Выдавая подсказки и прогнозируя события, искусственный интеллект формирует рекомендательные системы для ротации товаров и услуг, адекватной запросам пользователей, ориентируясь на их предпочтения. По задумке, этот процесс должен происходить почти моментально: распределение товаров по категориям, автоматическое создание пула сопутствующих товаров на основе ассоциативного ряда и манипуляции big-датой. Но в реальности искусственный интеллект не успевает за меняющимися пользовательскими предпочтениями, а часто попросту ошибается, ранжируя товары, исходя из поступавших ранее запросов. В результате взрослому мужчине маркетплейсы предлагают наборы одежды для кукол, которые, когда-то пользуясь его картой, заказывала дочка-школьница, а детям вручают «в подарок» новые марки машинного масла и подписки на бизнес семинары.
Попадание в клиента
Часто системы генерируют либо ошибочные, либо не актуальные рекомендации причем в большом количестве, используя плохо сопротивляющийся накруткам и взломам алгоритм. Таким образом, интернет-магазины сталкиваются с проблемой слабой эффективности генерируемых рекомендаций.
Чтобы такого не происходило, создателям нейросетей необходимо решить проблему точного определения тенденций к изменениям и предпочтений у пользователей. То есть, рекомендательные движки должны учиться прогнозировать не только реакцию на предложение товара или услуги, но и предлагать похожие или альтернативные варианты (в зависимости от реакции пользователя).
В e-commerce, по-отдельности функционирующие коллаборативные, контентные и экспертные рекомендательные системы могут давать сбои, и надо создавать гибридную. Гибкий гибридный рекомендационный алгоритм будет комбинировать данные, полученные по нескольким каналам, протяженным по времени. В них можно одновременно применять взвешенные, дополненные, смешанные и рандомные приемы.
Алгоритм коллаборативной фильтрации выглядит таким образом. При наличии матрицы предпочтений и возможности определять похожесть при помощи косинусной меры, понадобится выбрать число пользователей со схожими вкусами. Вычислить косинусную меру для каждого пользователя, умножить его оценки на полученную величину меры и посчитать сумму калиброванных оценок для каждого товара. Формула алгоритма выглядит таким образом.

Функция sim – мера схожести двух пользователей.
U — множество пользователей.
r — выставленная оценка.
k — нормировочный коэффициент, который высчитывается по данной формуле:
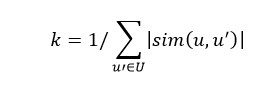
После решения уравнения надо будет кодифицировать информацию и перепроверить при помощи команды rec = makeRecommendation (‘имя пользователя, название товара (), вес, вес).
Важно, чтобы учитывалась главная цель пользователя, посетившего сайт для покупок, укомплектовав всю информацию в матрицу товарных предложений так, чтобы системе были видны и промежуточные действия покупателя. Для этой категории действий потребуется определить систему измерения – начиная от наведения мышкой на товар и заканчивая оплатой товара. Это важно, так как часть товаров «выпадает» из списка покупок, после вторичного прочитывания списка заказчиком. Еще одна категория товаров, которая нередко оказывается в категории промежуточных действий – самые дорогие или элитные товары. Многие пользователи их просто просматривают, что, в дальнейшем приводит к ошибкам в построении рекомендательных алгоритмов.
Определять низкую конверсию
Также важен отсев и низкоконверсионных товаров, препятствующих совершению покупок. Их объем в среднем составляет 5%, а иногда достигает 12%. Но в этом вопросе надо быть аккуратными, чтобы в число таких товаров не попали товары, которые действительно нужны покупателю. Например, помада определенной марки, но в маркетплейсе она представлена ограниченной палитрой цветов. Последний фактор снижает конверсию, и в случае, когда покупка помады этой марки не происходит, то ее смело можно отсеивать.
Чтобы не потерять часть клиентов на этапе выбора, важно построить адекватную запросам и психотипу человека систему модерации сообщений. Такой проект должен иметь микросервисную архитектуру, где каждый сервис выполняет свою задачу. Например, работу со складками, логистикой, хранением файлов и т д.
Задача микросервиса отдавать запорашиваемую информацию или выполнять определенные, поступающие из других сервисов, запросы. Например, нужно вывести в админке список мерчантов и их документы. Система запрашивает в микросервисе ответственном за мерчантов их список, из сервиса хранения файлов берет сами документы. При этом микросервисы общаются между собой при помощи json.
Учитывая то, что количество запросов с каждым днем нарастает, задача искусственного интеллекта снизить время их обработки, затраты на «живое» общение и конструирование диалога в режиме реального времени. Нейросеть и есть машинное обучение.
В результате внедрения, система может в автоматическом режиме рекомендовать наиболее часто заказываемые конкретной категорией покупателей товары. Помимо налаживания «диалога» с пользователем, интернет-магазин решает вопрос холодного старта, поддерживая ожидания клиентов в том числе и за счет рекомендации линейки низкочастотных товаров.
Почти все игроки рынка электронной коммерции, нарастив обороты за прошедший год, сегодня, сталкиваются с серьезной пробуксовкой бизнеса из-за того, что система не так хорошо, как хотелось бы, понимает пользователей. Вопрос создания универсальной модели искусственного интеллекта, который бы заменил маркетплейсам и маленьким магазинам продавца, товароведа и тонкого психолога – это вопрос одного-двух лет. И первый, кто сумеет учесть все вышеперечисленные ожидания бизнеса, станет лидером на рынке рекомендательных систем.