
Every time when the essential question arises, whether to upgrade the cards in the server room or not, I look through similar articles and watch such videos.
Channel with the aforementioned video is very underestimated, but the author does not deal with ML. In general, when analyzing comparisons of accelerators for ML, several things usually catch your eye:
- The authors usually take into account only the "adequacy" for the market of new cards in the United States;
- The ratings are far from the people and are made on very standard networks (which is probably good overall) without details;
- The popular mantra to train more and more gigantic models makes its own adjustments to the comparison;
The answer to the question "which card is better?" is not rocket science: Cards of the 20* series didn't get much popularity, while the 1080 Ti from Avito (Russian craigslist) still are very attractive (and, oddly enough, don't get cheaper, probably for this reason).
All this is fine and dandy and the standard benchmarks are unlikely to lie too much, but recently I learned about the existence of Multi-Instance-GPU technology for A100 video cards and native support for TF32 for Ampere devices and I got the idea to share my experience of the real testing cards on the Ampere architecture (3090 and A100). In this short note, I will try to answer the questions:
- Is the upgrade to Ampere worth it? (spoiler for the impatient — yes);
- Are the A100 worth the money (spoiler — in general — no);
- Are there any cases when the A100 is still interesting (spoiler — yes);
- Is MIG technology useful (spoiler — yes, but for inference and for very specific cases for training);
Please see below for details.
Simple Things
Let's immediately address the elephant in the room. At the time of this writing:
- 3090 is quite difficult to buy and they are sold with about a 30-40% premium (in the CIS). Moreover, there is a shortage of new cards not only in the CIS;
- The A100 is almost impossible to buy. Nvidia partners said that there is 1 piece in the Russian Federation, then a few more units will arrive;
- I haven't searched a lot, but I didn’t find information on whether PCIE version of A100 is compatible with conventional ATX platforms (Nvidia partners didn’t answer this question, but I assume that the cards do not have their own cooler and they are supposed to be installed in a server chassis with "loud" fan) — update — they are indeed passive;
- 3080 and lower models (although they are very interesting for the price, and especially for games) were not tested, because we do not have them, and we did not consider buying them due to the size of their memory (I naively assumed that it would be possible to run several networks on 1 card, but everything works a little differently there);
For obvious reasons, the holy war — to bow to the AWS religion — is omitted here.
Superior Cooling
According to the utilities from Nvidia, the 3090 and A100 are 15-20 degrees cooler than Maxwell and Pascal. I did not take accurate measurements, but on average the situation is like this:
- 4 * 1080 Ti (Pascal) with minimal cooling hacks operate in the range of 75-80C under 100% load;
- 3 * Titan X (Maxwell) worked around 85C under 100% load;
- 3 * 3090 (Ampere) operate in the range of 60-70C under 100% load;
- No overclocking, no restrictions on the power supply of cards or cooler speeds were applied anywhere, everything is out of the box;
- All cards have a blower fan, that is, they push heat out of the case;
There are 3 hypotheses why this is the case:
- New technical process;
- The 3090 has a slightly different shape of the card itself, the size of the fan is noticeably larger, the size of the hole on the rear panel is much larger;
- 3090 seems heavier (maybe someone knows where to find the exact numbers, there are no cards at hand now) which probably implies heavier heatsink;

A clear illustration of the differences between the cards, could someone from the comments tell the diameter of the fan?
Naive Metrics
First, to make sure the drivers work correctly (and when they did not work correctly, the numbers were completely different), let's test all the available cards with gpu-burn. The result is on the picture and correlates very strongly with what is reported in the reviews.
| Test | GPU | Gflop/s |
|---|---|---|
./gpu_burn 120 |
Titan X (Maxwell) | 4,300 |
./gpu_burn 120 |
1080 Ti (Pascal) | 8,500 |
./gpu_burn 120 |
3090 (Ampere) | 16,500 |
./gpu_burn 120 |
A100 (wo MIG) | 16,700 |
./gpu-burn -tc 120 |
3090 (Ampere) | 38,500 |
./gpu-burn -tc 120 |
A100 (wo MIG) | 81,500 |
MIG wasn't tested here, you will see why further in the article.
Pricing
It is important to note here that we bought the 1080 Tis and Titan Xs from the second hand market almost "new" (less than a year of use). We will not dwell once again on the holy wars about miners and Nvidia's pricing policy, but if you use even secondhand gaming cards carefully, their service life is about 3-4 years. Prices and characteristics are approximate. According to the information from Nvidia partners in Russia, only one A100 is on sale until the new year. When new 1080 Tiы were available, prices ranged from about 50k to 100k rubles.
| GPU | Mem | Price |
|---|---|---|
| Titan X (Maxwell) | 12G | 10,000 rubles (Avito) |
| 1080 Ti | 11G | 25,000 rubles (Avito) |
| 3090 (Ampere) | 24G | 160,000+ rubles (new) |
| A100 (wo MIG) | 40G | US $ 12,500 (new) |
Make the obvious conclusions.
Trying 3090 and A100 with MIG
Trying 3090
And now let's move on to the most interesting thing — to real down-to-earth tests. In theory, it seems that if the memory and computing capabilities of the 3090 or A100 are 2-3 times higher than the 1080 Ti, then 1 such card can replace 2-3 1080 Ti and a standard server with 4 proper PCIE ports can replace a server with 12 cards? Or is it possible to take, let's say, 3-4 PCIE versions of A100 and get a very powerful server, dividing each of them into several compute instances using MIG?
The short answer is no, the longer answer is also no, but with many caveats.
Why, would you ask? Well, server rack platforms that fully support 8 — 16 video cards even in the smallest reasonable configuration cost 4-5 times more expensive than standard ATX professional solutions. And DGX Workstation or DGX are sold with about a 50% premium to similar configurations assembled on Mikrotik or Gigabyte platforms.
Card manufacturers are in no hurry to release fully-fledged single-slot GPUs (except for PNY with the Quadro series, but this is a separate story and is more likely for design or inference). Of course, you can assemble a custom water circuit for 7 cards (there were several motherboard models with 7 proper PCIE ports), but it's "difficult" and it's not clear where to host it (and the game is not worth the trouble). With the advent of PCIE 4.0, the attractiveness of such solutions, in theory, should grow, but I haven't seen anything interesting on the market yet.
A couple of remarks about the task on which we tested:
- Task — training Spech-to-Text network on the Ukrainian dataset;
- Due to the problem itself, the experimentally optimal batch size for one process — 50 — cannot be increased significantly without losses in the convergence rate;
- It is on this task that AMP does not work for us (although it works for others, all other things being equal, we have not yet understood why), but this is more of an optimization. That is, it's not about the hardware, but about the task. It works on other tasks, so let's keep things simple;
- An important caveat — since the fact this task is a sequence-to-sequence, in the general case batching here is not entirely trivial. Files of different lengths only get into the batch with files of about the same length (to reduce wasted padding processing resources), but the size of the batch is static for easier comparisons and faster convergence;
- The dynamic and increased batch size were tested, but this does not particularly affect the speed and convergence rate (or worsens);
Contrary to the trend of making more and more gigantic networks, we are miniaturizing our algorithms and are trying to make our networks more and more efficient. Therefore, it is more interesting to increase the worker count, not the networks size or batch size.
And here we come across the first pitfall (https://t.me/snakers4/2590) — Distributed Data Parallel from PyTorch (DDP, the optimal way of scaling networks to "many" video cards) out of the box is essentially configured only for 1 process on 1 card. That is, 1 process can use 1+ card. 2 processes cannot use 1 card, even if there is more than enough IO / compute / RAM. In older driver versions, there is no explicit limitation, and on 1080 Ti 2 processes per 1 card could be launched (but the speed increase is only 5-10% instead of 40-50%). With the new cards, an exception has already been cut in there.
RuntimeError: NCCL error in: /opt/conda/conda-bld/pytorch_1603729096996/work/torch/lib/c10d/ProcessGroupNCCL.cpp:784, invalid usage, NCCL version 2.7.8But not everything is so sad and bad. Maybe because of some low-level magic in the drivers, maybe because of TF32 (I hope experts will prompt here), maybe because of the developments in MPS 3090s behave a little differently in our benchmark:
- Ceteris paribus they use more memory than Titan X and 1080 Ti (~16 GB instead of 7-8 GB);
- The speed is about 3 times higher than with the Titan X (Maxwell);
- [We still need to accurately measure the speed on 1080 Ti];
- Utilization of cards at a high level — over 90%;
When we try to run 2 DDP workers on 1 card, we just get an error, when we try to train 2 networks "at the same time" we get a proportional slowdown, when the batch increases, the speed gain is insignificant. The timings for 2 * 3090 are like this:
| Epoch time, m | Type | Workers | Batch | Params |
|---|---|---|---|---|
| exception | DDP | 4 | 50 * 4 | |
| 3.8 | DDP | 2 | 50 * 2 | |
| 3.9 | DDP | 2 | 50 * 2 | cudnn_benchmark = True |
| 3.6 | DDP | 2 | 100 * 2 |
For the sake of completeness, it is also important to note that Nvidia has an MPS which supposedly allows you to spin 2 processes on the cards without switching the context, and PyTorch has a built-in RPC framework. But I simply could not adequately use the former without getting incomprehensible low-level errors, and the latter requires a radical rewriting of the code and drastically complicates the code for training models (although it is very interesting in the long term).
So, with 3090 everything is clear. It will not replace two cards, of course, but by itself, even with "extra" memory (I remind, we train small networks), it works 2-3 times faster. Whether this is equivalent to having 2-3 cards depends on the task.
TLDR:
- You can simply replace the cards with a blower fan in your rig with 3090s (the only thing is that there are 2 8-pin power connectors in 3090, but there are 2000-Watt power supplies on the market that can definitely power 4-5 such cards, or just use 2 synced power supplies);
- Most likely, the temperature of the cards will drop by 10-20 degrees Celsius;
- These cards are now expensive and are in short supply (and probably are unlikely to become widely adopted), but if your most expensive resource is time, then this is an interesting option;
- If a large memory size is critical for you, you essentially have no choice;
Trying the A100 with MIG
Having looked at the metrics, availability, and price of cards, the A100 at first glance does not seem to be an interesting option at all, except for perhaps to train for 3 days 1 large network on 16 A100s on a small, not very private dataset in the cloud. Also, if AMP / FP16 helps your algorithms a lot, then A100 can significantly add speed.
But the A100 has an interesting MIG technology (Multi-Instance GPU). In fact, it allows you to break one "large and powerful" card into a set of small "subcards" and then create virtual Compute Instances, which can be accessed as separate cards.
There are quite a lot of details, check the documentation for them, but the following presets are available there:
+--------------------------------------------------------------------------+
| GPU instance profiles: |
| GPU Name ID Instances Memory P2P SM DEC ENC |
| Free/Total GiB CE JPEG OFA |
|==========================================================================|
| 0 MIG 1g.5gb 19 0/7 4.75 No 14 0 0 |
| 1 0 0 |
+--------------------------------------------------------------------------+
| 0 MIG 2g.10gb 14 0/3 9.75 No 28 1 0 |
| 2 0 0 |
+--------------------------------------------------------------------------+
| 0 MIG 3g.20gb 9 0/2 19.62 No 42 2 0 |
| 3 0 0 |
+--------------------------------------------------------------------------+
| 0 MIG 4g.20gb 5 0/1 19.62 No 56 2 0 |
| 4 0 0 |
+--------------------------------------------------------------------------+
| 0 MIG 7g.40gb 0 0/1 39.50 No 98 5 0 |
| 7 1 1 |
+--------------------------------------------------------------------------+
Available configurations
The question arises, what if our network is small, and A100 in theory (at least on FP16) should be 2 times more powerful than 3090? Is it possible to take 4 A100 and make 12 GPUs similar to 1080 Ti? Is it possible to train neural networks on these numerous "micro-cards" in the same way as on several conventional ones?
We will answer the questions one by one. Here are both the documentation itself and a very recent blog post from Nvidia.
There is a paragraph in the documentation:
MIG supports running CUDA applications by specifying the CUDA device on which the application should be run. With CUDA 11, only enumeration of a single MIG instance is supported.
CUDA applications treat a CI and its parent GI as a single CUDA device. CUDA is limited to use a single CI and will pick the first one available if several of them are visible. To summarize, there are two constraints:
- CUDA can only enumerate a single compute instance
- CUDA will not enumerate non-MIG GPU if any compute instance is enumerated on any other GPU
Note that these constraints may be relaxed in future NVIDIA driver releases for MIG.At first, when I read it, it seemed to me that it just meant that you cannot divide 2 cards at the same time. After I tried to play around with a real card, it turned out that the framework inside the container sees only 1 "card" (and apparently it only selects the "first" one). Moreover, if we carefully read the examples that Nvidia gives in its blog, they essentially all refer to the scenario "1 container — 1 piece of the card" or "tuning 7 small models in parallel".
There is also a passage like this:
There is no GPU-to-GPU P2P (both PCIe and NVLINK) support in MIG mode, so MIG mode does not support multi-GPU or multi-node training. For large models or models trained with a large batch size, the models may fully utilize a single GPU or even be scaled to multi-GPUs or multi-nodes. In these cases, we still recommend using a full GPU or multi-GPUs, even multi-nodes, to minimize total training time.If you use MIG for its intended purpose, that is, divide the card into physical pieces (slices), assign them Compute Instances, and drop them into isolated containers — then everything works as it should. It just works. Otherwise — it does not.
Final Measurements
Here are not really ideal comparisons (on Titan I had DP and not DDP), and on the A100, in the end, I did not run experiments for 10, 20, 30 hours (why pollute the atmosphere), but I measured the time for 1 epoch ...

When you launch 1 network on the A100, the utilization does not even reach half — well, that is, if it could be cut into 2-3 cards, everything would be fine
| Avg epoch time, m | Workers | Batch | GPUs | CER @ 10 hours | CER @ 20 h | CER @ 30 h | Comment |
|---|---|---|---|---|---|---|---|
| 4.7 | 2, DDP | 50 * 2 | 2 * 3090 | 14.4 | 12.3 | 11.44 | Close to 100% utilization |
| 15.3 | 1, DP | 50 | 2 * Titan X | 21.6 | 17.4 | 15.7 | Close to 100% utilization |
| 11.4 | 1, DDP | 50 * 1 | 1 * A100 | NA | NA | NA | About 35-40% utilization |
| TBD | 2, DDP | 50 * 2 | 2 * 1080 Ti | TBD | TBD | TBD |
On 1080 Ti, resources were only to run 1 epoch.
Conclusions
Conclusions about 3090:
- If we forget about stock shortages, then the upgrade is worth it. You will get x2 speed up minimum. If AMP works for you, then maybe even all x3-x4;
- Given the increased productivity, the price seems a bit high, but not exorbitant. A price reduction of about 30-40%, it seems to me, would be adequate;
- When a new generation of cards came out, everyone was worried about cooling. But the cards are surprisingly cold;
- The only problem is that the card demands 2 8-pin connectors for power supply;
Conclusions about the A100:
- Judging by the price divided by the performance, the card is not very interesting (the markup is 2-3 times against 3090);
- The fact that Nvidia made the technology for efficient inference is cool, otherwise the cards have become too big and poweful;
- If you can use ordinary gaming cards (the same 1080 Ti or PNY Quadro) for inference, then they represent much more value for money;
- There is a great untapped potential in the development of MIG technology;
- If you really need 40 GB of memory and a lot of computing, then there are really no alternatives;
- It is unclear whether the PCIE version could be installed in a regular ATX case without custom, hacking, or water cooling;
Update 1
Added gpu-burn along with CUDA_VISIBLE_DEVICES
I'll try to specify CUDA_VISIBLE_DEVICES inside each PyTorch process later
| Test | GPU | Gflop / s | RAM |
|---|---|---|---|
| ./gpu_burn 120 | A100 // 7 | 2,400 * 7 | 4.95 * 7 |
| ./gpu_burn 120 | A100 // 3 | 4,500 * 3 | 9.75 * 3 |
| ./gpu_burn 120 | A100 // 2 | 6,700 * 2 | 19.62 * 2 |
| ./gpu_burn 120 | A100 (wo MIG) | 16,700 | 39.50 * 1 |
| ./gpu-burn -tc 120 | A100 // 7 | 15,100 * 7 | 4.95 * 7 |
| ./gpu-burn -tc 120 | A100 // 3 | 30,500 * 3 | 9.75 * 3 |
| ./gpu-burn -tc 120 | A100 // 2 | 42,500 * 2 | 19.62 * 2 |
| ./gpu-burn -tc 120 | A100 (wo MIG) | 81,500 | 39.50 * 1 |
Update 2
GPU utilization schedule when running 3 parallel gpu-burn tests via MIG
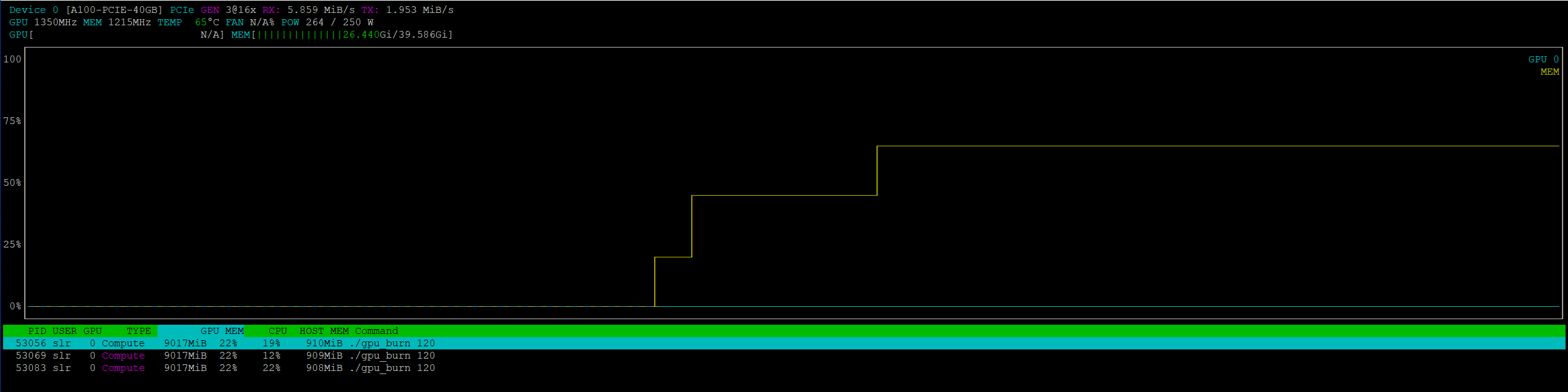
Update 3
I ended up being able to get DDP with MIG on PyTorch.
It was necessary to do so and use the zero (first) device everywhere.
def main(rank, args):
os.environ["CUDA_VISIBLE_DEVICES"] = args.ddp.mig_devices[rank]
import torch
...With NCCL I got the same exception. Changing nccl to gloo made it start… but it worked sooooo slow. Well, let's say, ten times slower and the utilization of the card was at a very low level. I think there is no point in digging further. So the conclusion is — MIG in its current state is absolutely not suitable for large-scale training of networks. Now this is purely a feature for inference or for training N small networks on small datasets.
Update 4
We found out why our networks refused to cooperate with AMP. More info here.