещё его презентация на всякие случай.
Я поудивлялся тому как нынче молодёжь решает аналитические задачи и перешёл ко второму датасету. Там предлагалось сделать систему для поиска похожих запросов:

В принципе, ребята из HH эту систему уже сделали, и даже год назад написали об этом подробную статью, но данных, которые не подпадают под NDA не так много, поэтому пришлось конструировать велосипед. Впрочем, велосипед, у меня получился вполне зачётный. Данных нам отгрузили щедро. Было два файлика. В первом для каждого пользователя были указаны его запросы (~100 000 000 строк):
Во втором, для каждого запроса было указано по какому результату каждый пользователь кликал (~60 000 000 строк):
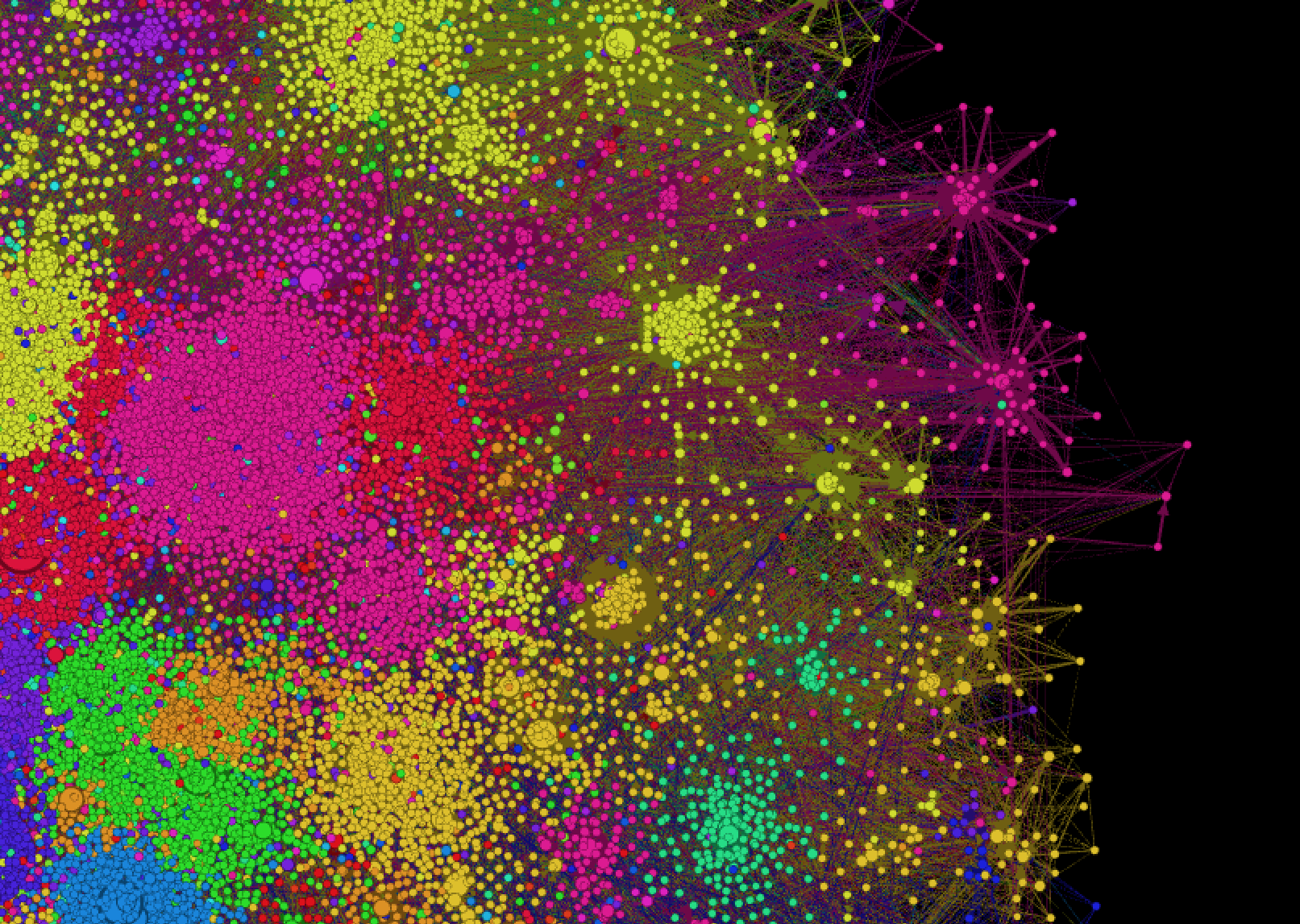
Я, естественно, не мог не заметить сходство этой задачи с задачей про поиск похожих групп ВК, про которую недавно писал. За несколько часов был построен роскошный граф вида:
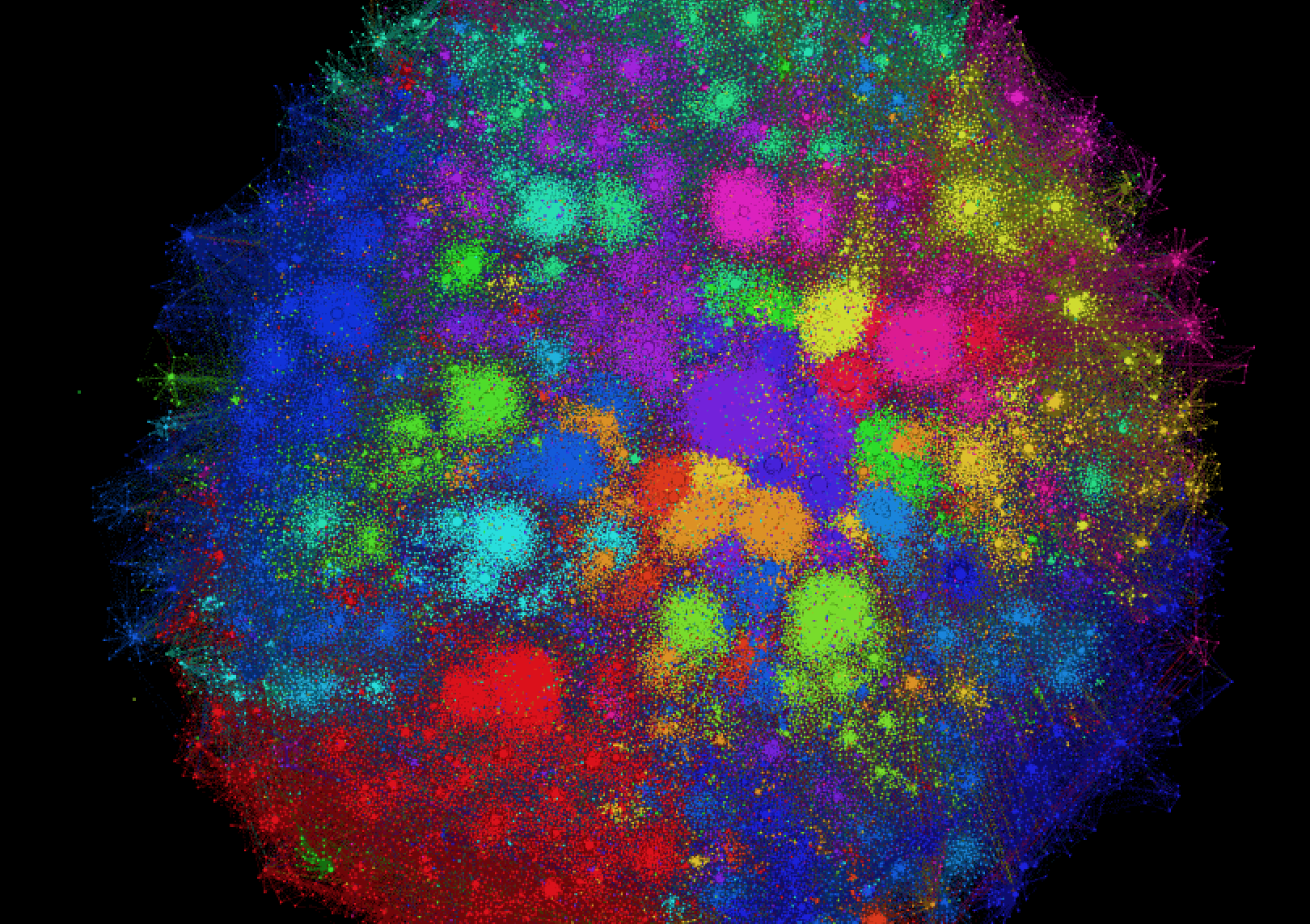
Каждой вершине соответствовал запрос. Похожие запросы объединялись в кластеры. Вот, например, запросы про фармацевтов:

Про таможенников:

Метрика для этой задачи была интересной. В конце хакатона нужно было выйти на сцену и в реальном времени понаходить рекомендации для запросов, которые придумает жюри. В нашем случае это выглядело так:

С первой и второй задачами у нас всё получилось, достаточно неплохо, чего не скажешь о последней третьей задаче. Там нужно было сделать систему рекомендаций товаров для Озона. Данные выглядели примерно так:
Подобных записей нам отгрузили ~10 000 000 штук, что дофига. Там была ещё куча всяких файликов, но я на них даже не смотрел. Нужно было для данного товара найти хорошие оригинальные рекомендации. Кроме того, что задача сама по себе, мягко говоря, не простая и данных очень много у нас возникла ещё одна проблема. Это Spark. Примерно 12 часов ушло на то, чтобы загрузить туда данные и запустить простейшие операции. Хакатон однозначно не лучше место для первого знакомства с подобными технологиями. В итоге за два часа до дедлайна мы приняли волевое решение забить на Spark и запилить хотя бы какое-то решение локально. Мой Макбучек, как всегда не подвёл, место на диске подходило к концу, но базовое решение у нас появилось. Мы делали очень примитивную вещь. Все слова из описания товара складывали в set. Потом шли по списку товаров и считали пересечение. Товары с большим пересечением попадали в рекомендации. В принципе, такой метод работал. Для
Мы рекомендовали
Правда, чтобы сделать рекомендации для одного товара, нам нужна была примерно минута. А тестовых кейсов было ~60 000. И до дедлайна оставалось 15 минут. Короче, третью задачу мы подслили.
Первое место заняли чуваки, которые, более или менее решили все три задачи. Респект им. Но мы тоже молодцы.
Для нас подготовили три задачи. Все достаточно интересные и сложные. Чтобы получить нормальное качество для каждой из них, я думаю, нужно потратить не одну неделю. Нам предложили уложиться в сутки.
Первая задача была про предсказание зарплат по описанию вакансий. На HH часто вместо суммы, на которую может рассчитывать соискатель, пишут «з/п не указана». Предлагалось как-то исправить это обстоятельно и заполнить пробелы примерными значениями. Нам предоставили ~700 000 записей вида
{
"code": null,
"site": {
"id": "hh",
"name": "hh.ru"
},
"published_at": "2015-08-18T18:19:00+0300",
"accept_handicapped": false,
"key_skills": [],
"employment": {
"id": "full",
"name": "Полная занятость"
},
"id": "4027565",
"archived": false,
"contacts": null,
"response_url": null,
"relations": [],
"employer": {
"logo_urls": null,
"vacancies_url": "https://api.hh.ru/vacancies?employer_id=1942790",
"name": "Сирота ЛБ",
"url": "https://api.hh.ru/employers/1942790",
"alternate_url": "http://hh.ru/employer/1942790",
"id": "1942790"
},
"response_letter_required": false,
"billing_type": {
"id": "free",
"name": "Бесплатная"
},
"hidden": false,
"type": {
"id": "open",
"name": "Открытая"
},
"specializations": [
{
"id": "3.318",
"profarea_name": "Маркетинг, реклама, PR",
"profarea_id": "3",
"name": "Управление маркетингом"
},
{
"id": "3.98",
"profarea_name": "Маркетинг, реклама, PR",
"profarea_id": "3",
"name": "Исследования рынка"
},
{
"id": "3.230",
"profarea_name": "Маркетинг, реклама, PR",
"profarea_id": "3",
"name": "Продвижение, Специальные мероприятия"
},
{
"id": "3.90",
"profarea_name": "Маркетинг, реклама, PR",
"profarea_id": "3",
"name": "Интернет-маркетинг"
}
],
"premium": false,
"description": "<p><strong>Обязанности:</strong> консультирование клиентов, работа с электронной почтой, обучение новых сотрудников, ведение отчета по проделанной работе.</p> <p> </p> <p><strong>Требования:</strong> уверенный пользователь ПК, скоростной интернет, целеустремленность, желание зарабатывать, терпеливость при работе с клиентами, ответственность, доброжелательность.</p> <p> </p> <p><strong>Условия</strong>: трудоустройство по Т.З.Р.Ф., своевременная зарплата, бонусы, премии, бесплатное обучение и сопровождение до результата, карьерный рост.</p> <p>Обращаться по эл. почте</p>",
"schedule": {
"id": "fullDay",
"name": "Полный день"
},
"suitable_resumes_url": null,
"test": null,
"department": null,
"allow_messages": true,
"address": null,
"salary": {
"to": null,
"from": 31000,
"currency": "RUR"
},
"name": "Менеджер он-лайн офиса",
"created_at": "2015-08-18T18:19:00+0300",
"area": {
"url": "https://api.hh.ru/areas/1884",
"id": "1884",
"name": "Льгов"
},
"experience": {
"id": "between1And3",
"name": "От 1 года до 3 лет"
},
"negotiations_url": null,
"branded_description": null
}
И тестовый набор с пустыми полями «salary.to» и «salary.from», которые нужно было заполнить. Вообще данные очень интересные. Думаю, с их помощью можно много чего понять про рынок труда в России. Мы, для начала, посмотрели на какие-то базовые вещи. Данные нам дали свежие. За несколько дней до выгрузки есть скачок числа новых вакансий. Ребята объясняют это тем, что рекрутеры часто в начале недели перезаливают объявления, чтобы их увидело побольше людей:
На удивление часто требуются люди без опыта:
Обычно нужны люди на полный день:
Пока я с интересом изучал данные и периодически делился наблюдениями, Диман, не особо вникая с содержание, запихнул всё в Vowpal Wabbit и получил модель, которая сразу заняла первой место и пребывала там в гордом одиночестве почти до самого конца хакатона. В чём там заключалась суть я не понял, поэтому слово Диме:
Одной из основных целей было показать, что нельзя огульно использовать Spark где попало, и большой пласт задач можно достаточно эффективно решать и на десктопных машинах, даже если выборка не помещается в память.
В таких случаях хорошо работает online обучение en.wikipedia.org/wiki/Online_machine_learning, если в кратце, то мы берем горстку элементов выборки (а чаще вообще один) и делаем шаг оптимизационного алгоритма. Простейший вариант стохастического спуска достаточно прост в описании и интуитивно понятен en.wikipedia.org/wiki/Stochastic_gradient_descent. Впрочем сходимость у него будет ни к черту, поэтому обычно используют более интересные вещи, например в приложениях хорошо зарекомендовал себя Follow-the-Regularized-Leader почитать подробнее можно, например, здесь web.stanford.edu/class/cs229t/notes.pdf.
Но прежде чем использовать сам алгоритм нужно было подготовить данные. На основе анализа, который был проделан ранее, а так же здравого смысла было отобрано несколько признаков, таких как геолокация, название компании, стаж, график, требуемые навыки и так далее. Куда интереснее дело обстоит с текстовым описанием. Так как хотелось получить максимально простое и быстрое решение от использования популярных, но затратных в плане вычесления методов отказались. В результате использовалось хэширование признаков en.wikipedia.org/wiki/Feature_hashing, которое опять же достаточно эффективно работает с линейными решающими правилами и большими размерностями, а так же решает проблему с кодированием категориальных признаков.
Писать велосипед не особо хотелось, поэтому использовалось готовое решение, а именно весьма популярный на Kaggle Vowpal Wabbit. Изначально эта утилита задумывалась, как исключительно линейная онлайн обучалка, однако со временем разрослась. Из полезных приятностей это возможность кэшировать файлы с данными, что сильно ускоряет работу (скорость ограничена чтением данных с диска), а так же Progressive Validation, что позволяет оценить скорость сходимости.
Как-то значительно улучшить модель, используя квадратичные признаки или регуляризацию, увеличение колличество проходов не удалось.
Весь процесс подготовки данных и обучения занимал около 6 минут, из которых 5 уходили на преобразование в нужный формат, обучение идет меньше минуты.
И вот ещё его презентация на всякие случай.
Я поудивлялся тому как нынче молодёжь решает аналитические задачи и перешёл ко второму датасету. Там предлагалось сделать систему для поиска похожих запросов:
В принципе, ребята из HH эту систему уже сделали, и даже год назад написали об этом подробную статью, но данных, которые не подпадают под NDA не так много, поэтому пришлось конструировать велосипед. Впрочем, велосипед, у меня получился вполне зачётный. Данных нам отгрузили щедро. Было два файлика. В первом для каждого пользователя были указаны его запросы (~100 000 000 строк):
Специалист 755713242
Call-центр 293043490
повар универсал -1453491075
Бухгалтер 368599217
83220527
Бухгалтер по расчету заработной платы 2002085826
-1690082898
кладовщик 199265113
Водитель категории C -571664634
starling 938815142
...
Во втором, для каждого запроса было указано по какому результату каждый пользователь кликал (~60 000 000 строк):
374962018 -1871849048 Перевозки
435199331 656053665 java
-479980995 2055924405 развитие территории
-312078053 1785295198 стажер
373352347 -1306352914 swatch group
-335100665 -786187311 обработка изображений
430556647 834763896 директор
430528038 1620277313 Бухгалтер
435232940 -1022351920 Программист 1с
433204418 -2121514172 координатор сервиса
...
Я, естественно, не мог не заметить сходство этой задачи с задачей про поиск похожих групп ВК, про которую недавно писал. За несколько часов был построен роскошный граф вида:
Каждой вершине соответствовал запрос. Похожие запросы объединялись в кластеры. Вот, например, запросы про фармацевтов:
Про таможенников:
Метрика для этой задачи была интересной. В конце хакатона нужно было выйти на сцену и в реальном времени понаходить рекомендации для запросов, которые придумает жюри. В нашем случае это выглядело так:
С первой и второй задачами у нас всё получилось, достаточно неплохо, чего не скажешь о последней третьей задаче. Там нужно было сделать систему рекомендаций товаров для Озона. Данные выглядели примерно так:
[
100000,
{
"0": "данная книга содержит подробное описание широко распространенных моделей телевизоров выпускаемых фирмами goldstar supra shivaki ham собранных на шасси pc04 и pc91a приведено комплексное описание работы телевизоров по функциональной и принципиальнойсхемам методика поиска неисправностей и регулировка этих телевизоров схемы сопровождаются таблицами назначения элементов данные модели широко распространены на нашем рынке и часто вызывают интерес у людей занимающихся ремонтом телевизионной аппаратуры в ответ на их многочисленные обращения была написана данная книга книга предназначена для специалистов занимающихся обслуживанием и ремонтом телевизионной техники и подготовленных радиолюбителей",
"1": "телевизоры goldstar на шасси pc04 pc91a",
"2": "ю бобылев",
"6": "зарубежная электроника",
"32": "русский",
"18": "наука и техника",
"53": "5_88977_036_5"
}
]
[
1000001,
{
"0": "регион все регионы br рейтинг mpaa not rated p",
"1": "skinny tiger and fatty dragon",
"7": "skinny tiger and fatty dragon"
}
]
[
1000003,
{
"0": "регион 1 usa and canada br рейтинг mpaa r not for sale to persons under age 18 p",
"1": "skipped parts",
"7": "skipped parts"
}
]
[
1000005,
{
"0": "регион 1 usa and canada br рейтинг mpaa not rated p",
"1": "sky wars",
"7": "sky wars"
}
]
...
Подобных записей нам отгрузили ~10 000 000 штук, что дофига. Там была ещё куча всяких файликов, но я на них даже не смотрел. Нужно было для данного товара найти хорошие оригинальные рекомендации. Кроме того, что задача сама по себе, мягко говоря, не простая и данных очень много у нас возникла ещё одна проблема. Это Spark. Примерно 12 часов ушло на то, чтобы загрузить туда данные и запустить простейшие операции. Хакатон однозначно не лучше место для первого знакомства с подобными технологиями. В итоге за два часа до дедлайна мы приняли волевое решение забить на Spark и запилить хотя бы какое-то решение локально. Мой Макбучек, как всегда не подвёл, место на диске подходило к концу, но базовое решение у нас появилось. Мы делали очень примитивную вещь. Все слова из описания товара складывали в set. Потом шли по списку товаров и считали пересечение. Товары с большим пересечением попадали в рекомендации. В принципе, такой метод работал. Для
[
28759795,
{
"1": "bruder тягач mack с прицепом платформой с колесным экскаватором погрузчиком цвет красный желтый черный",
"5": "спецтехника",
"6": "bworld",
"9": "машинки танки самолеты",
"10": "bruder",
"11": "bruder spielwaren gmbh",
"45": "23 февраля",
"15": "тягач прицеп платформа экскаватор погрузчик",
"38": "для мальчиков",
"30": "сын"
}
]
Мы рекомендовали
[
30161483,
{
"1": "bruder самосвал mercedes benz с колесным экскаватором цвет красный желтый",
"5": "спецтехника",
"6": "bworld",
"9": "машинки танки самолеты",
"10": "bruder",
"11": "bruder spielwaren gmbh",
"45": "23 февраля",
"15": "самосвал экскаватор",
"38": "для мальчиков",
"30": "сын"
}
]
[
28759817,
{
"1": "bruder эвакуатор mercedes benz с внедорожником цвет красный желтый черный",
"5": "спецтехника",
"6": "bworld",
"9": "машинки танки самолеты",
"10": "bruder",
"11": "bruder spielwaren gmbh",
"45": "23 февраля",
"15": "эвакуатор внедорожник аксессуары",
"38": "для мальчиков",
"30": "сын"
}
]
[
28759801,
{
"1": "bruder фургон scania цвет зеленый белый красный",
"5": "спецтехника",
"6": "bworld",
"9": "машинки танки самолеты",
"10": "bruder",
"11": "bruder spielwaren gmbh",
"45": "23 февраля",
"15": "машина погрузчик 2 паллета",
"38": "для мальчиков",
"30": "сын"
}
]
Правда, чтобы сделать рекомендации для одного товара, нам нужна была примерно минута. А тестовых кейсов было ~60 000. И до дедлайна оставалось 15 минут. Короче, третью задачу мы подслили.
Первое место заняли чуваки, которые, более или менее решили все три задачи. Респект им. Но мы тоже молодцы.
Комментарии (6)

ffriend
31.08.2015 01:44Правда, чтобы сделать рекомендации для одного товара, нам нужна была примерно минута.
Если сравнивали каждый с каждым, то у Твиттера есть интересный алгоритм, который значительно снижает время сравнения, а в Spark уже есть его реализация. Но Spark нужно знать и даже иметь заведённый кластер в любом случае, без этого никак.
Imp5
Огромное вам спасибо за статью!
Теперь я наконец-то могу составить для себя прогноз на будущее по поводу престижности специальностей в Data Mining и Big Data. По моим представлениям, к ним через десять лет будут относиться приблизительно как к создателям лендингов на PHP.
knagaev
Всё-таки наверно, как и везде, будет «расслоение» на специалистов высого класса (в том числе разрабатывающих новые модели и алгоритмы) и лего-лендинг-программистов.
Вся разница кто где останавливается в своём образовании.
Imp5
Да, согласен. Но я думаю, что судить будут по большинству. Наверное так во всех отраслях, где резко снижается порог вхождения. Лет 10 назад я не думал, что будет неудобно говорить, что занимаешься разработкой игр.
knagaev
Да, я тоже согласен.
Раньше, когда в ответ на вопрос «Чем занимаешься?», говорил «Программист», то был интерес в глазах.
А теперь как-то часто проскальзывает некое сожаление («ну да, ну да, ну ты не расстраивайся»).
И ловишь себя, что хочется сказать «Да нет, это не то, что вы подумали, я не тот, кто у вас в офисе картриджи в принтерах меняет, у меня очень интересная работа...», но потом мысленно махнёшь рукой и всё.
В общем в борделе на пианине лабаю.
kraidiky
Сейчас, кстати, найти реально хорошего HTML верстальщика стало такой большой проблемой, что за него готовы платить больше, чем за каких-нибудь дотнетеров, но вот найти его… Расслоение имеет интересные побочные эффекты.