
Что такое масштабируемые векторные расширения (Scalable Vector Extension)? Что они значат для индустрии и пользователей?
Если вы пользуетесь мобильным телефоном, то скорее вы знаете, что такое процессор ARM. Он является сердцем вашего смартфона, а недавно появился в новом поколении Mac. Процессоры ARM также появляются в серверах.
Мы находимся на пороге серьезных изменений в индустрии, которых не происходило уже несколько десятилетий. x86 доминирует в компьютерной индустрии уже продолжительное время, но активное развитие ARM, вероятно, станет серьезной проблемой для x86.
В этом году ARM выпустила архитектуру следующего поколения, которая задаст курс отрасли на следующее десятилетие, — ARMv9. Это важное событие, которое заслуживает пристального внимания.
Есть много вещей, о которых стоит поговорить, но наиболее важной темой является стандартизация того, что мы называем масштабируемым векторным расширением (Scalable Vector Extension 2, SVE2). Вы наверняка слышали про наборы инструкций SIMD (Single Instruction Multiple Data, одиночный поток инструкций, множественный поток данных), такие как MMX, SSE, AVX, AVX-512 от Intel или Neon от ARM. Однако вы можете не знать, для чего они нужны. Я постараюсь объяснить, что отличает SVE/SVE2 от более старых наборов инструкций SIMD.
Знали ли вы, что Fujitsu сыграла важную роль во всем этом? Мы наблюдаем своего рода возвращение к супервычислениям старой школы, которые встречались в суперкомпьютерах Cray-1 несколько десятилетий назад. Фактически компания Cray не умерла и сейчас занимается созданием суперкомпьютеров на базе ARM: LRZ to Deploy HPE’s Cray CS500 System with Arm Fujitsu A64FX Processors.

ARMv9 — это процессор, который я могу купить в магазине?
Это не то же самое, когда Intel или AMD выпускают новый микропроцессор, который вы можете купить и установить в ПК для повышения производительности. ARMv9 не имеет физического воплощения. Это новая микропроцессорная архитектура, которая обратно совместима с предыдущими поколениями ARM, такими как ARMv8.
Позвольте мне объяснить, как это работает. Множество компаний по всему миру, таких как Qualcomm, Apple, Fujitsu Ampere Computing, Amazon, проектируют собственные микропроцессоры. Это многоступенчатый процесс. Например, ни Apple, ни AMD не производят собственные чипы. Вместо этого они разрабатывают дизайн микросхемы, а затем отправляют его на заводы, например, Global Foundries или TSMC. Там дизайн травят на кремниевых пластинах, которые затем разрезают на отдельные микрочипы и упаковывают.
Компания ARM Ltd. не похожа на Qualcomm или Ampere Computing. Они не производят готовые чертежи, которые можно передавать на завод. Вместо этого они продают чертежи интеллектуальных блоков. Компании вроде Apple могут купить эти блоки и объединить их в итоговый чертеж, который отправится на фабрики.

Но это все очень вариативно. Например, у вас есть чертежи реальных микропроцессорных ядер, таких как Neoverse N1. Другая компания может купить этот дизайн, открыть в инструментах для проектирования, скопировать четыре ядра, нарисовать несколько линий соединения, добавить кэш-памяти, и вот у них получился новый микропроцессор. В реальной жизни этот процесс, конечно, сложнее, но основную мысль, думаю, вы поняли.
ARMv9, как и предыдущий ARMv8, — не законченный чертеж, который регламентирует соединение транзисторов. Это то, как вы размещаете транзисторы для достижения высокопроизводительной архитектуры. Мы называем это микроархитектурой.

ARMv9 — больше похожа на договоренность между разработчиками компиляторов и архитекторами аппаратного обеспечения. Это своего рода соглашение о том, как в итоге должен выглядеть каждый конкретный процессор ARM. Какие инструкции нужно поддерживать и как они будут работать. Но в соглашении ничего не говорится о том, как это достигается с точки зрения транзисторов.
ARMv9 — это архитектура центрального процессора, что-то более абстрактное. Это похоже на соглашение между аппаратным и программным обеспечением. Архитектура обозначает, какие регистры должны быть на микропроцессоре и сколько бит они должны содержать, какие инструкции необходимо поддерживать и куда записывать результат после выполнения инструкции.
Пример инструкций для загрузки чисел из памяти по адресам 14 и 23 в регистры x1 и x2 соответственно, сложения содержимого регистров и записи результата в x3.
load x1, 14 ; x1 < memory[14]
load x2, 24 ; x2 < memory[24]
add x3, x1, x2 ; x3 < x1 + x2Чтобы узнать больше, читайте: How Does a Modern Microprocessor Work?
Архитектура процессора важна для разработчиков инструментов. Программное обеспечение, такое как компиляторы и линковщики, работает с заданной архитектурой. Это значит, что выпуск ARMv9 равнозначен выпуску нового стандарта для разработчиков программного и аппаратного обеспечения. Пока Apple, Ampere и Qualcomm производят оборудование, которое понимает инструкции, указанные в спецификации ARMv9, программное обеспечение, производящее код для этой спецификации, будет работать.
Естественно, ARM будет создавать микроархитектуры, которые фактически реализуют стандарт ARMv9. Однако это будет лишь начало серии микроархитектур, которые мы увидим, вероятно, в ближайшие десять лет. Будет много различного оборудования, но все оно сможет запускать код, созданный для спецификации ARMv9.
Что нового в ARMv9?
Чтобы показать, насколько большой вклад производит выпуск новой архитектуры, мы вспомним про ARMv8. ARMv8 была выпущена восемь лет назад и стала первой 64-битной архитектурой компании ARM Ltd. Микропроцессоры на базе ARMv7 были 32-битными. Это означало, что регистры внутри ЦП могли работать только с числами, которые содержали не более 32 двоичных цифр.
Появление ARMv8 было важным событием для Apple, так как это позволило им неожиданно рано для индустрии перейти на 64-битную архитектуру. Это дало iPhone и iPad фору. Несомненно, Apple хотела заниматься высокопроизводительными архитектурами как можно быстрее, поэтому они стремились создать процессоры ARM для настольных компьютеров.
Если упростить, то можно сказать, что ARMv8 — это архитектура для настольных компьютеров. ARM сделала шаг от телефонов в мир настольных компьютеров и серверов.
ARMv9 — это все про суперкомпьютеры. Вы можете подумать, что для вас как для пользователя телефона и настольного компьютера, это не имеет значения. Но вы ошибаетесь.
Я не рассказал, что такого особенного в векторах и что это такое. Они имеют большое значение для науки. Старые суперкомпьютеры, такие как Cray-1, были созданы для векторной обработки, то есть для обработки огромного количества векторов.
Когда я был подростком и читал о компьютерах Cray, я не понимал, что это значит. Раньше я фантазировал со своими друзьями о том, какую частоту кадров в секунду мы получим, играя в DOOM на Cray. Но, вероятно, мы бы не заметили разницы. Cray был хорош в научных вычисления, таких как прогнозирование погоды, всевозможные виды анализа и обработки данных. Все, что связано с огромными таблицами данных с большим количеством строк и столбцов, выигрывает от векторной обработки.
Именно это приходит в ARMv9 благодаря добавлению целого ряда новых инструкций, которые называются SVE2, или Scalable Vector Extension 2. Другими словами, процессоры ARM становятся все более похожими на старые суперкомпьютеры.
Для дополнительного чтения: ARM, x86 and RISC-V Microprocessors Compared.
Суперкомпьютер в кармане
Почему ARM сегодня выбирает архитектуру как у суперкомпьютеров? Что происходит?
Вы заметили, что такие вещи, как распознавание лиц и речи, автопилот и машинное обучение стали более распространенными? У вас есть умные помощники, такие как Siri, которые информируют вас о встречах и отвечают на вопросы. Сейчас это может показаться привычным, но вы задумывались, как раньше работали такие решения?
Всякий раз, когда вы что-то говорите своему цифровому помощнику, запись отправляется по сети в облако, где суперкомпьютер анализирует ваш голос, определяет, что вы сказали, и отправляет результат обратно на ваш телефон. Сегодня мы пытаемся распространить этот интеллект на большое количество устройств. Однако не все устройства могут иметь высокоскоростное подключение к интернету.
Кроме того, пользователи не хотят всегда быть подключенными к интернету, чтобы взаимодействовать со своими цифровыми помощниками, выполнять задачи распознавания речи и лиц. Мы хотим, чтобы эти задачи выполнялись на более дешевых и распространенных устройствах. Оказывается, эти задачи похожи на те, что решал Cray-1. Таким образом, все новое — это хорошо забытое старое.
Читать далее: RISC-V Vector Instructions vs ARM and x86 SIMD.
ARM и высокопроизводительные вычисления
Следующим шагом после настольных компьютеров и серверов, естественно, являются высокопроизводительные вычисления (High Performance Computing, HPC). Настоящие суперкомпьютеры. В далеком прошлом в этом сегменте доминировали специальные аппаратные решения, такие как ARM, а затем появились крупные центры обработки данных с серийным оборудованием x86 и мощными видеокартами.
Intel и AMD хорошо зарабатывают на этом рынке, поскольку машинное обучение и анализ данных стали гораздо более распространенными и важными. Естественно, ARM хочет получить кусок этого рынка. Первым серьезным шагом стал микропроцессор Fujitsu A64FX на базе ARM.
У Fujitsu есть опыт построения Cray-подобных компьютеров с векторной обработкой. Они объединились с ARM, чтобы расширить процессоры ARM набором инструкций Scalable Vector Extension. Таким образом, это не изобретение ARM, а адаптация уже существующего набора инструкций для высокопроизводительных вычислений к процессорам ARM.
Эта комбинация, используемая для A64FX, стала основной для создания самого мощного суперкомпьютера в мире: Japan’s Fugaku gains title as world’s fastest supercomputer.

Но следует помнить об одном важном факте: это было расширением и не является частью спецификации ARMv8. То есть ваши iPhone или iPad с процессором на ARMv8 не могут запускать код, созданный для суперкомпьютера Fugaku, потому что у них нет поддержки инструкций SVE.
Для сравнения, в ARMv9 такие инструкции стали частью стандарта. Именно поэтому я говорю, что ARM кладут суперкомпьютер в карман.
Но есть и более сложная история, которая требует более подробного рассмотрения. Как видите, ARM предлагает создавать процессоры, которые способны выполнять один и тот же код вне зависимости от их стоимости и мощности.
Они делают это таким образом, что прирост производительности обычного кода может превышать определенные ранее пределы. Подобные вещи невозможны с решениями, которые Intel и AMD использовали с инструкциями AVX для своих микропроцессоров x86.
Чтобы лучше понять почему, нам нужно рассмотреть различия и сходства между векторной обработкой и инструкциями SIMD. Но сначала рассмотрим, что такое вектор.
Вы можете смотреть на векторы по-разному. Например, как на набор цифр. Но на самом деле они указывают направление в пространстве, как стрелки. Координаты (x, y) точки указывают, где находится точка. Координаты (x, y) вектора указывают, как далеко растягивается вектор по осям. Причина, по которой векторы могут иметь больше чисел, заключается в том, что они не ограничены двухмерным или трехмерным пространством. Они могут существовать в воображаемом пространстве с сотнями, если не тысячами, измерений. В математике возможно все, что вы можете вообразить.
Что такое вектор?
Вектор — это просто причудливый математический термин для списка чисел. Например:
[3, 5, 9]Удобно работать со списками чисел, обращаясь к ним по имени или иному идентификатору. Например, два вектора с именами v1 и v2.
v1 < [3, 2, 1]
v2 < [1, 2, 2]И вот способ выразить, что я складываю векторы и сохраняю результат в v3.
v3 < v1 + v2 ; v3 должен быть [4, 4, 3]Почему я использую стрелки (<)? Это полезно при объяснении того, что происходит внутри компьютера, потому что обычно мы храним числа в некоторой области памяти. Эта память может быть пронумерована или названа. Внутри микропроцессора есть небольшая область памяти, которая разделена на фрагменты, называемые регистрами. В микропроцессорах ARM эти регистры имеют имена, такие как x0, x1, …, x31 или v0, v1, …, v31.
Чтобы иметь возможность выполнять операции сложения, вычитания или умножения, числа необходимо перенести из памяти в один из регистров. Вы не можете работать с числами, хранящимися в основной памяти. Процессор выполняет операции только над содержимым регистров.
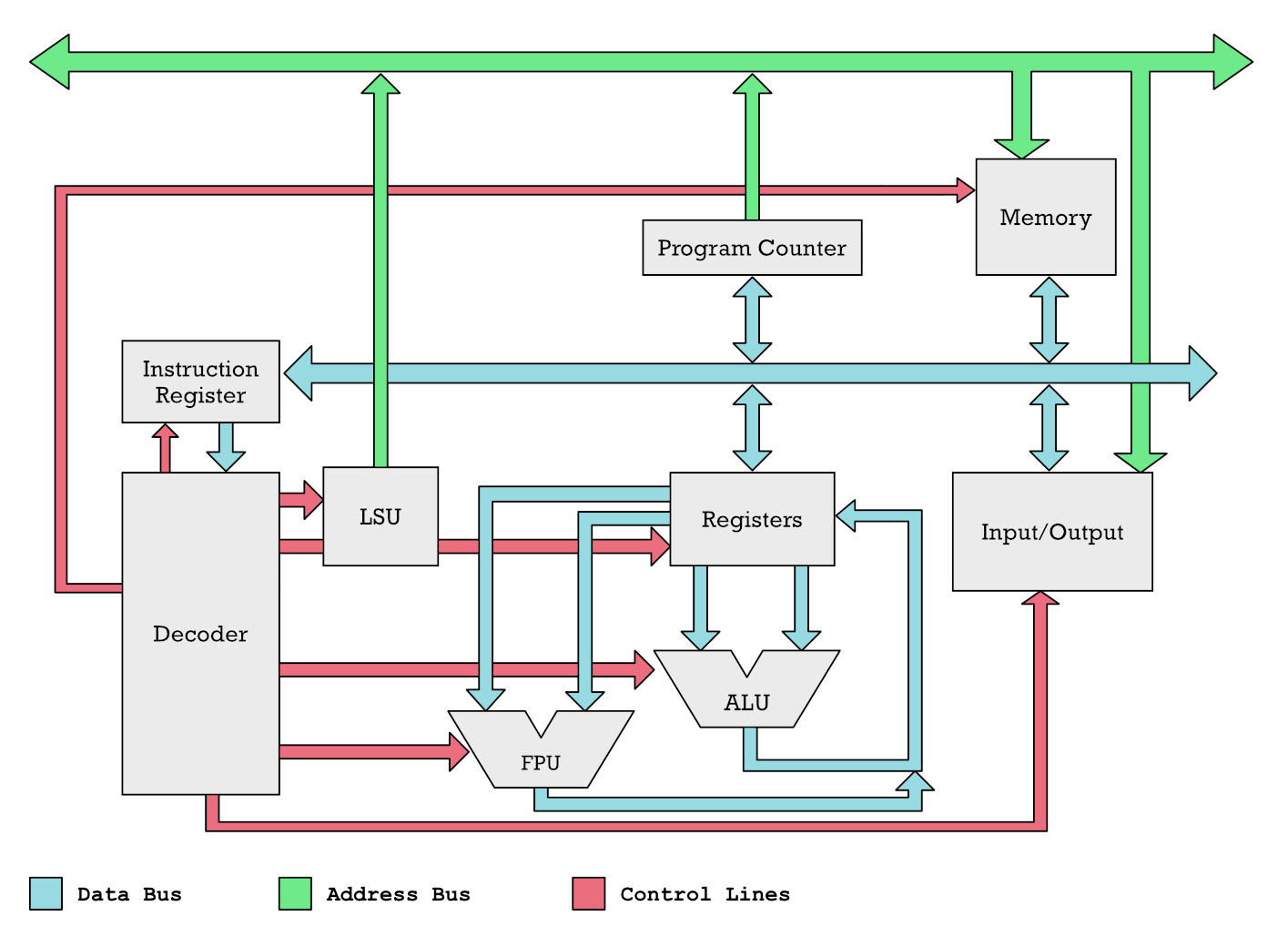
Упрощенная схема микропроцессора. Числа из памяти передаются по цветным линиям, которые называются шинами. Регистры подают числа на вход математическим сопроцессорам или другим блокам, которые выполняют вычислительные операции.
Противоположность векторам — скалярная величина. Это причудливое словосочетание для отдельных чисел. Итак, простой пример для скалярных операций с использованием стрелочной нотации.
x1 < 3 ; записать 3 в x1
x2 < 4 ; записать 4 в x2
x2 < x1 + x2 ; сложение x1 и x2 дает 7Векторы используются для многих вещей. Даже если вы не программист, вероятно, вы использовали приложение для работы с таблицами, например, Microsoft Excel. Столбец в таблице можно рассматривать как вектор. Обычно мы рассматриваем его как один логический элемент. Например, мы можем сложить все элементы в столбце или добавлять каждую ячейку столбца с каждой ячейкой на той же строке, но в другом столбце. Примерно это происходит внутри процессора, когда мы складываем два вектора. Вместе несколько столбцов образуют таблицы. Говоря математическим языком, несколько векторов образуют матрицы. То есть набор чисел, организованных в строки и столбцы.

Это хорошее подспорье в машинном обучении и почти в любой научной работе. Первый программируемый компьютер, Z1, фактически был создан для матричных вычислений.
Хотя современные компьютеры обычно не работают с матрицами, вычисления на матрицах можно ускорить с помощью векторов. Вот почему векторные инструкции важны для ускорения машинного обучения, распознавания изображений и речи. Математика векторов и матриц называется линейной алгеброй. У меня есть вступление для любопытных: The Core Idea of Linear Algebra.
Но не будем углубляться в математику. То, что нам нужно, связано с микропроцессорами. Инструкции в современном микропроцессоре, используемые для работы с векторами, называются SIMD.
SIMD против векторных инструкций
Технически ARM Neon и SVE являются формой SIMD (Single Instruction Multiple Data). Под этими инструкциями мы подразумеваем такие вещи, как сложение, вычитание и умножение. Таким образом, основная идея SIMD заключается в том, что вы отправляете одну инструкцию для процессора, а он выполняет одну и ту же операцию с несколькими значениями одновременно.

Подобные наборы инструкций существуют уже некоторое время. Вы, наверное, слышали про наборы инструкций MMX, SSE, а теперь и AVX на микропроцессорах x86 Intel и AMD. Они были созданы, чтобы выполнять обработку мультимедиа, такую как кодирование и декодирование видео. Инструкции ARM Neon наиболее похожи на них. Эти инструкции выглядят так:
LDR v0, [x4] ; v0 < memory[x4]
LDR v1, [x6] ; v1 < memory[x6]
ADD v4.16B, v0.16B, v1.16B
STR v4, [x8] ; v4 > memory[x8]В этом примере скалярные регистры x4, x6 и x8 содержат адреса в памяти, по которым располагаются числа в памяти.
Инструкция LDR загружает числа из памяти в регистр. Инструкция STR делает обратное: записывает числа из регистра в память.
Инструкция ADD выглядит странно. Почему там есть суффикс .16B после имени каждого регистра?
Дорожки в векторной обработке
Векторные регистры, такие как v0 и v1, имеют размер 128 бит. Что это значит? По сути, это максимальное количество двоичных разрядов, которые может содержать векторный регистр.
Это устанавливает верхний предел того, над сколькими числами мы можем выполнять операцию одновременно и сколько двоичных разрядов может иметь каждое из этих чисел. Например, если вы хотите складывать 64-битные числа, то вы сможете работать только с двумя, потому что в 128-битный регистр их помещается только два. Однако если числа будут меньше, то вы сможете уместить их больше. Например, при работе со значениями цвета мы обычно представляем компоненты красного, зеленого и синего как 8-битные значения. В 128-битный регистр их поместится 16.
128/8 = 16Это должно дать вам подсказку. 16B обозначает шестнадцать байтовых элементов. Попробуйте угадать, что означает эта инструкция сложения.
ADD v4.2D, v0.2D, v1.2DВ терминах микропроцессора мы называем 32-битное число машинным словом (word), а 64-битное число — двойным машинным словом (double-word). Таким образом, .2D означает два двойных слова, а .4S — четыре одинарных.
128/32 = 4Но почему эти суффиксы есть только у инструкции сложения? Почему нет у инструкций загрузки и сохранения? Потому что при работе с памятью нам не нужно рассматривать векторный регистр как состоящий из нескольких элементов.
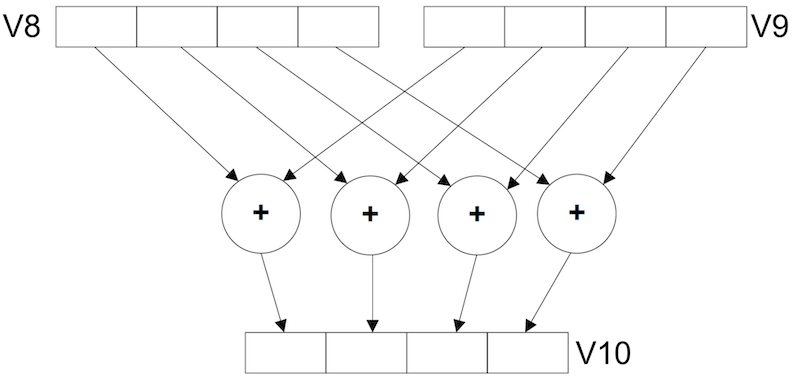
Количество элементов, на которые мы разбиваем регистр во время вычисления, определяет, сколько дорожек будет настроено для вычислений. Подумайте о дороге, где числа, словно машины, идут параллельно по нескольким полосам. Ниже приведен пример этого. У нас есть регистры v1 и v2, которые используют для вычислений, а результат сохраняется в регистр v3. Таким образом, мы разбиваем на два элемента (.2D), и у нас есть две дорожки для вычислений. Каждая дорожка получает одно арифметико-логическое устройство (АЛУ).

Если вам не нравятся мои иллюстрации, то вот иллюстрация ARM, которая демонстрирует задумку на четырех дорожках.
Проблемы с инструкциями SIMD
Инструкции SIMD, подобные тем, которые вы видите ниже, могут выполняться с разными аргументами.
ADD v4.2D, v0.2D, v1.2D
ADD v4.4S, v0.4S, v1.4SОднако они кодируются как отдельные инструкции. Это быстро выходит из-под контроля, что хорошо видно на примере x86. Intel начала с MMX, затем появились SSE, SSE2, AVX, AVX2 и наконец AVX-512. MMX, например, имел 64-битные векторные регистры, поэтому вы могли выполнять параллельную работу над двумя 32-битными регистрами или восемью 8-битными.
Со временем, когда транзисторов становилось все больше, было принято решение сделать новые векторные регистры большего размера. Например, SSE2 имеет 128-битные регистры. В конце концов этого оказалось недостаточно, и мы получили AVX, а AVX2 предоставил нам 256-битные регистры. Теперь, наконец, AVX-512 представил нам невероятные 512-битные регистры. Итак, теперь мы можем вычислять шестьдесят четыре 8-битных значения цвета параллельно.
Каждый раз, когда Intel делала доступными регистры большего размера, им приходилось добавлять множество новых инструкций. Почему? Потому что длина векторного регистра прописана в инструкции SIMD. Например, инструкция ADD потребуется для:
- Каждого регистра длиной 64, 128, 256 или 512 бит.
- Для каждого из регистров нужен отдельный вариант с нужным числом дорожек.
Таким образом, добавление инструкций SIMD привело к резкому увеличению числа инструкций, особенно для x86. И конечно же, не каждый процессор поддерживает эти инструкции. Только новые будут поддерживать AVX-512.
Почему ARM не следует стратегии AMD и Intel
Эта стратегия не работает для ARM. У Intel и AMD простая миссия. Они просто пытаются сделать самые мощные узкоспециализированные процессоры, которые они могут выпустить в любое время в магазин.
ARM, напротив, пытается удовлетворить широкий спектр потребностей. ARM работает как на крошечных встраиваемых устройствах, так и на суперкомпьютерах, таких как Fugaku. ARM может предложить дизайн процессора для сервера с использованием 512-битных векторов, но его поддержка на крошечном ARM, предназначенном для работы в бюджетном телефоне, будет невозможна. Конечно, ARM может сделать доступным множество различных наборов инструкций.
И действительно, ARM предлагает разные профили для разных сегментов рынка. Но ARM по-прежнему заинтересованы в том, чтобы одно программное обеспечение могло работать с широким спектром их процессоров.
SVE и SVE2 позволяют ARM задавать разную физическую длину векторных регистров для каждого типа микросхем. В SVE/SVE2 векторный регистр должен иметь длину от 128 до 2048 бит. Для смартфоном с низким энергопотреблением они могут продавать дизайны с 128-битными векторными регистрами, а для суперкомпьютеров — с 2048-битными.
Красота SVE в том, что один код будет работать как на суперкомпьютере, так и на дешевом телефоне. Это невозможно с инструкциями SIMD x86. Хотя я не являюсь экспертом по асемблерному коду ARM, судя по тому, как выглядит код при использовании Neon и SVE, мне кажется, что последний будет более эффективным даже при равной длине векторного регистра.
Причина заключается в том, что вы получаете более короткий ассемблерный код. Это означает, что меньше инструкций будет помещено в кэш. Меньше инструкций будет декодировано и выполнено. Позвольте мне объяснить, что я имею в виду. Когда микропроцессор получает инструкцию из памяти, например, сложение или умножение двух чисел, ему необходимо определить, что эта инструкция значит. Это называется декодированием и требует мощности. Чем меньше инструкций декодируется, тем дольше живет аккумулятор.
SVE в действии
Если мы посмотрим на инструкции Neon, то они кодируют количество дорожек так же, как указано в предыдущем примере.
ADD v4.2D, v0.2D, v1.2D
ADD v4.4S, v0.4S, v1.4SНо если мы переведем это в инструкции SVE, то мы увидим что-то подобное.
ADD v4.D, v0.D, v1.D
ADD v4.S, v0.S, v1.SЭто означает, что мы больше не указываем, сколько дорожек вычислений мы выполняем. Используя инструкции SVE при компиляции, мы не знаем, сколько дорожек будет использоваться, поскольку не знаем длину векторного регистра.
Предикация
Вместо этого в SVE используется то, что мы называем предикацией. Есть набор специальных регистров p0, p1, …, p15, которые работают как маски для вычислительных дорожек. Их можно использовать для включения или выключения дорожек. Таким образом, использовавшаяся ранее инструкция сложения выглядела бы так:
ADD v4.D, p0/M, v0.D, v1.DТеперь у нас есть дополнительный аргумент p0/M, который позволяет процессору сохранять результаты сложения v0 и v1 в v4 только когда соответствующий элемент p0 равен логической единице (истина). В псевдокоде это выглядит следующим образом.
while i < N
if p0[i] == 1
v4[i] = v0[i] + v1[i]
else
v4[i] = v0[i]
end
i += 1
endРегистр предикатов используется, например, для загрузки и сохранения данных. Пример для загрузки данных из памяти.
LD1D z1.D, p0/Z, [x1, x3, LSL #3]Здесь происходит несколько процессов, поэтому необходимо некоторое объяснение. [x1, x3, LSL #3] — это типичный для ARM способ указания адреса памяти. Это можно прочесть так:
base_address = x1 + x3*2^3
z1 < memory[base_address]Но поскольку мы используем предикат, то это не совсем правильно. Нам нужно отфильтровать то, что загружается. Более точно это выглядит так:
base = x1 + x3*2^3
while i < N
if p0[i] == 1
v1[i] = memory[base + i]
else
v1[i] = 0
end
i += 1
endЭта концепция с масками существует во многих языках высокого уровня — например, в Python, R и Julia. Пример на языке высокого уровня может помочь донести идею. Пример из командной строки Julia, но должно быть аналогично в Python и R.
julia> mask = [false, true, true, false];
julia> A = [2, 4, 8, 10];
julia> B = [1, 3, 7, 9];
julia> A[mask]
2-element Vector{Int64}:
4
8
julia> B[[true, false, false, true]]
2-element Vector{Int64}:
1
9
julia> A[mask] + B[mask]
2-element Vector{Int64}:
7
15В этом примере вы видите, что у нас есть векторы с четырьмя элементами. Мы используем маску, аналогичную регистрам предикатов, для выбора двух средних элементов.
Таким образом, мы можем выполнить сложение только двух средних значений.
Как работать с вектором неизвестной длины
Предикаты на самом деле являются обобщением условных операторов для векторной обработки. Естественно, вы не можете перепрыгивать через код для каждой дорожки. Для выполнения различных условий на различных дорожках мы используем предикаты.
Это помогает нам значительно упростить код векторной обработки и избежать необходимости знать точную длину вектора. Допустим, нам нужно обработать шесть 32-битных значений. То есть N = 6, и это единственное, что вы знаете во время компиляции. Инструкции Neon будут выглядеть так:
ADD v4.4S, v0.4S, v1.4S ; v4 < v0 + v1Вы сделали это один раз, но вам осталось обработать еще два элемента. Если вы повторите инструкцию, то обработаете восемь элементов, что больше, чем нужно. Таким образом, код векторной обработки будет делать столько, сколько может, а остатки мы должны будем вычислить с помощью простых скалярных операций.
С SVE этого делать не придется. Вместо этого нам приходит на помощь волшебная инструкция WHILELT. Вот пример:
WHILELT p3.s, x1, x4Но что она делает? Я объясню на примере псевдокода. Допустим, есть M дорожек для векторной обработки. Вы не знаете значение M до начала выполнения, но, допустим, что M = 4. Тем не менее, мы знаем количество элементов, которые хотим обработать, то есть N = x4 = 6. Инструкция WHILELT (WHILE Less Than, пока меньше чем) работает так:
i = 0
while i < M
if x1 < x4
p3[i] = 1
else
p3[i] = 0
end
i += 1
x1 += 1
endТаким образом, если мы представим выполнение этих векторных операций в цикле, то на первой итерации p3 будет выглядеть так:
x1 = 0
p3 = [1, 1, 1, 1]На второй итерации в какой-то момент x1 станет больше, чем x4, поэтому получаем следующее:
p3 = [1, 1, 0, 0]Таким образом, в коде не нужно явно указывать, на скольких дорожках мы работаем. Инструкция WHILELT гарантирует, что все дорожки включены, пока мы не дойдем до конца.
Так работает вся обработка SIMD. Вы обрабатываете партии чисел. Так, например, если вам нужно обработать 20 элементов, а ваш векторный регистр вмещает 4 дорожки, то вы можете сделать всю работу за 5 итераций (5?4 = 20). Но что если у вас 22 элемента?
Вы не можете выполнить полный пакет из четырех элементов. Таким образом, вам нужно доделать остатки вручную, по одному элементу за раз. С регистрами предикатов такой проблемы нет. Вы просто убираете из маски последние элементы. Это работает и с записью элементов в память.
Операции загрузки и сохранения
Другой важной особенностью SVE-инструкций является поддержка того, что мы называем операциями сборки-разборки (gather-scatter). Это означает, что вы можете заполнить векторный регистр данными, которые распределены по нескольким ячейкам памяти, всего за одну операцию. Точно так же вы можете записывать результаты из вектора в несколько местоположений. Принцип аналогичен тому, что мы обсуждали с предикатами.
Почему это полезно? В языках программирования более высокого уровня данные хранятся обычно следующим образом.
struct Sale {
int unit_price;
int sold_units;
int tax;
}
Sale sales[1000];Допустим, у нас тысячи таких объектов. Обычно мы хотим проводить расчеты между связанными полями. Например, умножить цену unit_price на количество проданных единиц sold_units. Это значит, что вы хотите, чтобы в одном векторном регистра были цены за единицу, а в другом — количество проданных единиц. Однако значения этих полей не лежат в памяти последовательно. Они чередуются.
Есть много таких деталей, которые позволяют применять SVE-инструкции к гораздо большее разнообразному коду. Можно векторизовать больше циклов for, что дает больше возможностей для повышения производительности.
Что предлагает SVE2?
Здесь, вы, естественно, задаетесь вопросом, а что добавляет SVE2, чего еще нет в SVE?
Расширение SVE было необязательным для архитектуры ARMv8. В то время SVE2 — это часть стандарта. Это означает, что Neon и SVE получили еще более тесную интеграцию. В SVE добавлены инструкции, которые делают SVE2 заменой Neon. Теперь вы можете делать все, в чем был хорош Neon с помощью SVE2.
Помните, SVE создавался только для суперкомпьютерных вещей, а для мультимедийных рабочих нагрузок, для которых создавался Neon? Мультимедийным материалам обычно не нужны длинные регистры. Рассмотрим цветной пиксель, закодированный как RGBA. Это четыре 8-битных значения, которые помещаются в 32-битный регистр.

Каждый пиксель состоит из четырех компонент: красный, зеленый, синий цвета и прозрачность. Каждый байт должен вычисляться независимо. Мы можем сделать это, используя 32-битный векторный регистр с 4 дорожками.
Однако с SVE2 эти задачи, которые больше подходят для коротких векторных регистров, также хорошо работают с векторными регистрами с переменной длиной.
Это дает ARM отличный набор инструкций, который может работать как с наиболее энергоэффективными, так и с наиболее производительными микросхемами. При этом пользователям необходимо выполнить компиляцию только один раз. Помимо этого, получается более простой код с точки зрения компилятора. А ARM не нужно участвовать в этой гонке вооружений с инструкциями SIMD, в которой участвуют Intel и AMD.
Им не нужно каждые несколько лет добавлять множество новых SIMD-инструкций. SVE2 дает фундамент с большой стабильностью и хорошим пространством для роста.
Последствия для пользователей, разработчиков и отрасли
Для разработчиков это значит, что написание и оптимизация кода ARM станет проще. Разработка программ для машинного обучения, распознавания лиц и голоса станет проще. Не придется беспокоиться, поддерживает ли целевая платформа нужные инструкции.
Для индустрии это значит, что компании смогут поставлять более разнообразный набор устройств, которые используют машинное обучение. Пользователи же будут меньше зависеть от доступа к сети, поскольку устройство сможет делать то, что раньше делало облако.
ARM также будет все больше вытеснять Intel и AMD из прибыльного бизнеса в центрах обработки данных. Я не являюсь экспертом по дизайну микросхем, но, видя, как RISC-V использует этот набор инструкций и понимает все преимущества, мне кажется, что Intel и AMD совершили ошибку, когда отказались от ARM. Их стратегия с SIMD не кажется мне разумной. Подозреваю, что эта ошибка будет их преследовать.








FDsagizi
Краткость сестра таланта