Придя в компанию МегаФон как iOS-разработчик, Валентин Чернов попал в сегодняшний основной тренд — переход приложений в оффлайн. Основная работа Валентина — разработка главного приложения МегаФона, мобильного личного кабинета. Это в нем вы можете смотреть баланс и вообще управлять им, подключать/отключать услуги и сервисы, смотреть сторисы, участвовать в конкурсах и видеть персональные предложения от партнеров МегаФона.
Даже несмотря на то, что оно недавно получило две премии Рунета, с таким количеством сервисов приложение, конечно, будет тяжелым и весомым. И перевод его в оффлайн — большая длинная задача. Сейчас МегаФон выбрал возможность работать при нестабильной связи как одну из важных точек роста. Хотя уже двадцать первый век, 4G-5G сети наступают по всем фронтам, тем не менее для приложений федерального масштаба в России найдутся места, где связь временно отключается или пропадает надолго. И нужно, чтобы даже в этом случае приложение работало без сбоев.
О том, как эта задача выполнялась в течение последних 5 месяцев, как выбирали и воплощали архитектуру проекта, какие технологии выбрали и использовали, а также чего достигли и что запланировали на будущее, Валентин рассказал в докладе на Конференции разработчиков мобильных приложений Apps Live 2020.

Бизнес сказал — идём в оффлайн, чтобы пользователь мог успешно взаимодействовать с приложением в условиях нестабильного сетевого подключения. Мы, как команда разработки, должны были гарантировать Offline first — работу приложения даже при нестабильном или совсем отсутствующем интернете. Сегодня расскажу о том, с чего мы начали и какие первые шаги в этом направлении сделали.
Помимо стандартной архитектуры MVC мы используем:
Большая часть кода (80% нашего проекта) написан на Objective-C. А уже новый код мы пишем на Swift.
Глобальные куски кода мы логически разделяем на модули для достижения более быстрой компиляции, запуска проекта и развития его.
Все дополнительные библиотеки мы подключаем через git submodule, чтобы получить больше контроля над используемыми библиотеками. Поэтому, если вдруг прекратится поддержка какой-либо из них, мы сможем что-то с этим сделать сами.
При выборе для нас главным критерием были нативность и интеграция с iOS фреймворками. А эти преимущества Core Data стали решающими при его выборе:
У UI kit есть встроенный класс, называемый UIManagedDocument, и который является подклассом UIDocument. Его основное отличие — при инициализации управляемого документа указывается URL-адрес для расположения документа в локальном или удаленном хранилище. Затем объект документа полностью создает стек Core Data прямо из коробки, который используется для доступа к постоянному хранилищу документа с использованием объектной модели (.xcdatamodeld) из основного пакета приложения. Это удобно и имеет смысл, даже несмотря на то, что мы живем уже в 21 веке:

Процесс проектирования у нас проходит в несколько этапов:
Сейчас, после 5 месяцев разработки этого проекта, я могу показать весь наш процесс в три этапа: что было, как менялось и что получилось в результате.
Нашей отправной точкой была стандартная MVC архитектура — это связанные между собой слои:
Activity indicator был расположен в том месте схемы, где мы держим пользователя в режиме ожидания — он хочет быстрого результата, но вынужден смотреть на какие-то лоадеры, индикаторы и прочие сигналы. Это было нашим слабым местом в user experience:
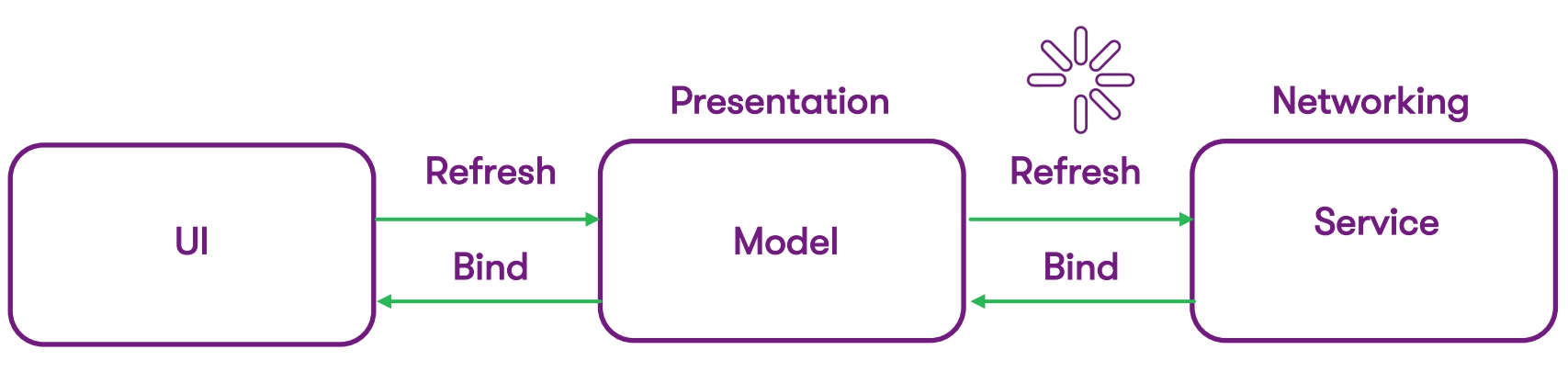
В переходный период мы должны были внедрить кэширование для экранов. Но так как приложение большое и содержит много legacy кода на Objective C, мы не можем просто взять и удалить все сервисы и модели, вставив Swift-код — мы должны учитывать, что параллельно с кэшированием у нас в разработке еще много других продуктовых задач.
Мы нашли безболезненный способ, как интегрироваться в текущий код максимально эффективно, ничего при этом не сломав, а первую итерацию провести максимально мягко. В левой части предыдущей схемы мы полностью убрали все, что связано с сетевыми запросами — по интерфейсу сервис теперь общается с DataSourceFacade. И сейчас это — фасад, с которым работает сервис. Он ждет от DataSource те данные, которые раньше получал от сети. А в самом DataSource скрыта логика по добыче этих данных.
В правой части схемы мы разбили получение данных на команды — паттерн Command нацелен выполнить какую-то базовую команду и получить результат. В случае iOS мы используем наследников NSOperation:
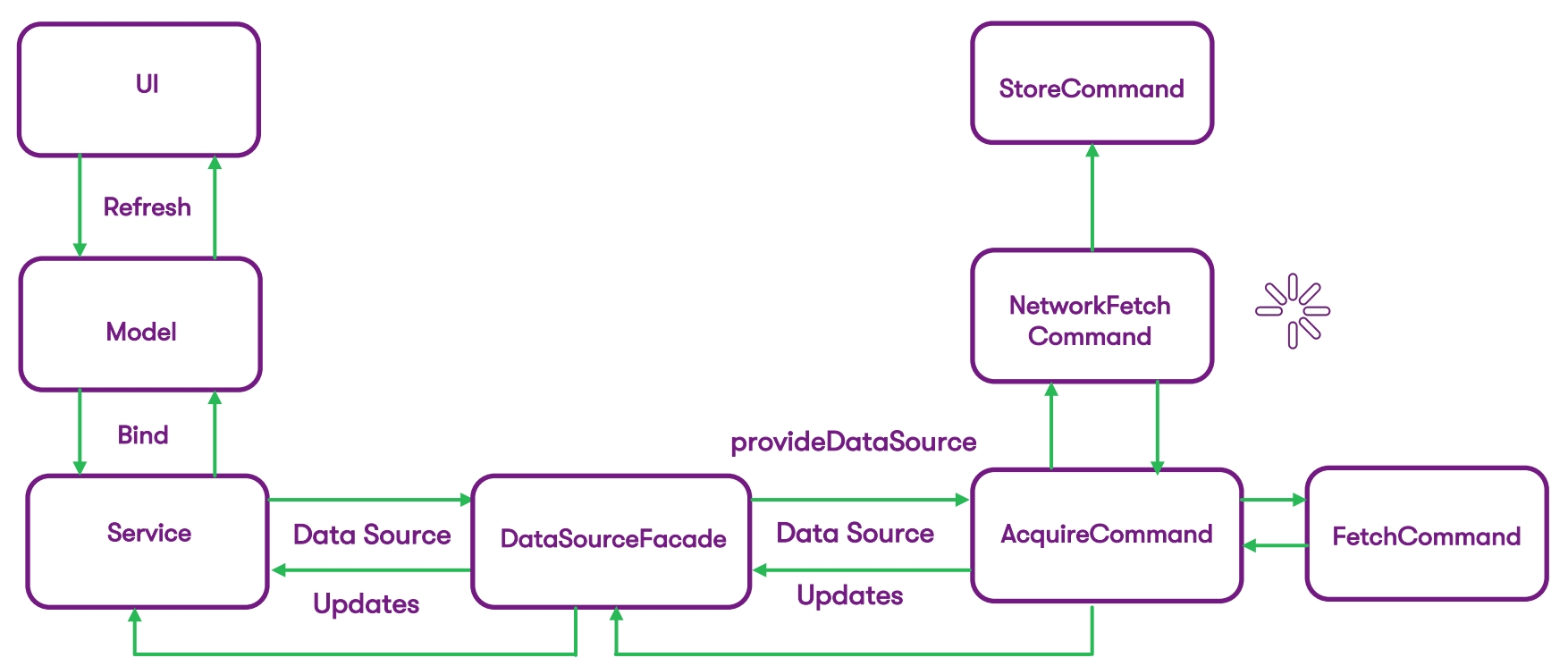
Каждая команда, которую вы здесь видите — это операция, в которой есть логическая единица ожидаемого действия. Это получение данных из БД (или сети) и сохранение этих данных в Core data. Или, например, главная задача AcquireCommand — это не только вернуть фасаду источник данных, но и дать нам возможность разрабатывать код таким образом, чтобы получать данные через фасад. То есть взаимодействие с операциями идет через данный фасад.
А основная задача операций — передать данные DataSource для DataSourceFacade. Конечно, мы выстраиваем логику так, чтобы как можно быстрее показать данные пользователю. Как правило, внутри DataSourceFacade у нас есть операционная очередь, где мы запускаем наши NSOperations. В зависимости от настроенных условий мы можем принять решение, когда показывать данные из кэша, а когда — получать из сети. При первом запросе источника данных в фасаде мы идем в БД Core data, достаем оттуда через FetchCommand данные (если они там есть) и моментально возвращаем их пользователю.
Одновременно запускаем параллельный запрос данных через сеть, и когда этот запрос выполняется, то результат приходит в базу данных, сохраняется в ней, и после мы получаем update нашего DataSource. Этот update попадает уже в UI. Так мы минимизируем время ожидания данных, а пользователь, получая их мгновенно, не замечает разницы. А обновленные данные он получит сразу, как база данных получит ответ от сети.
К такой более лаконичной схеме мы идем (и придем в итоге):
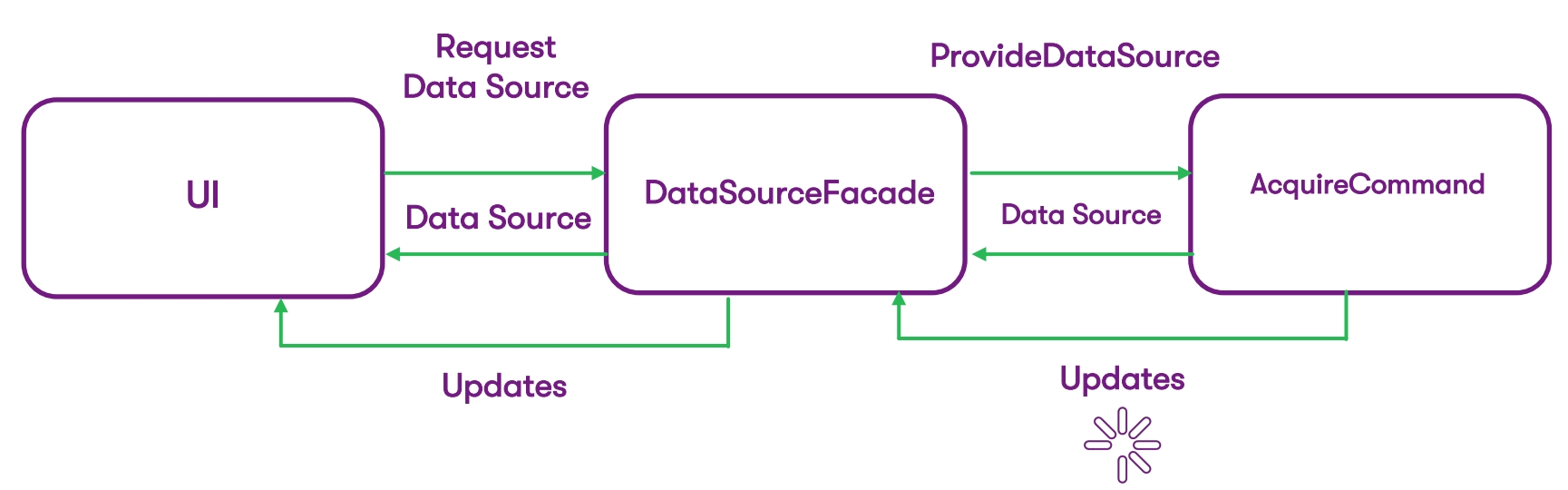
Сейчас из этого у нас есть:
DataSource — это объект, который предоставляет данные для слоя презентации и соответствует заранее определенному протоколу. А протокол должен быть подстроен под наш UI и предоставлять данные для нашего UI (неважно, для конкретного экрана или для группы экранов).
У DataSource, как правило, две основных обязанности:
Мы у себя используем несколько вариантов DataSource, потому что у нас много Objective C legacy кода — то есть, мы не везде можем легко наш Swift’овый DataSource воткнуть. Еще мы пока не везде используем коллекции, но в будущем перепишем код именно для использования CollectionView экранов.
Пример одного из наших DataSource:

Это DataSource для коллекции (он так и называется CollectionDataSource) и это достаточно несложный класс с точки зрения интерфейса. Он принимает в себя коллекцию, настроенный fetchedResultsController и CellDequeueBlock. Где CellDequeueBlock — type alias, в котором мы описываем стратегию по созданию ячеек.
То есть мы создали DataSource и присвоили его коллекции, вызвав у fetchedResultsController performFetch, и дальше вся магия возложена на взаимодействие нашего класса DataSource, fetchedResultsController и возможность у делегата получать обновления из базы данных:

FetchedResultsController — сердце нашего DataSource. В документации Apple вы найдете много информации по работе с ним. Как правило, мы получаем все данные с его помощью — и новые данные, и данные, которые были обновлены или удалены. При этом мы параллельно запрашиваем данные из сети. Как только данные были получены и сохранились в БД, мы получили update у DataSource, и update пришел к нам в UI. То есть одним запросом мы и получаем данные, и показываем их в разных местах — классно, удобно, нативно!
И везде, где можно использовать уже готовые DataSource с таблицами или с коллекциями, мы это делаем:

В тех местах, где у нас много экранов и не используются таблицы и коллекции (а используется Objective C программная верстка), мы оцениваем, какие данные нам нужны для экрана, и через протокол описываем наш DataSource. После этого пишем фасад — как правило, это тоже публичный протокол Objective C, через который мы запрашиваем наш DataSource. А дальше уже идет вход в Swift’овый код.
Как только мы будем готовы перевести экран полностью в Swift-реализацию, достаточно будет убрать Objective C-обертку — и можно работать напрямую со Swift’овым протоколом, благодаря кастомному DataSource.
Сейчас мы используем три основных варианта DataSources:
Даже несмотря на то, что оно недавно получило две премии Рунета, с таким количеством сервисов приложение, конечно, будет тяжелым и весомым. И перевод его в оффлайн — большая длинная задача. Сейчас МегаФон выбрал возможность работать при нестабильной связи как одну из важных точек роста. Хотя уже двадцать первый век, 4G-5G сети наступают по всем фронтам, тем не менее для приложений федерального масштаба в России найдутся места, где связь временно отключается или пропадает надолго. И нужно, чтобы даже в этом случае приложение работало без сбоев.
О том, как эта задача выполнялась в течение последних 5 месяцев, как выбирали и воплощали архитектуру проекта, какие технологии выбрали и использовали, а также чего достигли и что запланировали на будущее, Валентин рассказал в докладе на Конференции разработчиков мобильных приложений Apps Live 2020.
Задача
Бизнес сказал — идём в оффлайн, чтобы пользователь мог успешно взаимодействовать с приложением в условиях нестабильного сетевого подключения. Мы, как команда разработки, должны были гарантировать Offline first — работу приложения даже при нестабильном или совсем отсутствующем интернете. Сегодня расскажу о том, с чего мы начали и какие первые шаги в этом направлении сделали.
Стек технологий
Помимо стандартной архитектуры MVC мы используем:
Swift + Objective-C
Большая часть кода (80% нашего проекта) написан на Objective-C. А уже новый код мы пишем на Swift.
Модульная архитектура
Глобальные куски кода мы логически разделяем на модули для достижения более быстрой компиляции, запуска проекта и развития его.
Submodules (библиотеки)
Все дополнительные библиотеки мы подключаем через git submodule, чтобы получить больше контроля над используемыми библиотеками. Поэтому, если вдруг прекратится поддержка какой-либо из них, мы сможем что-то с этим сделать сами.
Core Data для локального хранения информации
При выборе для нас главным критерием были нативность и интеграция с iOS фреймворками. А эти преимущества Core Data стали решающими при его выборе:
- Автосохранение стека и данных, которые получаем;
- Удобная работа с моделью данных, достаточно удобная работа с графическим редактором для составления сущностей (и возможности их править, передавать новым разработчикам и т.д.)
- Поддержка миграции и версионирования;
- Ленивая загрузка объектов;
- Работа в многопоточном режиме;
- Отслеживание изменений;
- Интеграция с UI (FRC);
- Работа с запросами в БД на более высоком уровне (NSPredicates).
UIManaged document
У UI kit есть встроенный класс, называемый UIManagedDocument, и который является подклассом UIDocument. Его основное отличие — при инициализации управляемого документа указывается URL-адрес для расположения документа в локальном или удаленном хранилище. Затем объект документа полностью создает стек Core Data прямо из коробки, который используется для доступа к постоянному хранилищу документа с использованием объектной модели (.xcdatamodeld) из основного пакета приложения. Это удобно и имеет смысл, даже несмотря на то, что мы живем уже в 21 веке:
- UIDocument автосохраняет текущее состояние сам, с определенной частотой. Для особо критичных секций мы можем вручную вызывать сохранение.
- Можно отслеживать состояния документа. Если документ открыт для работы или находится в каких-то конфликтных ситуациях — например, мы осуществляем сохранение из разных точек, и где-то вдруг мы вызвали конфликт, — мы можем это отследить, обработать, поправить и уведомить пользователя правильной понятной ошибкой.
- UIDocument позволяет читать и записывать документ асинхронно.
- Он может создать стек Core data из коробки.
- Есть встроенная функция хранения в iCloud и синхронизации с облаком. Это как раз то, к чему мы в будущем стремимся.
- Поддержка версионности.
- Используется Document based app парадигма — представление модели данных как контейнер для хранения этих данных. Если посмотреть на классическую модель MVC в документации Apple, можем увидеть, что Core data создана как раз для того, чтобы управлять этой моделью и помогать нам на более высоком уровне абстракции работать с данными. На уровне модели работаем, подключая UIManagedDocument со всем созданным стеком. А сам документ рассматриваем как контейнер, который хранит Core data и все данные из кэша (от экранов, пользователей). Плюс это могут быть картинки, видео, тексты — любая информация.
- Мы же рассматриваем наше приложение, его запуск, авторизацию пользователей и все его данные как некий большой документ (файл), в котором хранится история нашего пользователя. И которую мы можем передавать, очищать и владеть ею на уровне приложения:
Процесс
Как мы проектировали архитектуру
Процесс проектирования у нас проходит в несколько этапов:
- Анализ технического задания.
- Отрисовка диаграммы UML-диаграмм. Мы используем в основном три типа UML-диаграмм: class diagram (диаграмма классов), flow chart (блок-схема), sequence diagram (диаграмма последовательностей). Это прямая обязанность senior-разрабочиков, но могут делать и разработчики с меньшим опытом. Это даже приветствуется, так как позволяет хорошо погрузиться в задачу и изучить все ее тонкости. Что помогает найти в ТЗ какие-то недоработки, а также структурировать всю информацию по задаче. И мы стараемся учитывать кросс-платформенность нашего приложения — мы тесно работаем с Android-командой, рисуя одну схему на две платформы и стараясь использовать основные общепринятые паттерны проектирования от «банды четырёх».
- Ревью архитектуры. Как правило, ревью и оценку проводит коллега из смежной команды.
- Реализация и тестирование на примере одного UI модуля.
- Масштабирование. Если тестирование проходит успешно, мы масштабируем архитектуру на все приложение.
- Рефакторинг. Чтобы проверить, не упустили ли мы что-нибудь.
Сейчас, после 5 месяцев разработки этого проекта, я могу показать весь наш процесс в три этапа: что было, как менялось и что получилось в результате.
Что было
Нашей отправной точкой была стандартная MVC архитектура — это связанные между собой слои:
- UI слой, полностью программно сверстанный с использованием Objective C;
- Класс презентации (модель);
- Сервисный слой, где мы работаем с сетью.
Activity indicator был расположен в том месте схемы, где мы держим пользователя в режиме ожидания — он хочет быстрого результата, но вынужден смотреть на какие-то лоадеры, индикаторы и прочие сигналы. Это было нашим слабым местом в user experience:
Переходный период
В переходный период мы должны были внедрить кэширование для экранов. Но так как приложение большое и содержит много legacy кода на Objective C, мы не можем просто взять и удалить все сервисы и модели, вставив Swift-код — мы должны учитывать, что параллельно с кэшированием у нас в разработке еще много других продуктовых задач.
Мы нашли безболезненный способ, как интегрироваться в текущий код максимально эффективно, ничего при этом не сломав, а первую итерацию провести максимально мягко. В левой части предыдущей схемы мы полностью убрали все, что связано с сетевыми запросами — по интерфейсу сервис теперь общается с DataSourceFacade. И сейчас это — фасад, с которым работает сервис. Он ждет от DataSource те данные, которые раньше получал от сети. А в самом DataSource скрыта логика по добыче этих данных.
В правой части схемы мы разбили получение данных на команды — паттерн Command нацелен выполнить какую-то базовую команду и получить результат. В случае iOS мы используем наследников NSOperation:
Каждая команда, которую вы здесь видите — это операция, в которой есть логическая единица ожидаемого действия. Это получение данных из БД (или сети) и сохранение этих данных в Core data. Или, например, главная задача AcquireCommand — это не только вернуть фасаду источник данных, но и дать нам возможность разрабатывать код таким образом, чтобы получать данные через фасад. То есть взаимодействие с операциями идет через данный фасад.
А основная задача операций — передать данные DataSource для DataSourceFacade. Конечно, мы выстраиваем логику так, чтобы как можно быстрее показать данные пользователю. Как правило, внутри DataSourceFacade у нас есть операционная очередь, где мы запускаем наши NSOperations. В зависимости от настроенных условий мы можем принять решение, когда показывать данные из кэша, а когда — получать из сети. При первом запросе источника данных в фасаде мы идем в БД Core data, достаем оттуда через FetchCommand данные (если они там есть) и моментально возвращаем их пользователю.
Одновременно запускаем параллельный запрос данных через сеть, и когда этот запрос выполняется, то результат приходит в базу данных, сохраняется в ней, и после мы получаем update нашего DataSource. Этот update попадает уже в UI. Так мы минимизируем время ожидания данных, а пользователь, получая их мгновенно, не замечает разницы. А обновленные данные он получит сразу, как база данных получит ответ от сети.
Как стало
К такой более лаконичной схеме мы идем (и придем в итоге):
Сейчас из этого у нас есть:
- UI слой,
- фасад, через который мы предоставляем наш DataSource,
- команда, которая этот DataSource вместе с updates возвращает.
Что такое DataSource и почему мы о нем так много говорим
DataSource — это объект, который предоставляет данные для слоя презентации и соответствует заранее определенному протоколу. А протокол должен быть подстроен под наш UI и предоставлять данные для нашего UI (неважно, для конкретного экрана или для группы экранов).
У DataSource, как правило, две основных обязанности:
- Предоставление данных для отображения в UI слое;
- Уведомление UI слоя об изменениях в данных и досылка необходимой пачки изменений для экрана, когда мы получаем уже обновление.
Мы у себя используем несколько вариантов DataSource, потому что у нас много Objective C legacy кода — то есть, мы не везде можем легко наш Swift’овый DataSource воткнуть. Еще мы пока не везде используем коллекции, но в будущем перепишем код именно для использования CollectionView экранов.
Пример одного из наших DataSource:
Это DataSource для коллекции (он так и называется CollectionDataSource) и это достаточно несложный класс с точки зрения интерфейса. Он принимает в себя коллекцию, настроенный fetchedResultsController и CellDequeueBlock. Где CellDequeueBlock — type alias, в котором мы описываем стратегию по созданию ячеек.
То есть мы создали DataSource и присвоили его коллекции, вызвав у fetchedResultsController performFetch, и дальше вся магия возложена на взаимодействие нашего класса DataSource, fetchedResultsController и возможность у делегата получать обновления из базы данных:
FetchedResultsController — сердце нашего DataSource. В документации Apple вы найдете много информации по работе с ним. Как правило, мы получаем все данные с его помощью — и новые данные, и данные, которые были обновлены или удалены. При этом мы параллельно запрашиваем данные из сети. Как только данные были получены и сохранились в БД, мы получили update у DataSource, и update пришел к нам в UI. То есть одним запросом мы и получаем данные, и показываем их в разных местах — классно, удобно, нативно!
И везде, где можно использовать уже готовые DataSource с таблицами или с коллекциями, мы это делаем:
В тех местах, где у нас много экранов и не используются таблицы и коллекции (а используется Objective C программная верстка), мы оцениваем, какие данные нам нужны для экрана, и через протокол описываем наш DataSource. После этого пишем фасад — как правило, это тоже публичный протокол Objective C, через который мы запрашиваем наш DataSource. А дальше уже идет вход в Swift’овый код.
Как только мы будем готовы перевести экран полностью в Swift-реализацию, достаточно будет убрать Objective C-обертку — и можно работать напрямую со Swift’овым протоколом, благодаря кастомному DataSource.
Сейчас мы используем три основных варианта DataSources:
- TableViewDatasource + cell strategy (стратегия по созданию ячеек);
CollectionViewDatasource + cell strategy (вариант с коллекциями);
CustomDataSource — кастомный вариант, его мы сейчас используем больше всего.
Результаты
После всех шагов по проектированию, реализации и взаимодействию с legacy кодом бизнес получил:
- Существенно повысилась скорость доставки данных до пользователя за счет кэширования — это, наверное, очевидный и логичный результат.
- Мы теперь на шаг ближе к парадигме offline first.
- Настроили процессы архитектурного кроссплатформенного ревью внутри iOS & Android команд — все причастные к этому проекту разработчики владеют информацией и легко обмениваются опытом между командами.
- Как бонус получили хорошую документацию к проекту за счет схем и описаний. Мы ее показываем нашим новым разработчикам, чтобы им было проще понять, как у нас проброшен мостик между legacy и новым кодом, и как работает сам процесс кэширования.
- Мы уложились в сжатые спортивные сроки, и это — на живом проекте. У нас получилось, условно говоря, провести ремонт, никого не выселяя из офиса, но все продолжали работать, и даже не дышали строительной пылью.
Для нас бонусом стало то, что мы поняли, как работа с архитектурой и схемами может быть интересной и увлекательной (а это упрощает разработку). Да, мы потратили много времени на то, чтобы отрисовать и согласовать наши архитектурные подходы, но когда дошло до реализации, мы отмасштабировались очень быстро по всем экранам.
Наш путь в Offline first продолжается — нам нужно, чтобы не только кэширование было оффлайн, но и пользователь мог дейстововать без подключения к сети, с дальнейшей синхронизацией с сервером после появления интернета.
Ссылки
- Document-based programming guide. Это довольно старый документ, Apple его уже не рекомендует использовать. Но я бы порекомендовал посмотреть хотя бы для дополнительного развития. Там очень много полезной информации.
- Document-based WWDC: первый и второй
- DataSources