
(Корень всех зол в data engineering лежит в излишне сложном конвейере обработки данных)
Исторический контекст
Разработка конвейера данных достаточно серьезная задача, а с учетом областей с огромными объемами данных, эта сложность многократно увеличивается. Инструменты и концепции, связанные с большими данными, начали развиваться примерно в начале 2000-х годов, когда масштабы и скорость интернета резко начали возрастать. Компании внезапно обнаружили, что им приходится иметь дело с огромными объемами и скоростью передачи данных. Возможно, одним из пионеров в этой области был Google, инженеры которого боролись с поисковым сканером и индексатором. По сути это по, которое в то время лежало в основе поисковика Google. Поскольку количество веб-сайтов и страниц астрономически росло, Google не мог решить, как масштабировать свой сканер/индексатор, используя существующие вычислительные ресурсы, которые были распределены географически. Ни одна из коммерческих баз данных или технологий в то время не могла масштабироваться быстро и с минимальными затратами, и обе эти технологии были необходимы Google для масштабирования своего основного продукта.
Двое программистов из Google решили эту проблему в течение четырех месяцев в 2003 году и изобрели парадигму Map Reduce для эффективного распределения обработки данных по кластеру вычислительных ресурсов. У Google был целый парк обычных серверов, некоторые из которых рандомно выходили из строя. Платформа Map Reduce была отказоустойчивой к таким сбоям. Вскоре сканер/индексатор был написан с использованием этой парадигмы, которая оказалась чрезвычайно эффективной, и как только инженеры осознали, насколько она мощна, все захотели использовать эту новую структуру. Пара программистов написала статью об этом новом алгоритме и обнародовала ее. Это было пропитано другими инженерами отрасли, и один из них, Дуг Каттинг, создал проект с открытым исходным кодом под названием Hadoop, используя парадигму Map Reduce. Вскоре Hadoop стал использоваться такими компаниями, как Yahoo, Facebook, Netflix, и оказался на порядок эффективнее и дешевле при крупномасштабной обработке данных. Наконец-то наступила эпоха больших данных!
Эволюция баз данных
I. RDBMS
Технология реляционных баз данных была изобретена в начале 1970-х годов инженерами IBM Research, которые использовали реляционную модель данных как способ доступа к данным без специального обучения математике или программированию. Системы управления реляционными базами данных (СУБД) с годами превратились в критически важную и многофункциональную технологию, способную эффективно поддерживать потребности бизнеса. Однако ключевым узким местом в этих системах является то, что почти все эти базы данных при ответе на запрос пользователя выполняют чтение с диска (которое происходит медленно) и помещают все данные в буфер памяти, а затем выполняют объединения и другие условия фильтрации. В случае нескольких запросов каждый запрос будет конкурировать (и ждать) за вычислительные ресурсы на основе алгоритма СУБД. По мере того, как объемы данных увеличивались и многие возможности были использованы (например, повторное использование данных в буфере, параллельная обработка и т. д.), то существенные ограничения этого подхода быстро стали очевидными.
II. MPP
Следующим этапом эволюции стал уровень баз данных MPP (массовая параллельная обработка). В этих системах вместо одного буфера памяти и дисковой архитектуры система была разбита на несколько мини-вычислительных блоков, каждая со своим собственным ЦП / памятью / диском. Каждая вычислительная единица будет работать независимо с данными, необходимыми для данного запроса запроса, которые разбиты на несколько частей и переданы в эти единицы. Эта архитектура «без общего доступа» распараллелила операции и значительно повысила пропускную способность. Впервые эта технология была коммерциализирована компанией Netezza в начале 2000-х годов. Однако у этого подхода было два явных недостатка:
- эти устройства MPP, продаваемые такими компаниями, как Oracle, Teradata, Netezza и т.д., были крайне дорогими;
- масштабирование по-прежнему было проблемой, вы могли купить самое большое устройство (и масштабировать его по вертикали), однако не было простого способа горизонтально масштабироваться, то есть добавить больше вычислений или хранилища к существующему устройству.
Для таких компаний как Google, для которых масштаб и экономическая эффективность были критически важными критериями, этот вариант не подходил. А небольшие компании в принципе не могли себе это позволить из-за высокой цены.
III. MPP-Columnar
Зачем хранить данные в формате последовательных строк, если все, что вам нужно, — это несколько столбцов или агрегированные результаты. Столбчатые базы данных хранят данные в блоках столбцов, а не в блоках строк. Это приводит к гораздо лучшему сжатию, так как большинство значений столбцов имеют один и тот же тип и сокращают ввод-вывод. Некоторые MPP, такие как Redshift / Teradata, с большим успехом объединили столбчатую архитектуру с MPP.
IV. Distributed FS
Hadoop с открытым исходным кодом решил обе проблемы из области MPP. Работая на платформе MapReduce, он распараллеливает операции и в то же время работает на дешевых обычных серверах, позволяет вам начинать со сколь угодно малых размеров и позволяет добавлять узлы по горизонтали по мере роста вашего бизнеса. Это положило конец гегемонии поставщиков баз данных, поскольку компании расширили свою инфраструктуру Hadoop и начали обрабатывать огромные объемы данных. И снова были две ключевые проблемы, которые побудили к следующему этапу эволюции.
- Парадигма MapReduce была написана Java-разработчиками, и было очень затратно писать подробные Java-программы для простых операций с базами данных (примерно в 2010 году Facebook изобрел Hive — интерфейс SQL поверх MapReduce для решения этой проблемы). Кроме того, внедрение кластеров Hadoop и управление ими может стать сложным процессом и потребовать большой команды инженеров-разработчиков.
- MapReduce также использует чтение с диска (хотя и параллельно), которое в целом является медленным.
V. Distributed In-Memory Data Processing/Query Engines
Дальнейшее развитие привело к обработке данных в памяти с использованием распределенной среды. В нем было лучшее из обоих миров — отсутствие чтения с диска и удобный интерфейс SQL. Наконец, появилась технология, которая была быстрой, как MPP, простой, как РСУБД, и масштабируемой, как Hadoop. Лидерами в этой области были Spark в качестве механизма обработки данных и Impala / Presto в качестве механизма запросов. Одной из проблем, которые все еще мучили, были проблемы с установкой и управлением кластерами в оперативной памяти и другими связанными задачами разработки.
VI. Cloud Based Distributed In-Memory Engines
Поставщики облачных услуг, такие как AWS, Azure и т.д. и другие компании, работающие с большими данными как услуга, предлагают модели SaaS / PaaS, которые скрывают операционные детали для управления механизмами в памяти и предлагают возможность масштабирования вверх или вниз в зависимости от запроса. Они предлагают множество дополнительных услуг, таких как хранилище файлов, аварийное восстановление, балансировка нагрузки, автоматическое резервное копирование, автоматическое обслуживание и т.д., что позволяет компаниям сосредоточиться на своих основных задачах, а не бороться с деталями инфраструктуры. Это было с энтузиазмом воспринято стартапами и множеством малых и средних предприятий, которые хотят начинать с малого, сохранять низкие затраты и не иметь большого штата разработчиков. Неудивительно, что в последние годы облачная модель резко стала популярна, и ее часто рекламируют как направление будущего.
Вызовы
Когда компания решает сместить акцент на большие данные, обычно происходит следующее:
- Инженеры и архитекторы в восторге от нового проекта Big Data.
- Организовываются тренинги (онлайн или оффлайн), изучаются книги и статьи в интернете на предмет последних предложений и лучших отраслевых практик.
- Принимаются решения относительно хостинга, типов используемых баз данных (NoSQL или столбчатая), приложений которые надо создавать(Java или Python), как осуществлять доступ к данным, как автоматизировать мониторинг и оповещения.
- Проект запускается, и вскоре данные будут передаваться по конвейеру через различные части программного обеспечения. Там может быть Hadoop или Spark, что-то вроде хранилища NoSQL, тысячи строк кода приложения генерируют сотни предупреждений, и ни одна из этих частей не задокументирована.
- Вскоре возникают проблемы с данными, разработчики проводят ночи и выходные, разбираясь во всем. Большая часть данных располагается в файлах, поэтому ни один из аналитиков данных и бизнес-аналитиков не имеет ни малейшего понятия что происходит и не может предоставить какую-либо помощь.
- Каждый новый функционал программного обеспечения требует резервного копирования, аварийного восстановления, возможности обновления без ущерба для бизнеса, поддержки разработчиков, возможности беспрепятственно взаимодействовать с другими частями сисетмы. Большинство из этих фич не были приоритетными и были созданы второпя.
- Продажники объявляют о подписании договора с сжатыми сроками поставки (сюрприз). Новые проблемы охватывают инженеров по запуску конвейеров больших данных для нового клиента, у которого, похоже, совершенно другие потребности.
- Ключевой ресурс (или два) уходит, менеджеры теперь опасаются беспокоить оставшихся людей, которые полностью понимают основные системы. Приглашаются новые люди. Встречи по планированию и митинги проходят как нескончаемая рутинная работа.
Цели
У меня более 20 лет опыта в создании хранилищ данных, конвейеров ETL, приложений на основе данных и, конечно же, экосистемы больших данных. В следующих нескольких разделах я расскажу, как построить эффективную «вселенную больших данных» для достижения следующих целей:
- Масштабируемость — добавление нового функционала не должно вызывать панику, все должно быть спроектировано с учетом дальнейшего расширения функциональных возможностей и данных.
- Производительность — Загрузка данных и доступ к ним для всех заинтересованных сторон должны быть адекватными. Примечание для менеджмента: для обеспечения сверхвысокой производительности может потребоваться больше инвестиций в технический стек.
- Техническое обслуживание — Технологический стек и инфраструктура должны обеспечить легкую поддержку и возможность обновлений. Команды разработчиков не должны страдать из-за вещей, касающихся dev-ops.
- Проблемы с данными — Любой человек в команде (включая QA, аналитика данных и дата сайнтиста) должен иметь возможность проанализировать проблему производственных данных и решить ее эффективно, без разрозненности или незаменимых членов команды.
- Повторы — Все должно быть написано с учетом того, что данные могут оказаться плохими и их можно будет исправить. Без или с минимальным ручным участием при повторах.
- Отсутствие разрозненности экспертизы — Каждый инженер по обработке данных должен уметь работать со всеми частями продукта, и при этом работать продуктивно. Процесс должен быть последовательным и простым.
- Мониторинг и оповещения — Поток данных следует отслеживать и генерировать разумное количество значимых оповещений (не слишком много и не слишком мало).
Архитектура и дизайн
1. Сокращение сложности (минимизация написания кода приложений для перемещения данных)
Как показывает опыт, построить сложное решение относительно проще, однако именно простота требует глубоких размышлений.
Эта мысль прекрасным образом касается построения конвейеров данных, которые традиционно включают в себя написание фрагментов кода для извлечения, преобразования и загрузки (ELT) данных и передачу этого конвейера в data lakes и data warehouses. Если ваша команда имеет привычку писать каждое задание ETL с использованием программного языка, вы вскоре будете управлять библиотекой кода, состоящей из (но не ограничиваясь) кода для задач, основных общих функций, кода для имитации функций базы данных, таких как агрегирование, объединения и т.д., создание инфраструктуры для оркестровки заданий ETL, создание шаблонного кода для подключения к разнородным источникам данных, ограничение безопасного доступа и множество других вещей. Ваша основная работа может превратиться в управление этим монстром, а не в понимание вашей основной структуры данных и размышление о решении следующего набора проблем с данными.
Есть два выхода из этой головоломки:
a. Buy Strategy
В сфере больших данных произошел взрывной рост «готовых инструментов интеграции данных», единственная цель которых — собирать данные и события из всех мыслимых источников и доставлять их в вашу зону подготовки. В процессе эти инструменты могут реплицировать, очищать, преобразовывать, дедуплицировать, сортировать и выполнять другие функции обработки данных. Большинство этих инструментов могут взаимодействовать с API-интерфейсами, потоками, IoT, мобильными устройствами, файлами, базами данных, практически со всем, что может генерировать событие или запись либо в облаке, либо на своих машинах. Кроме того, у них есть драйверы и плагины для большинства распространенных инструментов, используемых в отрасли, что упрощает интеграцию. Некоторые из распространенных инструментов ETL:
- Snowplow Analytics
- Stitch Data
- Five Tran
Все это предложения SaaS, доступные за небольшую ежемесячную плату.
b. Build Strategy
Если у вас есть опытная команда инженеров данных и вы живете с мыслью об уменьшении сложности, я бы порекомендовал другой класс инструментов, которые предоставляют красивую оболочку графического интерфейса для записи преобразований и имеют встроенную поддержку для всех повседневных задач, таких как открытие и чтение файлов, копирование данные, просмотр фрагмента кода, запуск и расписанию и т.д.
- Pentaho Data Integration (известная как Kettle)
- DBT (Data Build Tool)
- Python — лаконичный язык для обертки вашего движка преобразований (будет обсуждаться в следующем разделе)
Следуйте принципу DRY
Принцип DRY в разработке программного обеспечения означает «не повторяйся», основная цель которого — уменьшить повторение кода и повысить удобство сопровождения. Парадигма в индустрии больших данных смещается от написания громоздких MapReduce к минимизации написания кода приложений. И это имеет смысл, поскольку из-за стремительного роста количества источников данных, которые генерируют данные, и количества доступных баз данных и инструментов, которые могут потреблять данные, это сведет всех с ума (и сорвет проекты), если мы не будем хорошо управлять сложностью.
Оркестрация задач
Не пишите код для планирования заданий, определения зависимостей, мониторинга и т.д. Это различные инструменты, доступные на рынке, которые предоставляют эту функцию в готовом виде. Они могут быть не с открытым исходным кодом, и стоит потратить деньги на такого рода инструменты (например, Control-m), а не на создание библиотеки повторяющегося кода, что является утомительной работой, и никто не захочет ее поддерживать.
Совет №1: больше кода приложений = больше сложности
Совет №2: не пишите ни одной строчки кода, который кто-то уже написал и запаковал.
2. Используйте базы данных и SQL в качестве основного механизма преобразования конвейера больших данных
С каждым новым развитием технологии баз данных люди предсказывали смерть SQL, и какое-то время казалось, что с появлением баз данных Hadoop и NoSQL они могут оказаться правы. Однако со временем выяснилось, что у использования NoSQL есть несколько недостатков:
- Каждая база данных NoSQL предлагает свой собственный уникальный язык запросов, который требует времени и усилий, чтобы изучить и проповедовать
- Написание неуклюжих Java или других языков приложений для выполнения задач ETL увеличивает сложность и создает барьер для входа для разработчиков
- Для подключения приложений, использующих эти NoSQL, требуется тонна хрупкого связующего кода, который может создать византийскую структуру.
- Отсутствие экосистемы, поддерживающей все эти технологии, требует большого количества кастомной разработки
- Недостаточная зрелость (по сравнению с SQL) в языках NoSQL
Было время, когда инженеры думали, что работа во вселенной больших данных означает отказ от SQL и написание большого количества кода, не беспокоясь слишком много о модели данных (без использования схемы) и других деталях. Я бы сказал, наоборот, что с большими данными моделирование ваших данных и правильное проектирование ETL еще более важно, и мы обсудим эти детали в следующих разделах.
Современные базы данных имеют невероятное количество функций, встроенных в SQL, таких как лямбда-функции, карты, строка в столбец (и наоборот), геопространственные функции, аналитические функции, приближения, статистический анализ, функции сопоставления и сокращения, раскрытие предикатов и т.д. любой бизнес-сценарий, и я бы сказал, что 98% бизнес-проблема можно выразить в SQL, а для оставшейся части вы можете определить UDF (на таком простом языке, как Python) и использовать в своей функции SQL.
Вот некоторые из лучших практик использования баз данных / SQL:
- а. Вся бизнес-логика и преобразования должны быть написаны на SQL. Вы можете обернуть SQL в Python или инструмент ETL по вашему выбору для сервисных задач (ведение логов, исключения и т.д.)
- б. Для сложных функциональных вариантов использования разбейте SQL либо на серию CTE (общее табличное выражение), либо разбейте запрос, загрузив данные в промежуточную таблицу (метод, называемый ELT: извлечение, загрузка и затем преобразование)
- c. Используйте механизм обработки данных в памяти, такой как Spark, для сверхмощного ETL и механизм запросов в памяти, такой как Presto, для доступа к данным. Оба имеют встроенную поддержку SQL
- d. Используйте инструменты интеграции ETL, чтобы получить данные в промежуточной области, а затем использовать SQL для выполнения преобразований и загрузки в окончательное хранилище или витрину данных.
Преимущества подхода с использованием базы данных / SQL:
- SQL содержит предварительно построенный синтаксис для инкапсуляции сложной логики в мощные конструкции или встроенные функции. Это означает, что время разработки и тестирования значительно сокращается просто потому, что пишется значительно меньше строк кода, а SQL относительно прост для понимания и выполнения.
- Бизнес-логику кода можно просто изучить просмотрев SQL, нет необходимости следить и понимать сложный рабочий процесс прикладной программы. Это означает, что время изучения для новых членов команды значительно сокращается.
- Разработчик больше не является узким местом в случае возникновения проблем в логике. Любой инженер, аналитик, SDET, QA или технический специалист может понять преобразование, написанное на SQL, и помочь в воспроизведении проблемы и устранении неполадок. Одно только это стоит на вес золота, особенно в современных бережливых командах, где проблемы с данными клиентов требуют быстрого решения.
- Инженеры по данным не закапываются в управлении приложениями и другими деталями, они могут сосредоточиться на данных и лучше усвоить их структуры.
- Поддержание кода и управление им могут выполняться относительно небольшой командой.
Современный SQL чрезвычайно мощный, с каждым релизом добавляются новые функции. Например, для данного набора данных, если вы хотите перейти к предыдущей записи, вам придется написать сложную логику циклов и сортировки на языке приложения. В SQL это можно сделать с помощью однострочной конструкции:
lag(column_name) over (partition by household order by date desc)Индустрия в целом возвращается к SQL, лидером которой является Google. Мы успешно использовали эту парадигму, что привело к созданию стабильной и свободной от стресса среды больших данных.
Совет №3: Все преобразования и бизнес-логика должны быть написаны на SQL
Совет №4: Реализуйте разделение между хранением данных и вычислениями
3. Обеспечение качества данных
Обеспечение качества данных, проходящих по конвейерам и хранящихся в хранилищах и озерах данных, имеет большое значение. Если клиенты и конечные пользователи не могут доверять вашим данным, все остальное — вопрос спорный. Это единственный наиболее важный фактор, который определит, будет ли ваша платформа для анализа больших данных успешной или нет, и все же нет четких или простых формул для определения качества данных. Вот несколько рекомендаций о том, как обеспечить качество данных во вселенной больших данных.
а. Встроенная проверка в конвейере данных
Единственное, что хуже задержки данных, — это неверные данные. Доверие к производимым данным и их объединению в конвейер данных имеет первостепенное значение. Большие данные могут и должны быть проверены перед загрузкой в ??продакшн. В конце каждого конвейера должен быть построен A/B своп:
- Перед последним шагом в конвейере загрузите окончательные данные в промежуточные таблицы
- Выполните этапы встроенной проверки, которые основываются на модели данных. Эта модель позволяет вам определять любую проверку, написанную на SQL, и прикреплять ее к заданию ETL. Фреймворк будет читать мета-записи в конце каждого задания, выполнять их и сравнивать результаты с возможными значениями.
- Если какая-либо из проверок завершилась неудачно, задание завершится неудачно, в противном случае скопируйте данные из стадии стейджинга в продакшн.
- Управление этапами встроенной проверки с помощью архитектуры, основанной на метаданных (см. схему модели даты данных ниже)
- Автоматизируйте все
- Этапы валидации должны включать как проверки процесса (подсчет, дублирование и т.д.), так и функциональные проверки (имеют ли числа смысл, сравнение с известным набором и т.д.)
б. Создание тестовой среды для конвейера данных
Как и любая другая программная система, конвейеры данных постоянно развиваются и требуют частого развертывания и изменений в продакшн среде. В сложной конвейерной системе изменение одного задания потенциально может повлиять на несколько зависимых заданий и базовых таблиц, все из которых находятся в рабочем состоянии. Другими словами, одно изменение может привести к дестабилизации всего вашего конвейера, и поэтому мы должны быть уверены, что этого не произойдет, перед развертыванием в производственной среде.
Каждый конвейер данных проекта должен быть надежно проверен с помощью тестовых кейсов и регрессионного тестирования, чтобы скрыть любой потенциальный сбой. Сценарии тестирования могут быть определены на простом английском языке с использованием фреймворка Behavior Driven Development (BDD), который поддерживается предварительно созданными пакетами на Python, которые можно легко изменить, чтобы гарантировать, что все сценарии проверены перед развертыванием изменений.
Общие типы сценариев для создания тестовых кейсов
- Существуют ли база данных и все лежащие в ней таблицы (используемые в конвейере)?
- Все ли необходимые столбцы существуют с ожидаемым вами типом данных?
- Приближается ли количество данных, производимых конвейером, к (заранее определенному) порогу?
- Приводят ли преобразования тестовых данных к ожидаемым результатам?
Это дает большую уверенность в управлении инженерными работами, снижает количество ошибок и в целом создает плавный процесс разработки и развертывания.
Советы по построению песочниц:
- Создавайте и разворачивайте фреймворк из докер контейнеров, который содержит все базовые образы приложений, взаимодействующие друг с другом.
- Создавайте образцы тестовых данных для заданий ETL, которые позволят проверять все сценарии
- Напишите BDD для каждого ETL задания и кода на Python
- Изолируйте тестовые кейсы, выполняя их в песочнице из докер контейнеров
- Считать тестовый кейс провальным, если одни из тестов BDD не прошел, автоматизировав это в фреймворке
c. Создавайте дашборды для мониторинга и оповещений
Все ключевые структуры данных, должны отслеживаться на предмет трендов и аномалий. Создайте модель данных на основе метаданных, которая автоматически публикует метрики на информационной панели. Любой разработчик, аналитик, инженер по эксплуатации должен иметь возможность видеть новые метрики, просто добавляя новую запись в модель метаданных.
Дашборды должны быть настроены для отправки предупреждений при превышении порогового значения, которое может быть определено в метаданных.
Примеры метрик:
- Общее количество
- Количество на стандартную единицу (например, для семьи или клиента)
- Анализ трендов с использованием данных временных рядов для исторической загрузки
- Любые показатели, необходимые для бизнеса
- Обнаружение аномалий
Образец модели данных:
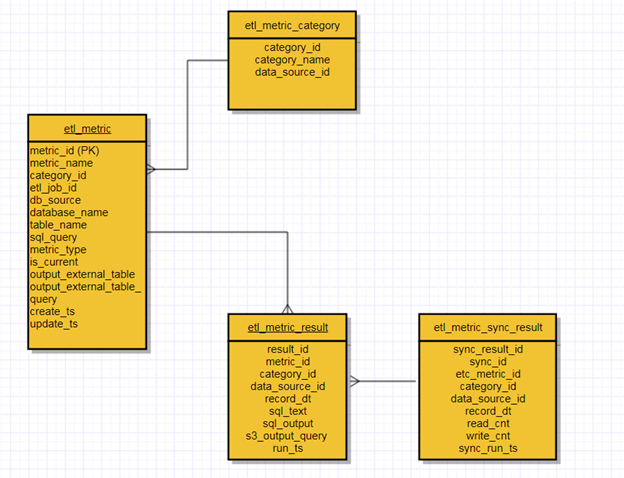
Совет № 5: Не перебарщивайте с количеством предупреждений, продумайте порог для предупреждения, иначе никто не будет обращать внимания (что сводит цель на нет)
4. Уделите время на разработку модели данных и уровня доступа к данным.
Современные механизмы обработки больших данных обладают огромной вычислительной мощностью, что создает иллюзию того, что мы можем просто поместить данные в файл, на лету построить схему и работать с ней. На рынке много инструментов, которые продают идею того, что аналитики могут создавать конвейеры данных и одновременно анализировать данные. Некоторое время это работает, но в конечном итоге не масштабируется.
У большинства витрин данных будут следующие потребители: внешние клиенты, дата аналитики, дата сайнтисты, разработчики и бизнес-пользователи. Существует несколько возможных способов доступа к данным. В конечном итоге хочется повысить эффективность своей системы не только за счет постоянного увеличения ресурсов, но и за счет хорошего дизайна и архитектуры. Вот ключевые моменты дизайна:
а. Анализ больших данных по большей части выполняется с целью аналитики, построения отчетов и бизнес-исследований. В области больших данных для обеспечения высокой пропускной способности отлично подходит структура типа data-warehous. Я категорически не согласен с подходом заливки случайных данных и организации доступа к ним с использованием мощных кластеров. Хорошая архитектура уменьшает хаос, повышает эффективность и должна иметь следующие компоненты:
- Data Lake — это место, где лежат все ваши необработанные или почти необработанные данные. Этот компонент важно иметь, иначе невозможно будет решить какие-либо проблемы с данными в вашей системе, и повторная обработка будет чрезвычайно сложной.
- Dimensional Warehouse — традиционная модель измерения фактов, мы не хотим строить сводные таблицы непосредственно из промежуточной области, потому что в случае, если измерение необходимо пересчитать, также потребуется пересобрать факты (что может оказаться очень дорогостоящим для больших наборов данных). Нам нужна изоляция разных потоков данных в размерной модели, чтобы они могли существовать не влияя друг на друга. В некоторых сценариях технологии Elastic search также могут иметь смысл для большого количества неструктурированных данных.
- Summarized tables — комбинация фактов и измерений, необходимая для большинства требуемых запросов от пользователей. Это сэкономит затраты на джоинах и ускорит запросы конечных пользователей.
Даже если ваши необработанные данные представляют собой файлы без схемы или файлы логов, мы все равно должны стремиться к структуре для повышения эффективности доступа к данным.
б. Партицирование — потратьте время на понимание паттернов доступа к данным и определение ключей для физического партицирования. Хорошо партицированное хранилище отлично минимизирует IO запросов. Некоторые механизмы обработки данных, такие как Spark, позволяют партицировать данные на лету, что может быть очень полезно.
c. Данные как сервис — подумайте, как приложения и бизнес-пользователи будут получать доступ к данным. Создайте интерфейс API для наиболее популярных или частых запросов на данные.
d. Устранение «темных данных» — все данные на любом этапе конвейера ETL (staging, warehouse, logs, aggregate, metadata) должны быть легко доступны для всех пользователей, желательно с одной платформы (например, ReDash, SuperSet, Jupyter и т. Д.). Чем более доступными будут данные, тем выше их уровень принятия и качество. Простой запрос или энпоинт API должны иметь все что нужно для доступа к данным. Данные не должны быть скрыты в файлах логов, JSON, недоступных файлах данных и т.д.
е. Высокая доступность и аварийное восстановление — независимо от того, хранятся ли данные в распределенных файловых системах, таких как HDFS, или в хранилищах объектов, таких как S3, или в базе данных любого типа, железное правило практики инженерии данных гласит, что все, что может дать сбой, выйдет из строя. Для каждой части критически важных и бизнес-данных должна быть резервная копия, которую можно будет восстановить во время сбоев. В зависимости от потребностей бизнеса выберите стратегию высокой доступности или аварийного восстановления (или и то, и другое). Никогда не экономьте на этом.
Совет № 6. Создайте Warehouse / DataMart в качестве конечной точки конвейера больших данных, чтобы обеспечить эффективный анализ данных и доступ к данным.
Совет № 7. «Дата инженер» — это библиотекарь хранилища данных, и то, как данные загружаются, упорядочиваются и извлекаются из хранилища, полностью ложится на плечи инженера по данным.
5. Никогда не загружайте файл
Каждая экосистема больших данных должна принимать различные файлы от множества клиентов, поставщиков и партнеров. Если вы напишете ETL для загрузки одного файла (который пришел к вам как срочное бизнес-требование), я могу гарантировать, что:
- Вы напишете новый ETL для второго файла (и третьего и четвертого ..)
- Вы будете поддерживать эти ETL и участвовать каждый раз, когда нужно добавить или изменить столбец.
- Вы потратите много времени на управление сложностью этой растущей базы кода.
Рекомендации
а. Никогда не пишите ETL для загрузки конкретного файла, вместо этого напишите фреймворк, управляемый метаданными, для приема любого файла или для создания любого извлечения.
б. Основная логика должна управляться SQL, хранящимся в метатаблицах.
c. Определите структуру столбцов в мета-таблицах, и задача по добавлению / редактированию столбца должна принадлежать командам поддержки, а не основной разработке (я отказываюсь присутствовать на любых таких встречах)
d. Платформа должна динамически считывать структуру данных на основе определения столбца в метатаблицах, что позволяет легко добавлять / изменять / удалять столбец.
е. Программа обертки при запуске должна читать мета-записи и соответственно выполнять SQL
Образец модели данных такого фреймворка с метаданными:
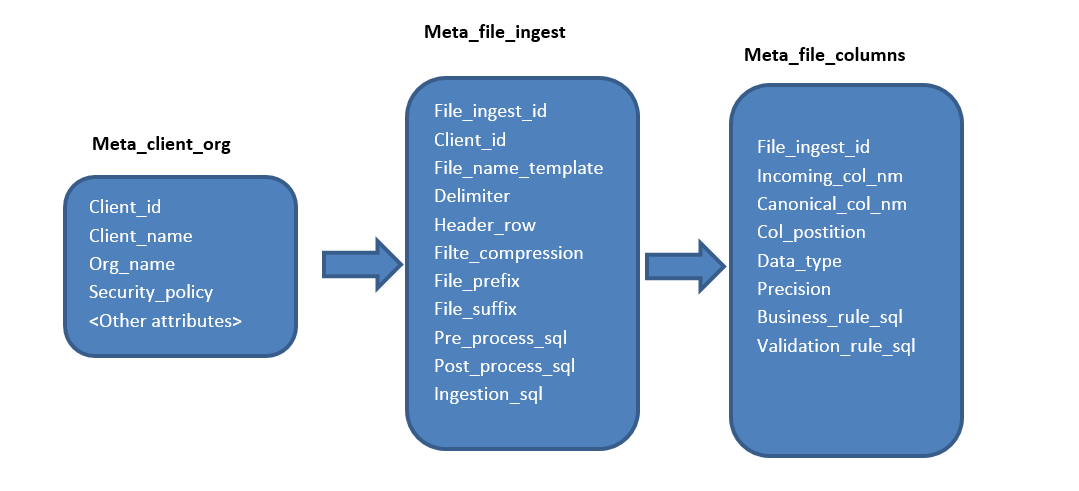
Совет № 8: автоматизируйте рутинные задачи с помощью архитектуры, основанной на метаданных, загрузка файлов с разными типами не должно все усложнять
6. Конвейер должен быть построен таким образом, чтобы обеспечить надежность и масштабируемость.
Хорошо спроектированный конвейер будет включать следующие элементы:
а. Повторные запуски — в случае изменения исходных данных (по любой причине) или катастрофического сбоя иногда необходимо повторно запустить задание ETL. Задание ETL должно быть контрольной точкой и иметь возможность повторно запускаться без каких-либо изменений кода или человеческих усилий (кроме тех, которые требуются для перезапуска задания). Это может быть достигнуто с помощью конвейера ETL, управляемого метаданными, где каждое задание устанавливает контрольную точку своего статуса, и каждое преобразование можно запускать повторно. Пример — используйте «Insert overwrite» вместо «insert into», чтобы сделать шаг вставки повторно используемым.
б. Мониторинг — в любой момент с помощью одного запроса (или пользовательского интерфейса) вы сможете узнать, каков статус моего батча? Какие задания были запущены и где они выполняются (или зависли). Если бы поверх модели данных был бы пользовательский интерфейс для мониторинга и анализа состояния конвейера, это значительно упростило бы жизнь. Есть множество готовых опций, доступных для мониторинга (например, Airflow), однако каждая из этих опций, в свою очередь, требует дополнительного кода и dev-ops.
c. Автоматическое масштабирование — конвейер должен масштабироваться в соответствии с нагрузкой. Кластер, работающий круглосуточно и без выходных, чрезвычайно расточителен (если вы не активны каждое мгновение), и с нынешними технологиями его можно построить относительно легко. Пример. В зависимости от триггера кластеры AWS EMR могут просыпаться, запускать определенное задание или последовательность заданий ETL, а затем прекращать работу. В зависимости от загрузки данных конфигурация кластера может увеличиваться или уменьшаться.
Совет № 9: платите только за то, что используете
Совет № 10: Использование архитектуры, основанной на метаданных, для проверок / повторных запусков / мониторинга снизит сложность, повысит производительность и в целом снизит нагрузку на команды инженеров данных.

Вот образец модели данных для всех рассмотренных выше сценариев использования на основе метаданных.
7. Потратьте время на выбор стека технологий
Времена, когда одна база данных или технология удовлетворяли все потребности, давно прошли. Например, резко выросла линейка специализированных решений для баз данных, вот неполный список доступных типов баз данных.
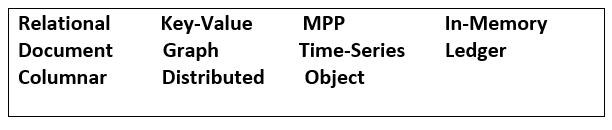
Два практических правила при выборе стека технологий:
- Каждая новая технология потребует накладных расходов, таких как dev-ops, роли безопасности, стратегия резервного копирования, подготовка пользователей, обучение, поддержка и т.д. Помните об этом, прежде чем приступать к делу. Создавайте стек технологий осторожно, постепенно и медленно.
- Гораздо эффективнее использовать специализированный продукт, чем пытаться построить общее решение под все варианты использования. Пример — если вам нужно хранить данные временных рядов, доступ будет намного более эффективным в базе данных временных рядов, чем из традиционной СУБД. Однако существует предел того, сколько специализированных продуктов можно или нужно использовать, каждая организация должна найти правильный баланс.
Для использования аналитики имеет смысл выбрать новейшее поколение баз данных и технологий ETL, то есть облачный механизм SQL (in-memory) и облачную обработку данных (in-memory). Протестируйте несколько предложений, используя закон Амдала, чтобы убедиться, что мы знаем верхний предел количества параллельных заданий, которые могут быть выполнены для данного предложения. Это также может служить ценным сравнением результатов тестирования от нескольких поставщиков.
8. Наймите правильную команду
Убедитесь, что каждый инженер по обработке данных понимает структуры данных и интуитивно понимает основные таблицы и функциональные данные, а также может устранять проблемы с данными достаточно быстро. Вот пример конфигурации группы инженеров:
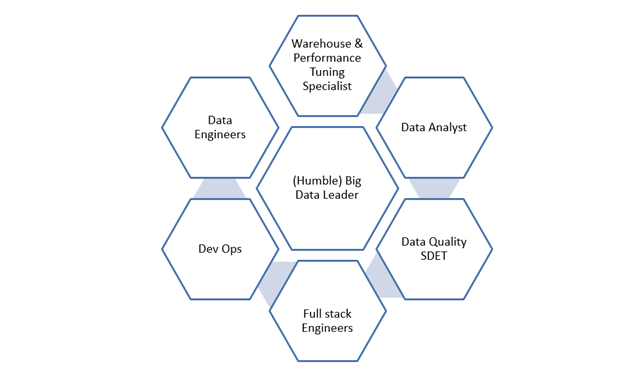
9. Best Practices
а. Уровень абстракции сводит к минимуму перемещение данных
Если данные распределены по нескольким базам данных или хранилищам данных, создайте уровень абстракции, используя технологию, которая может взаимодействовать с разнородными источниками данных без необходимости их перемещения. Например, Presto может подключаться к более чем 20 источникам данных и использовать их в одном запросе, как если бы все источники данных были в одном кластере.
Если данные распределены по нескольким файловым системам от нескольких поставщиков (HDFS, S3, Azure), тогда создайте уровень абстракции, используя что-то вроде Alluxio, который может служить как уровень доступа между вычислениями и хранением.
б. Столбцовое сжатие
Всегда храните окончательные агрегированные данные (которые доступны для запросов конечных пользователей) в сжатом виде, предпочтительно с использованием столбчатой ??файловой системы, такой как Parquet, ORC и т.д. Эти файловые системы были оптимизированы под многие механизмы обработки данных и значительно увеличивают пропускную способность запросов.
с. Notebooks
Используйте такие инструменты как Jupyter, iPython и т.д., для визуализации, создания прототипов и исследовательского анализа. Это быстрый и эффективный способ понимания данных перед их моделированием или приемом. Если возможно, создавайте параметризованные шаблоны «notebooks» со стандартными функциями и встроенными бизнес-сценариями, такими как просмотр данных, аудит данных, общие графики и т.д., которые могут быть быстро использованы любым инженером или аналитиком.
е. Стройте для своего бизнеса, а не для славы
Если ваша вселенная больших данных предназначена в первую очередь для аналитического бизнеса (как и большинство других) и аналитические данные необходимы или доступны на следующий день, то вам, вероятно, не нужна потоковая загрузка ваших данных в реальном времени. Инфраструктура потоковой передачи заведомо нестабильна, и ею очень сложно управлять. Это потребует значительных вложений в ресурсы, которые в отсутствие серьезного экономического обоснования будет трудно объяснить руководству инженерного отдела.
f. Контейнеры
Используйте популярный сервис контейнеризации Docker для разработки конвейеров данных и изоляции тестовых кейсов в изолированной программной среде разработчика.
Контейнеризованные сервисы также легко масштабируются вверх или вниз в зависимости от потребности. Контейнеры очень полезны для повышения безопасности, воспроизводимости и масштабируемости при разработке программного обеспечения.
g. Распределенные вычисления — ваш лучший друг
Не выполняйте никаких операций с данными, которые не распределяются и не распараллеливаются. Например, одна из распространенных ошибок людей заключается в том, что они запускают основное преобразование в SQL (распределенно), а затем сохраняют полученный результат в файл с помощью вызова однопоточного приложения. Лучшим подходом было бы создать файл, используя операцию CTAS базы данных и указав параметры файла.
h. Алгоритмы аппроксимации
Используйте алгоритмы аппроксимации, когда скорость имеет существенное значение, и для пользователя нормально когда есть небольшая погрешность в выходящиз данных. Базы данных, такие как Snowflake, Presto, предоставляют такого рода приближенные функции, встроенные в SQL. Они значительно сокращают время запроса для большого набора данных.
10. Безопасность
Лучшие практики для создания структуры безопасности для экосистемы больших данных:
- Всегда шифруйте данные при передаче и хранении.
- Все пользователи должны иметь свои собственные идентификаторы доступа с ограниченным доступом для чтения к производственной среде.
- Только идентификаторы процессов должны иметь доступ для чтения / записи на продакшене. Идентификаторы процессов должны напрямую настраиваться в инструменте оркестровки заданий.
- Всегда выполняйте резервное копирование на удаленные хранилища и планируйте инфраструктуру высокой доступности и аварийного восстановления (HA / DR)
- Используйте специализированные инструменты для аудита и обработки личной информации (PII)
- Контролируйте доступ к данным с помощью представлений, не открывайте основные таблицы напрямую
- Использование централизованных каталогов данных
- Всегда проверяйте SQL-инъекции, DoS и другие распространенные векторы угроз
- Все вызовы API должны делаться с ключом аутентификации.
Заключение
Тщательно продумайте потребности вашей организации, возможности кадрового резерва, стоимость разработки, стоимость обслуживания, баланс вашей работы и личной жизни и т.д. То что Кремниевая долина использует Airflow или Luigi для оркестровки, еще не значит, что вам тоже нужно это делать. Не попадайтесь в ловушку крутых детей. Выясните, что работает для вашей организации, а затем адаптируйтете это и развивайте.
Четыре ключевых вывода из этой статьи
а. Пишите меньше кода, в основном SQL
b. Всегда стремитесь снизить сложность
c. Создавайте гибкие конвейеры данных с помощью моделирования на основе метаданных
d. Сдерживайте свою естественную предвзятость к действиям перед началом разработки. Конвейеры данных трудно откатить назад — думайте, проектируйте и упрощайте перед разработкой.
* Коллеги, если знаете хорошие материалы про подходы построение Big Data систем(книги, видео, статьи), поделитесь пожалуйста в комментариях.
AlexTheLost
Статья если честно — чрезмерно водянистая. Можно было её свести к трем коротким пунткам, используетй SQL+Python+Airflow.