В этой статье речь пойдёт об архитектуре данных, где необходимо хранить статусы записей, получая информацию об их актуальности.
Суть задачи.
На основе информации из базы платежей выявить категории получателей платежей и вывести сводную информацию по категориям в отчёт для руководства.
Каждый платёж проходит в два этапа: средства переводятся внутри организации на внешний счёт и второй транзакцией происходит выплата средств получателям платежа. Между этими двумя сущностями нет прямой зависимости внутри БД, есть только поля описания платежа и поля описания получателя, которые заполняются сотрудниками бухгалтерии вручную, они зачастую могут иметь отличия. Например, первый платёж описан так:
"Оплата адм.штрафа в области благоустройства, предусмотренные главой 4 закона Санкт-Петербурга от 31.05.2010 №273-70 "Об адм.правонарушениях в Санкт-Петербурге" постановления №3456/17 от 21.19.75."
При этом, во втором этапе в описании платежа находится похожая информация:
"Оплата административных штрафов № 1234/17,2345/17,3456/17,4567/17 вст в зак. силу 21.19.75г., согласно распоряжениям от 55.04.2047г."
Отличия налицо. Данные соответствующих номеров и дат изменены.
В текущем варианте алгоритм соединения таких сущностей построен на условиях, а определение категории получателя использует ML модель, обученную на совпадениях, найденных вручную, за предыдущие периоды, а во всякой модели необходимо поддерживать актуальность и повышать её эффективность.
В свою очередь, основная сложность получения полных и качественных данных из источника состоит в том, что из-за фильтров в загрузке Staging-хранилища, в него могут не попасть нужные данные, а эти фильтры нужны для уменьшения загружаемого объёма. Грубо говоря, для отчёта нужны платежи, касающиеся только штрафов. Соответственно, на этом этапе также необходимы регулярные доработки на основе найденных ошибок или пропущенных данных.
Архитектура проекта
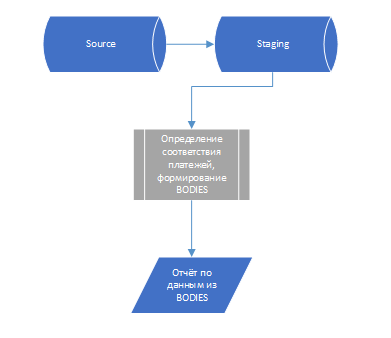
Итак, имеются две таблицы с сырыми данными (Staging) и одна витрина (Data Mart, DM). Staging. Таблицы загружаются из источника на регулярной основе по расписанию с применением фильтров. Фильтров много (более 350). В этом же ETL-процессе (процесс загрузки данных) происходит удаление старых загруженных данных. Затем по другому расписанию с помощью алгоритмов в скриптах обновляются данные DM. Далее отчёт в BI-системе выводит информацию из DM, используя простые запросы. Backup настроен на уровне БД. Про настройку Foreign Keys речи не идёт, поскольку связей DM и Staging либо нет вовсе, либо они могут быть всех типов. Например, некоторые штрафы могут быть взяты из другого нерегламентированного источника с другой структурой данных, либо один штраф имеет множество транзакций под собой.
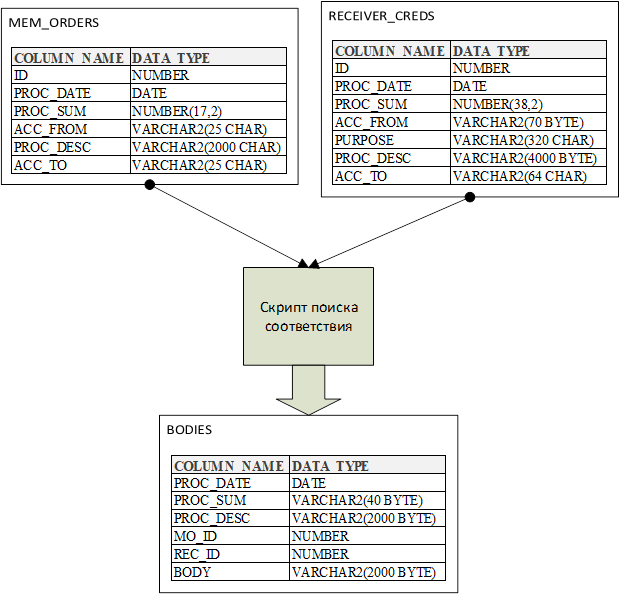
Так выглядит процесс обработки данных для отчёта (схематично):
Основная проблема
Основная проблема: не загружаются нужные данные платежей из источника, причины могут быть следующие:
Сбой ETL-процесса. Явление крайне редкое, но раз в сто лет и ружьё на стене стреляет;
Разработанные фильтры на счета и типы операций, ограничивающие объём платежей нужного типа, отрезают как раз нужные платежи. Эти фильтры постоянно нуждаются в доработке. Например, для отчёта не нужны платежи со словом ПОШЛИНА в описании, но начли появляться штрафы ГИБДД, где присутствует слово ПОШЛИНА в разных вариациях, и условия SQL-фильтров усложняются;
В информации платежей могут записать неправильный счёт, и тогда правильные фильтры не пропустят нужный платёж.
При частом изменении сложных фильтров может возникнуть ситуация, когда добавлены нужные платежи, но одновременно пропали другие.
Все проблемные кейсы, выявленные вручную, записываю в лог и раз в квартал провожу ТО фильтров и других компонентов проекта, включая ML модель на решающих деревьях.
Решение проблемы
Решение - создать таблицу актуальности данных. Это таблица-связка, которая наполняется уникальными идентификаторами платежей, рассчитанным категориями платежей и статусами, подходит ли платёж для отчёта. Фильтры и условия используются при заполнении этой таблицы, но затем через неё можно вручную исправить актуальность данных, меня значение поля FLAG, картинка ниже. В эту таблицу занесены все ранее удостоверенные платежи с рассчитанными категориями, а все проблемные случаи исправлены в ручном режиме. Эта информация и послужила также для обучения модели, которая определяет категорию платежа по тексту его описания. На удивление, простая модель на решающих деревьях с градиентным бустингом показала отличный результат по F-мере, и, действительно, её не нужно часто переобучать, поскольку тексты описаний платежей чаще всего типовые и содержат одни и те же фразы, по которым происходит разделение на категории.
Структура таблицы:
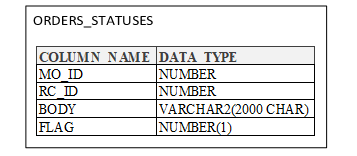
Здесь поля MO_ID и RC_ID содержат ссылки на платежи из начальных таблиц, а ORGAN можно как вычислить с помощью ML-модели, так и задать вручную. Затем при сборе таблицы BODIES в первую очередь берётся орган, рассчитанный в таблице актуальности. В таблице статусов нет дат платежей, поскольку часто нужно найти ошибки в формировании ID платежей на источнике данных, иногда они, к сожалению, повторяются. Все workarounds связаны с неопределённостью в регулярности и структуре данных на БД-источнике. Здесь скрипт на Oracle PL/SQL в части работы с обновлением статусов записей:
procedure p_proc_BODIES(p_start_date date) as
begin
--DELETE NON-TAXES
delete
from TAXFORM.BODIES e
where e.mo_id in
(select s.mo_id from TAXFORM.ORDERS_STATUSES s
where s.FLAG = 0);
--TWINS DELETE
delete
from TAXFORM.BODIES tt
where tt.PROC_DATE >= p_start_date
and tt.rowid in
(select rid from
(select rowid rid
, row_number()
over (partition by PROC_DATE, PROC_SUM, PROC_DESC, MO_ID, REC_ID, BODY
order by null) as rn
from TAXFORM.BODIES t
where t.PROC_DATE >= p_start_date
)
where rn > 1
)
;
--ADD NEW ROWS TO ORDERS_STATUSES
insert into TAXFORM.ORDERS_STATUSES(MO_ID,RC_ID,BODY,FLAG)
SELECT distinct mo_id, rec_id, body, 1
FROM TAXFORM.BODIES o
where o.mo_id not in (select s.mo_id from TAXFORM.ORDERS_STATUSES s
);
--ADD APPROVED ROWS TO BODIES
insert into TAXFORM.BODIES(PROC_DATE,PROC_SUM,PROC_DESC,MO_ID,REC_ID,BODY)
select distinct e.PROC_DATE, e.PROC_SUM, e.PROC_DESC, e.mo_id, s.rc_id, coalesce(s.BODY, TAXFORM.FORM_PKG.f_get_BODY(e.PROC_DESC))
from TAXFORM.ORDERS_STATUSES s
join TAXFORM.MEM_ORDERS e
on e.mo_id = s.mo_id
where s.mo_id not in
(select o.mo_id from TAXFORM.BODIES o)
and s.FLAG = 1;
--UPDATE BODIES
update TAXFORM.BODIES o set o.BODY = (select min(BODY) from TAXFORM.ORDERS_STATUSES s where s.mo_id = o.mo_id and s.tb = o.tb and s.FLAG = 1)
where o.PROC_DATE >= p_start_date
and exists (select 1 from TAXFORM.ORDERS_STATUSES s
where s.mo_id = o.mo_id
and s.FLAG = 1
and o.BODY != s.BODY)
;
commit;
end;Функция f_get_BODY возвращает рассчитанный орган штрафа по описанию платежа. Ранее это был разветвлённый скрипт на Oracle PL/SQL, а сейчас это делает ML-модель. Речь в этой статье не о модели, поэтому её скрипт оставляю за рамками повествования. С такой таблицей меняются все этапы вычисления данных, кроме первого этапа загрузки. На каждом этапе при обращении к старым данным добавлены проверки актуальности платежей по статусам. Также в конце ETL-процесса добавлены операции актуализации данных в таблице актуальности.
Вывод
По итогу: вместо удаления платежей с подозрением на неактуальность, можно их отключать изменением флага в таблице актуальности, а на основе полного сета данных актуальных и неактуальных платежей появляется возможность строить модель определения категории платежей. Теперь изначальные фильтры можно расширить или убрать совсем для загрузки более полных данных в зависимости от наличия свободного места на сервере. Такая архитектура пригодится в похожих задачах, где есть неопределённость в исходных данных и в последующей их обработке.