Стремительно и неотвратимо приближается ключевое событие года в области Data Science: конференция NIPS 2020, запланированная на 6-12 декабря 2020. Традиционно на самом масштабном событии года будут представлены значимые результаты, свежие идеи и перспективные подходы в различных областях Data Science, в том числе и в области математической обработки и понимания естественного языка. Каждому специалисту хочется если и не предложить новаторскую идею, то оказаться ранним последователем той идеи, которая «выстрелит», и не хочется попасть в хвост отстающих скептиков, которым приходится догонять и осваивать уже признанную большинством методику.
Полезным подходом для обнаружения перспективных идей на ранней стадии является мониторинг динамики в докладах на различных конференциях в течение года. С этой целью для сообщества Хабр был выполнен этот обзор самых ярких докладов в области NLP c конференции ICLR 2020, сделанный на основе перевода статьи Kamil Kaczmarek. Мы вернемся на несколько месяцев в Прошлое, чтобы затем на NIPS 2020 заглянуть в Будущее развития технологий по работе с текстами.
Если вам интересна тема NLP, вы хотите легко находить общий язык с моделями, непринужденно общаться сдевушками на улице передовыми специалистами и не отстать от быстрого движения современного мира, то вам может помочь эта статья. Поехали!
 Источник
Источник
В начале мая 2020 прошла International Conference on Learning Representations (ICLR). Это мероприятие, посвященное исследованиям всех аспектов обучения представлениям, широко известным, как Deep Learning. В этом году мероприятие было немного другим, так как оно стало виртуальным из-за пандемии коронавируса, однако онлайн-формат не изменил прекрасной атмосферы. Конференция была весьма увлекательной и привлекла 5600 специалистов со всего мира (вдвое больше, чем в прошлом году).
Более 1300 спикеров представили множество интересных докладов, поэтому было решено написать серию постов в блоге, обобщающих лучшие из работ по четырем основным направлениям. Вы можете ознакомиться в первом посте с лучшими работами по глубокому обучению здесь, во втором посте — со статьями по обучению с подкреплением здесь, а в третьем — с работами по генеративным моделям здесь.
Текущий пост является последним в серии, и в нем описываются 10 лучших вкладов в обработку/понимание естественного языка от ICLR.

Новый предобученный метод, достигающий самых передовых оценок на GLUE, RACE и SQuAD тестах, при этом оперирующий меньшим набором параметров по сравнению с BERT-large.
Документ / Код
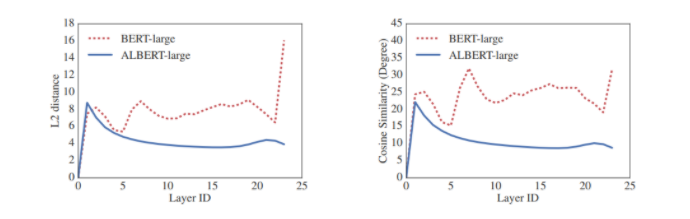
Расстояния L2 и косинусная близость (в терминах степени) входящих и исходящих эмбеддингов каждого слоя для BERT-large и ALBERT-large.
Автор: Чжэньчжун Лан
Представление слов является типичной задачей в NLP. В своей работе авторы заявляют о новом фреймворке, сочетающем классические методы получения эмбеддингов слов (например, Skip-gram) с более современными подходами, основанными на контекстных моделях получения эмбеддингов (BERT, XLNet).
Документ
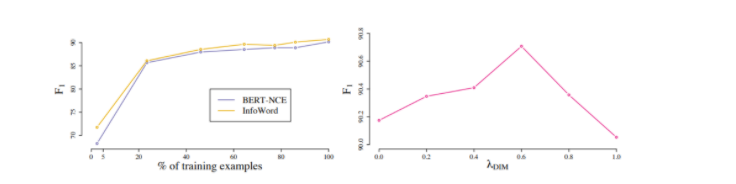
Левый график показывает рост F1 меры BERT-NCE и INFOWORLD по мере того, как увеличивается доля объектов в тренировочной выборке в SQuAD (dev). Правый график показывает изменение F1 меры INFOWORD на SQuAD (dev) в зависимости от ?DIM.
Автор: Лингпенг Конг
Модификация LSTM для получения передовых результатов в области языковых моделей.
Документ
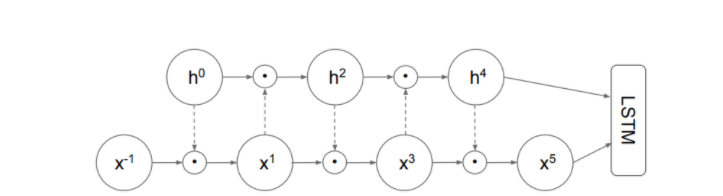
Mogrifier с 5 этапами обновлений весов. Предыдущее состояние h0 = hprev преобразуется линейно (пунктирные стрелки), подается через сигмовидную функцию в гейт x-1 = x поэлементно и образует x1. В обратную сторону, линейно преобразованный x1 проходит через гейт h0 и образует h2. После нескольких повторений описанного цикла взаимного пропускания полученные значения последовательностей h? и x? подаются в ячейку LSTM. Индекс prev в h опущен, чтобы избежать нагромождения.

Автор: Габо Мели
Авторы представляют GAN-TTS, генерирующую состязательную сеть (GAN) для преобразования текста в речь, значение Mean Opinion Score (MOS) которой достигает 4.2.
Документ / Код
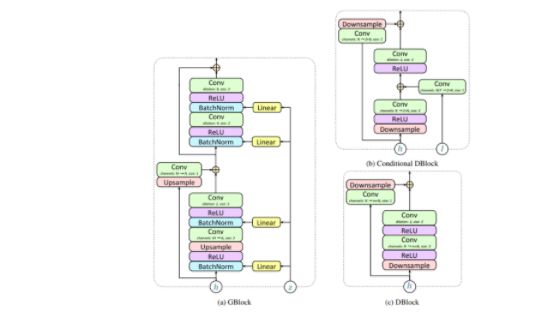
В модели используются residual блоки. Сверточные слои имеют одинаковое количество входных и выходных каналов и не расширяются, если не указано иное. h — представление скрытого слоя, l – лингвистические признаки, Z – вектор шума, m – канальный множитель, m = 2 для блоков понижающей дискретизации (т. е. если их коэффициент понижающей дискретизации больше 1) и m = 1 в противном случае, входные каналы M — G, M = 2N в блоках 3, 6, 7 и M = N в противном случае; размер подразумевает размерность ядра.

Автор: Миколай Биньковский
Эффективный трансформер с локально-чувствительным хешированием и реверсивными слоями.
Документ / Код
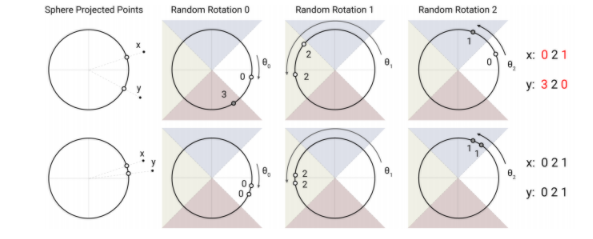
Хэш, чувствительный к угловой локализации, использует случайные вращения сферически проецируемых точек для установления блоков с помощью argmax-функции над знаками осей проекций. В этом сильно упрощенном 2D-изображении две точки x и y вряд ли будут иметь одинаковые хэш-блоки (вверху) для трех различных угловых хэшей, если только их сферические проекции не будут близки друг к другу (внизу).

Авторы: Никита Китаев и Лукаш Кайзер
DeFINE использует глубокую, иерархическую, разреженную сеть с новыми skip-соединениями, чтобы эффективно обучать эмбеддинги слов.
Документ
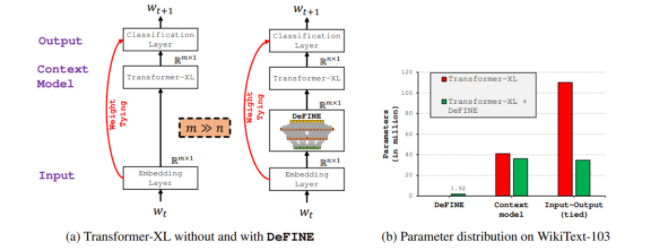
С помощью DeFINE сеть Transformer-XL обучается входящим (эмбеддинги) и исходящим (классификация) представлениям в пространстве малой размерности n, в отличии от пространства высокой размерности m, что позволяет значительно снизить количество параметров и при этом получить минимальное влияние на эффективность.
Автор: Сачин Мехта
Модель работы с последовательностями, динамически регулирующая объем вычислений для каждого ввода.
Документ
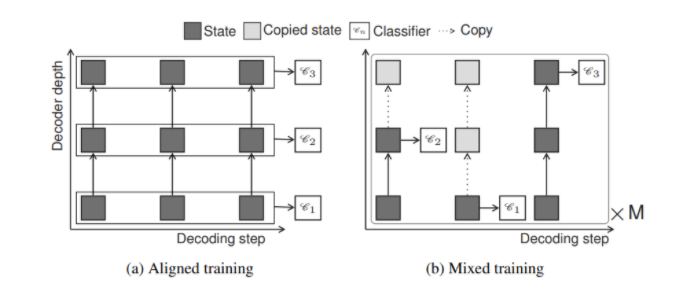 Aligned training — согласованное обучение, Mixed training — смешанное обучение
Aligned training — согласованное обучение, Mixed training — смешанное обучение
Для декодирующих сетей в процессе обучения есть возможность работы с данными на любом слое. Режим согласованного обучения оптимизирует все классификаторы на выходе Cn одновременно, предполагая, что все предыдущие скрытые состояния для текущего слоя известны. В режиме смешанного обучения происходит сэмплирование M путей из случайных выходов модели; отсутствие информации о прошлых скрытых состояниях компенсируется путем копирования из предыдущего слоя.

Автор: Маха Элбаяд
Авторы исследуют возможность раздельной оценки различных параметров и интерпретируемости attention-а и токенов для контекстуальных эмбеддингов в модели Bert-a, основанной на self-attention.
Документ
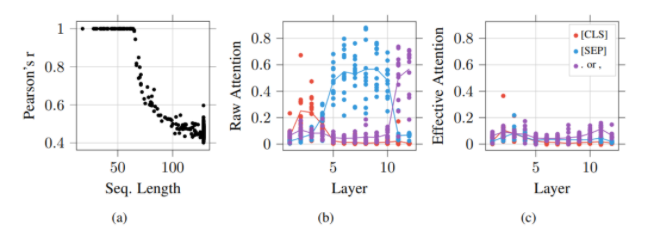
(а) каждая точка представляет собой коэффициент корреляции Пирсона между актуальным attention и сырым attention как функцию размера токена. (b) зависимость необработанного значения attention и © эффективного attention, где каждая точка представляет усредненное (эффективное) attention данной head к типу токена.

Автор: Гино Бруне
Подходы к переводу, известные как модели Neural Machine Translation (NMT), сильно зависят от наличия обширного корпуса, построенного в виде языковой пары. Авторами предлагается новый метод перевода в обоих направлениях с использованием архитектуры на основе генеративной нейронной сети.
Документ
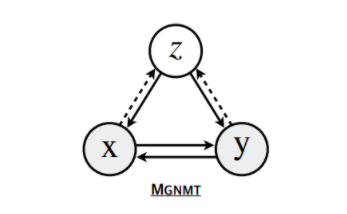
Схематическая модель MGNMT
Автор: Зайсян Чжэн
Авторы предлагают новый алгоритм, который по-новому формализует подход к обучению состязательной сети для тренировки языковой модели. Новый подход получил название FreeLB.
Документ / код


Автор: Чен Чжу
Глубина и качество публикаций ICLR весьма впечатляют. Согласно анализу, ключевые направления, представленные на ICLR-2020, выглядят следующим образом:
Спасибо, что дочитали пост до конца. Он посвящен теме обработки естественного языка, которая является одним из основных направлений конференции ICRL. Необходимо отметить, что подавать доклад на ICRL необходимо более, чем за 6 месяцев до самой конференции, поэтому часть материала к моменту докладов устаревает и отражает только актуальный срез развития области с опозданием на полгода. Тем не менее, даже с опозданием, представленный материал вызывает большой интерес для исследователей и специалистов.
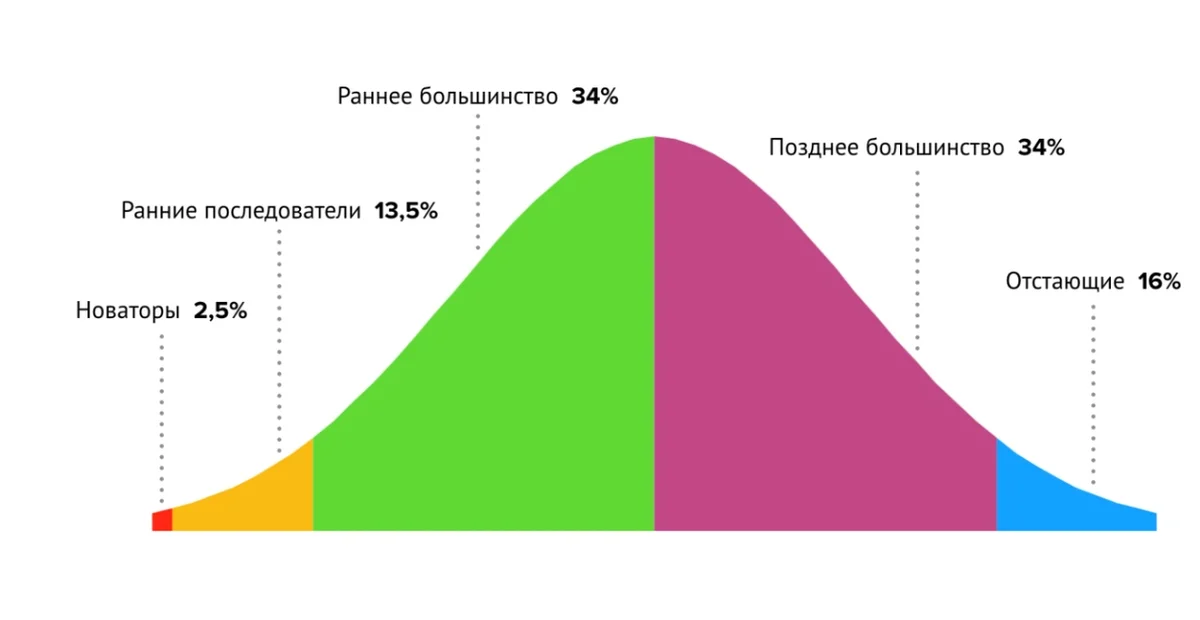
Ученые и энтузиасты области Data Science подвержены такому же делению на типы последователей, как и пользователи стартап-продуктов: крупные конференции и международные ассамблеи играют ту же роль, что и битвы стартапов, эти мероприятия помогают привлечь больше последователей и расширить свою аудиторию.
 Мы в компании CleverData давно следим за ICLR и рады поделиться с вами интересными находками и идеями, представленными в серии статей. Надеюсь, что подготовленный материал поможет обнаружить на раннем этапе перспективные подходы, взять их на вооружение и стать их ранним последователем. Если вас заинтересовал текущий обзор, то могут показаться интересными и другие статьи, посвященные ICLR этого и прошлого года. Вы можете прочитать их здесь и здесь.
Мы в компании CleverData давно следим за ICLR и рады поделиться с вами интересными находками и идеями, представленными в серии статей. Надеюсь, что подготовленный материал поможет обнаружить на раннем этапе перспективные подходы, взять их на вооружение и стать их ранним последователем. Если вас заинтересовал текущий обзор, то могут показаться интересными и другие статьи, посвященные ICLR этого и прошлого года. Вы можете прочитать их здесь и здесь.
Буду рад обсудить написанное в комментариях.
Полезным подходом для обнаружения перспективных идей на ранней стадии является мониторинг динамики в докладах на различных конференциях в течение года. С этой целью для сообщества Хабр был выполнен этот обзор самых ярких докладов в области NLP c конференции ICLR 2020, сделанный на основе перевода статьи Kamil Kaczmarek. Мы вернемся на несколько месяцев в Прошлое, чтобы затем на NIPS 2020 заглянуть в Будущее развития технологий по работе с текстами.
Если вам интересна тема NLP, вы хотите легко находить общий язык с моделями, непринужденно общаться с
В начале мая 2020 прошла International Conference on Learning Representations (ICLR). Это мероприятие, посвященное исследованиям всех аспектов обучения представлениям, широко известным, как Deep Learning. В этом году мероприятие было немного другим, так как оно стало виртуальным из-за пандемии коронавируса, однако онлайн-формат не изменил прекрасной атмосферы. Конференция была весьма увлекательной и привлекла 5600 специалистов со всего мира (вдвое больше, чем в прошлом году).
Более 1300 спикеров представили множество интересных докладов, поэтому было решено написать серию постов в блоге, обобщающих лучшие из работ по четырем основным направлениям. Вы можете ознакомиться в первом посте с лучшими работами по глубокому обучению здесь, во втором посте — со статьями по обучению с подкреплением здесь, а в третьем — с работами по генеративным моделям здесь.
Текущий пост является последним в серии, и в нем описываются 10 лучших вкладов в обработку/понимание естественного языка от ICLR.
1. АЛЬБЕРТ: облегченный BERT для самостоятельного изучения языковых представлений
Новый предобученный метод, достигающий самых передовых оценок на GLUE, RACE и SQuAD тестах, при этом оперирующий меньшим набором параметров по сравнению с BERT-large.
Документ / Код
Расстояния L2 и косинусная близость (в терминах степени) входящих и исходящих эмбеддингов каждого слоя для BERT-large и ALBERT-large.
Автор: Чжэньчжун Лан
2. A Mutual Information Maximization Perspective of Language Representation Learning
Представление слов является типичной задачей в NLP. В своей работе авторы заявляют о новом фреймворке, сочетающем классические методы получения эмбеддингов слов (например, Skip-gram) с более современными подходами, основанными на контекстных моделях получения эмбеддингов (BERT, XLNet).
Документ
Левый график показывает рост F1 меры BERT-NCE и INFOWORLD по мере того, как увеличивается доля объектов в тренировочной выборке в SQuAD (dev). Правый график показывает изменение F1 меры INFOWORD на SQuAD (dev) в зависимости от ?DIM.
Автор: Лингпенг Конг
3. Mogrifier LSTM
Модификация LSTM для получения передовых результатов в области языковых моделей.
Документ
Mogrifier с 5 этапами обновлений весов. Предыдущее состояние h0 = hprev преобразуется линейно (пунктирные стрелки), подается через сигмовидную функцию в гейт x-1 = x поэлементно и образует x1. В обратную сторону, линейно преобразованный x1 проходит через гейт h0 и образует h2. После нескольких повторений описанного цикла взаимного пропускания полученные значения последовательностей h? и x? подаются в ячейку LSTM. Индекс prev в h опущен, чтобы избежать нагромождения.
Автор: Габо Мели
4. Высокоточный синтез речи с помощью состязательных сетей
Авторы представляют GAN-TTS, генерирующую состязательную сеть (GAN) для преобразования текста в речь, значение Mean Opinion Score (MOS) которой достигает 4.2.
Документ / Код
В модели используются residual блоки. Сверточные слои имеют одинаковое количество входных и выходных каналов и не расширяются, если не указано иное. h — представление скрытого слоя, l – лингвистические признаки, Z – вектор шума, m – канальный множитель, m = 2 для блоков понижающей дискретизации (т. е. если их коэффициент понижающей дискретизации больше 1) и m = 1 в противном случае, входные каналы M — G, M = 2N в блоках 3, 6, 7 и M = N в противном случае; размер подразумевает размерность ядра.
Автор: Миколай Биньковский
5. Reformer: The Efficient Transformer
Эффективный трансформер с локально-чувствительным хешированием и реверсивными слоями.
Документ / Код
Хэш, чувствительный к угловой локализации, использует случайные вращения сферически проецируемых точек для установления блоков с помощью argmax-функции над знаками осей проекций. В этом сильно упрощенном 2D-изображении две точки x и y вряд ли будут иметь одинаковые хэш-блоки (вверху) для трех различных угловых хэшей, если только их сферические проекции не будут близки друг к другу (внизу).
Авторы: Никита Китаев и Лукаш Кайзер
6. DeFINE: Deep Factorized Input Token Embeddings for Neural Sequence Modeling
DeFINE использует глубокую, иерархическую, разреженную сеть с новыми skip-соединениями, чтобы эффективно обучать эмбеддинги слов.
Документ
С помощью DeFINE сеть Transformer-XL обучается входящим (эмбеддинги) и исходящим (классификация) представлениям в пространстве малой размерности n, в отличии от пространства высокой размерности m, что позволяет значительно снизить количество параметров и при этом получить минимальное влияние на эффективность.
Автор: Сачин Мехта
7. Глубинно-адаптивный трансформер
Модель работы с последовательностями, динамически регулирующая объем вычислений для каждого ввода.
Документ
Для декодирующих сетей в процессе обучения есть возможность работы с данными на любом слое. Режим согласованного обучения оптимизирует все классификаторы на выходе Cn одновременно, предполагая, что все предыдущие скрытые состояния для текущего слоя известны. В режиме смешанного обучения происходит сэмплирование M путей из случайных выходов модели; отсутствие информации о прошлых скрытых состояниях компенсируется путем копирования из предыдущего слоя.
Автор: Маха Элбаяд
8. О возможности раздельной оценки различных параметров в трансформерах
Авторы исследуют возможность раздельной оценки различных параметров и интерпретируемости attention-а и токенов для контекстуальных эмбеддингов в модели Bert-a, основанной на self-attention.
Документ
(а) каждая точка представляет собой коэффициент корреляции Пирсона между актуальным attention и сырым attention как функцию размера токена. (b) зависимость необработанного значения attention и © эффективного attention, где каждая точка представляет усредненное (эффективное) attention данной head к типу токена.
Автор: Гино Бруне
9. Mirror-Generative Neural Machine Translation
Подходы к переводу, известные как модели Neural Machine Translation (NMT), сильно зависят от наличия обширного корпуса, построенного в виде языковой пары. Авторами предлагается новый метод перевода в обоих направлениях с использованием архитектуры на основе генеративной нейронной сети.
Документ
Схематическая модель MGNMT
Автор: Зайсян Чжэн
10. FreeLB: продвинутое обучение состязательных сетей для NLU
Авторы предлагают новый алгоритм, который по-новому формализует подход к обучению состязательной сети для тренировки языковой модели. Новый подход получил название FreeLB.
Документ / код
Автор: Чен Чжу
Заключение
Глубина и качество публикаций ICLR весьма впечатляют. Согласно анализу, ключевые направления, представленные на ICLR-2020, выглядят следующим образом:
- глубокое обучение;
- обучение с подкреплением;
- генеративные модели;
- NLP/NLU (что и является основным предметом текущей статьи).
Эпилог
Спасибо, что дочитали пост до конца. Он посвящен теме обработки естественного языка, которая является одним из основных направлений конференции ICRL. Необходимо отметить, что подавать доклад на ICRL необходимо более, чем за 6 месяцев до самой конференции, поэтому часть материала к моменту докладов устаревает и отражает только актуальный срез развития области с опозданием на полгода. Тем не менее, даже с опозданием, представленный материал вызывает большой интерес для исследователей и специалистов.
Ученые и энтузиасты области Data Science подвержены такому же делению на типы последователей, как и пользователи стартап-продуктов: крупные конференции и международные ассамблеи играют ту же роль, что и битвы стартапов, эти мероприятия помогают привлечь больше последователей и расширить свою аудиторию.
Буду рад обсудить написанное в комментариях.
У нас есть вакансии! Может быть, мы ищем именно вас?