
В State Of DevOps 2018 от DORA мы видим, что Нigh Performing компании используют Trunk Based Development. Разберемся, почему именно ее, какие ее преимущества и недостатки имеет эта модель.
Всем привет! Меня зовут Андрей. Я DevOps-консультант. Работаю в Express 42, по совместительству ведущий подкаста DevOps Deflope. И сегодня я рассказу про Trunk Based Development.
Это штука очень сложная. Я не уверен, что у меня получится за 10 минут объяснить все концепции, идеи, которые за ней стоят.

Почему эта модель лучше? Я не буду рассуждать на тему: лучше она или нет, потому что пруфы в индустрии уже есть:
- У нас есть State Of DevOps, в котором ребята на основе статистики заметили, что производительность компании напрямую коррелирует с практиками и конкретно с Trunk Based Development.
- У нас есть книжка Accelerate, которая описывает, почему это все так работает.
- У нас есть классный доклад трехлетней давности от Google про то, что у них люди используют Trunk. В одной монорепе 25 000 человек.
- Также можно у Martin Fowler найти кучу статей, как это все работает.
Я буду сосредотачиваться только на том, почему и зачем это нужно.
Мы хотим тестировать бизнес-гипотезы как можно быстрее. Мы хотим выдвинуть идею, протестировать, отдать пользователям. И Trunk Based Development идеально для этого подходит.

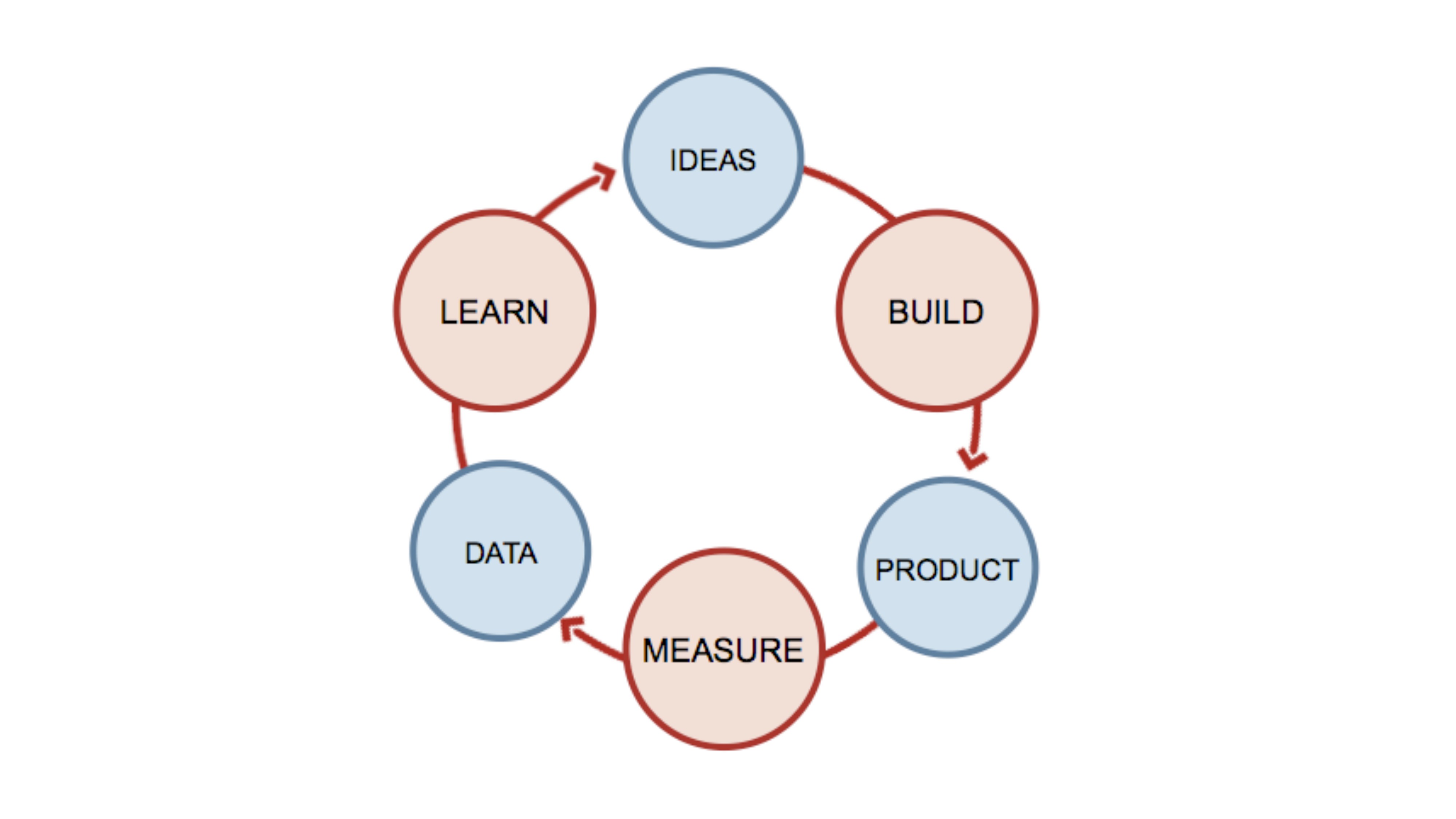
В чем суть Trunk Based Development?
Это:
- Короткоживущие ветки. У нас любая ветка, которая создается (кроме мастера), живет не больше двух дней. Два дня и все, это уже не Trunk и все печально. Поэтому все ветки, кроме мастера, например, ветка релизная или для фичи живет не больше двух дней.
- Feature Flags и Branch By Abstraction. Я про это расскажу чуть позже.
- Continuous Code Review.
- И основная идея в том, что у нас теперь и мастер всегда готов к деплою, даже если в нем есть недописанные фичи. Он всегда – release ready и вообще не важно, что в нем.

Поговорим про все эти штуки. Почему они хороши?
Все начинается с Feature Flags. Все следующие шаги без этой штуки сделать не получится.
В чем идея Feature Flags? В том, что мы теперь с помощью ключика можем сказать, какие фичи мы включаем, а какие нет. Большая часть фич оборачивается в Feature Flags. И когда мы запускаем наше приложение, мы говорим, что теперь наши пользователи могут за один клик покупать. И таким образом мы можем делать A/B тесты и мержить в мастер те фичи, которые еще не готовы.

Что дает нам включение-выключение фич?
- Можем мержить и деплоить код, который еще не готов.
- Можем делать A/B тесты.
- Можем шарить код между недоработанными фичами.
Когда я раньше писал код за деньги, у меня была большая боль. В чем была проблема? У меня есть большой pull request. Я в нем сделал кучу абстракций, полей в базе данных и прочее. И они уже нужны в других фичах. Но мы не можем это переиспользовать, потому что у меня еще не все готово. И мы не можем это смержить. А Trunk позволяет все это делать, потому что у нас Feature Flags как обязательный подход.

Вот это самая сложная вещь. Тут очень многие люди совершают ошибку. У нас больше нет веток для фич. Это сложная концепция.
В чем идея? Мы больше не делаем ветки для фич, мы делаем ветки на изменение одной абстракции.
Например, у нас есть машинка, в ней есть абстракция «передние колеса» и «задние колеса». И мы хотим, чтобы эти колеса работали как-то по-другому. Например, чтобы был другой тип колес, шин.
Как в случае с Trunk будем их менять?
- Мы сначала создадим один pull request и обернем колесико в другую абстракцию. Колесо будет вести себя также, но оно будет спрятано за другой абстракцией, т. е. мы сделали pull request, смержили.
- Следующий pull request. Мы реализуем другой вид поведения передних колес. Мы добавили новую абстракцию. Это отдельный pull request. Смержили. За два pull requests мы создали абстракцию интерфейсную, мы создали внутри нее новое поведение. И тут у нас уже Feature Flags, чтобы могли переключаться между новым типом колес и старым.
- У нас есть задние колеса. Делаем то же самое. Имплементируем интерфейсную абстракцию, которая будет позволять нам переключаться между колесами. Внутри нее заворачиваем логику выбора колес. Пилим вторым pull request’ом туда новый тип колес.
- Дальше мы все это можем выпустить в prod и переключить Feature Flags на то, что мы теперь используем новые колеса.
- И новыми pull request’ами удалить старое.
Мы задачу по замене колес, которая большая и сложная с кучей рефакторинга, декомпозировали на маленькие кусочки. И pull requests делаем на изменение одной маленькой абстракции. Вот это ключевая идея. И это то, за счет чего Trunk получается очень быстрым.

Что дает нам такой подход?
- У нас частые интеграции. У нас был continuous integration в индустрии, где мы пришли к тому, чтобы работать маленькими кусочками. И это ультимативный вариант, т. е. мы теперь все время работаем маленькими кусочками, даже микрокусочками.
- Мы можем рефакторить так наше приложение постепенно. У нас нет такого, что мы за один раз должны переделать вообще все. Маленькие кусочки, маленькие итерации.
- И это позволяет нам быстро переключаться между задачами. Например, мы делали одну штуку, а у нас сейчас аврал и надо что-то фиксить, мы можем спокойно вмержить то, что у нас уже было, переключиться на другую задачу. Это ничего не сломает. Наш pull request не будет потерян, забыт. И его можно будет легко проверить спустя 5 дней после того, как его написали, потому что они все маленькие.
Соответственно, мы теперь работаем маленькими кусочками, меняем одну абстракцию за раз и это нам позволяет использовать подход Continuous Review.

- В чем идея подхода? Идея в том, что мы изменили маленькую абстракцию, сделали pull request. И кто-то другой в этот же момент начинает смотреть. В тот момент, когда мы закончили работу над своим изменением, мы смотрим чужое. Т. е. все коллеги постоянно друг друга смотрят.
- Поскольку у нас pull requests очень маленькие, они изменяют только маленький кусочек кода. И у нас review занимает пару минут. Т. е. pull request не висит три дня, пока его кто-нибудь посмотрит, а потом вы будете еще что-то там подправлять и в итоге он не висит очень долго, а всего лишь пара минут.
- На trunkbaseddevelopment.com еще отмечают, что если 10 минут смотрели pull request, т. е. от создания до мержа 10 минут, то это приемлемый результат. Не очень хорошо, но жить можно.
- Если pull request висел больше часа, то надо обращать внимание на это, что-то тут не так. Где-то у нас проблемы с подходом.

- Как любое review оно дает нам шаринг знаний. Все программисты понимают, как код меняется. Мы переиспользуем код, советуем друг другу лучшие практики и т. д. И мы это делаем постоянно, каждые 10 минут фактически, с каждой абстракцией.
- Можно использовать экстремальное программирование. Когда два человека все время пишут код вместе, тогда вам review не нужно, вы его делаете сразу. Соответственно, снижаете тех долга по причине того, что мы все смотрим.
- И ускоряем поставку. Мы pull request готовим не днями. Мы сделали изменение, оно в prode через две минуты.

Это все очень-очень сложно. Я пытался уже несколько раз рассказывать про Trunk. И каждый раз у людей складывалось впечатление, что это как Git Flow или GitHub Flow, но только проще, потому что нет пару лишних веток, поэтому Trunk Based Development очень простой. Нет, эта штука очень сложная.
- Во-первых, у вас должно быть высокое покрытие тестами, чтобы вы могли так делать. Чтобы вы могли все время мержить все свои изменения в мастер и при этом не бояться, что у вас что-то сломается, вам нужно высокое покрытие тестами.
- Feature Flags потребуют изменений в инфраструктуре. Вы теперь должны кодом, переменными включать те фичи, которые вам нужны. И вам нужно написать код вокруг ваших …, Ansible-ролей и т. д., чтобы вы могли этим управлять.
- Branch By Abstraction требует от вас навыка построения абстракции и декомпозиции ваших задач, чтобы бить это все на мелкие кусочки.
И, поверьте, это не так просто. По моему опыту общения с программистами далеко не у всех все хорошо с применением SOLID-практик. Если ваши программисты разбираются в SOLID, то, скорее всего, эта абстракция у них есть и так. Потому что SOLID нам говорит: «Делай объект, а вокруг него делай еще интерфейс-абстракцию». Если у программиста с этим проблемы, то не взлетит, надо будет все это подтягивать.

Почему, несмотря на все эти сложности, мы приходим к тому, что она лучшая?
Потому что:
- У нее самые короткие итерации. Когда мы изменение делаем за две минуты, за две минуты его ревьювим и мержим, и оно уже в prode, то это огонь.
- Мы можем деплоить все подряд. У нас нет никаких блокировок, что в какой-то ветке фича не готова, мы деплоим все подряд. Мы шарим код и за счет этого мы быстрее.
- Шаринг знаний за счет Continuous review, потому что все всё смотрят.
- И это ревью занимает буквально несколько минут.
Конец
Тут парочка полезных ссылочек:
- https://www.youtube.com/watch?v=Iq0Nm_cc0wo.
- https://speakerdeck.com/devopsmoscow/pochiemu-trunk-based-development-luchshaia-modiel-vietvlieniia.
- http://express42.com (Ссылка на сайт компании Express 42, где я работаю. Возможно, мы сможем вам помочь с курсами, аудитами, проектами и т. д.).
- https://devopsdeflope.ru (Ссылка на подкаст DevOps Deflope, который мы с коллегой ведем).
- https://t.me/aladmit_world (Ссылочка на Telegram-канал с новостями индустрии).
- https://t.me/devops_deflope (Мой персональный канал, где я пишу про всякие штуки, которые мне в голову приходят).

Приветствую! Допустим, у нас есть команда, у которой нет вообще никаких процессов, т. е. даже Git Flow нет. Теоретически мы можем пропустить итерацию выстраивания Git Flow и прочих процессов, а сразу прыгнуть в Trunk Based? И насколько это реально?
Теоретически можно. Trunk Based Development очень сильно вариативный. Если сейчас не получается прыгнуть сразу в Branch By Abstraction, то можно сделать Short-Lived Branches. Это как фичи-ветки, только они живут очень мало. Один-два дня – максимальное время жизни ветки от создания. Можно зайти с этого. Можно сделать короткоживущие ветки, а потом сверху все остальное. Можно попробовать так.
Ты сказал, что для принятия pull request его должно посмотреть достаточное количество глаз. Обычно при разработке у нас есть TeamLead, который просматривает все поступающее и принимает единоличное решение о включении или не включении в текущий Branch. Каким образом вы организовываете pull request, что у вас несколько человек смотрят и принимают решение? У вас голосование?
Можно делать по-разному. Можно, чтобы просто любой коллега посмотрел. Делать так, что все pull requests смотрит TeamLead – это плохая идея, потому что их теперь у тебя очень много, они очень частые и он становится бутылочным горлышком.
Т. е. не несколько человек смотрят все-таки?
Это как принято в компании. Может смотреть несколько, может один человек. Но хоть кто-то должен посмотреть, иначе у тебя не будет никаких плюшек от review, т. е. нет шаринга, нет моментального рефакторинга и т. д.
Привет! Спасибо большое за доклад! Какого размера примерно проект должен быть? Это должен быть маленький проект, микросервисы или это идеология натягивается на любой размер проекта?
Абсолютно на любой. У тебя по большому счету претензия к архитектуре в этом случае. Если ты монолит сделал по условному SOLID, у тебя все абстракции нормально разделены, то у тебя никаких проблем не будет. Ты за счет этого подхода, даже если изначально он был сделан плохо, можешь его кусочками-кусочками медленно рефакторить. И при этом своим рефакторингом абсолютно не блокируешь коллег.
Накрывается ли тестами работа Feature Flags? И насколько большой overhead для разработки, для тестирования вот это покрытие вызывает?
Мы должны тестировать и вариант, когда фича включена и вариант, когда она выключена, иначе мы не понимаем ломаем ли мы prod или нет.
А насколько overhead? Тут не очень понятно, как мерить.
Т. е. два раза нужно написать тест? Нужно написать для старой фичи, нужно написать для новой фичи?
Нет, тест для старой фичи у тебя не пишется, потому что ты его уже писал.
Он уже есть, да. А для новой нужно написать. И внутри написать включилось и не включилось.
Да, ты внутри теста старой абстракции пишешь «if включена новая фича», тогда вот эти тесты новые. Also – старые. И прогоняешь и то, и то. Я не вижу тут какого-то overhead, кроме добавления строчки if, потому что старые тесты у тебя есть, новые ты добавляешь.
Спасибо за доклад! У нас большой проект. У нас Trunk Based Development уже год.
Огонь.
Все отлично, все работает. Только у нас SVN. И поэтому мы просто коммитим прямо в Trunk. И у нас нет pull request, мы коммитим прямо в Trunk. Все здорово и хорошо. Спасибо автотестам. Но пришли новые люди и начали ныть: «Давайте нам Git Flow, ваш Trunk Based – это какой-то ужас». И мы прогнулись, и решили переехать на Git. И сейчас у нас пол проекта в SVN, полпроекта в Git. Скоро весь проект будет в Git. И мне страшно. Мне Trunk Based Development нравится. И мне страшно от него отказываться. Если переехать с такого вида, когда мы коммитим прямо в Trunk, на такое, мы не замедлимся? Т. е. если Short-Lived Branches не по фичам, а Branch By Abstraction, то это не замедлит нас?
У тебя один коммит в мастер – это целая фича?
Нет, у меня один коммит в мастер – это просто кто-то что-то написал и коммитит.
Я понял. Branch By Abstraction, только Commit By Abstraction фактически?
Да.
Если вы все-таки начинаете друг друга ревьювить, то это плюс две минуты на ревью кого-то.
Мы в Trunk смотрим и если что-то там плохо, то правим.
Тогда не должно быть никаких проблем. Если мы посмотрим тот же trunkbaseddevelopment.com, то он говорит, что если вы очень крутые, то можете прямо в мастер фигачить. Но вы должны быть очень крутыми, чтобы так делать. видимо, вы крутые.
Привет! Спасибо за доклад! Я хотел по этой картинке спросить (Branch By Abstraction вместо feature branch). Ты говоришь, что над любой фичей должна быть абстракция. Почему тогда не остановится на 4-ом варианте? Если в следующий раз нужно будет что-то поменять, то нужно будет эту абстракцию дополнительно пилить как в первом шаге.
Есть два варианта. Есть вариант, когда мы эту абстракцию оставляем и есть вариант, когда мы ее убираем. Все делают по-разному. Если мы посмотрим, например, на блог Fowler, то он говорит, что эту штуку давайте оставим, пусть у нас для всего будет abstraction layer или layer интерфейса. Это пример с Trunk Based Development, они объясняют эту штуку так. Но можно оставлять, можно убирать – это не принципиально. Но я бы рекомендовал все-таки оставить. Т. е. мы удалили старый вариант, но оставили новый тип колес и абстракцию, через которую мы все еще можем с этим что-то делать.
И еще вопрос у меня по Code Review. Очевидно, когда приходит junior-разработчик в команду, то его Code Review вряд ли будет занимать 10 минут и PR вряд ли будет висеть час. Это может быть и дольше, и может быть отклонено. Что будет в таких случаях? Или ты не берешь вообще juniors в команду?
Можно раскрыть вопрос?
Когда junior берется за дело, то ему требуется больше комментариев по коду и т. д. И, возможно, какие-то исправления необходимо вносить в pull request. А ты говоришь, что pull request висит 10 минут, т. е. он не успеет за 10 минут, скорее всего, поправить. Что делать?
У тебя junior будет исключением. 10 минут – это еще приемлемый результат. Если больше часа, то мы считаем это плохим результатом. Понятно, что Junior будет сложно. Скорее всего, он еще не те абстракции менял или не оттуда зашел. Для него придется сделать исключение.
Можно картинку с машинкой? Вот здесь все вроде бы понятно и хорошо. Мы меняем только колеса. А что если это будет не машинка, а здоровенный космолет из 50 150 частей, которые одновременно изменяются? Ладно, давайте вернемся к этой машинке. У нас несколько команд одновременно изменяет кто-то поведение фар, кто-то поведение стекла, колеса. В итоге выглядит более логичным, чтобы вместо красного корпуса была одна здоровенная абстракция, либо мы ее тоже будем менять. Не приводит ли это к тому, что у тебя начинается какая-то безумная простыня из Feature Flags, когда не понятно, как эти изменения должны друг с другом взаимодействовать? Потому что измененное стекло пусть даже с абстракцией не будет взаимодействовать через корпус с новыми колесами и ее абстракциями. Я уже сам запутался, пока объяснял.
Я понял. Основной вопрос в том, что будет, если мы параллельно меняем кучу всего.
Да, когда проект большой и изменений много в один момент времени.
Проблем не будет и вот почему. У тебя тут абстракция интерфейсная, которая позволяет колеса менять. Тут абстракция, позволяющая фары менять. Тут абстракция, позволяющая менять стекла. Почему это не будет сложно? Потому что у тебя в каждый момент времени все разработчики знают, что меняется. У тебя разработчик шлет сюда pull request на изменение фары, но он работает с максимально актуальным кодом, потому что мы мержимся каждые несколько минут. Поэтому он видит, что еще делают его коллеги. И, возможно, они объединятся и сделают какой-то единый вариант абстракции или еще что-то. У тебя, когда кто-то будет слать сюда pull request, он будет видеть, что другие коллеги уже тоже что-то делают.
Я вспомнил, что хотел сделать опрос. Поднимите руку, кто до этого момента слышал про Trunk. Неплохо, почти треть. А кто использует его у себя в проектах? 4 человека.
Мы в одном компании.
А, вы в одной компании, хорошо. Отлично.

ctacka
Ругаться хочется!
— TBD лучше чем что? Чем git flow? Всегда? А когда нельзя все фичи оборачивать фича-флагам. И как трекать зависимости между фича-флагами? Если, допустим, вы отключили покупки в один клик, и у вас отвалились покупки через apple pay.
А вообще, чем лучше? А мы можем деплоить очень быстро в прод, очень быстро доставлять фичи! А если у нас верификация каждой поставки — месяц? А если деплой в полях на девайсы, не by wire?
Выбор стратегии конфигурационного менеджмента зависит в первую очередь от жизненного цикла проекта, и уже во вторую — от имеющихся процессов и зрелости команды. Не все проекты — интернет-магазины, не все позволяют А/Б тестирование, и делать такие ультимативные заявления — расписываться в собственном узком кругозоре. Что для devops-консультана (а не in-house devops, который, может, одним проектом живет и другого не видал) — вообще равносильно профнепригодности!