Идея
Однажды я играл в игру "Слово", основная суть которой заключается в составлении слов из прилегающих друг к другу букв, которые даны на игровом поле 5 на 5. И ко мне пришла идея о создании программы, которая могла бы автоматически решать поставленную задачу. В итоге был реализован shortcut на iPhone1, который совместно с дополнительными программами помогает находить слова.
Дисклеймер
Данная статья была написана с целью ознакомления читателя с реализацией алгоритмов и технологий, примененных в данном проекте. Я настоятельно рекомендую не применять подобного рода программы в данной или похожих играх и думать своей головой :)

shortcut
1 shortcut на iPhone - способ решения той или иной проблемы в виде последовательности действий на основе визуальных сценариев в операционной системе iOS.
Оглавление
1. Нахождение слов
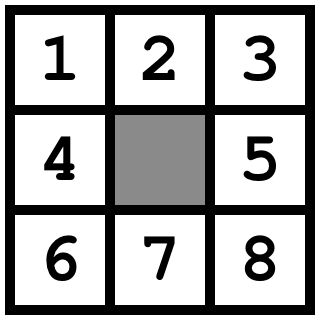
Первым делом необходимо было разработать программу, которая могла бы находить максимальное количество слов на игровом поле. Описанная выше игра - это одна из версий настольной игры Боггл, но со своей системой бонусов.

Идея концепции игры Боггл была разработана еще в 1972 году Алланом Туроффом, поэтому не удивительно, что программы, решающую данную задачу, уже давно реализованы и для того, чтобы найти такую, нужно просто написать в поисковом запросе "Boggle Solver". Но так как данная игра больше распространена среди англоговорящих, то пришлось рассмотреть различные реализации решений и на их основе написать версию для русских слов.
Для решения поставленной задачи нам понадобится 4 класса:
WordsSolver- основной класс для нахождения слов на игровом поле размераBoard- класс, который представляет игровое поле с буквамиWord- класс, который представляет формируемое словоDictionary- класс, представляющий словарь слов
Введем следующие условные обозначения.

Посмотрим на все методы и поля в классах.

Поля:
dictionary- объект классаDictionaryдля проверки наличия слова или подслов2 в словареboard- объект классаBoardдля получения буквы по номеру строки и столбцаmin_length- минимальная длина слов, которые необходимо найтиfound_words- множество всех найденных слов
Методы:
find_words- находит все слова, длина которых не менееmin_length, на игровом поле_find_words- находит все слова, длина которых не менееmin_length, с позицииrow,column_can_add_word- проверяет, можем ли мы добавить текущее слово в итоговое множество_get_valid_coordinates- выдает значение координат следующей позиции на поле
Как вы можете заметить, есть 3 "защищенных" метода, которые начинаются с "_". Они используется как вспомогательные функции для find_words и не подразумевают использование вне рамок данной функции.
Определение подслова
2 Подслово - непрерывная непустая последовательность букв слова, начиная с первой буквы. Например, для слова "добро" подсловами являются: "д", "до", "доб", "добр", "добро"

Поля:
letter_sequence- последовательность букв (формируемое слово)used_board_coordinates- множество всех используемых координат игрового поля для данного формируемого слова
Методы:
add_letter- добавляет букву к формируемому словуnew- формирует новое пустое словоnew_from_word- формирует новое слово на основе переданного
Метод new вызывается каждый раз при переходе на новую позицию игрового поля. Метод new_from_word вызывается, если формируемое слово вместе со следующей буквой могут образовать слово, содержащиеся в словаре.

Поля:
side_length- длина стороны игрового поляboard- игровое поле (квадратная матрица из букв)
При инициализации класса мы передаем список всех букв игрового поля слева направо сверху вниз. Далее производится проверка того, можем ли мы составить из данных букв квадратную матрицу.

Поля:
words- множество всех слов из словаряsubwords- множество всех подслов, которые можно получить из слов путем взятия первыхбукв, где
.
Методы:
contains_word- проверяет наличие слова во множестве словwordscontains_subword- проверяет наличие подслова во множестве подсловsubwords
Метод contains_word используется в методе _can_add_word, когда мы проверяем, можем ли мы добавить текущее формируемое слово в итоговое множество found_words. Метод contains_subword необходим каждый раз, когда мы проверяем, может ли текущее формируемое слово вместе со следующей буквой образовать слово. Например, пусть формируемое слово "ябло", тогда если на следующей рассматриваемой позиции игрового поля находится буква "а", то мы не станем формировать новое слово из текущего и переходить на данную позицию.
Реализация данных классов представлена в репозитории GitHub, ссылка на который дана в конце статьи. Далее показан визуальный пример работы программы по нахождению слов.

На гифке, приведенной выше, я показал визуализацию работы алгоритма до нахождения первого слова, которое есть в словаре. На самом деле, после буквы "р" должна идти буква "а", но для краткости я сразу перешел к букве "о", что в итоге дало формируемое слово, которое есть в словаре.
Также стоит сказать о том, как формировался словарь. Согласно правилам игры в словаре используются следующие части речи:
Существительные
Глаголы в форме инфинитива
Прилагательные в начальной форме (м. р. , ед. ч.)
Причастия в начальной форме (м. р., ед. ч.)
Наречия
Исходя из этого, необходимо было найти слова, являющиеся одной из приведенных выше частью речи. Для нахождения таких слов я использовал открытые словари слов, найденные в интернете. Там, где слова были разделены на страницы, где каждая страница была отведена под одну букву, пришлось реализовывать парсер сайтов. Таким образом, был собран словарь в формате .txt, состоящий из слов. К сожалению, не все слова подходят, но "отчистка" словаря от таких слов весьма времязатратное действие.
Резюмируя вышесказанное, еще раз опишем кратко работу алгоритма. Начинается все загрузки слов из словаря, далее игровое поле заполняется буквами, после чего начинается поиск с первой позиции и проверка на вхождение формируемого слова в соответствующие множества слов и подслов. После того, как все слова, начинающиеся с буквы, которая была на первой позиции, найдены, алгоритм переходит к следующей позиции
и поиск начинается заново. И так до тех пор, не будут перебраны всевозможные позиции на игровом поле, после чего алгоритм завершает работу, а множество
found_words содержит все найденные слова. Слова в дальнейшем нужно отсортировать в порядке убывания их длины, ведь за более длинные слова начисляются больше игровых очков.
2. Предобработка фото
С нахождением слов разобрались, но для работы алгоритма необходимо передать последовательность букв, расположенных на игровом поле, объекту класса WordsSolver. Данную задачу с легкостью решит человек, но для автоматизации этого процесса нужно распознать все буквы на игровом поле.
Для предобработки изображения воспользуемся одной из главных библиотек компьютерного зрения и обработки изображений - OpenCV. Распознавание буквы - это всего одна строка кода, но для того чтобы она работала корректно и почти во всех случаях, необходима качественная предобработка, поэтому далее рассмотрим поэтапно все шаги предобработки скриншота.
Исходное изображение (скриншот игры) хранится в формате .png. Для загрузки изображения из указанного файла воспользуемся функцией imread().
import cv2
image = cv2.imread('../images/screenshot_example_1.png')Получаем следующее изображение:
")
Изображение на рис. 9 выглядит не так, как должно быть. Дело в том, что когда файл изображения считывается с помощью функции imread(), порядок цветов - BGR (синий, зеленый, красный). Порядок цветов можно изменить, используя функцию cvtColor(). Но так как далее мы будем работать с черно-белым изображением, то в качестве второго аргумента для cvtColor() будет сv2.COLOR_BGR2GRAY, что позволит перевести исходное цветовое пространство изображение в черно-белое.
# преобразование изображения в черно-белое
image = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
Нам необходима только та часть изображения, где располагаются буквы, т.е. нужно вырезать игровое поле. Так как возвращаемый тип значения функции imread() это numpy.ndarray, то мы можем взять нарезку от матрицы (исходного изображения).
# значение по координате y, начиная с которого нужно рассматривать изображение
y = 600
# значение по координате x, начиная с которого нужно рассматривать изображение
x = 30
# высота рассматриваемого участка изображения
h = 800
# ширина рассматриваемого участка изображения
w = 800
# вырезаем необходимую часть изображения
image = image[y:y+h, x:x+w]
Далее необходимо применить пороговую функцию, которая бинаризирует изображение таким образом, чтобы буквы были черными, а все остальное белым. Для этого применим функцию threshold() :
Первым аргументом является исходное изображение
, которое должно быть изображением в оттенках серого.
Вторым аргументом является пороговое значение
, которое используется для классификации значений пикселей, в нашем случае данный аргумент игнорируется, так как добавлен флаг
THRESH_OTSU, который отвечает за выбор оптимального порогового значения на основе алгоритма Otsu3.Третьим аргументом является максимальное значение
которое присваивается значениям пикселей, превышающим пороговое значение, в нашем случае это
255(белый цвет).Четвертым аргументом являются дополнительные флаги. Помимо флага
THRESH_OTSUбыл добавлен флагTHRESH_BINARY_INV, который по сути инвертирует изображение (на самом деле он меняет пороговую функцию на)
Алгоритм Otsu
3 Алгоритм Otsu пытается найти пороговое значение , которое минимизирует взвешенную внутриклассовую дисперсию. Также данный алгоритм обладает важным свойством, заключающимся в том, что он полностью основан на вычислениях, выполняемых на гистограмме изображения, легко получаемой в виде одномерного массива.
# применение пороговой функции
image = cv2.threshold(image, 0, 255,
cv2.THRESH_BINARY_INV + cv2.THRESH_OTSU)[1]Функция threshold() возвращает 2 значения: найденный порог и изображения после применения пороговой функции. Так как нас интересует только изображение, то мы сразу берем значение второго элемента кортежа. Посмотрим на изображение после применения пороговой функции:

Осталось избавиться от дополнительных символов, представляющих бонусы в игре. Воспользуемся для этого несколькими методами. Прежде всего функцией medianBlur(), которая вычисляет медиану всех пикселей под окном ядра, и центральный пиксель заменяется этим медианным значением. Вторым аргументом функции задается размер ядра, который должен быть положительным нечетным числом (значение подобранно эмпирически).
# медианная фильтрация
image = cv2.medianBlur(image, 7)
Как видно на рис. 13, от дополнительных символов удалось избавиться не полностью, поэтому применим последовательность действий, устраняющих небольшие элементы на изображении. Дальнейшая обработка будет производиться с инвертированным изображением.
Воспользуемся функцией connectedComponentsWithStats().
Первым аргументом мы передаем 8-разрядное одноканальное изображение, которое будет помечено
Вторым аргументом передаем количество подключений между пикселями (4 или 8)4
Алгоритм связанных компонент
4 При выборе значения параметра connectivity может возникнуть вопрос о том, какое значение выбрать. Разберемся в чем разница между 4 и 8.
Алгоритм связанных компонент представляет собой итерационный алгоритм для маркировки изображения с использованием четырех или восьми пикселей связности. Два пикселя соединены, если они имеют одинаковое значение и являются соседями. На изображении каждый пиксель имеет восемь соседних пикселей:
Четыре подключения означают, что только соседи 2, 4, 5, 7 могут быть подключены к центру, если они имеют то же значение, что и центральный пиксель. С восьмью подключениями 8 соседей могут быть подключены, если они имеют то же значение, что и центральный пиксель.
Покажем различие между количеством соседей на небольшом изображение размером 10x10:

Алгоритм с четырьмя соседями обнаруживает два объекта. Алгоритм с восемью соседями обнаруживает только один объект, потому что два пикселя соединены по диагонали.
Третий аргумент (тип метки выходного изображения) взят по умолчанию.
Функция возвращает кортеж, состоящий из 4 элементов:
Общее количество уникальных меток
nb_components(т. е. общее количество компонентов), которые были обнаруженыМаска
output, которая имеет те же пространственные размеры, что и входное изображение. Каждому пикселю в маске сопоставляется целое значение идентификатора, соответствующее определенной компоненте-
Статистика
statsпо каждой компоненте:CC_STAT_LEFT: крайняя леваякоордината компонента
CC_STAT_TOP: самая верхняякоордината компонента
CC_STAT_WIDTH: ширина компоненты, определяемая ограничительной рамкойCC_STAT_HEIGHT: высота компоненты, определяемая ограничительной рамкойCC_STAT_AREA: количество пикселей (площадь) компоненты
Центроиды
centroids(т. е. центр)- координаты каждой компоненты
def remove_elements(image):
"""
Удаляет из изображения объекты небольшого размера
Параметры
---------
image : numpy.ndarray
Черно-белое изображение, где фон - черный, а объекты - белые
Возвращает
----------
numpy.ndarray
Черно-белое изображение без объектов небольшого размера
"""
# получаем данные по найденным компонентам
nb_components, output, stats, centroids = cv2.connectedComponentsWithStats(
image, connectivity=8)
# получаем размеры каждой компоненты
sizes = stats[1:, -1]
# не рассматриваем фон как компоненту
nb_components = nb_components - 1
# определяем минимальный размер компоненты
min_size = 300
# формируем итоговое изображение
image = np.zeros((output.shape))
# перебираем все компоненты в изображении и сохраняем только тогда, когда она больше min_size
for i in range(0, nb_components):
if sizes[i] >= min_size:
image[output == i + 1] = 255
return imageПокажем визуальный пример работы данной функции. Для каждой компоненты рисуем ограничивающую рамку (красный прямоугольник) и центроид/центр (зеленый круг).

Посмотрим, какое изображение получилось после применения функции remove_elements():
")
Казалось бы, что работа по предобработке изображения закончена, однако это не так. Необходимо применить дополнительные меры для повышения качества распознавания букв. Применим к изображению функцию GaussianBlur() для размытия с помощью фильтра Гаусса. В качестве первого параметра мы передаем изображение, далее мы должны указать ширину и высоту ядра (3, 3), которые должны быть положительными и нечетными. Также необходимо указать стандартное отклонение в направлениях и
.
# размытие изображения на основе фильтра Гаусса
image = cv2.GaussianBlur(image, (3, 3), 2, 2)")
Далее воспользуемся функцией filter2D(), которая применяет к изображению произвольный линейный фильтр. Вторым параметром является значение -1, так как глубину изображения нам менять не надо. Третьим параметром в качестве линейного фильтра передаем следующее ядро:

# повышение резкости изображения
kernel = np.array([[-1, -1, -1],
[-1, 9, -1],
[-1, -1, -1]])
image = cv2.filter2D(image, -1, kernel)
После всех шагов предобработки инвертируем изображение обратно и получаем:
# инвертируем результат
image = 255 - image
3. Распознавание букв
Для распознавания букв воспользуемся Python-tesseract - инструмент оптического распознавания символов (OCR) для python. Для перевода изображения в строку воспользуемся функцией image_to_string() в качестве первого параметра мы передаем объект типа PIL.Image.Image. Так как мы будем распознавать русские буквы, то необходимо выставить значение параметра lang='rus', но для этого дополнительно необходимо скачать соответсвующий языковой файл.
Еще один из важнейших параметров это конфигурация config.
config = '--psm 10 --oem 0 ' \
+ '-c page_separator="" ' \
+ 'tessedit_char_whitelist=абвгдежзийклмнопрстуфхцчшщъыьэюя'Рассмотрим все опции, необходимые для корректного распознавания:
psmили PageSegMode - режим сегментации страницы. Данная опция влияет на то, как Тессеракт разбивает изображение на строки текста и слова. Значению 10 соответсвуетPSM_SINGLE_CHAR, означающее, что изображение стоит рассматривать как единственный символ.oemили OcrEngineMode - режим работы механизма распознавания текста. Тессеракт имеет несколько режимов работы механизма распознавания с разной производительностью и скоростью. Значению 0 соответсвуетOEM_TESSERACT_ONLY. Т.е. для распознавания используется старая версия движка Tesseract, так как версия, включающая новый движок на основе LSTM для данной задачи работала хуже, показывая меньшую точность (против
).
tessedit_char_whitelist- список букв для распознавания. Кроме букв русского алфавита (исключая ё) ничего распознавать не нужно.
Для того чтобы поставленный режим сегментации работал правильно, нужно разбить изображение на 25 частей, каждая из которых включает в себя одну букву.
# высота и ширина обрезанного с буквой изображения
height = width = 170
# список распознанных букв
letters = []
# перебор координат по сетке
for i, y in enumerate(range(0, 700, 155)):
for j, x in enumerate(range(0, 700, 150)):
# обрезанное изображение
crop_image = image[y:y+height, x:x+width]
# добавление белой границы вокруг каждого обрезанного фрагмента
border_size = 10
crop_image = cv2.copyMakeBorder(
np.float32(crop_image),
top=border_size,
bottom=border_size,
left=border_size,
right=border_size,
borderType=cv2.BORDER_CONSTANT,
value=[255, 255, 255]
)
# конвертация изображение в объект Image в оттенках серого
crop_image = Image.fromarray(crop_image).convert('L')
# распознавание буквы
data = image_to_string(crop_image, lang='rus', config=config)
# добавляем букву в список распознанных букв
letters.append(data[0].lower())Можно заметить, что я добавил рамку белого цвета вокруг обрезанного фрагмента. Дело в том, что согласно документации по улучшению качества распознавания Tesseract, рекомендуется добавлять такие границы. Также стоит уточнить, что значение высоты и ширины обрезанной части изображения подобранны эмпирически. В итоге получаем следующую картину:

На рис. 20 я показываю каждый из 25 фрагментов, где в качестве заголовка распознанная буква. Можно заметить, что для заглавной буквы "Д" была распознана строчная "д", но в рамках решаемой задачи это не важно, так как в итоге все буквы приводятся к нижнему регистру.
4. Взаимодействие клиента и сервера
Для взаимодействия клиента и сервера воспользуемся воспользуемся TCP сокетом, обеспечивающим надежный информационный обмен между процессами. Рассмотрим визуально работу TCP сокета.

Реализация сервера и клиента представлена в репозитории GitHub, ссылка на который дана в конце статьи. Со стороны клиента необходимо написать тот IP адрес, который соответствует IP адресу машины, на которой запущен сервер. IP адрес можно узнать через терминал.
Программа на сервере работает до тех пор, пока не поступит сигнал прерывания. Таким образом, можно запускать shortcut несколько раз без необходимости повторного запуска программы на сервере.
5. Клиентская часть и Shortcuts
Взаимодействие со стороны клиента начинается с шортката для большей автоматизации процесса. Рассмотрим далее поэтапное создание шортката.
Переходим в приложение Команды и нажимаем на знак "+" для создания нового шортката.

Нажимаем на кнопку "Добавить действие" и во вкладке "Скрипты" в разделе "Логика управления" находим действие "Если" (Любое действие можно найти в поиске по ключевому слову).

Далее в качестве входных данных выбираем "Входные данные команды". Это те данные, которые передаются вместе с запуском шортката.

Выбираем в следующем поле "нет никаких значений".

Далее все действия вставляем в ту часть ветки, которая выполняется при истинности условия, т.е. когда входных данных при запуске шортката нет. Ищем в поиске действие "Открыть приложение" и в качестве приложения выбираем искомую игру.

Находим действие "Подождать" и оставляем значение по умолчанию (1 секунда).

Добавляем действие "Сделать снимок экрана".

Сделанный снимок экрана, на котором располагается игровое поле, необходимо скопировать в буфер обмена. Находим данной действие и вставляем после предыдущего. Поле, в котором нужно указать что конкретно скопировать, выставиться автоматически. Дополнительные параметры для данного действия указывать не нужно.

Возвращаемся обратно в приложение "Команды" с помощью знакомого нам действия "Открыть". Это действие необходимо для возможности открытия скрипта в "Pythonista".

Начинается самая интересная часть шортката. Запускаем скрипт в приложении Pythonista. В качестве имени скрипта вводим путь до скрипта в Pythonista. Дополнительные аргументы передавать не нужно.

Вместо пути "/Socket/client.py" нужно указать свой, который ведет до скрипта. Скрипт в Pythonista можно создать с помощью нажатия на "+" снизу экрана и выбрав "Empty Script".

Назвать скрипт можно как угодно, главное, указать в дальнейшем правильный путь при его запуске. Код, который нужно вставить в скрипт, приведен ниже. Он также находится в репозитории GitHub под названием client_iphone.py. Дополнительно нужно помнить о необходимости поменять IP хоста, на котором запущен сервер, на корректный (т.е. на свой).
Скрипт для Pythonista
import os
import clipboard
from socket import *
from PIL import Image
from io import BytesIO
from shortcuts import open_shortcuts_app
def image_to_binary(image):
"""
Преобразует изображение в бинарную строку
Параметры
---------
image : PIL.Image.Image
Исходное изображение
Возвращает
----------
bytes
Изображение в бинарном представлении
"""
# инициализируем бинарный поток BytesIO
with BytesIO() as output:
# сохраняем в изображение в памяти
image.save(output, format='PNG')
# получаем массив байтов
binary_image = output.getvalue()
return binary_image
def main():
# указываем ip хоста, на котором запущен docker
ip = "192.168.1.64"
# порт, через который взаимодействует с сервером
port = 50000
# адрес сервера
server_address = (ip, port)
# создаем экземпляр класса socket
# AF_INET - используем протокол версии IPv4
# SOCK_STREAM - использование протокола TCP
socket_ = socket(AF_INET, SOCK_STREAM)
# подключаемся к серверу
socket_.connect(server_address)
# получаем содержимое буфера обмена
image = clipboard.get_image()
# конвертируем изображение в бинарный формат
binary_image = image_to_binary(image)
# отправляем бинарное изображение серверу
socket_.sendall(binary_image)
print("Sent photo")
# закрываем сокетное соединение
socket_.close()
# создаем экземпляр класса socket
socket_ = socket(AF_INET, SOCK_STREAM)
# пытаемся подключиться к серверу
connect = False
while not connect:
try:
socket_.connect(server_address)
connect = True
except Exception:
pass
# получаем сообщение
text = socket_.recv(65536)
print('Received text')
# сохраняем сообщение в буфер обмена
clipboard.set(text.decode())
# закрываем сокетное соединение
socket_.close()
# открываем нужный shortcut
open_shortcuts_app(name='WordsSolverCV', shortcut_input='ready')
if __name__ == "__main__":
main()Стоит уточнить некоторые важные детали в скрипте. В Pythonista есть специальные модули для взаимодействия с iPhone, такие как clipboard и shortcuts.
clipboard- определяет простые функции для чтения и записи в буфер обмена в iOS. Функцияget_image()позволяет получить изображение из буфера обмена в видеPIL Image. Функцияset()устанавливает содержимое буфера обмена в новую строку или строку юникода.shortcuts- предоставляет утилиты для URL-адресов Pythonista, которые можно использовать для запуска приложения, а также для запуска или открытия сценариев. Функцияopen_shortcuts_app()позволяет открыть определенный шорткат с возможностью передачи значения. Первым аргументом вводим название шортката'WordsSolverCV'(так мы в итоге назовем шорткат), а вторым мы можем передать любое значение, например, строку'ready'. Именно данная функция позволяет нам вернуться обратно в работающий шорткат.
Так как для работы скрипта нужно некоторое время, то необходимо добавить действие "Ожидать возврата", которое позволяет приостановить выполнение шортката до тех пор, пока мы не вернемся обратно.

На этом первая часть ветки условия завершена. В другой части, которая начинается с "Иначе", добавим действия: "Открыть Слово", "Получить буфер обмена" и "Показать уведомление". В "Показать уведомление" дополнительно добавляем переменную "Буфер обмена".

В буфере обмена хранится сообщение (найденные слова через пробел в порядке убывания длины), которое передал сервер, после решения задачи. Посмотрим на весь шорткат целиком.

Может показаться, что такая структура подразумевает выполнение только одной из веток условного оператора, однако это не так. При первом запуске шортката мы попадаем в левую ветвь и далее скрипт с помощью функции open_shortcuts_app() возвращает нас к искомому шорткату. Функция передает дополнительно при открытии шортката входные данные, поэтому мы попадаем в правую ветвь, на которой выполнение шортката заканчивается.
6. Серверная часть и Docker
Загрузка всех дополнительных модулей, использующихся в данном проекте, требует некоторого времени и усилий, поэтому было принято решение о переносе всей серверной части в Docker. Docker - это способ изолировать процесс от системы, в которой он запущен. Это позволяет нам изолировать код, написанный для приложения, и ресурсы, необходимые для запуска этого приложения, от оборудования, на котором оно выполняется. Мы добавляем уровень сложности в наше программное обеспечение, но при этом получаем преимущество, гарантируя, что наша локальная среда разработки будет идентична любой возможной среде, в которой мы будем развертывать приложение.
Далее рассмотрим файл Dockerfile. Dockerfile - это способ создания сценария создания образа.
# Задаем базовый образ
FROM python:3.7-slim
# Устанавливаем необходимые зависимости
RUN apt-get update && \
apt-get install -yq libgtk2.0-dev && \
apt-get install -yq libtesseract-dev && \
apt-get install -yq tesseract-ocr && \
pip install --upgrade pip
# Копируем языковой файл для tesseract-ocr в нужное место
COPY rus.traineddata /usr/share/tesseract-ocr/4.00/tessdata/
# Устанавливаем постоянные переменные среды
ENV PROJECT_ROOT /app
ENV IMAGE_ROOT /images
# Создаем дополнительные директории
RUN mkdir $PROJECT_ROOT $IMAGE_ROOT
# Копируем код из локального контекста в рабочую директорию образа
COPY . $PROJECT_ROOT
# Задаём текущую рабочую директорию
WORKDIR $PROJECT_ROOT
# Установка необходимых модулей и удаление лишего файла
RUN pip install -r requirements.txt --no-cache-dir && \
rm rus.traineddata
# Запуск основной программы с отключением буферизации stdout
CMD ["python3", "-u", "./main.py"]В качестве базового образа я использую python:3.7-slim, который содержит только минимальные пакеты, необходимые для запуска python. Итоговый образ весит чуть менее 900 Мб. Развертывание проекта занимает около 83 секунд. Для снятия необходимости самостоятельно пробрасывать порты при каждом запуске Docker, я прописал все необходимое в docker-compose.yaml.
version: '3'
services:
# Название сервиса
server:
build:
# Путь к директории, содержащей файл Dockerfile
context: ./
# Название образа
image: words_solver_cv_server
# Название контейнера
container_name: words_solver_cv
# Перенаправление порта [порт компьютера]:[порт контейнера]
ports:
- "50000:50000"
# Данная инструкция сообщает докеру, что контейнер должен
# прослушивать данный порт во время выполнения
expose:
- "50000"Посмотрим, как происходит проброс портов на докере.

Клиент посылает запрос на IP 192.168.1.64 и порт 50000. Данный локальный IP привязан к хосту, на котором запущен Docker. При обращении к 50000 порту механизм Docker за кулисами перенаправляет нас на порт 50000 контейнера, IP адрес которого 172.19.0.2.
7. Вывод и пример работы
Посмотрим на пример работы программы со стороны клиента и сервера.
На видео видно, что приложение работает корректно. Работа скрипта составляет 14 секунд.
Итого: мы рассмотрели реализацию алгоритма нахождения слов в игре типа Boggle, научились предобрабатывать изображение для дальнейшего распознавания букв, разобрались со связью клиента и сервера через TCP сокеты, поняли как связать между собой Shortcut и Pythonista, выяснили как осуществляется проброс портов в Docker.
8. Полезные ссылки
Комментарии (6)

lyrjie
08.09.2021 15:19Спасибо за интересную статью
Несколько лет назад тоже развлекался с этой игрой, но под Android. Пришёл примерно к тому же, что и у вас, только не стал запариваться с OCR и просто находил для каждого квадрата наиболее похожую букву из заранее сделанных скриншотов, работало в 99% случаев. Так же находились множители слов и букв (и влияли на приоритет слова естественно)
Потом ещё сделал автоматический ввод свайпом с использованием ADB
В целом игра в этом оказалась несколько скучнее той же Балды -- комбинаций намного меньше (потому что нет подставновки своих букв, значительно увеличивающих фактор ветвления) и практически любая реализация поиска оказывается достаточно быстра

prudent Автор
08.09.2021 15:28Спасибо за отзыв!
Я также, как и вы, думал об автоматическом вводе слов свайпом, но в рамках ОС iOS пока не представляю как это реализовать.
В остальном я с вами согласен.
theGrove
Жаль что Pythonista стоит 10$
prudent Автор
Да, это действительно так. Есть множество бесплатных альтернатив Pythonista, которые есть в App Store, однако, скрипты python из приложения "Команды" (Shortcuts) через них не запустишь.
Возможна альтернатива в качестве запуска JavaScript через Shortcuts, но в таком случае архитектура проекта будет совсем другой.
Также можно обеспечить взаимодействие с хостом через скрипт SSH.
P.S. Pythonista является очень мощным инструментом, позволяющим реализовывать множество интересных вещей совместно с Shortcuts.