Когда дело доходит до работоспособности и мониторинга, распределенная архитектура может подкинуть вам пару проблем. Вы можете иметь дело с десятками, если не сотнями микросервисов, каждый из которых мог быть создан разными командами разработчиков.
При работе с крупномасштабной системой очень важно следить за ключевыми показателями этой системы, работоспособностью приложений и достаточным объемом данных, чтобы иметь возможность быстро отслеживать и устранять проблемы. Пребывание в ОБЛАЧНОЙ среде, такой как AWS, Google Cloud, Azure, еще больше усугубляет проблему и затрудняет обнаружение, устранение и локализацию проблем из-за динамического характера инфраструктуры (вертикальное масштабирование, временные машины, динамические IP-адреса и т. д.).
Базис наблюдаемости:
Метрики - метрики приложений, метрики хоста/системы, метрики сети и т. д.
Логи (журналы) - логи приложений и поддерживающей инфраструктуры
Трейсы (трассировки) - отслеживание прохождения запроса через распределенную систему
В этой статье я сосредоточусь на двух аспектах наблюдаемости: логах (только сгенерированных приложением) и трейсах.
Логи
Использование централизованной системы логирования в распределенной архитектуре, чтобы иметь возможность собирать логи и визуализировать их, стало обычной практикой. Логи, сгенерированные различными микросервисами, будут автоматически отправляться в централизованную базу для хранения и анализа. Вот некоторые из популярных решений централизованных систем логирования для приложений:
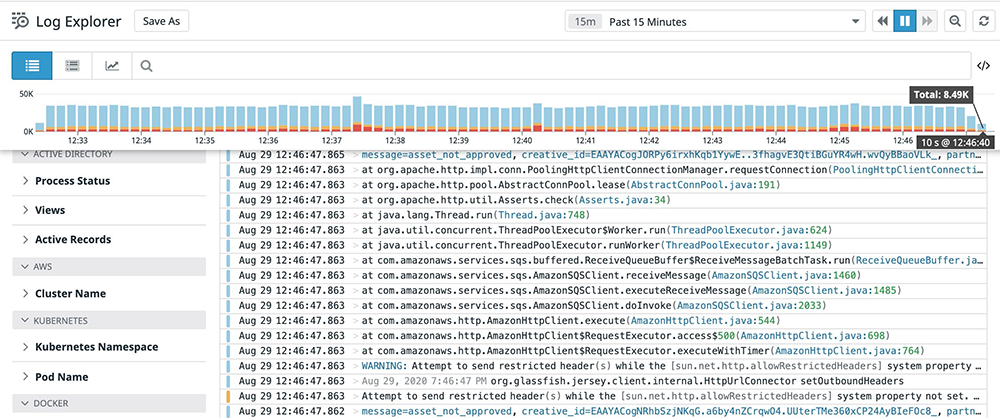
Логи предоставляют полезную информацию о событиях, которые произошли в вашем приложении. Это могут быть логи INFO-уровня или логи ошибок с подробными стек трейсами исключений.
Кореляция логов между микросервисами
Централизованная система логирования в большом распределенном приложении может принимать гигабайты данных в час, если не больше. Учитывая, что запрос может проходить через несколько микросервисов, один из способов получения всех логов, связанных с запросом, охватывающим несколько микросервисов, - это присваивать каждому запросу какой-нибудь уникальный идентификатор (id).
В большинстве случаев это может быть userId, связанный с запросом, или какой-нибудь уникальный UUID, сгенерированный в первой точке входа в приложение. Эти идентификаторы будут прикреплены к каждому сообщению в логе и будут передаваться последовательно от одного микросервиса к другому в заголовке запроса (в случае, если идентификатор не является частью последовательно обрабатываемого запроса). Так можно легко использовать requestId или userId для запроса к системе логирования, чтобы найти все логи, связанные с запросом в нескольких сервисах!!!
Ниже приведены несколько примеров того, как пометить (tag) ваши логи необходимой информацией на Java с помощью фильтров запросов (RequestFilter).
Трассировка
Трассировка - это метод, который позволяет профилировать и контролировать приложения во время их работы. Трейсы предоставляют полезную информацию, такую ??как:
Путь запроса через распределенную систему.
Задержка запроса при каждой пересылке/вызове (например, от одного сервиса к другому).
Ниже приведен пример трассировки для запроса, взаимодействующего с двумя микросервисами (сервисом-аукционом рекламы и сервисом-интегратором рекламы).
В приведенном выше примере данные были захвачены и визуализированы с помощью инструмента DataDog. Есть несколько других способов захвата трейсов, о которых я расскажу в следующем разделе.
Составляющие трейса
Трейс представляет из себя древовидную структуру с родительским трейсом и дочерними спанами. Трейс запроса охватывает несколько сервисов и далее разбивается на более мелкие фрагменты по операциям/функциям, называемые спанами. Например, спан может охватывать вызов от одного микросервиса к другому. В рамках одного микросервиса может быть несколько спанов (в зависимости от того, сколько уровней классов/функций или зависимых микросервисов вызывается для обслуживания запроса).
Трассировка зиждется на создании уникального идентификатора для каждого запроса в точке входа и распространения его на последующие системы в качестве контекста трассировки в заголовках запросов. Это позволяет связать различную трассировочную информацию, исходящую от нескольких служб, в одном месте для анализа и визуализации.
Корреляция логов и трейсов
В итоге мы можем фильтровать логи по userId или другому уникальному идентификатору (например, сгенерированному UUID) и можем отслеживать по трейсам производительность/поведение отдельного запроса. Было бы неплохо, если бы мы могли связать это воедино и иметь возможность сопоставлять логи и трейсы для конкретного запроса!!
Наличие такой корреляции между логами и запросами позволяет:
Сопоставлять метрики производительности напрямую с логами.
Направлять в систему специальный запрос для устранения неполадок.
Выполнять искусственные транзакции с системой в разные моменты времени и иметь возможность сравнивать текущие трейсы с историческими, а также автоматически собирать системные логи связанные с этими запросами.
Реализация распределенной трассировки с помощью корреляции логов и трейсов
ПОДХОД #1: Инструментация с помощью сторонних решений, таких как DATADOG
Ссылка: DataDog APM
При таком подходе мы инструментируем сервисы в распределенных системах с DataDog APM (application performance monitors - системы мониторинга производительности приложений). Datadog выполняет 100%-ную трассировку запросов, а также может собирать логи, создаваемые вашими приложениями.
Datadog по существу берет на себя заботу о централизованном логировании и сборе трассировочной информации. Datadog генерирует уникальные идентификаторы трейсов и автоматически распространяет их на все инструментированные нижестоящие микросервисы. Единственное, что от нас требуется, это связать DD traceId с логами, и мы сможем получим корреляцию логов и трейсов.
ПОДХОД #2: ZIPKINS, CLOUD-SLEUTH СО SPRING BOOT
Ссылка:
Преимущества:
Полная интеграция в SPRING boot
Простота в использовании
Трейсы можно визуализировать с помощью пользовательского интерфейса Zipkins.
Поддерживает стандарты OpenTracing через внешние библиотеки.
Поддерживает корреляцию логов через контексты Log4j2 MDC.
Недостатки:
Нет решения для автоматического сбора логов, связанных с трейсами. Нам придется самостоятельно отправлять логи в ElasticSearch и выполнять поиск, используя идентификаторы трейсов, сгенерированные cloud-sleuth (как заголовок X-B3-TraceId).
Дизайн:
ПОДХОД #3: AMAZON XRAY
Ссылка: AmazonXRAY
Преимущества:
Нативно поддерживает все ресурсы AWS, что очень хорошо, если ваши распределенные сервисы развернуты и работают в AWS
Балансировщики нагрузки AWS автоматически генерируют идентификаторы (REQUEST ID) для каждого входящего запроса, что освобождает приложение от этой заботы. (Ссылка)
Позволяет выполнять трассировку на всем пути от шлюза API до балансировщика нагрузки, сервиса и других зависимых ресурсов AWS.
Реализует корреляцию логов с помощью логов в CLOUDWATCH logs
Недостатки:
Cloudwatch log может стать очень дорогими при большом объеме логов
ПОДХОД #4: JAGER
Ссылка: Jager
Преимущества:
Поддерживает opentracing по умолчанию
Имеет библиотеки, которые работают со Spring
Поддерживает Jager Agent, который можно установить в качестве средства распространения трейсов и логов.
Недостатки:
С точки зрения обслуживания и настройки инфраструктуры достаточно сложен.
ЗАКЛЮЧЕНИЕ
Логи и трейсы сами по себе безусловно полезны. Но когда они связаны вместе с помощью корреляции, они становятся мощным инструментом для ускорения устранения проблем в производственной среде и в то же время дают девопсу представление о работоспособности, производительности и поведении распределенных систем. Как вы увидели выше, существует несколько способов реализации этого решения. Выбор за вами :-)
Перевод статьи подготовлен в преддверии старта курса "Архитектура и шаблоны проектирования". Узнать подробнее о курсе.

chemtech
Странно что не упомянут jaeger.