Привет, Хабр! Сегодня будет заключительная часть темы Кластеризация и классификация больших Текстовых данных с помощью машинного обучения на Java. Данная статья является продолжением первой и второй статьи.
Статья описывает архитектуру системы, алгоритма, а также визуальные результаты. Все детали теории и алгоритмов вы найдете в первых двух статьей.
Архитектуры системы можно разделить на две основные части: веб приложение и программное обеспечение кластеризации и классификации данных
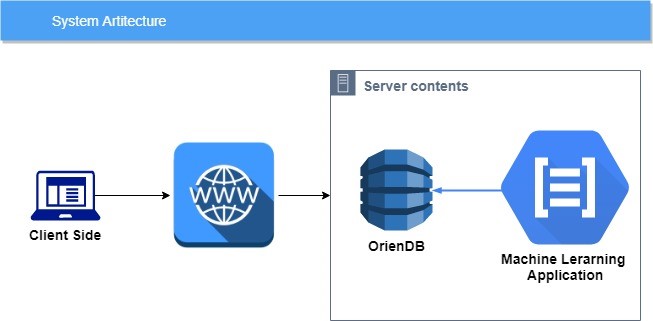
Алгоритм программного обеспечение для машинного обучение состоит из 3 основных частей:
обработка естественного языка;
токенизация;
лемматизация;
стоп-листинг;
частота слов;
методы кластеризации ;
TF-IDF ;
SVD;
нахождение кластерных групп;
методы классификации – Aylien API.
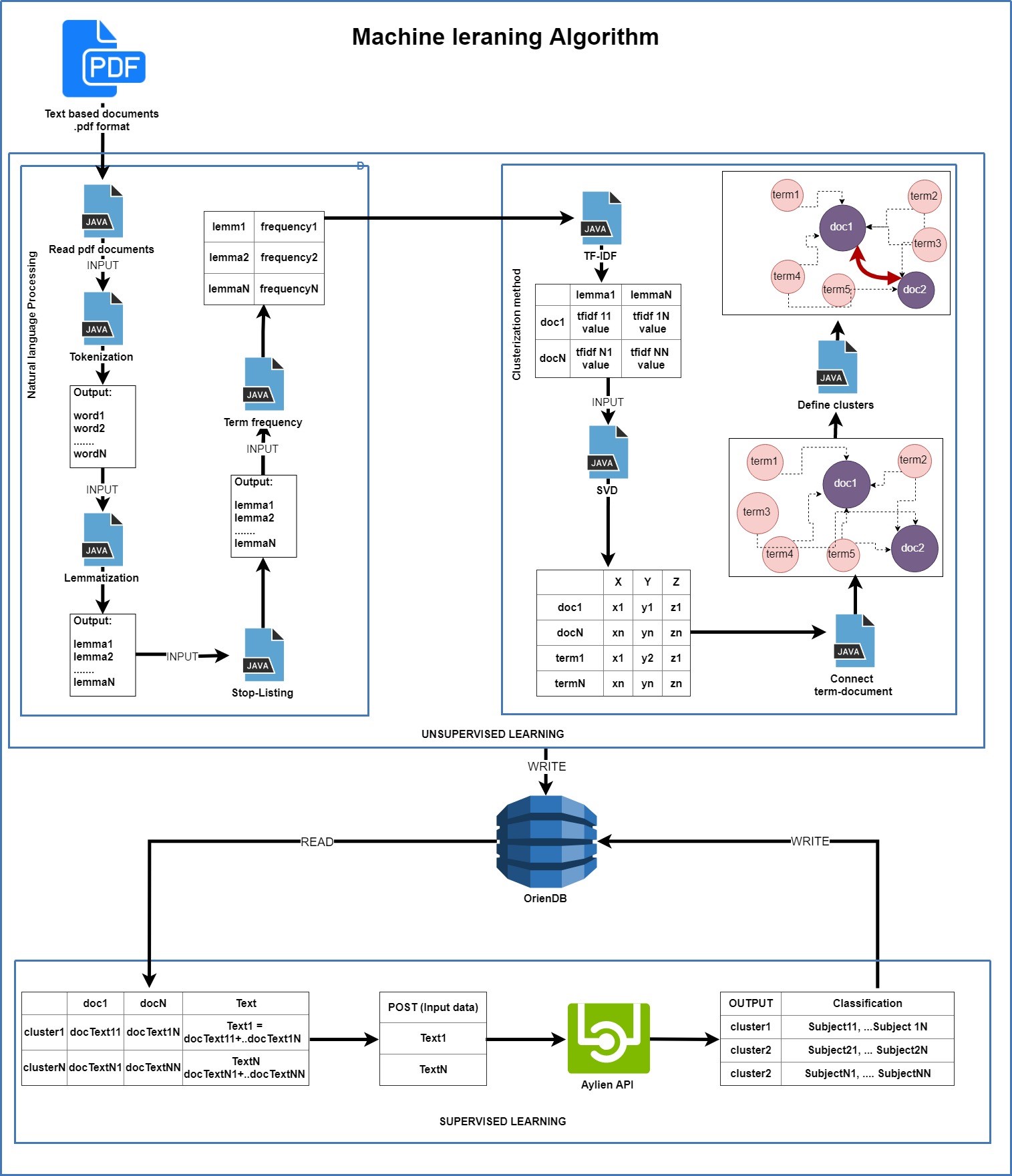
Обработка естественного языка
Алгоритм начинается с чтение любых текстовых данных. Так как система у нас электронная библиотеку, то и книги в основном в формате pdf. Реализация и детали обработки NLP можно почитать тут.
Ниже приводим сравнение при запуске алгоритмов Лемматизации и Стеммитизации:
Общее количество слов: 4173415
Количество слов после приминение Лемматизации: 88547
Количество слов после приминение Стеммитизации: 82294
При лемматизации время для обработки требуется больше, чем при стеммитизации, но качества слов значительно возрастает, и при конечном итоге точность кластеризации тоже будет увеличиваться. При применении лемматизации, алгоритм высчитывает полное слово:
characterize, design, space, render, robot, face, alisa, kalegina, university, washington, seattle, washington, grace, schroeder, university, washington, seattle, washington, aidan, allchin, lakeside, also, il, school, seattle, washington, keara, berlin, macalester, college, saint, paul, minnesota, kearaberlingmailcom, maya, cakmak, university, washington, seattle, washington, abstract, face, critical, establish, agency, social, robot, building, expressive, mechanical, face, costly, difficult, robot, build, year, face, ren, der, screen, great, flexibility, robot, face, open, design, space, tablish, robot, character, perceive, property, despite, prevalence, robot, render, face, systematic, exploration, design, space, work, aim, fill, gap, conduct, survey, identify, robot, render, face, code, term, property, statisticsа стеммитизация обрезает окончание и в некоторых случаях удаляет нужные буквы, теряя основной смысл слово:
character, design, space, render, robot, face, alisa, kalegina, univers, washington, seattl, washington, grace, schroeder, univers, washington, seattl, washington, grsuwedu, aidan, allchin, lakesid, also, il, school, seattl, washington, keara, berlin, macalest, colleg, saint, paul, minnesota, kearaberlingmailcom, maya, cakmak, univers, washington, seattl, washington, abstract, face, critic, establish, agenc, social, robot, build, express, mechan, face, cost, difficult, mani, robot, built, year, face, ren, dere, screen, great, flexibl, robot, face, open, design, space, tablish, robot, charact, perceiv, properti, despit, preval, robot, render, face, systemat, explor, design, space, work, aim, fill, gap, conduct, survey, identifi, robot, render, face, code, term, properti, statist, common, pattern, observ, data, set, face, conduct, survey, understand, peopl, percep, tion, render, robot, face, identifi, impact, differ, face, featur, survey, result, indic, prefer, vari, level, realism, detail, robot, facecharacter, design, space, render, robot, face, alisa, kalegina, univers, washington, seattl, washington, grace, schroeder, univers, washington, seattl, washington, grsuwedu, aidan, allchin, lakesid, also, il, school, seattl, washington, keara, berlin, macalest, colleg, saint, paul, minnesota, kearaberlingmailcom, maya, cakmak, univers, washington, seattl, washington, abstract, face, critic, establish, agenc, social, robot, build, express, mechan, face, cost, difficult, mani, robot, built, year, face, ren, dere, screen, great, flexibl, robot, face, open, design, space, tablish, robot, charact, perceiv, properti, despit, preval, robot, render, face, systemat, explor, design, space, work, aim, fill, gap, conduct, survey, identifi, robot, render, face, code, term, properti, statist, common, pattern, observ, data, set, face, conduct, survey, understand, peopl, percep, tion, render, robot, face, identifi, impact, differ, face, featur, survey, result, indic, prefer, vari, level, realism, detail, robot, faceМетоды кластеризации
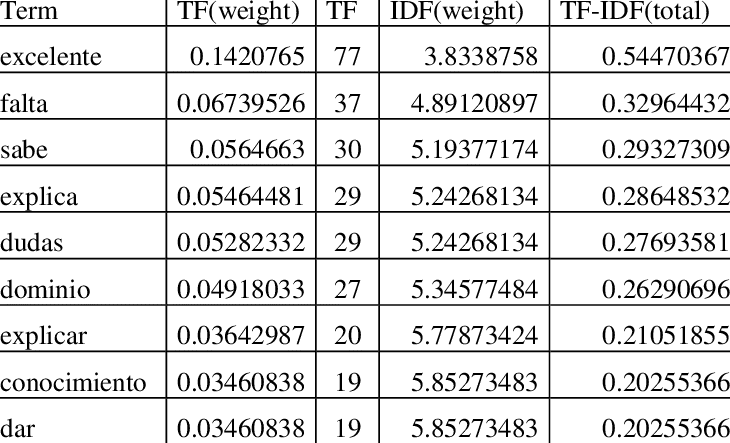
Для применения алгоритма tf-idf нужно подсчитать сколько раз слово встречается в каждом документе. Можно использовать HashMap, где ключ - слово, значение - кол-во.
После этого нужно построит матрицу документы-слова:

Далее по формуле вычисляем tf-idf:
Следующий этап, использование метода сингулярного разложение, где на вход приходит результат tf-idf. Пример выходных данных алгоритма сингулярного разложение:
-0.0031139399383999997 0.023330604746 -1.3650204652799997E-4
-0.038380206566 0.00104373247064 0.056140327901
-0.006980774822399999 0.073057418689 -0.0035209342337999996
-0.0047152503238 0.0017397257449 0.024816828582999998
-0.005195951771999999 0.03189764447 -5.9991080912E-4
-0.008568593700999999 0.114337675179 -0.0088221197958
-0.00337365927 0.022604474721999997 -1.1457816390099999E-4
-0.03938283525 -0.0012682796482399999 0.0023486548592
-0.034341362795999995 -0.00111758118864 0.0036010404917
-0.0039026609385999994 0.0016699372352999998 0.021206653766000002
-0.0079418490394 0.003116062838 0.072380311755
-0.007021828444599999 0.0036496566028 0.07869801528199999
-0.0030219410092 0.018637386319 0.00102082843809
-0.0042041069026 0.023621439238999998 0.0022947637053
-0.0061050946438 0.00114796066823 0.018477825284
-0.0065708646563999995 0.0022944737838999996 0.035902813761
-0.037790461814 -0.0015372596281999999 0.008878823611899999
-0.13264545848599998 -0.0144908102251 -0.033606397957999995
-0.016229093174 1.41831464625E-4 0.005181988760999999
-0.024075296507999996 -8.708131965899999E-4 0.0034344653516999997
Матрицу SVD можно использовать как координаты в трехмерном пространстве.
После применение сингулярного разложение, нужно записать результат в базу данных для дальнейшей обработки. Так как уже упоминалась что выходные данные – это координаты, то нужно записать эти данные в трехмерном пространстве. OrientDB поддерживает графовые базы данных, и данная поддержка и является целью использование именно OrientDB как основной базы данных. OrientDB поддерживает только двухмерные графическое пространство, но это не помешает, так как трехмерная пространство нужно только для вычислении, для графических целей можно использовать и двухмерное пространство. Все данные каждого документа хранится в объекте вершин. Данные вершины записываются в базу.
Теперь нужно применить данную операцию и для терминов, то есть слов.
Последний этап метода кластеризации – найти кластерные группы. Так как у нас уже есть трехмерная пространство, где хранятся точки документов и терминов в виде вершин, то нужно соединить эти документы и слова использовав схожий метод кластеризации DBSCAN. Для определения расстояние между документом и словом используется Евклидовое расстояние. А радиус можно определить по формуле ниже. В данном примере и при тестировании используется r=0.007. Так как в пространстве находится 562 документов и более 80.000 тысяч слов, то они расположены близко. При большом радиусе алгоритм будет связывать термин и документ в один кластер, которые не должны быть в одной группе.

где max(D) - это дистанция между документом и самой дальней точкой термина, то есть максимальная дистанция документа в пространстве. n - это количество документов в пространстве
В базе данных, вершины документов и вершины слов будут связаны с помощью ребра. Вершины коричневого цвета – документы, вершины розового цвета – термины
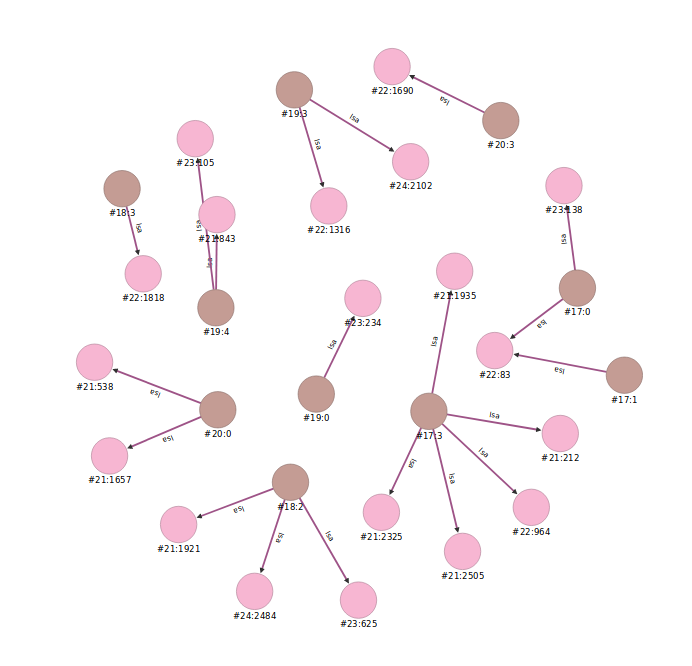
После этого нужно всего лишь соединить вершины документов, которые имеют общие вершины терминов. Для соединения документов нужно чтобы общее число терминов было больше 4-х. Формула определение общего сила слов (в данном случае > nt)

N- это количество кластерных групп термин - документов, S - это количество связей в семантическом пространстве.
Данные результаты также записываются в базу данных, где вершины документов соединены. Каждая отдельная соединенная группа документов являются кластерами
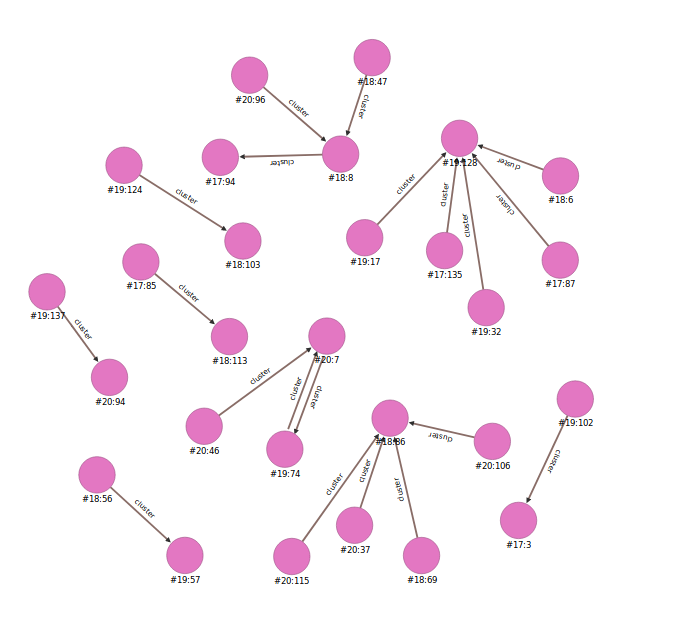
Методы классификации – Aylien API
Для классификации в инструменте Aylien API всего лишь нужно передать любой текст. API вернет ответ в виде json объекта, где внутри есть категории классификации. Можно было бы отправлять весь текст каждого документа в одной группе кластеров через API и получить категории классификации. Для примера рассмотрим 9 групп кластеров, которые состоят из статьи про ИТ технологии. Все тексты документов каждой группы записываются в массив и отправляют запрос POST через API:
String queryText = "select DocText from documents where clusters = '" + cluster + "'";
OResultSet resultSet = database.query(queryText);
while (resultSet.hasNext()) {
OResult result = resultSet.next();
String textDoc = result.toString().replaceAll("[\\<||\\>||\\{||\\}]", "").replaceAll("doctext:", "")
.toLowerCase();
keywords.add(textDoc.replaceAll("\\n", ""));
}
ClassifyByTaxonomyParams.Builder classifyByTaxonomybuilder = ClassifyByTaxonomyParams.newBuilder();
classifyByTaxonomybuilder.setText(keywords.toString());
classifyByTaxonomybuilder.setTaxonomy(ClassifyByTaxonomyParams.StandardTaxonomy.IAB_QAG);
TaxonomyClassifications response = client.classifyByTaxonomy(classifyByTaxonomybuilder.build());
for (TaxonomyCategory c : response.getCategories()) {
clusterUpdate.add(c.getLabel());
}
После успешного получение ответа от сервиса методам GET, данные группы обновляются:
На этом этапе алгоритм кластеризации и классификации закончен. Все эти данные записываются в базу данных для дальнейшей обработки и использование в веб интерфейсе.
Так же изучался и подход применение классификации без использования метода кластеризации. Результат очень сильно отличался. Так как если алгоритм не знает группы кластеров, то метод классификации будет классифицировать каждый документ отдельно. И предметы для каждого документа может быть различным и не обобщенным. Так для эксперимента, классифицируем каждый документ и находим предмет. Но для сравнения оставим кластерные группы, которые не будут влиять на саму классификацию:
Разработка веб-интерфейса
Цель разработки веб-интерфейса – наглядный вид результата использование алгоритма кластеризации и классификации. Это дает пользователю удобный интерфейс не только увидеть сам результат, но и в дальнейшем использовать эти данные для нужд. Так же разработка веб-интерфейса показывает, что данный метод можно успешно использовать для онлайн библиотек. Веб приложение было написано с использованием Фреймворка Vaadin Flow:
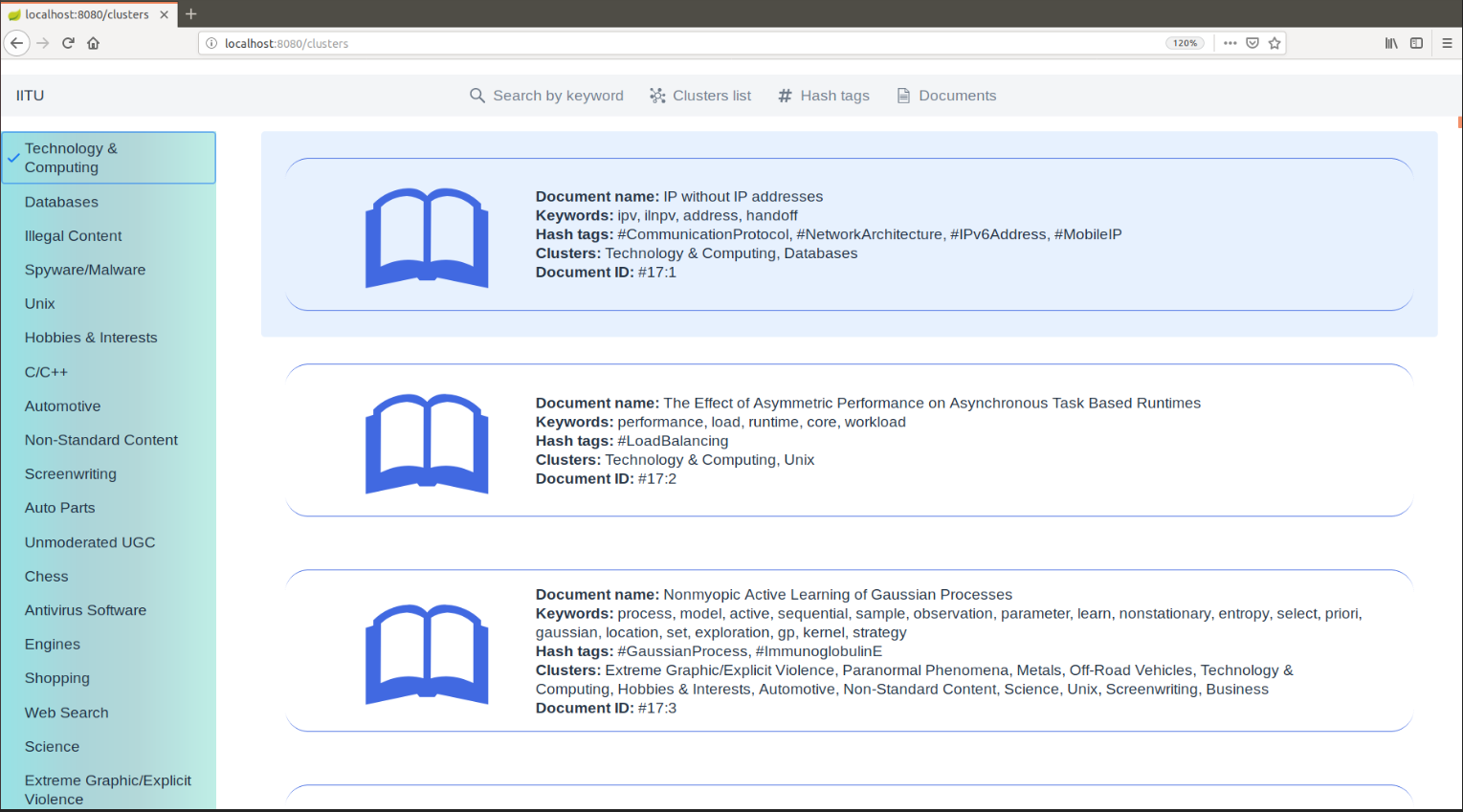
В данном приложении есть следующие функции:
Документы, разделенные по предметам методом кластеризации и классификации.
Поиск по ключевым словам.
Поиск по хэш-тегам.
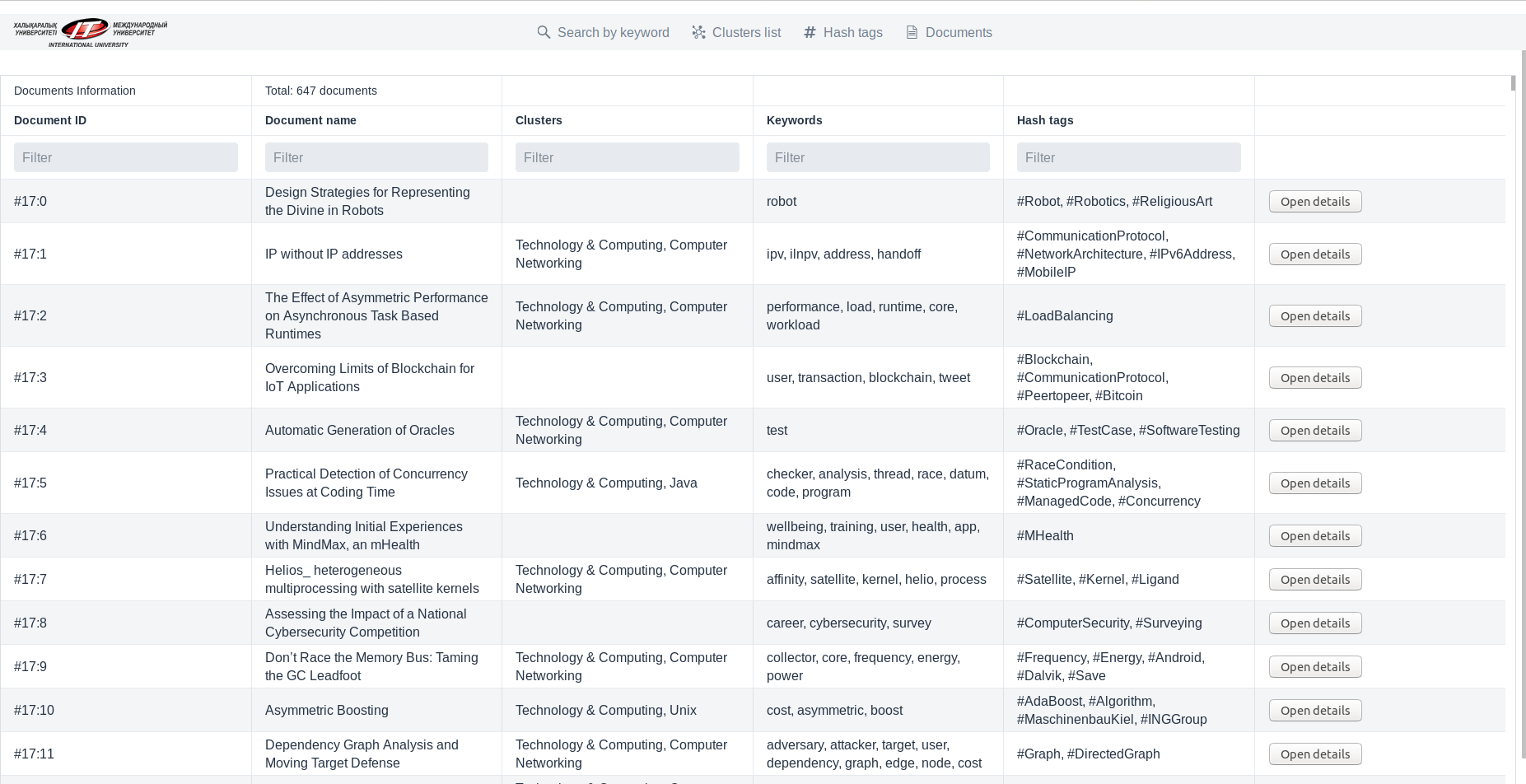
Весь список документов в базе данных, где есть возможность поиска по ИД документа, наименованию документа, предметам кластеров, ключевым словам и по хэш-тэгам.
Возможность скачивание файла.
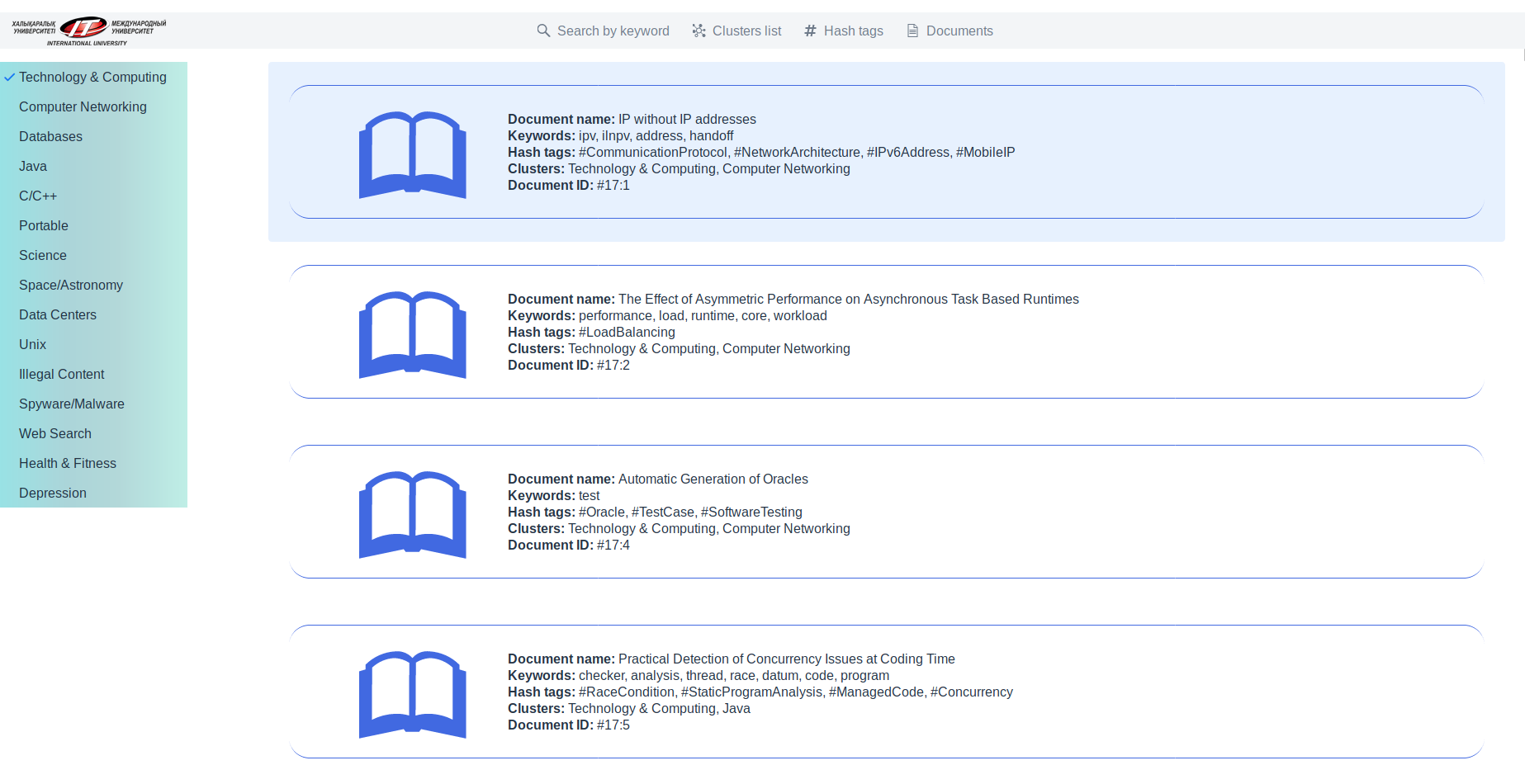
Список документов классификации по предмету “Technology & Computing”:
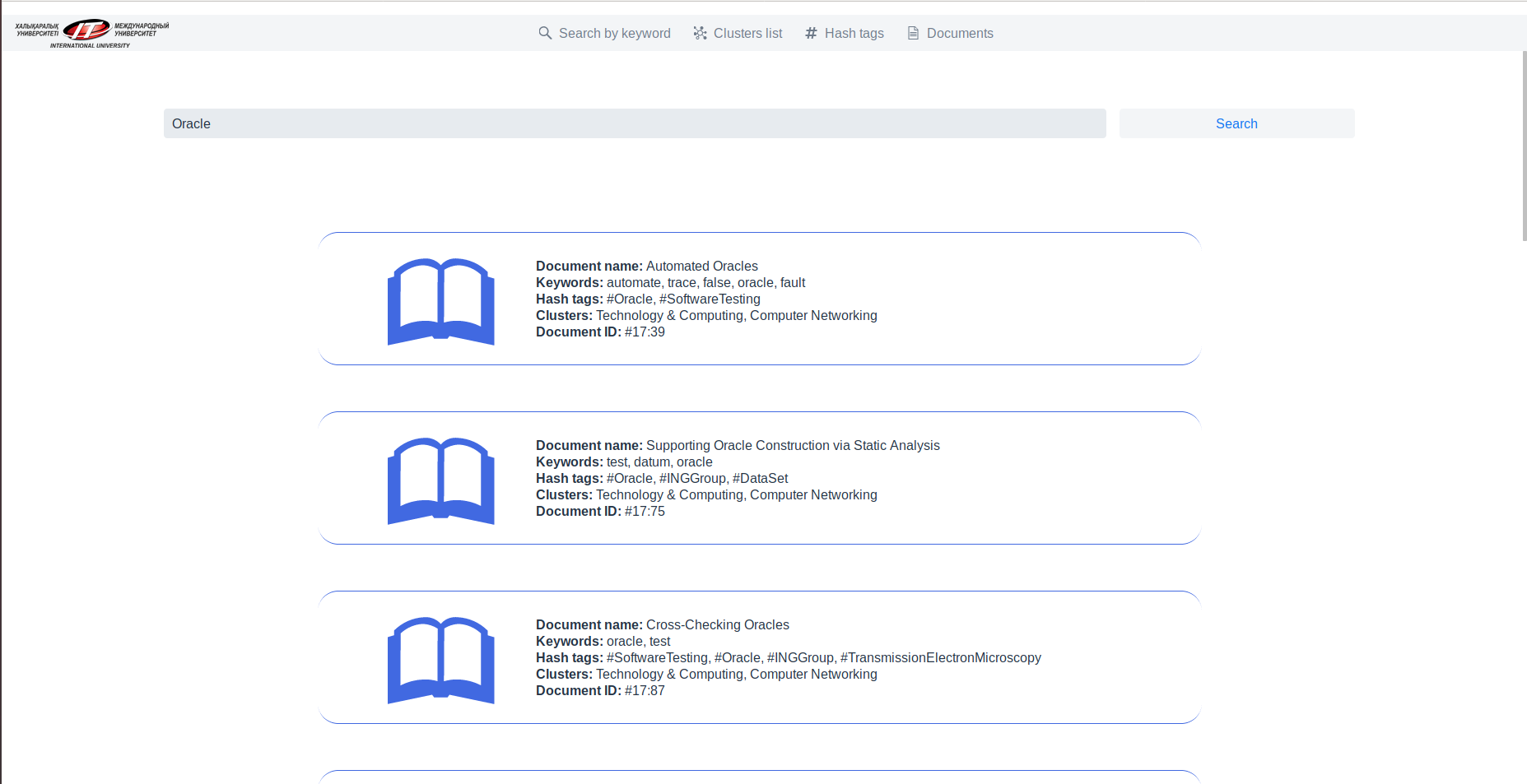
Список документов найденные по ключевым словам:
Табличный список всех документов:
Заключение
В работе был подробно рассмотрен сама концепция машинного обучение, для понимания цели использование методов или алгоритмов машинного обучения. Подробно описаны актуальные и известные методы и алгоритмы машинного обучения для решения цели и задачи работы. Так как задачи кластеризации используется для разных областей и предметов, в данной исследовательской работе было выбрано цель автоматизация процесса классификации текстовых данных, которые считаются сложнее чем обычные задачи классификации других данных. Алгоритм описанный и разработанный в данной исследовательской работе можно применять на большие количества текстовых документов на английском языке. Хотя алгоритм не сильно подвязан на язык текста. Для использования алгоритма для других языков нужно изменить алгоритмы обработки естественного языка. Алгоритм включает в себе две основных методов: кластеризация текста и классификация групп кластеров.
Разработка алгоритма кластеризации, который включают в себе последовательное применение алгоритмов лемматизации, токенизации, стоп-листниг, tf-idf, сингулярного разложение. Первые три метода относится к методу обработки естественного языка, данные методы можно изменить под язык обрабатываемого текста. Для нахождение кластерных групп используется алгоритм на основе метода DBSCAN и использование Евклидового расстояние для определения расстояние между объектами. При исследовании было доказано что точность кластеризации зависит от отношения количества кластеров к количеству объектов в одном кластере. Количество кластеров определяется радиусом каждого документа, а количество объектов в одном кластере определяется средним количеством общих объектов, в данном случае слов или терминов. Алгоритм кластеризации описанный в работе можно использовать не только для классификации групп, а и для других целей, таких как нахождение ассоциативных правил, нахождение групп документов, которые схожи по смысловому тексту и т.д.
В результате исследование, было предложено использование NoSQL базы данных, о именно OrinetDB, который поддерживает все 4 модели NoSQL. Данный тип базы данных очень хорошо подходит для хранения результатов алгоритма кластеризации, так как данный результат является не реляционным. Стоит отметить что OrientDB очень удобен для хранения, обработки и визуализации хранимых данных.
Для классификации кластерных используется Aylien API, который использует подход классификации по таксономии и на базе кодов. В результате исследовании кластерные группы были разделены по предметным областям, который включает в себя более 100 контентной категории. Данный метод можно заменить и другими, более специфическими алгоритмами машинного обучение, таких как метод опорных векторов, метод k-ближайших, нейронную сеть. Но так как данные методы требуют большое количество данных который используется для построения модели, в данной работе было использована готовая модель классификации.