Как-как, с помощью магии нейронок, конечно. А если серьёзно, то в этой статье расскажем, как эволюционировали технологии шумоподавления и улучшения речи, какие есть варианты, чтобы собрать своё решение, и какой сетап получился у нас.

Задачу рассмотрим достаточно общую: отличить человеческую речь от фонового шума и вырезать все посторонние звуки. Её решение полезно для любой дальнейшей обработки. И системы распознавания, и детектирование акустических событий, и другие приложения, взаимодействующие с человеческой речью, обычно лучше работают с сигналом без лишнего шума. Нам же такая технология поможет повысить качество видеозвонков ВКонтакте, в Одноклассниках и Почте Mail.ru: чтобы фоновые шумы не мешали участникам конференций общаться.
Постановка задачи
С точки зрения продукта задача выглядит так: в звонке мы хотим хорошо слышать людей, а шум от техники, животных, улицы — не слышать.
В плане разработки нам нужно обработать грязный аудиосигнал так, чтобы отфильтровать фоновые шумы и выделить речь целевого спикера.
При этом к технологии мы предъявляем следующие требования:
работа в реальном времени (не увеличить задержки более чем на 20 мс);
легковесность, чтобы запускаться на пользовательских устройствах;
качество, сопоставимое с другими решениями (Zoom и Krisp), а лучше — превосходящее конкурентов.

Прежде чем рассмотреть доступные подходы и углубиться в нейронки, пробежимся по базовым понятиям.
Звук — это волна. Микрофон реагирует на её распространение, и получается аналоговый сигнал, то есть непрерывный. Чтобы передавать и обрабатывать аналоговый сигнал, его преобразуют в цифровой. Есть разные аппаратные и программные способы, но самый распространённый — импульсно-кодовая модуляция, или PCM. Частота, например 44 100 Гц, определяет качество оцифрованного звука, а величина амплитуды обычно кодируется в 16 бит.
Все методы фильтрации шумов имеют дело с цифровым сигналом: набором значений уровня сигнала, записанных через равные промежутки времени.
Как делали раньше
Один из самых старых методов улучшения речи (Speech Enhancement) — Spectral Subtraction. Его идея очень простая: из зашумлённого спектра вычитаем спектр шума, получаем спектр только чистой речи, преобразуем обратно из спектра в сигнал.
Грязный сигнал может быть представлен как где
— чистая речь,
— шум.
Алгоритм Spectral Subtraction математически описывается так:
где— спектр чистой речи,
— предполагаемый спектр шума,
— спектр входного сигнала.
Позже появился более продвинутый метод, который называется винеровский фильтр. Его идея заключается в минимизации расстояния междуи
Формулируется это как
где— вычисленный спектр,
— спектр шума.
Ниже общая схема улучшения речи с помощью винеровского фильтра.

Однако винеровское оценивание, как и почти все строгие математические результаты, основывается на допущениях, которые далеко не всегда выполняются на практике. Поэтому плохо справляется с фильтрацией сильных шумов — и даёт гораздо меньше возможностей для подгонки алгоритма под внешние условия, чем пришедшие ему на смену алгоритмы машинного обучения.
Нейронные сети для фильтрации шума
Сложные математические преобразования заменила магия нейронных сетей.
RNNoise
Одной из первых известных и успешных сетей, решающих задачу улучшения речи, стала RNNoise. RNNoise сочетает классические алгоритмы и RNN-сеть (рекуррентную нейронную сеть). Основная идея заключается в использовании нейросети для эмуляции трёх основных компонентов системы: VAD (Voice Activity Detection), вычисления спектра шума и вычитания спектра шума из исходного сигнала.

Сеть на вход принимает спектр шумного сигнала, а на выход отдаёт два тензора. Один предсказывает, является ли данный фрейм речевым. А на второй надо умножить фрейм, чтобы получить чистую речь.
Естественно, за один проход обрабатывается не весь образец сигнала, а небольшое окно — в оригинальной RNNoise это 20 мс. В каждой последующей итерации окно сдвигается на 10 мс, получается перекрытие и повторный анализ части окна.
Архитектура самой нейросети RNNoise выглядит примерно так.

NSNet
Более современный подход предложили специалисты из Microsoft. В NSNet из фрейма извлекается магнитуда после преобразования STFT (Short-Time Fourier Transform) и LPS (Log-Power Spectra).

Признаки считаются на окне 32 мс, перекрытие составляет 24 мс. Другими словами, сеть отдаёт очищенную речь фреймами по 8 мс.
На вход при обучении подаётся спектрограмма чистого сигнала, аугментированного шумами (см. data augmentation). Для обучения NSNet использует среднеквадратичное расстояние между спектрограммой оригинального чистого сигнала и спектрограммой, полученной в результате работы сети.
DCCRN
Следующей ступенью на пути улучшения речи стала DCCRN. DCCRN имеет U-net-подобную архитектуру, где все операции представлены комплексными операциями. Основная идея метода состоит в использовании не только магнитуды сигнала, но и фазы. За счёт этого нейросеть качественнее очищает речь, чем предыдущее решение NSNet.
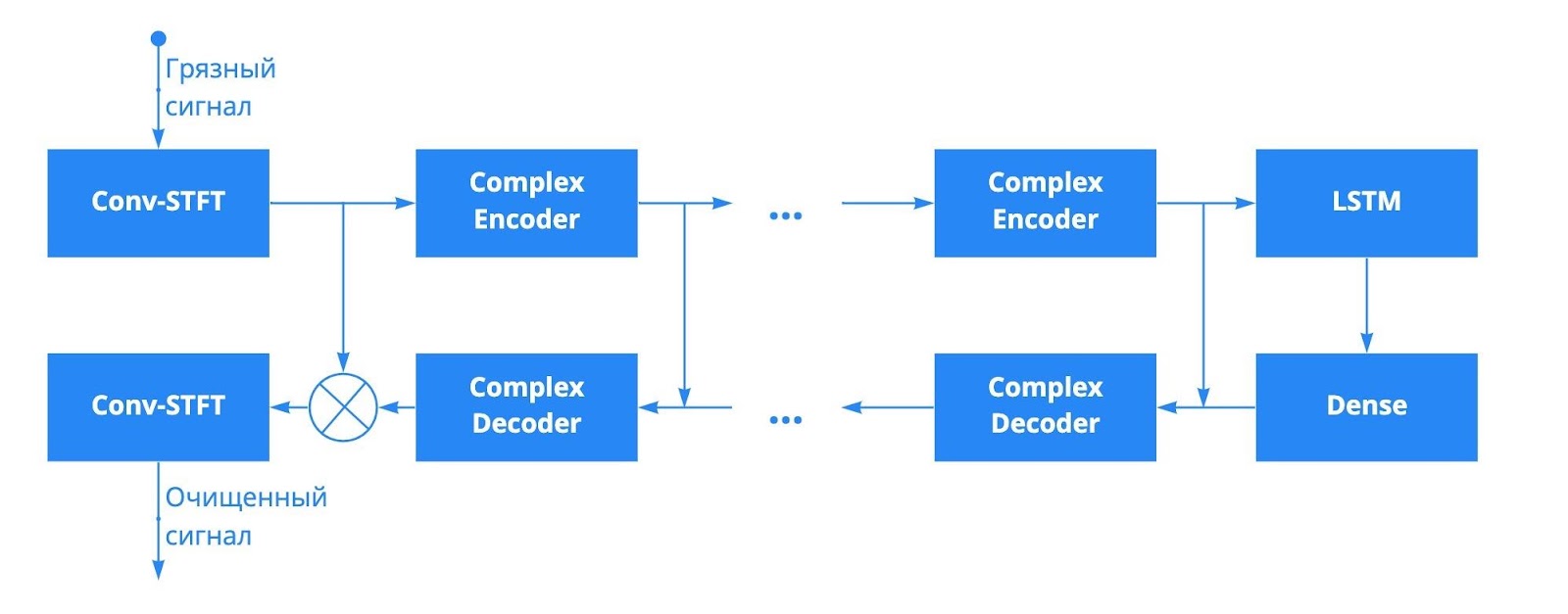
Но высокое качество DCCRN стоит дорого. Во-первых, исходная сеть не может работать в реалтайме. Эту проблему авторы решили, вставив рекуррентный слой между энкодером и декодером. Во-вторых, модель сложна в реализации и не приспособлена для работы с окнами произвольных размеров. Третий минус — размер модели и скорость её работы. По заявлению авторов, для обработки 32 мс на Intel i5-8250U требуется порядка 3 мс. То есть для этой сети с окном перекрытия в 8 мс Real Time Factor (RT) (метрика, которая показывает, во сколько раз быстрее сигнал обрабатывается, чем поступает) будет меньше 3. С таким показателем на более слабой технике уже можно выпасть из реального времени.
PoCoNet
PoCoNet — state-of-the-art решение в области Speech Enhancement от Amazon, которое превосходит по качеству все предыдущие подходы.
Архитектура PoCoNet похожа на DCCRN — она также U-net-подобная. Но вместо комплексных блоков авторы представляют Dense Attention Block: в сеть включены self-attention слои для улавливания глобального контекста.
Главное же отличие PoCoNet от предыдущих работ заключается во введении frequency positional embedding. Этот механизм похож на работу Positional Encoding из Transformer Architecture: входная спектрограмма конкатенируется с позиционными эмбеддингами, которые вычисляются как
Однако у PoCoNet есть существенные минусы:
долго обучается — обучение такой модели занимает 4 дня на восьми Tesla V100;
медленно работает — обработка 1 секунды занимает 0,65 секунды на Tesla V100.
DTLN
Проанализировав актуальные работы в области улучшения речи, мы остановились на DTLN. Если её правильно приготовить, то она даёт качество, соизмеримое с DCCRN и PoCoNet, и при этом имеет маленький размер и хороший показатель реалтайма.

Идея сети DTLN (Dual-Signal Transformation LSTM Network) заключается в двух проходах. Сначала, как и в предыдущих работах, делаем оконное преобразование Фурье (STFT), передаём магнитуду в нейросеть, получаем вектор, на который умножаем магнитуду. Потом делаем обратное преобразование Фурье (IFFT) и полученный сигнал отправляем на вход во вторую часть сети, на выходе которой получаем полностью очищенный сигнал.
Важные для нас преимущества DTLN в том, что модель занимает меньше 4 Мбайт, а для обработки 32 мс на Intel i5 6600k требуется 0,65 мс. Это в 5 раз быстрее, чем для DCCRN, не говоря уже о PoCoNet. Показатели качества подробнее рассмотрим ниже, но в целом DTLN отстаёт от лучших моделей примерно на 10%. С учётом выполнения остальных требований это нас вполне устраивает.
К сожалению, исходная модель не работает с реверберированным сигналом (отражëнным от стен, отчего возникает эффект порхающего эхо). После процессинга появляется субъективно неприятный шелест. Поэтому мы решили доработать модель и исправить эти проблемы.
Что в итоге используем
Сейчас мы используем DTLN-подобную архитектуру, которая чуть толще оригинальной, но работает быстрее. Благодаря реализации на C++, скорость работы составляет ~0,2 мс на 10 мс речи. Сеть работает с окном 30 мс и перекрытием 20 мс. В выборе размера окна мы отошли от классического сочетания 32 мс и перекрытия 24 мс для более бесшовной интеграции с WebRTC и Opus.
Данные для обучения
Как известно, результат работы нейросетей сильно зависит от данных, которые используются для обучения. К счастью, в свободном доступе есть несколько хороших больших датасетов с размеченными шумами и с чистой человеческой речью: MUSAN, AudioSet, WHARM!, LibriVox, RIR.
Записи человеческой речи, сделанные в идеальных условиях, будем использовать как эталон для обучения. А с помощью шумов подготовим образцы, на которых будем тренировать нейросеть. Для этого, как показано на схеме ниже, комбинируем речь и шум в некоторых пропорциях.

Полученный грязный сигнал отдаём нейросети для улучшения, результат сравниваем с эталонной исходной записью речи, постепенно обучая сеть.
Причём мы не разделяем шумы по видам, а просто используем весь их объём (сейчас у нас в обучении около 900 часов чистой речи и 10 000 часов шумов). Так как нейросеть обучается на большом количестве самых разных данных, в итоге она может фильтровать и стационарный, и нестационарный шум. Хотя фильтрация нестационарного пока остаётся более сложной задачей.
Обучение нашей модификации DTLN-подобной сети на таком объёме данных занимает около двух дней на Tesla T4.
Функция потерь и оценка качества
В большинстве статей в качестве функции потерь используется MSE:
Для обучения мы выбрали SNR (Signal to noise ratio), так как по нашим экспериментам с этой loss-функцией удаётся добиться более высокого качества.
Что значит «высокое качество» и как его оценивать, в данном случае не самый простой вопрос. Простое сравнение по отклонению от эталона не покажет, улучшится ли на самом деле пользовательский опыт.
Поэтому метрики качества в задаче улучшения речи довольно сложные и пытаются оценить, насколько разборчивой получилась речь в очищенном образце. Для сравнения моделей обычно применяют PESQ-метрику (Perceptual Evaluation of Speech Quality). Она была специально разработана для моделирования субъективной оценки восприятия человеческой речи, применяемой в телекоммуникации. В некотором приближении PESQ-метрика должна соответствовать средней экспертной оценке по шкале от 1 (плохо) до 5 (отлично). Но так как абсолютные значения очень зависят от исходных условий теста, мы используем метрику только для того, чтобы определять прогресс продакшен-решения.
В таблице ниже кроме собственно PESQ-метрики, свойств нейросети (работа с реверберацией и размеры окна и шага) указаны две характеристики, которые могут сильно повлиять на выбор архитектуры: Real Time Factor и память.
PESQ |
Работает с ревербе- |
Размер окна |
Размер шага |
RT Factor |
ROM |
|
Исходный сигнал |
1,71 |
— |
— |
— |
— |
— |
RNNoise |
1,93 |
Нет |
20 мс |
10 мс |
— |
0,35 Мбайт |
NSNet |
2,05 |
Нет |
32 мс |
8 мс |
— |
11 Мбайт |
DTLN (baseline) |
2,41 |
Нет |
32 мс |
8 мс |
27,7 |
3,9 Мбайт |
DTLN (VK) |
2,54 |
Да |
30 мс |
10 мс |
45,6 |
5,3 Мбайт |
Real Time Factor, по сути, показывает скорость работы. Чем он больше — тем, значит, быстрее мы обрабатываем поступающий сигнал. RT Factor нашей модификации DTLN-сети в 45,6 означает, что 1 секунда будет обработана быстрее, чем за 25 мс. А сети в исходном виде понадобится больше 80 мс на процессинг той же секунды. ROM напрямую влияет на итоговый размер приложения и имеет большое значение — когда, как у нас, шумоподавление выступает только одной из функций.
Однако метрика — это всё равно только метрика, не всё может учесть. Например, в сигнале, обработанном оригинальной DTLN, появляется неприятный для человеческого уха свист, а значение метрики при этом отличное. Поэтому на слух результаты тоже проверяем: например, тестируем настройки на рабочих совещаниях и проводим перепись воображаемых (неслышных) домашних животных.
Что не сработало
Дорабатывая DTLN-модель, пробовали разные идеи, которые иногда помогают в задачах с обучением нейросетей. Некоторые не принесли пользы.
Экспериментировали с функциями потерь, пробовали MSE и loss-функцию на основе quality-net. Но они не привели к повышению качества работы модели. Выбранная функция SNR показалась нам самой удачной.
Также пробовали увеличить количество слоёв в нейросети, но это тоже не помогает повысить качество.
Генерация данных для обучения без добавления новых шумов или чистой речи не даёт профита. Если из тех же исходных шумов и записей речи сгенерировать дополнительную тысячу часов грязного сигнала, обучение займёт больше времени, но качества в улучшении речи не прибавится.
Выводы и лайфхаки
Сейчас наша модель для улучшения речи работает на бэкенд-сервере звонков, на iOS и Android и будет встроена в нативное приложение под Windows, macOS и Linux. На iOS и macOS модель запускается с помощью Core ML, на остальных платформах используем TensorFlow Lite.
Результат работы получившегося шумодава предлагаем читателям оценить самостоятельно. Клиентское шумоподавление уже работает в iOS- и Android-приложении ВКонтакте, а скоро будет доступно и для десктопа в нативном клиенте звонков.
Базовый рецепт, который вы можете повторить у себя: DTLN-сеть, данные для обучения из открытых источников, Signal to noise ratio в качестве функции потерь плюс не забывать проверять шумодав на слух — и голос будет гораздо лучше слышно в записи или интернет-звонке.
И перечислим лайфхаки, которые помогли нам добиться большего.
Если научить нейросеть работать с реверберированными сигналом, то улучшенная речь будет звучать приятнее, хотя по метрикам это может быть незаметно.
Вместо традиционного размера окна в 32 мс подойдёт окно в 30 мс с перекрытием в 20 мс. Разницы в работе сети нет, а интеграция с WebRTC и аудиокодеком удобнее.
Кастомный модуль улучшения речи можно комбинировать со встроенным в WebRTC — лучше почистятся микрошумы.
Возможности WebRTC вообще лучше использовать по максимуму. Например, WebRTC Voice Activity Detection со слабыми настройками перед шумодавом позволяет в несколько раз снизить нагрузку: пока никто не разговаривает, в окне приходят нули и можно просто прокрутить буфер. В серверном варианте в такой конфигурации у нас получилось 3% загрузки ядра CPU вместо 11%.
Всё это входит в состав нового аудиопайплайна звонков ВКонтакте, который рассчитан на неограниченное число одновременных участников, — о нём подробно в отдельной статье. В ближайшее время больше всего нас будет интересовать стабильная работа моделей в продакшене и обратная связь (с этим вы можете помочь в комментариях — профессиональный опыт очень ценен). А дальше, возможно, продолжим эксперименты и попробуем, например, сделать персонализированный шумодав, использующий для обучения вектор спикера и лучше выделяющий из шума голос конкретного человека.
Благодарности: Ивану Григорьеву и Виталию Шутову.
Комментарии (16)


stalinets
19.08.2021 15:45-1А если я захочу дать человеку послушать шум пылесоса? А если у меня, например, дефект речи и я сильшо шамкаю, меня и так трудно понять, а тут ещё начало и конец фразы небось будет резаться как шум?

alatobol Автор
19.08.2021 16:47+1Специально для этого случая в настройках есть отключение шумодава.
При этом проблему с дефектом речи решает VAD, который определяет речь, чтобы начало и конец не проглатывались.

site6893
19.08.2021 18:06а вдруг повезет и нейронка будет убирать дефект речи, при єтом смысловая нагрузка не пострадает)

iShrimp
19.08.2021 20:41А когда-то люди специально во время разговора включали фоновые шумы типа дрели, поезда, плачущего ребёнка и т.д. (фантазия не ограничена).
P.s. Да и сейчас ещё живо приложение AlibiSound...

Interreto
19.08.2021 19:29Вы тестируете насколько сильно дрейнится батарея если перенести это на клиентскую сторону в моб. клиентах?
alatobol Автор
19.08.2021 21:20да, мы проводили а/б тесты и контролируем огромное кол-во параметров клиента, рост потребления в пределах погрешности, что объяснимо, так как во время звонка основными факторами потребления являются кодирование/декодирование и сетевой стек
nickeodash
19.08.2021 21:21Запиши свой голос с включенным пылесосом и посмотри на диапазон чистот в аудио-редакторе, и заодно попробуй руками отсеки пылесос :)
nickeodash
20.08.2021 01:25Пока мой коммент был на премодерации, автор исходного (Interreto) успел изменить комментарий, но я восстановлю: в общем ввиду разных диапазонов частот у пылесоса и человеческого голоса предложил просто отсечь пылесос из аудиодорожки и не париться)
Interreto
20.08.2021 05:40Я не изменил, а хотел дополнить, а получаеться что потёр, потому что на Хабре, да и не только Хабре, писать длинные коменты с мобилки неюзабельно.

Gorodecki
21.08.2021 17:33При распознавании голосовых сообщений в текст не используете денойзер?
alatobol Автор
21.08.2021 17:36Для обучения в распознавании голосовых сразу использовались шумные, а не эталонные записи. То есть там адаптация к шуму заложена на уровне языковой модели, и поэтому не требуется дополнительная задержка на денойзинг. Скоро выпустим подробную статью про это. Но и предварительный денойзинг в распознавании голосовых тоже планируем тестировать.
dmzubr
Спасибо за статью!
В сторону DEMUCS (https://arxiv.org/pdf/2006.12847.pdf) не смотрели? Или смотрели, и не устроил ожидаемый RTF?
Krinjev
Смотрели, DEMUCS решили не использовать ввиду большого размера чекпоинта у первых версий статьи и очень маленького RTF, на слабых девайсах даже после всех возможных оптимизация влезть было бы очень тяжело .
Рассматривали похожую работу DCRNN, с нашей точки зрения она более продвинутая в контексте топологии, там такая же U-net-подобная архитектура, но блоки оперируют в комплексном поле и encoder/ecoder не содержат рекуррентные слои, т.е. проще наращивать глубину модели.