На сегодняшний день базы данных класса Massive Parallel Processing — это отраслевой стандарт для хранения Больших Данных и решения разнообразных аналитических задач на их основе.
Сценарии использования mpp-баз разнообразны: они могут быть и «рабочей лошадкой» корпоративного BI, и инструментом централизации данных из сотен источников в одном DWH, и даже использоваться для «горячего» взаимодействия с ML-моделями, работающими в продуктивном окружении.
Данный класс технологий — необходимый элемент в инструментарии современного Data Engineer.
На демо-занятии мы подробно разберем, что же такое mpp-БД, какие решения есть сегодня на рынке и даже углубимся в практический пример использования одной их самых инновационных mpp-систем на сегодня: ClickHouse.
Приглашаем всех желающих присоединиться к участию в демо-уроке «Введение в MPP-базы данных на примере ClickHouse».

Как IT-индустрия мы исключительно хорошо умеем создавать большие и сложные программные системы. Но сейчас мы начинаем наблюдать рост массивных и сложных систем, построенных вокруг данных, для которых основная ценность системы для бизнеса заключается в анализе этих данных, а не непосредственно в программном обеспечении. Мы видим стремительные изменения, спровоцированные этой тенденцией, во всей индустрии, что включает появление новых специальностей, сдвиги в пользовательской финансовой активности и появление новых стартапов, предоставляющих инфраструктуру и инструменты для работы с данными.
Многие из самых быстрорастущих инфраструктурных стартапов сегодня создают продукты для управления данными. Эти системы позволяют принимать решения на основе данных (аналитические системы) и управлять продуктами на основе данных, в том числе с помощью машинного обучения (оперативные системы). Они варьируются от конвейеров, по которым передаются данные, до решений для их хранения, SQL-движков, которые анализируют данные, дашбордов для мониторинга, которые упрощают понимание данных — от библиотек машинного обучения и data science до автоматизированных конвейеров данных, каталогов данных и т.д.
И все же, несмотря на весь этот импульс и энергию, мы обнаружили, что все еще существует огромная неразбериха в отношении того, какие технологии являются ведущими в этой тенденции и как они используются на практике. За последние два года мы поговорили с сотнями основателей, лидеров в сфере корпоративных данных и других экспертов, в том числе опросили более 20 практикующих специалистов по их текущим стекам данных, в попытке систематизировать новые передовые практики и сформировать общий словарь по инфраструктуре данных. В этой статье мы расскажем о результатах этой работы и продемонстрируем вам технологи, продвигающие индустрию вперед.
Инфраструктура данных включает…

Этот доклад содержит эталонные архитектуры инфраструктуры данных, составленные в результате обсуждений с десятками практиков. Огромное спасибо всем, кто участвовал в этом исследовании!
Стремительный рост рынка инфраструктуры данных
Одной из основных причин, из-за которых был составлен этот доклад, является стремительный рост инфраструктуры данных за последние несколько лет. По данным Gartner, расходы на инфраструктуру данных достигли в 2019 году рекордного показателя в 66 миллиардов долларов, что составляет 24% — и эта цифра растет — всех расходов на программное обеспечение для инфраструктуры. По данным Pitchbook, 30 крупнейших стартапов по созданию инфраструктуры данных за последние 5 лет привлекли более 8 миллиардов долларов венчурного капитала на общую сумму 35 миллиардов долларов.
Венчурный капитал, привлеченный наиболее показательными стартапами в области инфраструктуры данных в 2015-2020 гг.

Примечание: Любые инвестиции или портфельные компании, упомянутые или описанные в этой презентации, не являются репрезентативными для всего объема инвестиций во все инвестиционные каналы, управляемые a16z, и нет никаких гарантий, что эти инвестиции будут прибыльными или что другие инвестиции, сделанные в будущем, будут иметь аналогичные характеристики или результаты. Список инвестиций, сделанных фондами под управлением a16z, доступен здесь: https://a16z.com/investments/.
Гонка за данными также отражается на рынке труда. Аналитики данных, инженеры по обработке данных и инженеры по машинному обучению возглавили список самых быстрорастущих специальностей Linkedin в 2019 году. По данным NewVantage Partners 60% компаний из списка Fortune 1000 имеют директоров по обработке и анализу данных, по сравнению с 12% в 2012 году, и согласно исследованию роста и прибыльности McKinsey эти компании значительно опережают своих коллег.
Что наиболее важно, данные (и системы данных) напрямую влияют на бизнес-показатели — не только в технологических компаниях Кремниевой долины, но и в традиционных отраслях.

Унифицированная архитектура инфраструктуры данных
Из-за энергии, ресурсов и роста рынка инфраструктуры данных решения и передовые методы для инфраструктуры данных также развиваются невероятно быстро. Настолько, что трудно получить целостное представление о том, как все части сочетаются друг с другом. И это именно то, на что мы намеревались пролить здесь свет.
Мы опросили практиков из ведущих организаций, работающих с данными: (а) как выглядели их внутренние технологические стеки, и (б) что бы они изменили, если бы им нужно было создавать новый с нуля.
Результатом этих обсуждений стала следующая диаграмма эталонной архитектуры:
Unified Architecture for Data Infrastructure
Унифицированная архитектура для инфраструктуры данных

Примечание: Исключает транзакционные системы (OLTP), обработку логов и SaaS-приложения для аналитики. Перейдите сюда, чтобы просмотреть версию в высоком разрешении.
Столбцы диаграммы определены следующим образом:

Эта архитектура включает очень большое количество элементов — гораздо больше, чем вы можете найти в большинстве производственных систем. Это попытка сформировать целостную картину унифицированной архитектуры практически для всех вариантов использования. И хотя самые искушенные пользователи располагают чем-то похожим на это, большинство — нет.
Остальная часть этой статьи посвящена разбору этой архитектуры и того, как она чаще всего реализуется на практике.
Аналитика, AI/ML и грядущая конвергенция?
Инфраструктура данных на высоком уровне служит двум целям: помочь бизнес-лидерам принимать более обоснованные решения с помощью данных (аналитические варианты использования) и встроить аналитику данных в клиентские приложения, в том числе с помощью машинного обучения (оперативные варианты использования).
Вокруг этих вариантов использования выросли две параллельные экосистемы. Основу аналитической экосистемы составляют хранилища данных (data warehouse). Большинство хранилищ данных хранят данные в структурированном формате и предназначены для быстрого и простого получения выводов на основе обработки основных бизнес-метрик, обычно с помощью SQL (хотя Python становится все более популярным). Озеро данных (data lake) является основой оперативной экосистемы. Сохраняя данные в необработанном виде, он обеспечивает гибкость, масштабируемость и производительность, необходимые для специализированных приложений и более сложных задач обработки данных. Озера данных работают на широком спектре языков, включая Java/Scala, Python, R и SQL.
У каждой из этих технологий есть свои ярые приверженцы, а выбор одной из них оказывает значительное влияние на остальную часть стека (подробнее об этом позже). Но что действительно интересно, так это то, что у современных хранилищ и озер данных становится все больше общих черт — обе предлагают стандартные хранилища, собственное горизонтальное масштабирование, полуструктурированные типы данных, ACID-транзакции, интерактивные SQL запросы и т. д.
Важный вопрос на будущее: находятся ли хранилища и озера данных на пути к конвергенции? То есть станут ли они взаимозаменяемыми в стеке? Некоторые эксперты считают, что это все-таки происходит и способствует упрощению технологического и вендорного многообразия. Другие считают, что параллельность экосистем сохранится из-за различий в языках, сценариях использования или других факторов.
Архитектурные сдвиги
Инфраструктура данных подвержена широким архитектурным сдвигам, происходящим в индустрии программного обеспечения, включая переход к облаку, бизнес-моделям с открытым исходным кодом, SaaS и так далее. Однако помимо них существует ряд изменений, которые уникальны для инфраструктуры данных. Они продвигают архитектуру вперед и часто дестабилизируют рынки (например, ETL-инструменты) в процессе.

Новые возможности
Формируется набор новых возможностей обработки данных, которые нуждаются в новых наборах инструментов и базовых систем. Многие из этих трендов создают новые категории технологий (и рынки) с нуля.

Схемы построения современной инфраструктуры данных
Чтобы сделать архитектуру как можно более действенной, мы попросили экспертов систематизировать набор общих «схем» (blueprints) — руководств по внедрению для организаций, работающих с данными, в зависимости от размера, сложности, целевых вариантов использования и применения.
Здесь мы предоставим обзор трех обобщенных схем. Мы начнем со схемы современной бизнес-аналитики, которая фокусируется на облачных хранилищах данных и аналитических вариантах использования. Во второй схеме мы рассматриваем мультимодальную обработку данных, охватывая как аналитические, так и оперативные варианты использования, построенные на основе озера данных. В окончательной схеме мы подробно рассмотрим оперативные системы и новые компоненты AI и ML стека.
Три обобщенных схемы
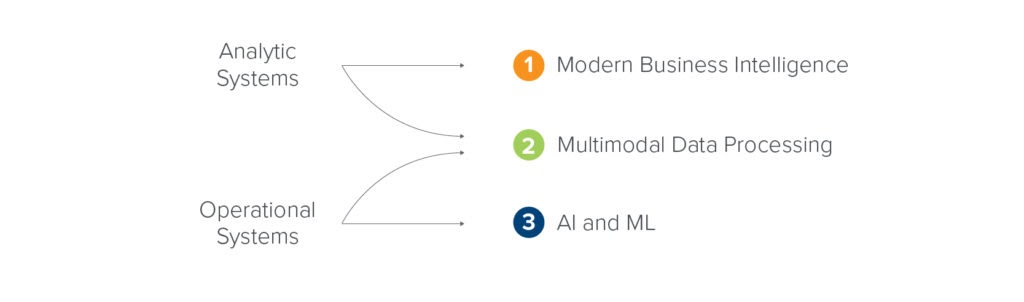
Схема 1: современная бизнес-аналитика
Облачно-ориентированная бизнес-аналитика для компаний любого размера - простая в использовании, недорогая для начала работы и более масштабируемая, чем предыдущие модели хранилищ данных.

Перейдите сюда, чтобы просмотреть версию в высоком разрешении.
Эта схема постепенно становится вариантом по умолчанию для компаний с относительно небольшими командами и бюджетами. Предприятия также все чаще переходят с устаревших хранилищ данных на эту схему, пользуясь преимуществами гибкости и масштабируемости облака.
Основные варианты использования включают отчеты, дашборды и специальный анализ, в основном с использованием SQL (и некоторого количества Python) для анализа структурированных данных.
К сильным сторонам этой модели относятся низкие первоначальные инвестиции, скорость и простота начала работы, а также широкая доступность кадров. Этот план менее приемлем для команд, у которых есть более сложные потребности в данных, включая обширную data science, машинное обучение или приложения для потоковой передачи / с низкой задержкой.
Схема 2: мультимодальная обработка данных
Новейшие озера данных, поддерживающие как аналитические, так и оперативные варианты использования, также известные как современная инфраструктура для Hadoop-беженцев

Перейдите сюда, чтобы просмотреть версию в высоком разрешении.
Эта модель наиболее часто встречается на крупных предприятиях и технологических компаний с сложными, высокотехнологичными потребностями в обработке данных.
Сценарии использования включают в себя как бизнес-аналитику, так и более продвинутые функции, включая оперативный AI/ML, аналитику, чувствительную к потоковой передаче / задержке, крупномасштабные преобразования данных и обработку различных типов данных (включая текст, изображения и видео) с использованием целого набора языков (Java/Scala, Python, SQL).
Сильные стороны этого шаблона включают гибкость для поддержки разнообразных приложений, инструментальных средств, определяемых пользователем функций и контекстов развертывания, а также преимущество в стоимости на больших наборах данных. Этот план менее приемлем для компаний, которые только хотят начать работу или имеют небольшие команды обработки данных - его поддержание требует значительных временных, денежных затрат и опыта.
Схема 3: Искусственный интеллект и машинное обучение.
Совершенно новый, еще развивающийся стек для поддержки надежной разработки, тестирования и эксплуатации моделей машинного обучения.

Перейдите сюда, чтобы просмотреть версию в высоком разрешении.
Большинство компаний, занимающихся машинным обучением, уже используют некоторую часть технологий из этого шаблона. Серьезные специалисты по машинному обучению часто реализуют полную схему, полагаясь на собственные разработки в качестве недостающих инструментов.
Основные варианты использования сосредоточены на возможностях работы с данными как для внутренних, так и для клиентских приложений - запускаемых либо онлайн (т. е. в ответ на ввод данных пользователем), либо в пакетном режиме.
Сильной стороной этого подхода, в отличие от готовых решений машинного обучения, является полный контроль над процессом разработки, создание большей ценности для пользователей и формирование ИИ / машинного обучения как основного долгосрочного ресурса. Этот план менее приемлем для компаний, которые только тестируют машинное обучение, используют его для менее масштабных, внутренних вариантов использования или тех, кто предпочитает полагаться на вендоров - масштабное машинное обучение сегодня является одной из самых сложных задач обработки данных.
Смотря в будущее
Инфраструктура данных претерпевает быстрые фундаментальные изменения на архитектурном уровне. Создание современного стека данных включает в себя разнообразный и постоянно растущий набор вариантов. И сделать правильный выбор сейчас важнее, чем когда-либо, поскольку мы продолжаем переходить от программного обеспечения, основанного исключительно на коде, к системам, которые объединяют код и данные для обеспечения ценности. Эффективные возможности обработки данных теперь являются главной ставкой для компаний во всех секторах, и выигрыш в данных может обеспечить твердое конкурентное преимущество.
Мы надеемся, что эта статья послужит ориентиром, который поможет организациям, работающим с данными, понять текущее состояние дел, реализовать архитектуру, которая наилучшим образом соответствует потребностям их бизнеса, и спланировать будущее в условиях непрекращающейся эволюции в этой сфере.
Перевод подготовлен в рамках онлайн-курса "Data Engineer".
Смотреть вебинар «Введение в MPP-базы данных на примере ClickHouse».
asm679
Отличная статья!
Nokia запускает блокчейн-рынок данных для безопасной торговли данными и моделей искусственного интеллекта
Nokia Data Marketplace