JIT (Just-in-Time) компилятор оказывает огромное влияние на быстродействие приложения. Понимание принципов его работы, способов мониторинга и настройки является важным для каждого Java-программиста. В цикле статей из двух частей мы рассмотрим устройство JIT компилятора в HotSpot JVM, способы мониторинга его работы, а также возможности его настройки. В этой, первой части мы рассмотрим устройство JIT компилятора и способы мониторинга его работы.
Процессоры могут исполнять только ограниченный набор инструкций — машинный код. Для исполнения программы процессором, она должна быть представлена в виде машинного кода.
Существуют компилируемые языки программирования, такие как C и C++. Программы, написанные на этих языках, распространяются в виде машинного кода. После того, как программа написана, специальный процесс — Ahead-of-Time (AOT) компилятор, обычно называемый просто компилятором, транслирует исходный код в машинный. Машинный код предназначен для выполнения на определенной модели процессора. Процессоры с общей архитектурой могут выполнять один и тот же код. Более поздние модели процессора как правило поддерживают инструкции предыдущих моделей, но не наоборот. Например, машинный код, использующий AVX инструкции процессоров Intel Sandy Bridge не может выполняться на более старых процессорах Intel. Существуют различные способы решения этой проблемы, например, вынесение критичных частей программы в библиотеку, имеющую версии под основные модели процессора. Но часто программы просто компилируются для относительно старых моделей процессоров и не используют преимущества новых наборов инструкций.
В противоположность компилируемым языкам программирования существуют интерпретируемые языки, такие как Perl и PHP. Один и тот же исходный код при таком подходе может быть запущен на любой платформе, для которой существует интерпретатор. Минусом этого подхода является то, что интерпретируемый код работает медленнее, чем машинный код, делающий тоже самое.
Язык Java предлагает другой подход, нечто среднее между компилируемыми и интерпретируемыми языками. Приложения на языке Java компилируются в промежуточный низкоуровневый код — байт-код (bytecode).
Байт-код затем исполняется JVM также как и программа на интерпретируемом языке. Но поскольку байт-код имеет строго определенный формат, JVM может компилировать его в машинный код прямо во время выполнения. Естественно, старые версии JVM не смогут сгенерировать машинный код, использующий новые наборы инструкций процессоров вышедших после них. С другой стороны, для того, чтобы ускорить Java-программу, ее даже не надо перекомпилировать. Достаточно запустить ее на более новой JVM.
В различных реализациях JVM JIT компилятор может быть реализован по-разному. В данной статье мы рассматриваем Oracle HotSpot JVM и ее реализацию JIT компилятора. Название HotSpot происходит от подхода, используемого в JVM для компиляции байт-кода. Обычно в приложении только небольшие части кода выполняются достаточно часто и производительность приложения в основном зависит от скорости выполнения именно этих частей. Эти части кода называются горячими точками (hot spots), их и компилирует JIT компилятор. В основе этого подхода лежит несколько суждений. Если код будет исполнен всего один раз, то компиляция этого кода — пустая трата времени. Другая причина — это оптимизации. Чем больше раз JVM исполняет какой либо код, тем больше статистики она накапливает, используя которую можно сгенерировать более оптимизированный код. К тому же компилятор разделяет ресурсы виртуальной машины с самим приложением, поэтому ресурсы затраченные на профилирование и оптимизацию могли бы быть использованы для исполнения самого приложения, что заставляет соблюдать определенный баланс. Единицей работы для HotSpot компилятора является метод и цикл.
На самом деле в HotSpot JVM существует не один, а два компилятора: C1 и C2. Другие их названия клиентский (client) и серверный (server). Исторически C1 использовался в GUI приложениях, а C2 в серверных. Отличаются компиляторы тем, как быстро они начинают компилировать код. C1 начинает компилировать код быстрее, в то время как C2 может генерировать более оптимизированный код.
В ранних версиях JVM приходилось выбирать компилятор, используя флаги -client для клиентского и -server или -d64 для серверного. В JDK 6 был внедрен режим многоуровневой компиляции. Грубо говоря, его суть заключается в последовательном переходе от интерпретируемого кода к коду, сгенерированному компилятором C1, а затем C2. В JDK 8 флаги -client, -server и -d64 игнорируются, а в JDK 11 флаг -d64 был удален и приводит к ошибке. Выключить режим многоуровневой компиляции можно флагом -XX:-TieredCompilation.
Существует 5 уровней компиляции:
Типичные последовательности переходов между уровнями приведены в таблице.
Машинный код, скомпилированный JIT компилятором, хранится в области памяти называемой code cache. В ней также хранится машинный код самой виртуальной машины, например, код интерпретатора. Размер этой области памяти ограничен, и когда она заполняется, компиляция прекращается. В этом случае часть «горячих» методов так и продолжит выполняться интерпретатором. В случае переполнения JVM выводит следующее сообщение:
Другой способ узнать о переполнении этой области памяти — включить логирование работы компилятора (как это сделать обсуждается ниже).
Code cache настраивается также как и другие области памяти в JVM. Первоначальный размер задаётся параметром -XX:InitialCodeCacheSize. Максимальный размер задается параметром -XX:ReservedCodeCacheSize. По умолчанию начальный размер равен 2496 KB. Максимальный размер равен 48 MB при выключенной многоуровневой компиляции и 240 MB при включенной.
Начиная с Java 9 code cache разделен на 3 сегмента (суммарный размер по-прежнему ограничен пределами, описанными выше):
Включить логирование процесса компиляции можно флагом -XX:+PrintCompilation (по умолчанию он выключен). При установке этого флага JVM будет выводить в стандартный поток вывода (STDOUT) сообщение каждый раз после компиляции метода или цикла. Большинство сообщений имеют следующий формат: timestamp compilation_id attributes tiered_level method_name size deopt.
Поле timestamp — это время со старта JVM.
Поле compilation_id — это внутренний ID задачи. Обычно он последовательно увеличивается в каждом сообщении, но иногда порядок может нарушаться. Это может произойти в случае, если существует несколько потоков компиляции работающих параллельно.
Поле attributes — это набор из пяти символов, несущих дополнительную информацию о скомпилированном коде. Если какой-то из атрибутов не применим, вместо него выводится пробел. Существуют следующие атрибуты:
Аббревиатура OSR означает on-stack replacement. Компиляция — это асинхронный процесс. Когда JVM решает, что метод необходимо скомпилировать, он помещается в очередь. Пока метод компилируется, JVM продолжает исполнять его интерпретатором. В следущий раз, когда метод будет вызван снова, будет выполняться его скомпилированная версия. В случае долгого цикла ждать завершения метода нецелесообразно — он может вообще не завершиться. JVM компилирует тело цикла и должна начать исполнять его скомпилированную версию. JVM хранит состояние потоков в стеке. Для каждого вызываемого метода в стеке создается новый объект — Stack Frame, который хранит параметры метода, локальные переменные, возвращаемое значение и другие значения. Во время OSR создается новый объект Stack Frame, который заменяет собой предыдущий.
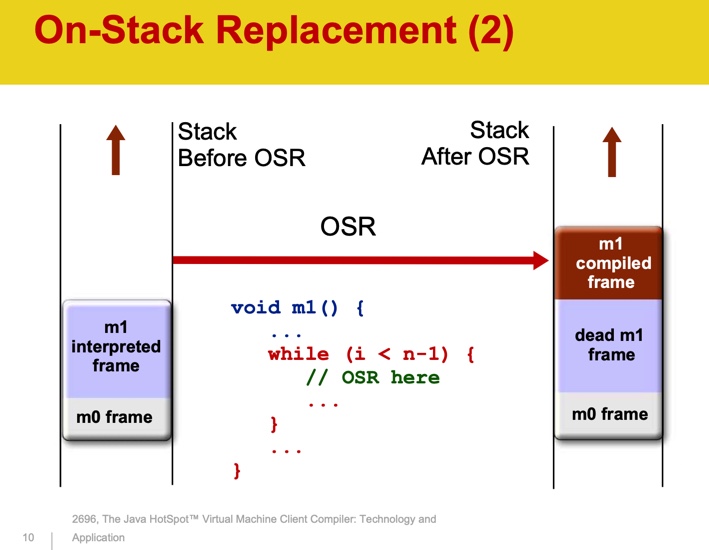
Источник: The Java HotSpotTM Virtual Machine Client Compiler: Technology and Application
Атрибуты «s» и «!» в пояснении я думаю не нуждаются.
Атрибут «b» означает, что компиляция произошла не в фоне, и не должен встречаться в современных версиях JVM.
Атрибут «n» означает, что скомпилированный метод является оберткой нативного метода.
Поле tiered_level содержит номер уровня, на котором был скомпилирован код или может быть пустым, если многоуровневая компиляция выключена.
Поле method_name содержит название скомпилированного метода или название метода, содержащего скомпилированный цикл.
Поле size содержит размер скомпилированного байт-кода, не размер полученного машинного кода. Размер указан в байтах.
Поле deopt появляется не в каждом сообщении, оно содержит название проведенной деоптимизации и может содержать такие сообщения как «made not entrant» и «made zombie».
Иногда в логе могут появиться записи вида: timestamp compile_id COMPILE SKIPPED: reason. Они означают, что при компиляции метода что-то пошло не так. Есть случаи, когда это ожидаемо:
Во всех случаях, кроме переполнения code cache, JVM попробует повторить компиляцию. Если этого не происходит, можно попробовать упростить код.
В случае, если процесс был запущен без флага -XX:+PrintCompilation, взглянуть на процесс компиляции можно с помощью утилиты jstat. У jstat есть два параметра для вывода информации о компиляции.
Параметр -compiler выводит сводную информацию о работе компилятора (5003 — это ID процесса):
Эта команда также выводит количество методов, компиляция которых завершилась ошибкой и название последнего такого метода.
Параметр -printcompilation выводит информацию о последнем скомпилированном методе. В сочетании со вторым параметром — периодом повторения операции, можно наблюдать процесс компиляции с течением времени. В следующем примере команда -printcompilation выполняется каждую секунду (1000 мс):
В следующей части мы рассмотрим пороговые значения счетчиков при которых JVM запускает компиляцию и как можно их поменять. Мы также рассмотрим как JVM выбирает количество потоков компилятора, как можно его поменять и в каких случаях стоит это делать. И наконец, кратко рассмотрим некоторые из оптимизаций выполняемых JIT компилятором.
AOT и JIT компиляторы
Процессоры могут исполнять только ограниченный набор инструкций — машинный код. Для исполнения программы процессором, она должна быть представлена в виде машинного кода.
Существуют компилируемые языки программирования, такие как C и C++. Программы, написанные на этих языках, распространяются в виде машинного кода. После того, как программа написана, специальный процесс — Ahead-of-Time (AOT) компилятор, обычно называемый просто компилятором, транслирует исходный код в машинный. Машинный код предназначен для выполнения на определенной модели процессора. Процессоры с общей архитектурой могут выполнять один и тот же код. Более поздние модели процессора как правило поддерживают инструкции предыдущих моделей, но не наоборот. Например, машинный код, использующий AVX инструкции процессоров Intel Sandy Bridge не может выполняться на более старых процессорах Intel. Существуют различные способы решения этой проблемы, например, вынесение критичных частей программы в библиотеку, имеющую версии под основные модели процессора. Но часто программы просто компилируются для относительно старых моделей процессоров и не используют преимущества новых наборов инструкций.
В противоположность компилируемым языкам программирования существуют интерпретируемые языки, такие как Perl и PHP. Один и тот же исходный код при таком подходе может быть запущен на любой платформе, для которой существует интерпретатор. Минусом этого подхода является то, что интерпретируемый код работает медленнее, чем машинный код, делающий тоже самое.
Язык Java предлагает другой подход, нечто среднее между компилируемыми и интерпретируемыми языками. Приложения на языке Java компилируются в промежуточный низкоуровневый код — байт-код (bytecode).
Название байт-код было выбрано потому, что для кодирования каждой операции используется ровно один байт. В Java 10 существует около 200 операций.
Байт-код затем исполняется JVM также как и программа на интерпретируемом языке. Но поскольку байт-код имеет строго определенный формат, JVM может компилировать его в машинный код прямо во время выполнения. Естественно, старые версии JVM не смогут сгенерировать машинный код, использующий новые наборы инструкций процессоров вышедших после них. С другой стороны, для того, чтобы ускорить Java-программу, ее даже не надо перекомпилировать. Достаточно запустить ее на более новой JVM.
HotSpot JIT компилятор
В различных реализациях JVM JIT компилятор может быть реализован по-разному. В данной статье мы рассматриваем Oracle HotSpot JVM и ее реализацию JIT компилятора. Название HotSpot происходит от подхода, используемого в JVM для компиляции байт-кода. Обычно в приложении только небольшие части кода выполняются достаточно часто и производительность приложения в основном зависит от скорости выполнения именно этих частей. Эти части кода называются горячими точками (hot spots), их и компилирует JIT компилятор. В основе этого подхода лежит несколько суждений. Если код будет исполнен всего один раз, то компиляция этого кода — пустая трата времени. Другая причина — это оптимизации. Чем больше раз JVM исполняет какой либо код, тем больше статистики она накапливает, используя которую можно сгенерировать более оптимизированный код. К тому же компилятор разделяет ресурсы виртуальной машины с самим приложением, поэтому ресурсы затраченные на профилирование и оптимизацию могли бы быть использованы для исполнения самого приложения, что заставляет соблюдать определенный баланс. Единицей работы для HotSpot компилятора является метод и цикл.
Единица скомпилированного кода называется nmethod (сокращение от native method).
Многоуровневая компиляция (tiered compilation)
На самом деле в HotSpot JVM существует не один, а два компилятора: C1 и C2. Другие их названия клиентский (client) и серверный (server). Исторически C1 использовался в GUI приложениях, а C2 в серверных. Отличаются компиляторы тем, как быстро они начинают компилировать код. C1 начинает компилировать код быстрее, в то время как C2 может генерировать более оптимизированный код.
В ранних версиях JVM приходилось выбирать компилятор, используя флаги -client для клиентского и -server или -d64 для серверного. В JDK 6 был внедрен режим многоуровневой компиляции. Грубо говоря, его суть заключается в последовательном переходе от интерпретируемого кода к коду, сгенерированному компилятором C1, а затем C2. В JDK 8 флаги -client, -server и -d64 игнорируются, а в JDK 11 флаг -d64 был удален и приводит к ошибке. Выключить режим многоуровневой компиляции можно флагом -XX:-TieredCompilation.
Существует 5 уровней компиляции:
- 0 — интерпретируемый код
- 1 — C1 с полной оптимизацией (без профилирования)
- 2 — C1 с учетом количества вызовов методов и итераций циклов
- 3 — С1 с профилированием
- 4 — С2
Типичные последовательности переходов между уровнями приведены в таблице.
| Последовательность |
Описание |
|---|---|
| 0-3-4 | Интерпретатор, уровень 3, уровень 4. Наиболее частый случай. |
| 0-2-3-4 | Случай, когда очередь уровня 4 (C2) переполнена. Код быстро компилируется на уровне 2. Как только профилирование этого кода завершится, он будет скомпилирован на уровне 3 и, наконец, на уровне 4. |
| 0-2-4 | Случай, когда очередь уровня 3 переполнена. Код может быть готов к компилированию на уровне 4 все еще ожидая своей очереди на уровне 3. Тогда он быстро компилируется на уровне 2 и затем на уровне 4. |
| 0-3-1 | Случай простых методов. Код сначала компилируется на уровне 3, где становится понятно, что метод очень простой и уровень 4 не сможет скомпилировать его оптимальней. Код компилируется на уровне 1. |
| 0-4 | Многоуровневая компиляция выключена. |
Code cache
Машинный код, скомпилированный JIT компилятором, хранится в области памяти называемой code cache. В ней также хранится машинный код самой виртуальной машины, например, код интерпретатора. Размер этой области памяти ограничен, и когда она заполняется, компиляция прекращается. В этом случае часть «горячих» методов так и продолжит выполняться интерпретатором. В случае переполнения JVM выводит следующее сообщение:
Java HotSpot(TM) 64-Bit Server VM warning: CodeCache is full.
Compiler has been disabled.
Другой способ узнать о переполнении этой области памяти — включить логирование работы компилятора (как это сделать обсуждается ниже).
Code cache настраивается также как и другие области памяти в JVM. Первоначальный размер задаётся параметром -XX:InitialCodeCacheSize. Максимальный размер задается параметром -XX:ReservedCodeCacheSize. По умолчанию начальный размер равен 2496 KB. Максимальный размер равен 48 MB при выключенной многоуровневой компиляции и 240 MB при включенной.
Начиная с Java 9 code cache разделен на 3 сегмента (суммарный размер по-прежнему ограничен пределами, описанными выше):
- JVM internal (non-method code). Содержит машинный код, относящийся к самой JVM, например, код интерпретатора. Размер этого сегмента зависит от количества потоков компиляции. На машине с четырьмя ядрами по умолчанию его размер составляет около 5.5 MB. Задать произвольный размер сегмента можно параметром -XX:NonNMethodCodeHeapSize.
- Profiled code. Содержит частично оптимизированный машинный код с коротким временем жизни. Размер этого сегмента равен половине пространства оставшегося после выделения non-method code сегмента. По умолчанию это 21.2 MB при выключенной многоуровневой компиляции и 117.2 MB при включенной. Задать произвольный размер можно параметром -XX:ProfiledCodeHeapSize.
- Non-profiled code. Содержит полностью оптимизированный код с потенциально долгим временем жизни. Размер этого сегмента равен половине пространства оставшегося после выделения non-method code сегмента. По умолчанию это 21.2 MB при выключенной многоуровневой компиляции и 117.2 MB при включенной. Задать произвольный размер можно параметром -XX: NonProfiledCodeHeapSize.
Мониторинг работы компилятора
Включить логирование процесса компиляции можно флагом -XX:+PrintCompilation (по умолчанию он выключен). При установке этого флага JVM будет выводить в стандартный поток вывода (STDOUT) сообщение каждый раз после компиляции метода или цикла. Большинство сообщений имеют следующий формат: timestamp compilation_id attributes tiered_level method_name size deopt.
Поле timestamp — это время со старта JVM.
Поле compilation_id — это внутренний ID задачи. Обычно он последовательно увеличивается в каждом сообщении, но иногда порядок может нарушаться. Это может произойти в случае, если существует несколько потоков компиляции работающих параллельно.
Поле attributes — это набор из пяти символов, несущих дополнительную информацию о скомпилированном коде. Если какой-то из атрибутов не применим, вместо него выводится пробел. Существуют следующие атрибуты:
- % — OSR (on-stack replacement);
- s — метод является синхронизированным (synchronized);
- ! — метод содержит обработчик исключений;
- b — компиляция произошла в блокирующем режиме;
- n — скомпилированный метод является оберткой нативного метода.
Аббревиатура OSR означает on-stack replacement. Компиляция — это асинхронный процесс. Когда JVM решает, что метод необходимо скомпилировать, он помещается в очередь. Пока метод компилируется, JVM продолжает исполнять его интерпретатором. В следущий раз, когда метод будет вызван снова, будет выполняться его скомпилированная версия. В случае долгого цикла ждать завершения метода нецелесообразно — он может вообще не завершиться. JVM компилирует тело цикла и должна начать исполнять его скомпилированную версию. JVM хранит состояние потоков в стеке. Для каждого вызываемого метода в стеке создается новый объект — Stack Frame, который хранит параметры метода, локальные переменные, возвращаемое значение и другие значения. Во время OSR создается новый объект Stack Frame, который заменяет собой предыдущий.
Источник: The Java HotSpotTM Virtual Machine Client Compiler: Technology and Application
Атрибуты «s» и «!» в пояснении я думаю не нуждаются.
Атрибут «b» означает, что компиляция произошла не в фоне, и не должен встречаться в современных версиях JVM.
Атрибут «n» означает, что скомпилированный метод является оберткой нативного метода.
Поле tiered_level содержит номер уровня, на котором был скомпилирован код или может быть пустым, если многоуровневая компиляция выключена.
Поле method_name содержит название скомпилированного метода или название метода, содержащего скомпилированный цикл.
Поле size содержит размер скомпилированного байт-кода, не размер полученного машинного кода. Размер указан в байтах.
Поле deopt появляется не в каждом сообщении, оно содержит название проведенной деоптимизации и может содержать такие сообщения как «made not entrant» и «made zombie».
Иногда в логе могут появиться записи вида: timestamp compile_id COMPILE SKIPPED: reason. Они означают, что при компиляции метода что-то пошло не так. Есть случаи, когда это ожидаемо:
- Code cache filled — необходимо увеличть размер области памяти code cache.
- Concurrent classloading — класс был модифицирован во время компиляции.
Во всех случаях, кроме переполнения code cache, JVM попробует повторить компиляцию. Если этого не происходит, можно попробовать упростить код.
В случае, если процесс был запущен без флага -XX:+PrintCompilation, взглянуть на процесс компиляции можно с помощью утилиты jstat. У jstat есть два параметра для вывода информации о компиляции.
Параметр -compiler выводит сводную информацию о работе компилятора (5003 — это ID процесса):
% jstat -compiler 5003
Compiled Failed Invalid Time FailedType FailedMethod
206 0 0 1.97 0
Эта команда также выводит количество методов, компиляция которых завершилась ошибкой и название последнего такого метода.
Параметр -printcompilation выводит информацию о последнем скомпилированном методе. В сочетании со вторым параметром — периодом повторения операции, можно наблюдать процесс компиляции с течением времени. В следующем примере команда -printcompilation выполняется каждую секунду (1000 мс):
% jstat -printcompilation 5003 1000
Compiled Size Type Method
207 64 1 java/lang/CharacterDataLatin1 toUpperCase
208 5 1 java/math/BigDecimal$StringBuilderHelper getCharArray
Планы на вторую часть
В следующей части мы рассмотрим пороговые значения счетчиков при которых JVM запускает компиляцию и как можно их поменять. Мы также рассмотрим как JVM выбирает количество потоков компилятора, как можно его поменять и в каких случаях стоит это делать. И наконец, кратко рассмотрим некоторые из оптимизаций выполняемых JIT компилятором.
Список литературы и ссылки
- Java Performance: In-Depth Advice for Tuning and Programming Java 8, 11, and Beyond, Scott Oaks. ISBN: 978-1-492-05611-9.
- Optimizing Java: Practical Techniques for Improving JVM Application Performance, Benjamin J. Evans, James Gough, and Chris Newland. ISBN: 978-1-492-02579-5.
- JEP 197: Segmented Code Cache
- The Java HotSpotTM Virtual Machine Client Compiler: Technology and Application
asadganiev
Эти две книжки давно у меня лежат в моем «Must Read Books» списке, но никак руки не доходят, и эта статья напомнила мне о них еще раз.
и очень хотелось бы узнать как Hotspot JIT компилятор работает под капотом.
Ждем второй части статьи.