
В начале 2014 года к нам в отдел контентных проектов пришла задача унификации дизайна. Дизайнеры хотели единый стиль проектов и принципы работы интерфейсов. Это будет удобно пользователям, облегчит запуск новых проектов и редизайн существующих (более подробно об этом писал Юра Ветров). Команда фронтенда получит возможность использовать схожие компоненты верстки на разных проектах, что уменьшит время разработки и поддержки существующего функционала. Для команды бэкенда задача оказалась нетривиальной: большинство наших проектов написана на Perl (Template Toolkit), Недвижимость на PHP, Дети и Здоровье используют Django. Но от нас требовалось реализовать не только поддержку единого шаблонизатора, но и согласовать единый формат отдаваемых данных в шаблоны. Обилие подгружаемых AJAX-блочков требовало поддержку еще и клиентской шаблонизации.
Таким образом, задача унификации дизайна превратилась в задачу выбора единого шаблонизатора для Perl, Python, PHP и JS.
Первые шаги
Задача казалась сложной и в полной мере не решаемой, мы стали искать разные варианты. Начали с готовых решений. Первой идеей было портировать шаблонизатор Django Dotiac::DTL на Perl или template toolkit на Python. Template toolkit позволяет писать программную логику в шаблонах, это делает их непереносимыми на другие языки. Шаблоны Django значительно ограничивают программирование в шаблонах, но и от расширений в виде фильтров и своих тегов придется отказаться, либо дублировать логику на Perl и JS. Кроме того, неизвестно, насколько функциональны портированные версии. Таким образом, эта идея свелась к использованию базовых конструкций шаблонизатора (блоки условий if/else, циклов for, включений include). Для этого полноценный порт не нужен. А функционал, который хочется использовать, но нельзя по тем или иным причинам (например, не реализован на другом языке, либо реализован иначе), будет только мешать общему процессу. Поэтому до тестирования производительности мы так и не дошли. Эту идею отложили.
Вторая идея была использовать Mustache. Этот шаблонизатор доступен на множестве языков от популярных в вебе (PHP, Python, Perl, Ruby, JS) до весьма далеких от него (R, Bash, Delphi). Отсутствие логики в шаблонах поначалу даже привлекало: процесс подготовки данных для шаблонизации контролирует полностью бэкенд, никакой логики в самих шаблонах. Но это оказалось излишней крайностью. Подготовка данных показалась слишком трудоемкой, механизм инклюдов (partials) был неудобным, требовался сборщик шаблонов. Вместе с фразой «на мой взгляд, это кусок ада на земле» мы перестали рассматривать усы.
Еще была идея написать свой простой шаблонизатор на всех необходимых языках, либо мета-описание, из которого можно будет создавать нужные шаблоны. Задача выглядела трудоемкой, мы продолжили искать варианты.
Fest
Fest — это шаблонизатор, компилирующий XML шаблоны в JavaScript функции. В то время у нас уже был опыт использования феста в мобильных версиях. Основное отличие от больших версий было в том, что в то время поисковые роботы уделяли мало внимания мобильным версиям, и мы могли позволить себе шаблонизацию полностью на клиенте, экономив при этом ресурсы сервера. Выглядело это следующим образом в HTML-странице:
<script>
document.write(fest[’news.xml’], context)
</script>
Где context — это сериализованные в JSON данные. Отрендеренный HTML выводился в страницу через document.write.
Использование феста решает вопрос шаблонизации на клиенте, нам нужно было научиться исполнять этот JS на сервере. Команда фронтенда также поддержала этот вариант. Для исполнения JavaScript на сервере мы выбрали популярный V8 от Google. V8 развивается стремительно, но постоянные «Performance and stability improvements» часто ломают обратную совместимость даже в минорных версиях. Это понятно, V8 разрабатывается в первую очередь для Chrome — браузера, новые версии которого приходят взамен старым. Мы начали использовать V8, перенимая опыт наших коллег из Почты.
V8
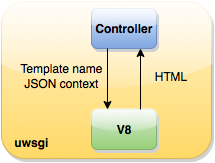
Первым делом мы стали искать готовые решения — биндинги для Python и Perl. Немного помучавшись со сборкой пакетов (V8 значительно опережают свои биндинги, и подобрать совместимые версии оказалось непросто), мы стали их пробовать. Сразу же заметили дорогое поднятие контекста: создание контекста занимает порядка 10 мс, рендеринг шаблона — 20 мс. Таким образом, контекст должен создаваться 1 раз на запрос, а, в идеале, переиспользоваться последующими. Поэтому никакой речи не шло о том, чтобы встроить рендеринг общих компонентов на фесте в родной шаблонизатор (TemplateToolkit или Django). На фест надо переходить полностью.
Эти биндинги вполне внушали доверие, проекты развивались, в интернете публиковались примеры использования. И мы стали их использовать. В то время шел редизайн проектов Авто (Perl) и Здоровье (Python), на них мы испытывали новую технологию. В контроллерах мы формировали контекст, сериализовали его в JSON, и отправляли в загруженный шаблон:
ctx = PyV8.JSContext()
with ctx:
ctx.eval(template)
ctx.eval('fest["%s"](%s)' % (fest_template_name, json_context)
Это был рабочий вариант, но все оказалось не так радужно. Помимо, собственно, шаблонов, существуют общие утилиты-хелперы. Их следует загружать в V8 один раз и использовать при рендеринге страниц. Обертки над V8 позволяли загружать такой код, но делать это нужно было строго один раз. Повторная загрузка приводила к утечке памяти. То же происходило и с кодом шаблонов. В результате контекст создавался на каждый запрос, а после — убивался. Шаблонизация проходила медленно, значительно тратились ресурсы процессора, но память не текла. Но все работало более-менее стабильно. В итоге Авто запустился на этой схеме.
Обертки над V8 позволяют использовать объекты языка в контексте JavaScript. Но в случае с PyV8 это совсем не работает. Все версии, которые я пробовал, либо быстро утекали, либо очищали память, но падали в segfault. Использование биндингов свелось чисто к исполнению JavaScript с некоторым оверхедом, так как биндинг честно проверяет тип переданных объектов. На Здоровье пробовать PyV8 в бою мы уже не стали.
Тем временем коллеги с почты поделились своим решением. Это отдельно живущий демон, который получает имя шаблона и контекст (JSON-строка), в ответ отдает HTML, который мы отдаем пользователю. Во многом он решает наши проблемы. Демон умеет загружать общие хелперы на старте, кешировать в память шаблоны, работает стабильно по скорости и по памяти. Но все же это было не идеальное решение. Этот инструмент Почта разрабатывала под свои задачи, которые отличаются от наших. Их шаблоны значительно меньше и легче наших и исполняются быстрее. Ранее Андрей Сумин писал про 1 мc на шаблонизацию (JavaScript на сервере, 1ms на трансформацию), мы имеем в среднем 15-20 мс.
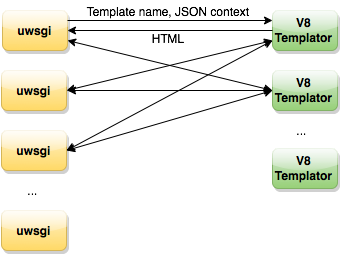
Их решение предполагает один процесс демона-шаблонизатора на сервер, мы себе это позволить не можем. Хотя для нас коллеги сделали мультипроцессорную версию, проблемы, требующие решения, оставались:
- Отдельно стоящий демон требует стабильной работы. Его работу нужно мониторить, уметь быстро переключаться на резервный сервер.
- Логи с ошибками не связаны с адресом страницы, на которой они возникают.
- Логи пишутся в файл, а не в общую систему сбора статистики.
- Чтобы не было задержек, надо иметь одинаковое количество воркеров бэкенда и демона-шаблонизатора.
Еще у нас был интересный случай. Однажды в шаблонах по ошибке возник вечный цикл, он полностью занимал воркера, это приводило к плачевным последствиям. Хотя подобных случаев впредь не возникало, защиты от таких ошибок у нас не было. В итоге с этой схемой запустилось Здоровье. Но на этом мы не остановились. Следующим шагом был отказ от отдельного демона, мы решили встроить шаблонизацию в исполняемый процесс Perl и Python. В итоге была написана общая обертка над V8, которая умела читать JS-файлы (хелперы и шаблоны), загружать код в память и исполнять (т.е. рендерить шаблоны в HTML).
Модуль поднимает один контекст V8 на процесс и всю дальнейшую работу ведет в рамках него. В результате такого подхода родилось и название для библиотеки — V8MonoContext. Затем мы написали XS-модуль на Perl и расширение для Python, использующие эти функции в контексте языка:
renderer = MonoContext()
renderer.load_file(utils_file)
append_str = 'fest["{}.xml"]( JSON.parse(__dataFetch()) );'.format(bundle)
html, errors = renderer.execute_file(template_file, append_str, json_str)
Хелперы загружаются 1 раз при старте процесса с помощью метода load_file. Метод execute_file загружает шаблон, вызывает функцию шаблона, в которую передается JSON с данными для шаблонизации. В результате мы получаем HTML и список возможных ошибок, которые можно логировать через стандартные средства самого бэкенда. Сейчас это решение нас полностью устраивает:
- Шаблонизация является неотъемлемой частью обработки запроса пользователя внутри одного воркера. Мы можем измерить, сколько времени она занимает, логировать возможные ошибки.
- Контекст V8 поднимается один раз при старте воркера.
- JS-код загружается один раз, ресурсы сервера расходуются оптимально.
- V8 потребляет больше памяти, чем «родные» шаблонизаторы языка. Резидентная память воркеров увеличилась в среднем на 200 Мб, в максимуме на 300 Мб.
- Также не поддерживается тредовый режим, что может быть актуально для Python-проектов. Внутри одного процесса может исполняться только один контекст, остальные в это время должны быть неактивны. Так работает V8 в Chrome. Но это нам не мешает, мы работаем в prefork-режиме.
Наблюдаются и другие особенности работы V8, связанные с GC. V8 запускает свой сборщик мусора в то время, как он посчитает нужным, как правило, если память начинает заканчиваться. Существует 2 метода жить с этим:
- Запастись оперативной памятью и полностью довериться V8. Контекст V8 погибнет вместе с воркером через заданное значение MaxRequest.
- С некоторой периодичностью запускать «ручку» — сигнал о нехватке памяти LowMemoryNotification. Редкий запуск грозит продолжительной уборкой, частый будет расходовать лишние ресурсы процессора. Мы вызываем LowMemoryNotification каждые 500 запросов на шаблонизацию.
Еще можно ограничить размер выделяемой памяти для V8 (Memory management flags in V8). В этом случае GC будет запускаться чаще, но отрабатывать он будет быстрее. При нехватке памяти сервер может откладывать часть хипа в своп, а это приводит к дополнительным задержкам. В итоге на этой схеме запустилась Афиша, результаты нас полностью устроили. Вскоре с V8MonoContext научился работать PHP, следом подтянулись и другие наши проекты — Авто, Гороскопы, Здоровье, Леди, Недвижимость, Погода, Hi-Tech.
Сравнение производительности
Надо отметить, что скорость работы шаблонизатора на V8 (так же, как и любого другого активного шаблонизатора) зависит от того, с каким объемом данных он работает и какая логика к ней применяется. Чистое время рендеринга можно определить только на синтетических тестах, которые могут не всегда отражать реальную картину. В нашем случае переход с V8 происходил с редизайном, поэтому точных замеров у нас нет. Косвенно сравнивая метрики, мы получили выигрыш до 2 раз.
Подход к разработке
С переходом на фест поменялся и подход к разработке:
- Общие компоненты шаблонов должны иметь единый интерфейс для проектов, которые его используют. Это требует определенного порядка и согласованности всех участников процесса. Мы начали описывать в документации формат передаваемых на фронт данных и следовать ему. Кроме этого, мы вырабатываем общие системные решения для разных бэкендов (Perl, Python, PHP), например, работа с CSRF-токенами.
- Общие компоненты расходятся по всем проектам, поэтому особенно важно, чтобы они работали быстро и эффективно.
- У нас получилась чистая MVC-схема, в которой бэкенд отдает данные и совсем не трогает шаблоны. Если на фронте каких-либо данных не хватает, нужно ждать бэкенда.
Выводы
Поставленную задачу перехода на единый шаблонизатор для Perl, Python, PHP мы решили. Теперь общие компоненты (например, комментарии, галереи, опросы) могут быстро внедряться и расходиться по всем нашим проектам. Жирным плюсом стала для нас клиентская шаблонизация: теперь перенести логику на сторону клиента практически ничего не стоит. Следующей в этой серии будет статья со стороны фронтенда, которую мои коллеги уже готовят.
Комментарии (32)

vintage
14.09.2015 17:20-2Другой подход — рендерить только на клиенте, а когда нужно на сервере — делать это через какой-нибудь prerender.io

blackhearted
14.09.2015 20:051. Скорость визуализации html-я в браузере полученного напрямую с сервера все равно будет быстрее чем загрузка страницы, которая должна будет потом получить данные для рендеринга, затем сам шаблон и только потом сделать шаблонизацию клиентом.
2. Дополнительно придется держать ноду в продакшене на всех бэкендах с дополнительной библиотекой, которая не очень понятно как справляется с нагрузкой.
Подход описанный в статье позволяет получить стабильное решение с использованием уже существующего стека технологий на бэкенде, при условии что проект уже использует Perl, Python или PHP.vintage
14.09.2015 21:591. Не сильно-то и быстрее. Зато при рендеринге на клиенте хтмл и прочие ресурсы можно намертво закешировать, динамически подгружая лишь собственно данные, без раздутого тэгами и классами хтмл.
2. Вы всё-равно держите v8 в продакшене на всех бэкендах с дополнительной библиотекой, которая не очень понятно как справляется с нагрузкой :-)
3. Позвольте уж усомниться в стабильности решения, где из трёх совершенно разных языков идёт обращение к четвёртому языку через три реализации моста между ними. Всё же «взять вебкит, загрузить в него страницу и сдампить полученное дерево» — более железное решение, гарантированно совместимое с любыми серверными языками.oblomikus
14.09.2015 23:031. Вероятнее всего полученный после рендеринга html кешируется, кроме того не все поисковые боты умеют(или умели) шаблонизацию на клиенте. Большая часть данных страницы все же не html.
2. Вряд ли кто-то выводит в продакшн решение без тестирования и замеров :). Ну и в статье вроде есть про выигрыш до 2-х раз:).
3. Из тех же языков ломиться к 4-му всеравно приходится. И про решение про демона все же было упомянуто.
в остальном решение с демоном тоже работает.vintage
14.09.2015 23:191. HTML с данными сложнее кэшировать — нужно избавляться от динамики, добавляя её уже скриптами после загрузки. Кроме того, всё равно перед показом страницы из кеша придётся делать запрос «а не изменилось и что». Вот для ботов-то как раз и необходима шаблонизация на сервере. Для обычного браузера современные высоко динамичные аяксовые сайты проще рендерить на клиенте, общаясь с сервером через тот же апи, через который к нему обращаются и мобильные приложения.
2. О том и речь, что аргумент этот так себе :-)
3. В случае с prerender.io и тп серверу вообще не надо знать про него, куда уж там «ломиться». Он выступает просто как рендеряще-кеширующий прокси.oblomikus
15.09.2015 11:041. Так я и имел ввиду что шаблонизация на сервере нужна для ботов. При правильно настроенном кэшировании доп. запросы могут вообще не понадобится, кеширование с данными конечно зло, но оно хорошо помогает разгрузить ресурсы. А без рендера на клиенте все равно не обойтись (большАя часть данные прилетает потом).
2. Ну выигрыш в 2 раза по ресурсам сервера я бы не назвал маленьким.
3. Дополнительный «демон» с доп. ресурсами, живущий так же своей жизнью. в случае либы, все-таки все собирается в «один процесс».vintage
15.09.2015 13:542. Речь о том, что вы вменяете в качестве недостатка этому способу то, что вы не замерили скорость его работы. Сомнительный аргумент.
3. Отдельный демон лучше масштабируется. Вы не любите микросервисы?oblomikus
15.09.2015 16:122. замеры конечно делали, не полноценные, а по «минимальным» и «максимальным» шаблонам.
3. беки тоже отлично масштабируются. Микросервисы дело неплохое, но сложно назвать микросервисом довольно «толстых» демонов отвечающих только за шаблонизацию.
blackhearted
15.09.2015 13:28+2Тема client-side vs server-side rendering довольно холиварная, но все же отвечу :)
1. Здесь все не так однозначно.
Во-первых, данный показатель сильно зависит от того как часто одни и те же юзеры заходят на проект, сколько делают внутренних переходов, от того как часто проекты релизятся и т.п.
У нас в контент проектах человек может зайти, например, в пятницу на tv.mail.ru, посмотреть главную страницу со своими любимыми каналами и уйти на неделю не сделав ни одного дополнительного хита. В середине следующей недели мы выкатываем релиз, в котором очень вероятно изменился какой-то компонент, из-за чего пришлось пересобирать шаблоны и js-библиотеки. В итоге клиент при заходе на тот же ресурс через неделю опять получает всю пачку статики.
Во-вторых, кроме проблемы с «первым запросом» еще есть проблемы с мобильными версиями, где железо зачастую менее производительное чем на десктопах и на шаблонизацию у них будет уходить больше времени. Хотя здесь ситуация постепенно и меняется в лучшую сторону, но людей со старыми смартфонами еще много.
Размер json данных и готового html я бы не стал учитывать вообще, т.к. после gzip они будут иметь сопоставимый вес. Например, если взять главную одного из наших проектов, то на ней html весит 300КБ, а данные для нее 80КБ. После gzip — 45 и 17 соответственно. Да, разница есть, но несущественная.
2. Мы держим v8 в продакшене, который работает в контексте привычного для нас языка и используем его только для шаблонизации. С нагрузкой справляется хорошо, иначе бы не было этой статьи :)
Именно для того, чтобы снять лишние вопросы мы решили выложить все свои наработки по этой теме в паблик. По исходникам должно быть видно, что решение очень простое и все во что тут можно упереться — это сам v8, а точнее его gc, но с этим вы столкнетесь и на ноде, только в еще большем объеме.
3. Реализаций сишных «прослоек» великое множество на любых языках. Они пишутся для того чтобы ускорить какие-то части кода, если стандартных средств языка не хватает. Либо если требуется сделать биндинг к какой-то популярной C/C++ библиотеке. Считайте что это как раз наш случай. Сама прослойка очень тонкая и является, по-сути, интерфейсом к v8monoctx.so. Ее реализация на Perl, Python и PHP весьма простая и она не привносит практически никакого оверхэда в работу проекта.
Сам модуль v8monoctx тоже простой. Его основная задача состоит в том, чтобы создать контекст v8, загрузить в него один раз все js-тулзы и дальше заниматься только компиляцией/кэшированием и выполнением самих шаблонов.
А вот в «железности» Вашего решения есть несколько сомнений:
— речь идет не просто о «взять вебкит, загрузить в него страницу и сдампить полученное дерево», а о работе ноды + вебкита + prerender.io. Это заведомо более длинная цепочка технологий, чем просто один голый вебкит. В нашем случае есть только v8.
— prerender.io на каждый запрос к нему сгенерит кучу внутренних запросов и будет вести себя как браузер, т.е. кэшировать (очевидно на диск) полученные ресурсы, а при повторных запросах валидировать кэш и делать прочую браузерную работу.
Таким образом мы получаем у себя на серверах кучу браузеров, которые кроме шаблонизации делают еще множество вспомогательной работы требующей ресурсы.
— ну, и, пожалуй, самый главный момент. Node.js — это в первую очередь асинхронный сервер. Поэтому его основная задача состоит в том, чтобы обслуживать кучу соединений, а не исполнять код, который требует значительных ресурсов CPU. Либо надо делать какой-то prefork сервер из нее, что уже точно будет выглядеть как зоопарк.
Как уже было сказано в статье наши шаблоны отрабатывают в среднем за 20мс, плюс к этому могут случаться всплески из-за работы gc.
Поэтому предлагая ноду в качестве сервера надо понимать, что пока идет шаблонизация или gc при обработке какого-либо запроса, все остальные клиенты будут ждать свою очередь! Именно поэтому мы выполняем v8 в синхронном режиме в наших обычных воркерах. Они просто предназначены для задач, в которых активно используется CPU.
Если проводить аналогию, то тут напрашивается nginx. Если начать при помощи него ресайзить картинки, писать кучу бизнес-логики на LUA, вкомпилить в него perl и т.п., то nginx превратится в тыкву и вместо обслуживания тысяч запросов будет ждать когда освободится процессор.
Конечно, можно представить, что запросов от поисковиков сравнительно мало, но ситуация опять не так однозначна… Яндекс и Гугл частенько приходят со своими краулерами одновременно, плюс к этому всегда есть пара ботов, которые маскируются под поисковик.
А поскольку «браузер» на бэкенде требует больше ресурсов для рендеринга, то нагрузка от поисковиков может оказаться не такой уж и маленькой как кажется.
И самое противное в этой истории, что любой сканер, ab, siege и т.п. может в любой момент прикинуться гуглом и устроить нагрузку, которую довольно сложно прогнозировать.
Мне кажется предложенное Вами решение можно применять в несильно нагруженных проектах где уже используется нода.
Либо в проектах типа Google Analytics, где вообще ничего не надо индексировать и сайт работает как одно большое приложение написанное на js. Там бэкенду достаточно отдавать только json, а вся шаблонизация ложится на плечи клиента
3al
15.09.2015 13:38кроме проблемы с «первым запросом» еще есть проблемы с мобильными версиями, где железо зачастую менее производительное чем на десктопах и на шаблонизацию у них будет уходить больше времени.
А есть бенчмарки? Просто по ссылке, которую я чуть ниже кинул, на мобильных клиентах всё точно так же, как на десктопных: шаблонизация действительно идёт дольше, но отрисовка отрендеренного сервером замедляется точно в той же пропорции.blackhearted
15.09.2015 13:54У нас был проект, который шаблонизировался полностью на клиенте. Основные проблемы у нас возникали как раз с мобильными пользователями. Конкретное время, которое тратилось на шаблонизацию тогда я сейчас уже, увы, не скажу…
Проблема в том, что у нас разный html генерится для веб и мобильной версии, поэтому сравнивать было бы некорректно.vintage
15.09.2015 14:35Тут ещё многое зависит от того чем вы рендерите. Есть быстрые способы рендеринга, а есть медленные. Например, стандартный паттерн собирать строку из кусочков, а потом вставлять её в дом в современных браузерах медленнее, чем сразу создавать дом узлы (раньше было наоборот). Или вот, например, AngularJS сначала рендерит шаблон в дом, а потом наполняет его данными — это куда медленнее, чем сначала отрендерить всё дерево, а потом его подклеить в дом.
vintage
15.09.2015 14:281.1. Вы пробовали application cache? Клиенту можно быстро показать версию приложения недельной давности, тем временем в фоне подгружая актуальную версию. При желании можно заморочиться и сделать горячую замену старой версии на новую сразу после загрузки оной, но проще не париться и принять, что версия клиента может быть слегка устаревшей.
1.2. То есть клиентская шаблонизация вас смущает по причине скорости, а что gzip не бесплатен не смущает? :-) Впрочем, не очень верится, что для отображения главной на маленьком экране смартфона требуется аж 80кб данных. Думаю тут стоило бы оптимизировать объём загружаемых данных, грузить их лениво, например, а не заставлять старый телефон рендерить 300кб хтмл кода.
3.1. Генерировать хтмл для пользователя через prerender.io разумеется гиблая затея ввиду больших задержек. Речь о том, чтобы не рендерить его для пользователя вообще (только для ботов, которые подождут лишних пол секунды в очереди). И о том, чтобы выпилить с сервера всю логику для загрузки и подготовки данных для шаблонов, оставив лишь простое и стройное API, которое никак не зависит от выбранного шаблонизатора и прочей клиентской логики. У архитектуры «сервер-апи + куча клиентов» масса преимуществ перед архитектурой «сервер, реализующий половину клиентской логики + один клиент, частично её дублирующий + неполнофункциональное апи для полноценных приложений»
3.2. Тупление рендерящего хтмл для ботов сервера никак не скажется на приложениях, которые работают, через легковесный апи, не тратящий время на шаблонизацию.
3.3. Вы не правы, микросервисная архитектура лучше масштабируется, что куда важнее как раз для высоко нагруженных проектов.blackhearted
15.09.2015 16:161.1. Кроме старого приложения могут потребоваться еще и данные из базы недельной давности… Согласовывать все эти кэши разного уровня тоже непростая задача.sdf
1.2. gzip линейный в плане потребления ресурсов и поэтому беспокоит мало, к тому же он действительно мало потребляет. Конечно, если у вас сервер раздает статику терабайтами, то и gzip начнет вносить свой вклад в нагрузку. Тогда можно заюзать nginx.org/ru/docs/http/ngx_http_gzip_static_module.html
80КБ — это веб версия, конечно
3. На мой взгляд проблема в том, что нода как асинхронный сервер плохо подходит для задач, требующих значительных ресурсов CPU. То что ее можно поднять в огромном количестве на нескольких серверах вовсе не значит что это оптимальный вариант. Железо у нас тоже не безлимитно.
p.s. Скорость ответа для поисковиков, насколько я помню — это одна из метрик при ранжировании…vintage
15.09.2015 18:511.1. Зачем именно устаревшие данные? Или вы о том, чтобы показать данные из кэша пока грузятся актуальные? Ну так это тоже не сложно, если используется реактивная архитектура приложения.
1.2. При чём тут нагрузка на сервер? Мы же про бабушкофоны :-)
3. Вебкит отдельным процессом крутится же, нода им просто управляет.
4. Вклад этой метрики даже если и есть, то незначителен на фоне остальных. И это хороший вопрос, скорость какой страницы они мерят: по исходной ссылке или преобразованной.blackhearted
15.09.2015 19:45Касаемо aplication cache. Мы стараемся не делать кэширование страниц документа на стороне клиента, т.к. это может приводить к различным негативным эффектам, например вместе со страницей закэшируется реклама или счетчики.
Все это безусловно можно победить, но надо понимать, что проектов много, у всех своя специфика и просто так всех на «реактивную» архитектуру не пересадить.
К тому же тема статьи именно про унификацию бэкенда, а не про архитектуру клиентской части. Про это скорее всего будет отдельная статья :)
Gzip для мобильного телефона важен, т.к. экономит трафик, без него просто нельзя работать. Отличие от js тут в том, что если gzip на телефоне тратит 1мс cpu на inflate, то он и дальше будет тратить 1мс, в отличии от v8 у которого может неожиданно случиться gc.
А вот про вебкит отдельным процессом интересно. Можете показать какой нибудь список работающих процессов (ps ax) где было бы видно ноду и отдельно работающий вебкит? При условии что в несколько потоков к ноде идут запросы от поисковиков, сколько у него там процессов, трэдов и т.п.?vintage
15.09.2015 22:53Appcache предназначен для кеширования не готового DOM, а ресурсов приложения (пустая хтмлина без данных, скрипты, стили, интерфейсные картинки и тп). Кроме быстрого старта приложения он позволяет работать ещё и в оффлайне, работая, например, с localStorage в качестве источника данных.
Боюсь, что не могу.
3al
15.09.2015 02:46> 1. Скорость визуализации html-я в браузере полученного напрямую с сервера все равно будет быстрее чем загрузка страницы, которая должна будет потом получить данные для рендеринга, затем сам шаблон и только потом сделать шаблонизацию клиентом.
http://www.onebigfluke.com/2015/01/experimentally-verified-why-client-side.html
If you care about first paint time, server-side rendering wins. If your app needs all of the data on the page before it can do anything, client-side rendering wins.
blackhearted
15.09.2015 13:31Да, нас заботит время первой отрисовки, также как и все последующие )
3al
15.09.2015 13:32Не первой отрисовки, а начала отрисовки. Server-side раньше начинает, но позже заканчивает.
blackhearted
15.09.2015 13:44Это больше синтетический тест. В реальности кроме котиков еще есть вагон js-библиотек, которые используются при рендеринге шаблона. Их тоже надо притащить клиенту, скомпилировать и т.п.
В нашем случае это все живет внутри воркера и грузится в него один раз.
Кроме этого шаблонизация на сервере более предсказуема в плане нагрузки, не говоря уже о мониторинге и прочих метриках за которыми становится легко следить.vintage
15.09.2015 15:28Хороший повод выкинуть вагон js-библиотек и воспользоваться чем-то легковесным. Я вот, разрабатываю микромодульный фреймворк, где чтобы отрендерить страничку не нужно грузить кучу огромных либ, а только несколько килобайт кода. Вот небольшое демо, если интересно :-)
bekbulatov
15.09.2015 10:57Перечисление юзерагентов, кому нужно показывать серверную версию, выглядит очень костыльно. Насколько полный этот список? Как тестировать эту версию, чтобы убедится, что prerender все делает правильно?
vintage
15.09.2015 15:42Все современные поисковики поддерживают _escaped_fragment_, так что достаточно при наличии этого параметра заворачивать запрос на prerender.io

alive
14.09.2015 21:29Косвенно сравнивая метрики, мы получили выигрыш до 2 раз.
И всетаки можете поделится временем синтетических тестов? На сколько я понял, вы замеры проводили для TT и Fest/V8MonoContext.blackhearted
15.09.2015 17:09+3На синтетике TT проигрывает даже сильнее, но в реальности у v8 есть gc, который слегка снижает разрыв.
Шаблон на TT
[%- FOREACH i IN data; i; END -%]
Исходный шаблон на FEST
<fest:template xmlns:fest="http://fest.mail.ru" context_name="json"> <fest:get name="common"> <fest:param name="html"> <fest:for iterate="json.data" index="i" value="item"> <fest:value>item</fest:value> </fest:for> </fest:param> </fest:get> </fest:template>
Тестовый скрипт на перле. Берем массив из тысячи элементов и прогоняем его тысячу раз. Все это работает в виртуальной машине на средней по мощности девелоперской тачке.
use strict; use warnings; use JSON::XS; use V8::MonoContext; use Template; use Digest::MD5 qw/md5_hex/; use Time::HiRes qw/gettimeofday tv_interval/; my $result_tt = ''; my $result_fest = ''; my $data = {data => [0..999]}; my $fest_file = 'test.xml.js'; my $tt_file = 'test.tpl'; my $v8 = V8::MonoContext->new or die; my $tt = Template->new( ENCODING => 'UTF-8', COMPILE_DIR => '.', COMPILE_EXT => '.ttc', ) or die; my $t0 = [gettimeofday]; foreach (0..999) { my $out = ''; $tt->process($tt_file, $data, \$out); $result_tt .= $out; } printf "TT: %f, checksum: %s\n", tv_interval($t0), md5_hex $result_tt; $t0 = [gettimeofday]; foreach (0..999) { my $out = ''; $v8->ExecuteFile($fest_file, \$out, {json => encode_json($data), append => ';fest["test.xml"]( JSON.parse(__dataFetch()) );'}); $result_fest .= $out; } printf "FEST: %fsec, checksum: %s\n", tv_interval($t0), md5_hex $result_fest;
Результат
TT: 7.066557sec, checksum: 5df3b88b7b9769de8a30398cf847cb93 FEST: 0.357796sec, checksum: 5df3b88b7b9769de8a30398cf847cb93vintage
15.09.2015 18:55У верстальщиков, наверно, при виде такого шаблона слёзы радости на глаза наворачиваются :-)
blackhearted
15.09.2015 19:48Думаю, скоро сможете спросить у них сами, но уже в рамках другой статьи посвященной фронтенду :)
PerlPower
15.09.2015 09:24Зачем такой зоопарк технологий в рамках одной компании в рамках веб-разработки?
bekbulatov
15.09.2015 10:44+2В рамках одного проекта у нас зоопарка нет. Мы используем классический стек технологий, из необычного только V8, но на это есть свои причины, описанные в этой статье. В отделе три языка для бэкенда по историческим причинам: некоторые проекты переписали с perl на python, потому что перловиков труднее найти, другие проекты влились к нам из других отделов компании.
Вообще в компании много проектов и много команд, которые ими занимаются. Каждая команда выбирает те технологии, которые им больше подходят.
VolCh
23.09.2015 11:22На практике встречался с четырьмя причинами в достаточно небольших компаниях (не аутсорсных, а со своими проектами):
— использование новых, лучших чем старые по важному параметру, технологий для новых проектов (или подпроектов одного большого) без выделения ресурсов на переписывание существующего кода
— приобретения (по разным сценариям, от недружественного слияния компаний до покупок «коробок») готовых проектов, которые переписывать на «любимом» стеке не рационально, но поддерживать и развивать надо
— отсутствие единого корпоративного стандарта на стэк технологий или его наличие, но недоведение его до разработчиков или недостаточный контроль за его соблюдением
— для разных задач лучше подходят разные инструменты, попытки использования одного «универсального» стека часто приводят к различным проблемам, прежде всего к неэффективному использованию ресурсов, как времени разработчиков, так и аппаратных ресурсов
drfisher
Важный момент — новый подход позволил использовать часть js-шаблонов и на сервере, и в браузере (для отрисовки подгружаемого ajax-ом контента).