Этой весной Питерская Вышка и JetBrains впервые провели проектную смену для старшеклассников — Школу по практическому программированию и анализу данных. В течение пяти дней 50 участников со всей страны работали над групповыми проектами по машинному обучению, NLP, мобильной и web-разработке.
Первое место заняла команда Deep Q-Mario — ребята создали нейронную сеть, которая использует reinforcement learning для обучения агента играть в Super Mario Bros. В этом посте они рассказывают, какие алгоритмы использовали и с какими проблемами столкнулись (например, в какой-то момент Марио просто отказался прыгать).

О нас
Мы — Владислав и Дмитрий Артюховы, Артём Брежнев, Арсений Хлытчиев и Егор Юхневич — учимся в 10-11 классах в разных школах Краснодара. С программированием каждый из нас знаком довольно давно, мы писали олимпиады на С++. Однако почти все члены команды раньше не работали на Python, а для написания проекта в короткий пятидневный срок он был необходим. Поэтому первым испытанием для нас стало преодоление слабой типизации Python и незнакомого синтаксиса. Но обо всем по порядку.
Немного теории
На школе Питерской Вышки нам предстояло создать нейронную сеть, которая использует reinforcement learning для обучения агента играть в Super Mario Bros.
Reinforcement Learning
В основе RL алгоритмов лежит принцип взаимодействия агента и среды. Обучение происходит примерно так: агент совершает в среде действие и получает награду (в нашем случае Марио умеет прыгать и перемещаться вправо); среда переходит в следующее состояние; агент опять совершает действие и получает награду; подобное повторяется, пока агент не попадет в терминальное состояние (например, смерть в игре).
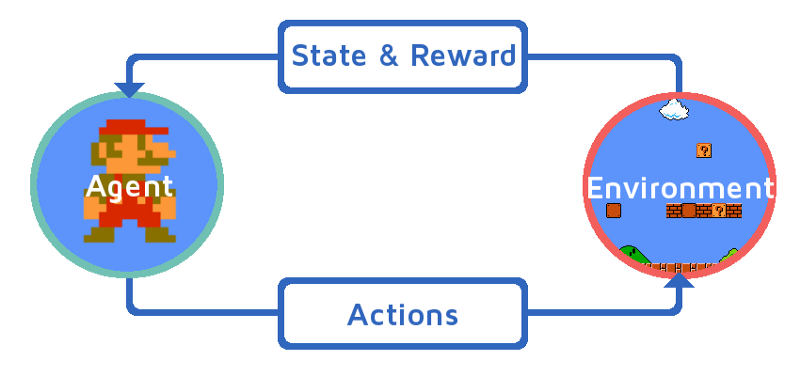
Основная цель агента заключается в максимизации суммы наград за весь эпизод — период от старта игры до терминального состояния. Особенностью обучения с подкреплением является отсутствие данных для тренировки, поэтому агент обучается на данных, которые получает, взаимодействуя со средой.
Q-learning
В основу нашей модели лег алгоритм Q-learning. Q-learning — это модель, которая обучает некоторую функцию полезности (Q-функцию). Эта функция на основании текущего состояния и конкретного действия агента вычисляет прогнозируемую награду за весь эпизод (Q-value).Агент совершает действия на основании некоторого свода правил — политики. Политика нашего агента называется Epsilon-Greedy: с некоторой вероятностью агент совершает случайное действие, иначе он совершает действие, которое соответствует максимальному значению Q-функции.
# implementation of Epsilon-Greedy Policy:
def act(state):
rand_float = random.random() # returns random float in range: [0, 1)
if rand_float <= EPS:
action = random_action()
else:
action = model.get_action(state) # returns action that brings max Q-value
return actionВ классической реализации алгоритма Q-learning формируется таблица из всех возможных состояний среды и всех возможных действий. Задача заключается в том, чтобы посчитать значения Q-values для каждой пары “состояние — действие”.
Обучение происходит так: мы добавляем к рассматриваемому значению Q-функции разность между оптимальным значением и текущим значением данной функции:
Где Q(s, a) — значение Q-функции для состояния и действия;
Qtarget(s, a) — это оптимальное, по нашему предположению, значение Q-функции, к которому мы пытаемся свести текущее значение Q-функции;
st, at — состояние среды и выбранное действие в момент времени $t$;
rt(st, at) — награда за текущее состояние среды и совершенное действие;
γ — коэффициент дисконтирования. Он необходим для того, чтобы уменьшать "значимость" награды в последующих моментах времени;
α — коэффициент обучения. Он определяет насколько сильно мы изменим текущее значение Q-функции.
Deep Q-Learning
Часто среда имеет слишком много состояний и действий, поэтому составить таблицу в явном виде невозможно. Для решения этой проблемы используют нейронные сети, чтобы не хранить значения полезности, а предсказывать их. На вход нейросети поступает текущее состояние среды, а на выход она дает прогнозируемую награду для всех действий.Для изменения Q-value мы обновляем параметры нейронной сети, чтобы предсказывать более точные значения. Обновление весов нейронной сети осуществляется градиентным спуском — это метод нахождения минимального значения функции (в этой статье можно почитать подробнее)

Experience Replay Buffer
Как мы уже говорили, особенностью алгоритмов обучения с подкреплением является отсутствие данных для тренировки модели, поэтому агенту необходимо накапливать игровой опыт и учиться на нем. Во время взаимодействия со средой агент накапливает переходы в некоторый буфер. Эти переходы включают в себя текущее состояние, произведенное действие, награду за действие, следующее состояние после действия, а также переменную, которая определяет, является ли текущее состояние терминальным:
# implementation of transition collecting:
transition = (state, action, next_state, reward, done)
replay_buffer.append(transition) Target network
Для того, чтобы весь алгоритм обучения работал, необходимо иметь вторую нейронную сеть target model, которая определяет оптимальное значение Q-функции (Q-target) и является копией модели, взаимодействующей со средой (online model). Единственное отличие этих сетей друг от друга заключается в том, что веса target model обновляются несколько реже, чем у online model — у нас это примерно каждый 500-й эпизод. Это нужно для корректного обучения модели: если online model будет производить вычисления Q-target и Q-функций самостоятельно, при изменении весов сети следующие значения Q-target и Q-функций изменятся примерно одинаково, то есть разница между ними останется такой же, и мы не будем сводиться к оптимальному значению.
Существуют два метода обновления весов target model: hard update и soft update. Первый копирует online model в target model каждую n-ую итерацию обучения. Во втором методе веса target model также пересчитываются при обучении, но медленнее, как взвешенное среднее весов двух сетей
Работа над проектом
Стоит отметить, что до школы никто из нашей команды не делал проекты по машинному обучению. За несколько недель нам сообщили тему проекта, и мы заранее, еще в Краснодаре, начали готовиться. Мы читали статьи, смотрели видео по машинному обучению и нейронным сетям, изучали математику, которая нам может пригодиться. Поэтому можно сказать, что на смену приехали уже подготовленными. Конечно, мы не знали нюансов, но во время школы наш куратор Дмитрий Иванов каждый день давал задания, благодаря которым мы смогли разобраться с деталями.Первые дни после начала школы мы занимались тем, что изучали необходимую теорию по нейронным сетям и обучению с подкреплением вместе с Дмитрием. После настало время кодинга: первая наша попытка реализовать DQN (Deep Q-learning Network) алгоритм и научить агента играть в Марио успехом не увенчалась. После девяти часов обучения прогресса не было, и мы не знали, в чем, собственно, дело. После тщетных попыток дебаггинга на питоне, командой было принято единственное разумное решение — переписать код с нуля, — что принесло свои плоды. Имея рабочую реализацию DQN, мы решили на этом не останавливаться, а написать модификацию Dueling DQN, сравнить ее со стандартным алгоритмом и посмотреть, какой агент лучше покажет себя в игре после обучения.
Dueling DQN
Основная идея Dueling DQN заключается в том, что нейронная сеть предсказывает не значения Q для всех действий, а отдельно средневзвешенное значение Q-функции по всем действиям (так называемое V-value), а также преимущества для каждого действия, которые определяются как разность между Q-функцией и средневзвешенным значением (подробнее можно почитать здесь).
")
Дополнительный функционал
Помимо алгоритмов обучения, нам необходимо было сделать еще несколько полезных вспомогательных фич: saver, logger, plotting, visualization.
Saver
Для того, чтобы в случае необходимого приостановления расчетов для изменения гиперпараметров нейронки иметь возможность продолжить обучение на сохраненной версии сети, мы реализовали функционал периодического сохранения весов обучаемой нейронки. Данная возможность была особенно полезна, когда мы столкнулись с проблемой в обучении DQN агента (подробнее о ней расскажем ниже).
Logger and Plotting
Также было реализовано логирование: на каждом n-том эпизоде мы сохраняли вычисляемые метрики — функцию средней потери (это функция, которую минимизирует нейронная сеть) и функцию средней награды за эпизод — в отдельном файле, чтобы иметь возможность строить их графики, не прерывая вычислительный процесс.
Visualization
Благодаря функции сохранения весов модели во время обучения, мы имели возможность восстанавливать версии нейронной сети. Это позволило нам строить визуализацию взаимодействия агента со средой — наш игровой процесс — на разных стадиях обучения.
Возникшие проблемы
На самом деле проблем во время работы над проектом была масса. Бороться с ними команде помогал куратор. Однако одна проблема заставила нас поломать головы над ее решением — на определенном этапе вычислений Марио стал упираться в трубы, не пытаясь их перепрыгнуть.

Мы считаем, что эта особенность поведения связана с тем, что отрицательная награда от исхода времени на прохождение эпизода была меньше, чем отрицательная награда от смерти Марио при ударе с врагом. Другими словами, Марио "считал", что завершить уровень из-за истечения времени для него более предпочтительно, чем смерть.Эта проблема действительно поставила нас в тупик: мы не знали, как заставить агента проходить уровень. Мы бились над решением в течение многих часов, пока Арсений Хлытчиев не придумал модификацию функции награды, названную Punishment-оптимизацией (за что мы всей командой выражаем Арсению благодарность!) Он предложил добавлять отрицательную награду за "простой" Марио, чтобы восстановить значимость передвижения агента вперед по уровню. Это улучшение оказало сильное влияние на поведение агента в среде: Марио больше не застревал перед трубами.

Результаты
К окончанию школы мы получили агента, который неплохо справлялся с частичным прохождением первого уровня игры: Марио сумел пройти около 50%. При этом каждый член команды сумел одолеть Марио, дойдя до второго уровня.

Оба алгоритма DQN и Dueling DQN после обучения проходили примерно равную часть уровня. Но в силу того, что обычный DQN имел больше времени для обучения, его результат был немного лучше.Так как нашей целью было сравнить обычный алгоритм DQN с его модификацией, давайте проанализируем графики, которые мы получили.
Функция потери
 и Dueling DQN (справа)")
На первый взгляд может показаться, что Dueling модификация показывает себя хуже, однако большое значение функции потери объясняется тем, что агент, обучающийся на Dueling DQN, в среднем проходил дальше по уровню, чем агент с обычной моделью обучения. В связи с этим среда для агента становилась неизвестной, и он чаще ошибался.
Функция награды
 и Dueling DQN (справа)")
Функция средней награды постепенно возрастает, это свидетельствует о том, что агенты узнают о среде больше, то есть проходят дальше по уровню. Из графиков видно, что агент с моделью обучения Dueling DQN в среднем получает такую же награду, что агент с DQN, однако модифицированной версии понадобилось практически в два раза меньше итераций, чтобы научиться получать такое среднее количество награды.
Заключение
Наш проект еще можно и нужно дорабатывать. Например, можно продолжить обучать агента, пока он не завершит уровень, подумать над другими оптимизациями алгоритма DQN и т.д. Но сейчас мы заняты другим: кто-то сдает ЕГЭ, кто-то готовится к летним школам по программированию, поэтому добавлять какие-либо изменения пока не планируем.
За время школы мы получили много опыта в командной разработке и базовые знания о машинном обучении, на основе которых можем создавать свои собственные ML-проекты. А еще мы познакомились с большим количеством интересных людей, которые также хотят развиваться в сфере IT. Поэтому хотим выразить безмерную благодарность организаторам смены, нашему куратору и всем, кто принимал участие в школе. Это был незабываемый и очень полезный опыт.
Другие материалы из нашего блога о проектах студентов младших курсов:
Красиво? Очень! Как мы написали приложение для визуализации аттракторов
4 угла хорошо, а 6 лучше: гексагональные шахматы в консоли и с ботом